JPA 등장 배경
ORM의 시초는 "EJB"이다.
EJB는 Eneterprise Java Bean의 약자로써 기업환경의 시스템을 구현하기 위한 Server 측 Componenet Model이다.
EJB에서는 DB 연동이 필요하지 않은 Session Bean과 DB의 데이터를 관리하는 Entity Bean이 존재한다. DB 관련 쿼리는 Entity Bean에서 자동으로 처리하여 개발자는 로직에 더욱 집중하며 코드를 짤 수 있게 되는 것이다.
일반적으로 Client가 Session Bean을 부르고, Session Bean이 Entity Bean을 호출하여 DB에 접근한다.
하지만 EJB는 코드가 지저분하고 Interface를 많이 구현해야 해서 복잡성이 높으며 속도가 느리다는 단점이 존재했다.
이런 문제를 해결하기 위해 나온 것이 JPA이다.
JPA는 인터페이스로서 자바의 ORM 기술 표준이다. Interface는 상속을 받아 구현을 해야 활용할 수 있는데 JPA도 Interface의 일종이므로 이를 구현한 구현체가 필요하다.
구현체의 대표적인 예가 Hibernate, Eclipse Link 등이 존재한다.
최신에는 Hibernate를 활용하지 않고 Hibernate를 더욱 쉽게 사용하기 위해 추상화시킨 Spring Data JPA라는 모듈을 이용하여 JPA 기술을 다룬다.
즉, JPA Interface에 대한 로직을 구현한 Hibernate를 사용하는데 Hibernate가 사용이 어렵기 때문에 Hibernate를 쉽게 사용할 수 있도록 추상화한 Spring Data JPA를 활용하게 되는 것이다.
Spring Data JPA가 등장한 이유는 크게 2가지가 존재한다.
먼저 구현체 교체의 용이성이다.
지금은 Hibernate를 활용하지만 만약 Hibernate가 아닌 다른 JPA 구현체가 개발의 메인 기술이 될 수도 있다.
이때 Spring Data JPA를 활용하면 교체가 매우 쉽다. 왜냐하면 Spring Data JPA는 내부에서 구현체 Mapping을 지원해주기 때문에 구현체가 달라지더라도 Spring 측에서 알아서 이 변경점을 인지하고 적용해주기 때문에 별다른 코드의 수정이나 추가 없이 빠른 교체가 가능해진다.
두 번째로 저장소 교체의 용이성이다.
지금은 RDB로 모든 데이터를 처리하고 있지만, 트래픽이 많아지면 RDB로 도저히 감당이 안될 때가 존재한다. 실제로 대기업에서는 MongoDB로 대용량의 데이터를 처리하는 경우도 많다.
이때 개발자는 Spring Data MongoDB로 의존성만 교체하면 된다. Spring Data의 하위 프로젝트는 결국 기본적인 CRUD Interface가 동일하기 때문에 의존성을 교체하더라도 기본적인 기능(find(), save(), findOne())등은 공통적으로 가지고 있으므로 저장소가 교체되더라도 기본적인 기능 변경은 수행하지 않아도 된다.
이런 장점들 때문에 Spring 팀에서도 Hibernate보다는 Spring Data 프로젝트를 활용하는 것을 권장하고 있다.
실무에서 JPA를 활용하지 못하는 가장 큰 이유로 높은 러닝 커브를 이야기한다.
JPA라는 기술이 RDB를 객체 지향적으로 활용하기 위한 것인데, 이를 잘 활용하려면 객체지향 프로그램과 관계형 데이터베이스에 대한 이해도가 높아야 하기 때문이다.
하지만 JPA를 제대로 활용하게 되면 CRUD 쿼리를 직접 짤 필요가 없어 시간적 이점을 볼 수 있다는 장점이 존재하며 객체지향 프로그램을 DB에 저장시키는 방법에 대해 고민하지 않아도 된다는 장점이 존재한다.
(RDB와 객체지향 프로그래밍의 패러다임의 불일치 문제를 해결해주는 것인데 아래에서 더욱 자세히 설명하도록 하겠다)
물론 최적의 Query문을 직접 짜서 실행하는 것보다 속도 자체는 느릴 수 있지만 JPA 측에서도 여러 성능 이슈 해결책들을 이미 준비해놨으며 개발자가 직접 짠 Query가 최적의 Query라는 것을 확실할 수 없는 경우에는 더욱 좋은 성능을 낼 수 있을 것이다.
JPA 동작 과정
JPA 또한 JDBC를 사용한다. 언제나 DB와 Java의 연동은 JDBC로부터 시작한다.
JPA는 Application과 JDBC 사이에 동작한다.
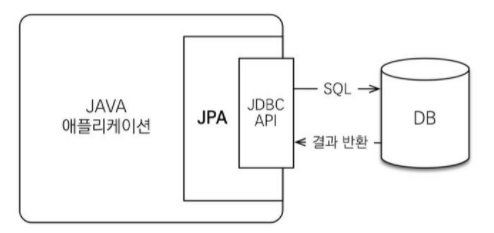
개발자가 JPA를 활용하면 JPA 내부에서 JDBC API를 활용하여 SQL을 호출하며 DB와 통신하는 것이다. 여기까지는 MyBatis와 동일하다.
단지 MyBatis와 달리 JPA는 Query문도 JPA 측에서 알아서 생성하게 된다.
따라서, 특정 객체를 저장하고 싶을 때 개발자는 JPA에 객체만 넘기면 JPA는 Entity와 개발자가 원하는 동작 과정을 인식하고 이에 맞춰 자동으로 적절한 SQL을 생성해 DB와 연동하게 된다.
또한 JPA에 PK값 등 특정 값을 전달해주면 이를 바탕으로 적절한 SELECT SQL을 생성하며, 결과를 원하는 형태로 알아서 매핑하게 된다.
JPA를 활용하는 이유
JPA를 활용하는 이유라기 보다는 정확히 "MyBatis 대신 JPA를 쓰는 이유"라고 설명하는 것이 더 좋을 것이다.
MyBatis는 SQL 기반 Persistence Framework인데, 과연 SQL을 직접 다루는 것에는 어떤 문제가 존재할까?
그리고 이 SQL을 직접 다루는 것에 대한 문제를 이해하면 반대로 JPA를 활용하는 이유도 알게 될 것이다.
SQL을 직접 다룰 때 발생하는 문제점
반복이 너무 많음
Member라는 클래스를 저장하고 싶다고 가정하자.
그렇다면 Member 클래스의 멤버 변수와 Column을 모두 mapping 시켜야 할 것이다. 그나마 Mapping 쪽은 MyBatis도 ReulstMap이나 SQL 태그를 통해 어느 정도 코드 양을 줄일 수 있다.
하지만 결국 실행할 Query는 내가 직접 짜야한다는 문제점이 존재한다.
모든 기능 개발을 할 때 CRUD는 기본일텐데, 우리는 객체 1개를 만들 때마다 해당 객체에 대한 CRUD 쿼리를 만들어야 하므로 최소 4개의 Query를 생성해야 하는 것이다.
즉, 클래스 하나를 생성하는데에는 10초면 끝나겠지만 Query문을 작성하는 지루하며 개발과 직접적인 연관도 없는 작업이 반복해서 일어나야 할 것이다.
SQL에 의존적인 개발
먼저 객체의 멤버 변수를 하나 증가시켜야 한다고 가정하자.
이 경우 MyBatis 같은 것은 Query문을 모두 수정해줘야 한다. 왜냐하면 멤버 변수를 DB에 저장하기 위해선 Table에 Column도 추가해줘야 할 것이며, 이 Column에 대한 데이터 처리 로직 또한 추가해야 할 것이기 때문이다.
사실 멤버 변수 증가는 그나마 괜찮다. JPA도 멤버 변수를 하나 추가시키면 어쨌든 추가적인 작업은 필요하기 때문이다.(그래 봤자 Annotation 추가와 Table 수정뿐이긴 하다)
문제는 "삭제"와 "변경"이다.
삭제의 경우 멤버 변수를 삭제할 경우 객체에는 해당 데이터가 없어질 것이다. 만약 해당 멤버 변수를 사용하는 Query문이 존재한다면 에러가 발생할 것이고, 에러 처리에 대한 시간이 소요될 것이며 Human Error의 가능성은 항상 존재하기 때문에 에러 발생 확률도 증가할 것이다.
변경은 더 골치아프다. 예를 들어 멤버 변수 이름을 userId -> userPassword로 바꿨다고 가정하자. 이 경우 #{userId}로 짠 모든 부분에 대해 에러가 발생할 것이며, userId를 userPassword로 모두 바꾸는 과정이 필수적일 것이다.
이미 구현된 로직을 계속해서 구조 수정이 필요할 때마다 바꿔야 하기 때문에 SQL에 너무 의존적인 개발이 되는 것이다
패러다임의 불일치
이 문제는 조금 핵심적인 부분을 관통하고 있다고 생각한다.
RDB의 목적은 무엇일까? 바로 데이터를 체계적으로 저장하는 것이다.
자바의 목적은 무엇일까? 객체지향 언어로써 추상화, 캡슐화, 정보은닉, 상속, 다형성 등 시스템의 복잡성을 제어하며 기능과 속성을 관리하는 것에 큰 목적을 둔다.
나는 자바로 코드를 짜서 최대한 속성과 기능을 관리하기 편하도록 구현했다. 그런데 RDB 입장에서는 이렇게 구현한 코드는 데이터를 저장하기 까다롭게 만들 뿐 아무런 장점이 없다. 오히려 Query 구현이 힘들어지기 때문에 악영향만 미치게 될 것이다.
만약 SQL을 활용하게 되면 이런 정보은닉, 상속 등은 JOIN문을 추가하여 Query를 짜야되며 이는 Query의 길이가 길어지며 로직이 복잡해져야 하는 단점을 가지고 올 것이다.
즉, 목적이 다르기 때문에 이런 패러다임의 불일치를 해결할 수 있는 자바 코드를 추가하거나 SQL문에서 이런 불일치 문제를 해결할 수 있는 Query문을 만들어야 하는 추가 작업이 필요하게 되는 것이다.
가장 대표적인 것이 "상속"이 아닐까 싶다.
자바에서는 상속 같은 경우 간편하게 extends를 통해 구현할 수 있다. 하지만 Table 입장에서는 "상속"이라는 개념은 전혀 필요하지 않다.
물론 상속 기능과 유사한 "Super-Sub Type"이 존재하기는 하지만 이를 직접 Query문에 활용하기엔 한계가 있다.
특히 Insert 문을 작성할 때는 부모 객체용 INSERT와 자식 객체용 INSERT를 따로 작성해야 하고, 자식이 많을 경우 부모 INSERT 1번과 자식 INSERT N번이 일어날 때마다 Connection Pool에서 계속 Connection을 빌렸다 돌려줬다 하는 과정이 필요하기 때문에 MyBatis의 "성능"이라는 장점을 지울 만큼의 시간 지연을 가지고 올 수도 있게 된다.
또한 연관 관계에서도 이런 단점이 보인다.
객체 입장에서 하위 객체인 멤버는 단방향 조회밖에 수행되지 않는다.
하지만, RDB에서는 JOIN을 활용하면 양방향으로 모두 조회가 가능하다. 결국 JOIN을 통해 얻은 데이터를 1개의 Row Data로 만들어 반환학 때문에 어느 방향에서나 데이터를 확인할 수 있게 되며, 처음 짠 로직과는 맞지 않는 Query문의 결과가 나오게 되는 것이다
JPA를 활용하는 이유
반복 작업의 감소
JPA는 Query를 JPA가 알아서 짜준다.
따라서 Query문을 반복해서 짜줄 필요가 없다는 장점이 존재한다.
생산성
JPA는 Query를 통해 DB를 활용하기보다는 Java처럼 Collection에 데이터를 넣고 빼는 방식으로 DB를 활용한다.
따라서, DB에 대해서 잘 모르더라도 Java에 대해 잘 알면 Java와 같은 방식으로 데이터를 처리할 수 있게 된다.
특히, 수정이 매우 간단하다는 장점이 존재한다.
JPA에서는 영속성 컨텍스트라는 장소 안에 객체(Entity)를 저장하게 된다. 여기에 남아 있는 객체를 선택하여 값을 변경한다면 따로 Update 쿼리를 수행하지 않아도 Transaction이 끝나면 영속성 컨텍스트 내에 존재하는 객체 정보를 DB에 저장시킨다. 즉, 이전에 변경시켰던 데이터가 DB에 저장되어 Update 과정이 수행되는 것이다.
유지보수
SQL 개발의 단점은 "SQL에 의존적이다"였다.
하지만 JPA는 SQL에 의존적이지 않기 때문에 컬럼 등이 변경되더라도 빠른 처리가 가능하며, Query 로직에 대한 변경이 필요 없기 때문에 유지보수가 쉽다는 장점이 존재한다.
Object와 RDB간 패러다임 불일치 해결
Object는 "객체 상속 관계"를 가지며 존재하고, Table은 "관계형 데이터베이스 관계", 즉 Super-Sub Type 관계로 존재한다.
이런 패러다임 불일치 문제를 JPA는 알아서 해결해준다는 장점이 존재한다.
즉, 개발자는 객체지향적으로만 프로그래밍을 하면 JPA에서 알아서 이를 RDB에 맞게 변환시켜주기 때문에 SQL 종속적인 개발을 하지 않아도 된다는 장점이 존재한다.
JPA의 성능 최적화 기능
중간 계층이 있는 경우 "캐싱 기능"과 "버퍼링 기능"이 존재한다.
캐싱 기능과 버퍼링 기능 모두 영속성 컨텍스트 내에서 일어나는데, 캐싱 기능은 같은 Transaction 내에서 같은 Entity를 사용할 경우 DB에서 2번 뽑는 것이 아닌 이전에 뽑았던 Entity를 활용하는 것이며, 버퍼링 기능은 "쓰기 지연"이라는 말로 대체될 수 있으며 최대한 SQL 구문을 실행하지 않고 Transaction이 끝날 때나 꼭 DB에 SQL 구문을 실행해야 하는 경우까지 SQL 실행을 지연하는 것이다.
캐싱 기능은 약간의 조회 성능에 도움을 주지만 큰 도움까지는 되지 않는다.
하지만 버퍼링 기능은 많은 이점을 가지고 온다. 예를 들어 A, B, C 데이터를 저장할 때 SQL 구문을 사용하면 A를 저장한 이후 차례로 B, C를 저장하는 과정이 벌어질 것이다. 이 경우 Connection Pool에서 커넥션을 빌려오는 과정이 3번 일어난기 때문에 이에 의한 시간 낭비가 생각보다 심하다. 하지만 JPA는 A, B, C 데이터를 저장하는 Query를 영속성 컨텍스트 내에 저장해놨다고 Transaction이 끝날 때 한 번에 저장된 쿼리를 수행시킴으로써 Connection을 한 번만 받아와도 모든 SQL 명령을 수행할 수 있게 되는 것이다.
추가로 지연 로딩과 즉시 로딩도 정할 수 있어 모두 지연 로딩으로 설정한 뒤 성능 최적화가 필요할 때만 옵션을 변경하며 활용할 수 있다.
Hibernate
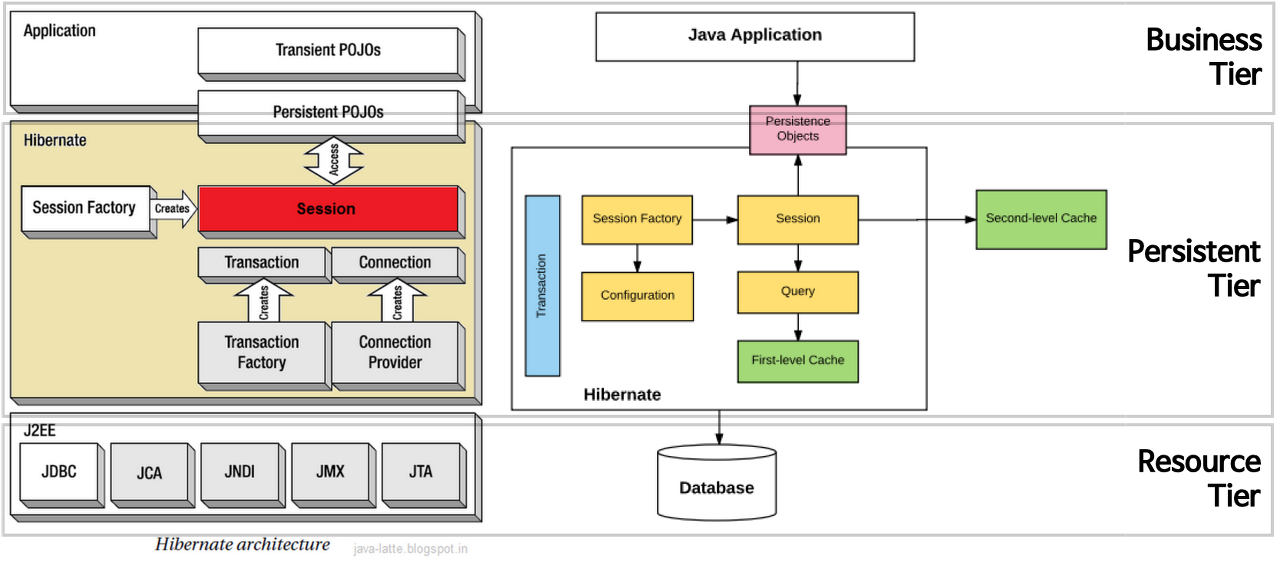
Hibernate는 JPA 구현체의 한 종류이다.
Hibenrate가 지원하는 메서드 내에 JDBC API가 동작하고 있고, Hibenrate가 직접 Query문을 짜주기 때문에 개발자가 직접 SQL을 작성하지 않아도 된다는 장점을 가진다.
Hibernate는 HQL(Hibernate Query Language)라고 불리는 매우 강력한 Query 언어를 포함하고 있다.
HQL은 SQL과 유사하면서도 추가적인 Convention을 정의할 수도 있다. HQL은 객체 지향적이기 때문에 상속, 다형성, 관계 등 객체 지향적 목표를 가지고 생성된 객체에 대한 처리가 매우 쉽다.
HQL은 쿼리 결과를 객체로 반환하기 때문에 개발자가 매우 편리하며 SQL에서는 직접 지원하지 않는 Pagination이나 동적 프로파일링과 같은 향상된 기능을 제공한다.
