영속성 컨텍스트
영속성 컨텍스트
JPA 개념 중에 가장 강조할 개념이 무엇인지 묻는다면 필자는 아무 고민하지 않고 영속성 컨텍스트라고 말할 것이다.
영속성 컨텍스트는 (개인적인 생각에) JPA의 꽃이라고도 할 수 있으며 동시에 JPA에서 제공하는 여러 편리한 기능을 활용할 수 있게 해주는 최고의 도우미이기도 하다.
동시에 Entity를 관리해주기도 하고 Update를 편리하게 할 수 있게 해주는 공간으로 영속성 컨텍스트에 대해 알지 못한다면 JPA 개념을 시작조차 할 수 없을 정도이다.
영속성 컨텍스트란 "Entity를 영구히 저장하는 환경"을 말한다.
조금 더 풀어보자면 JPA에서 Entity(객체)를 Transaction 과정에서 저장하여 재사용할 수 있게 해주는 공간이다.
이 영속성 컨텍스트라는 것은 HW적으로 "실제로 존재한다"의 개념보다는 논리적인 개념에 가깝다.
즉, 실제로는 존재하진 않지만 JPA의 동작 방식을 본다면 영속성 컨텍스트를 통해 객체가 관리된다고 이해하는 것이 JPA의 동작 방식을 가장 잘 표현하게 되는 것이다.
영속성 컨텍스트의 장점
캐싱에 의한 속도 증가
JPA는 영속성 컨텍스트 내에 Entity를 저장해 놓는다. 이때 Transaction 내에 Entity를 한 번이라도 사용하거나 검색한 적이 있다면 해당 Entity는 영속성 컨텍스트에 저장되어 있다. 만약 개발자가 임의로 Entity를 영속성 컨텍스트에서 삭제하지 않는 이상 Transaction이 끝날 때 까지는 Entity는 영속성 컨텍스트 내에 저장되어 있다. 따라서 A를 검색한 이후 A를 사용해야 할 때 다시 A를 검색하지 않고 영속성 컨텍스트에 저장되어 있는 A 데이터를 캐싱하여 활용함으로써 속도를 증가시킬 수 있다. 하지만, 이 캐싱에 의한 속도 증가는 그렇게까지 크지 않다는 것이 정설이다.
쓰기 지연을 통한 최소한의 Connection
이전에 말했던 "버퍼링 기능"이다. 실행시켜야 할 SQL 구문을 최대한 늦게 실행시키기 위해 영속성 컨텍스트 내에 존재하는 쓰기 지연 SQL 저장소에 SQL 구문들을 저장시켜 놓는다. 나중에 제대로 익히겠지만 꼭 SQL 저장소에 저장되어 있는 SQL 구문이 실행되어야 할 경우나 Transaction이 끝날 때 저장되어 있던 SQL 구문들을 한 번에 실행시킴으로써 Connection을 빌려오는 과정을 최소한으로 만들어 시간적 이득을 볼 수 있다는 장점이 존재한다.
쉬운 Update
영속성 컨텍스트에 저장된 Entity 값을 변경하면 Update 구문이 자동으로 쓰기 지연 SQL 저장소에 추가된다. 아래서 자세히 익히겠지만, 처음 뽑아서 저장했던 데이터와 현재 Entity를 비교하여 만약 차이가 존재한다면 Update 구문을 쓰기 지연 SQL 저장소에 추가시킴으로써 Update 구문을 추가시키는 것이다.
플러시(flush)
영속성 컨텍스트를 알기 전 미리 알고 가야 하는 개념인 "플러시(flush)"에 대해 먼저 알아보자.
플러시(flush)는 영속성 컨텍스트의 변경 내용을 인지하여 Update 구문을 쓰기 지연 SQL 저장소에 등록해주기도 하고 쓰기 지연 SQL 저장소에 저장된 Query를 DB에 전송하여 실행시키는 역할을 하기도 한다.
즉, Update 구문 추가와 SQL 저장소에 저장되어 있는 Query를 실행시키는 역할을 하는, "영속성 컨텍스트의 변경 내용을 DB에 동기화시키는" 것이다.
Update 시에 플러시를 실행시키면 아래와 같은 과정을 거치게 된다.
- Entity와 Snapshot(원래 저장되어 있던 Data)를 비교하여 변경을 감지(Dirty Checking)
- 1에서 변경이 존재할 경우 Update 구문의 Query를 생성하여 쓰기 지연 SQL 저장소에 등록
- 쓰기 지연 SQL에 저장된 Query문들을 DB에 전송 및 실행
물론 Update를 사용하지 않더라도 3 과정인 쓰기 지연 SQL에 저장된 Query문들을 전송하는 역할은 해야 하기 때문에 사실상 영속성 컨텍스트에 의해 관리되는 Transaction에는 무조건 1번 이상의 flush가 실행된다고 이해할 수 있다.
플러시라는 것의 정확한 개념은 "메서드를 실행시키는 것"이지만, 직접 메서드를 호출하는 경우는 거의 존재하지 않기 때문에 위에서 설명한 역할을 수행시키게 해주는 트리거 정도로 이해하면 더욱 이해가 쉬울 것이다.
플러시 모드 옵션
- FlushModeType.AUTO
- Default 설정
- Commit 하거나 Query를 실행할 때 Flush를 수행함
- FlushModeType.COMMIT
- Commit 할 때만 Flush를 수행함
- Commit 이전에 쓰기 지연 SQL 저장소에 존재하는 Query문에 대하여 Flush는 수행되지 않는다. 즉, INSERT, Update, DELETE 구문은 중간에 실행되지 않고 COMMIT 때 1번만 수행된다.
- 이 방법의 문제가 A를 저장한 이후 A를 바로 Search 하는 메서드가 존재한다고 가정하면 분명 A는 저장했는데 Commit 되지 않았으므로 DB에 저장되지는 않은 상태에서 A를 Select 하기 때문에 검색 결과가 없는 이상한 결과가 나올 수도 있다.
- 적용 방법 : EntityManager em일 때
em.setFlushMode(FlushModeType.COMMIT)을 통해 적용할 수 있다.
영속성 컨텍스트를 Flush 하는 방법
em.flush()를 통해 직접 호출
거의 활용하지 않는 방식이다.
Transaction Commit 시 자동 호출됨
트랜잭션을 Commit 하기 전 꼭 플러시를 호출하여 쓰기 지연 SQL 저장소에 저장되어 있는 SQL 구문들을 먼저 실행시켜줘야 한다.
이렇게 SQL Query를 실행시키고 Commit을 시켜야 내가 원하는 변경점들이 모두 적용될 것이다.
JPQL 쿼리 실행 시 플러시 자동 호출
JPQL는 DB에서 데이터를 뽑아 온다. 만약 flush()를 통해 DB와의 싱크가 맞춰져 있는 상태가 아니라면 내가 원하는 데이터를 뽑아 오지 못하거나 변경되기 이전 데이터를 뽑아올 수도 있다.
JPA는 이런 상황을 방지하기 위해 JPQL 실행 전 무조건 flush를 통해 DB와 영속성 컨텍스트 Entity의 싱크를 맞춘 이후 JPQL 쿼리를 날리도록 설정되어 있다.
영속성 컨텍스트의 Entity 처리 방식
엔티티 조회

영속성 컨텍스트의 장점 중 하나는 "캐싱"이 가능하다는 것이었다. 그리고 엔티티 조회를 통해 영속성 컨텍스트에 Entity를 저장하여 1차 캐시에 저장된 Entity를 활용함으로써 캐싱이 가능해지는 것이다.
DB에는 PK라는 Row Data에 대한 구분 값이 되는 고유한 값이 있다. 그리고 이 PK Column 데이터를 저장하는 객체의 멤버 변수를 "식별자"라고 한다.
@Id는 바로 이 식별자를 의미한다.
영속성 컨텍스트 안에는 1차 캐시라는 저장소가 존재하며 이 캐시에 Entity들을 저장하게 된다. 이때 Entity는 @Id(식별자) 값을 통해 활용할 수 있게 된다. 위 사진 예시에서 member라는 Entity를 활용하기 위해서는 "memebr1"이라는 값을 1차 캐시에 전달해주면 된다. 영속성 컨텍스트는 "member1"이라는 식별자를 가진 Entity를 찾아 해당 Entity를 반환해주는 역할을 함으로써 캐싱을 가능하게 하는 것이다.
1차 캐시가 존재하지 않는다면 "member"라는 데이터를 활용해야 할 때마다 DB에 접속하여 계속해서 데이터를 가지고 와야 할 테지만 1차 캐시를 활용할 경우 1번만 DB에 접속하여 등록시켰다면 이후에는 등록된 데이터를 계속해서 활용하면 되기 때문에 DB에 재접속할 필요가 없고 이 때문에 데이터를 빠르게 뽑을 수 있어 조회 속도를 향상할 수 있다.
그렇다면 만약 1차 캐시에 내가 원하는 데이터가 존재하지 않을 경우 어떤 과정을 통해 데이터를 뽑아 올까?
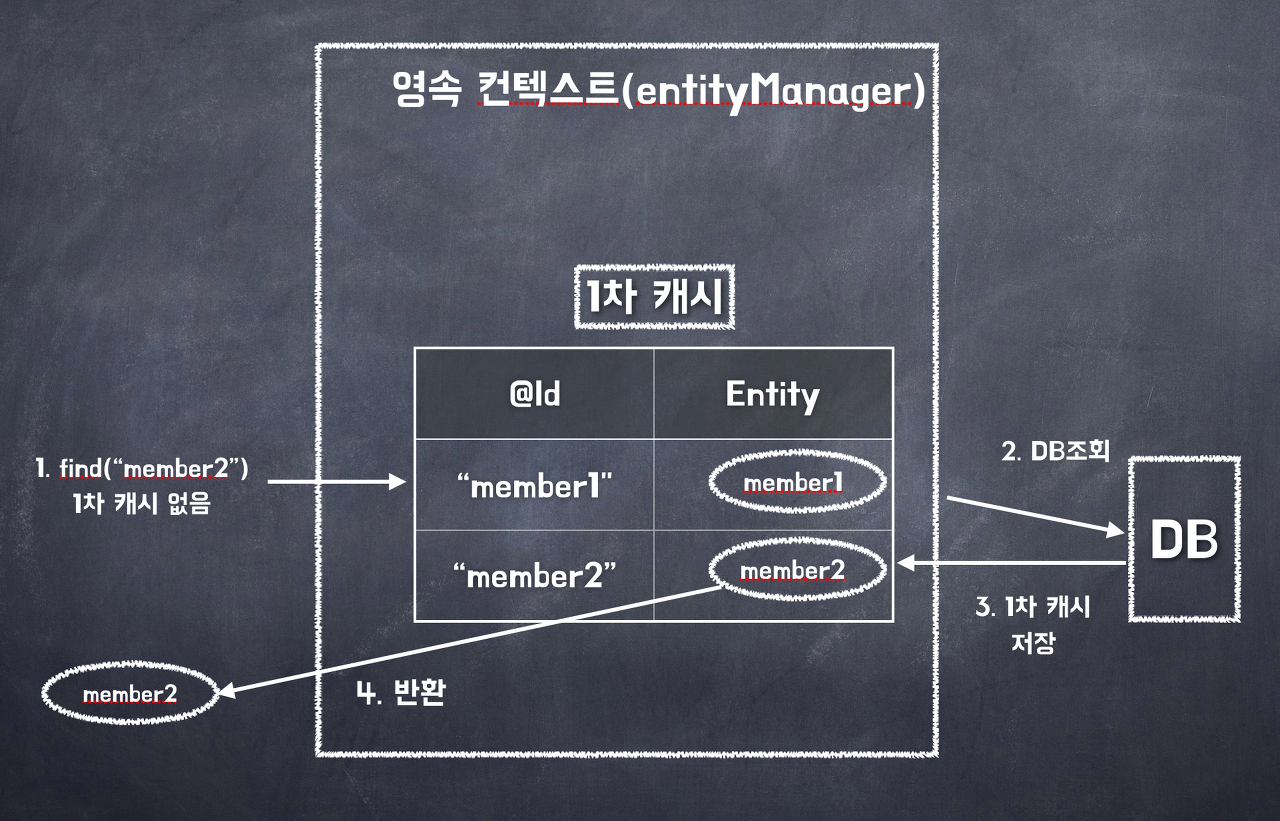
먼저 여기서 봐야 될 점은 3, 4 과정이다.
사실 1, 2 과정은 누구나 이해할 수 있을 것이다. 이전에 말했듯 식별자를 통해 Entity를 구분한다고 했기 때문에 "member2"라는 식별자를 가지는 Entity(member2 Entity)가 없었다고 가정해보자. 이 경우 영속성 컨텍스트에서는 해당 Entity가 존재하지 않는다는 것을 인지하고 DB에 접속하여 해당 데이터를 가지고 올 것이다. 여기까지는 아마 당연한 과정일 것이다.
내가 생각하는 핵심은 3번 과정이다.
JPA는 DB에서 데이터를 조회하면 이를 바로 반환해주는 것이 아닌 먼저 1차 캐시에 해당 Entity를 저장시킨다. 즉, 3번 과정을 통해 "member2"라는 식별자 값을 가진 member2 Entity를 1차 캐시에 선행적으로 저장시키는 것이다.
이렇게 1차 캐시에 Entity를 저장했다면 저장한 Entity를 반환함으로써 User는 "member2" 식별자를 가지는 Entity 데이터를 볼 수 있게 되는 것이다.
Entity 동일성 보장
엔티티 조회를 제대로 이해했다면 JPA의 특징 중 하나인 "Entity 동일성 보장"이라는 개념도 쉽게 이해할 수 있을 것이다.
이 Entity 동일성 보장이라는 개념이 상당히 재미있는 개념이다.
예를 들어 MyBatis에서 "User1"이라는 Entity를 User A에 저장하고, 이후 다시 "User1"이라는 Entity를 User B에 저장했다고 가정하자.
이후 A == B의 결과를 보면 당연히 "false"가 나올 것이다. 우리는 객체(Instance)에 대하여 "=="을 한다면 멤버 변수에 저장된 값이 같다고 하더라도 객체를 저장한 주솟값이 다르기 때문에 컴퓨터에서는 다르다고 판단함을 알고 있다.
하지만 JPA에서는 다르다.
이전에도 말했듯 JPA에서는 식별자(@Id) 값을 통해 Entity를 구분하게 된다. 이를 곰곰이 생각해보자면 "식별자만 같다면 동일한 Entity"라고 판단할 수 있는 것이다.
즉, "User1"이라는 Entity를 User A와 User B라는 다른 변수 이름에 저장했다 하더라도 두 객체는 동일한 식별자를 가질 것이고 JPA에서는 이 식별자를 통해 객체를 구분하기 때문에 결국은 동일한 객체로 판단하는 것이다.
따라서 a==b를 "true"로 판단하는 것이다.
결국, JPA에서는 식별자가 같은 객체에 대하여 처음 DB에 조회한 데이터와 동일한 Entity를 반복적으로 뿌려주기 때문에 동일한 Reference(주솟값)을 가지게 되며, 이러한 특징을 "Entity 동일성 보장"이라고 한다.
상당히 재미있는 특징이며 동일한 Entity에 대해서는 변수를 계속 선언해줘도 최종적으로는 1개의 레퍼런스에 대해 수행하는 것이기 때문에 모든 변경점을 한 번에 적용할 수 있다는 점에서 매우 편리한 특징이라고 생각한다.
쓰기 지연(Entity 저장)
JPA의 큰 장점 중 하나는 쓰기 지연을 통해 최대한 SQL 쿼리문을 한 번에 처리하기 때문에 Connection을 빌려오는 과정을 최대한 줄여 시간을 줄일 수 있다는 점이다.
그렇다면 이 "쓰기 지연"이라는 것은 무엇이고, 영속성 컨텍스트에서는 어떻게 이를 구현했을까?
내가 A, B, C라는 데이터를 모두 저장해야 한다고 가정하자. MyBatis나 SQL문은 주로 A 데이터를 저장하고 순차적으로 B, C 데이터를 저장하는 방식을 선택한다. 이 경우 데이터를 저장하는 과정 때마다 Connection Pool에서 Connection을 빌린 후 반납하는 과정이 수행되는데 만약 데이터가 수백, 수천 개라면 이 과정 또한 무시할 수 없는 시간적 손해가 될 것이다.
JPA는 "쓰기 지연"이라는 기능을 통해 이 문제를 해결했다.
쓰기 지연은 DB에서 실행시켜야 할 Query문들을 임시 저장소에 모아놨다가 Transaction을 Commit 할 때 저장소에 모여 있던 Query문을 한 번에 처리해 버리는 방식을 말한다.
이 방식은 Connection을 1번만 빌려오면 되기 때문에 데이터의 개수와 상관없이 시간적으로 많은 이점을 가지게 된다.
위 예시를 들자면 A, B, C 데이터를 저장하는 INSERT Query문을 한 번에 처리하는 것이다.
그렇다면 쓰기 지연을 영속성 컨텍스트에서 어떻게 수행하는지에 대해 알아보자
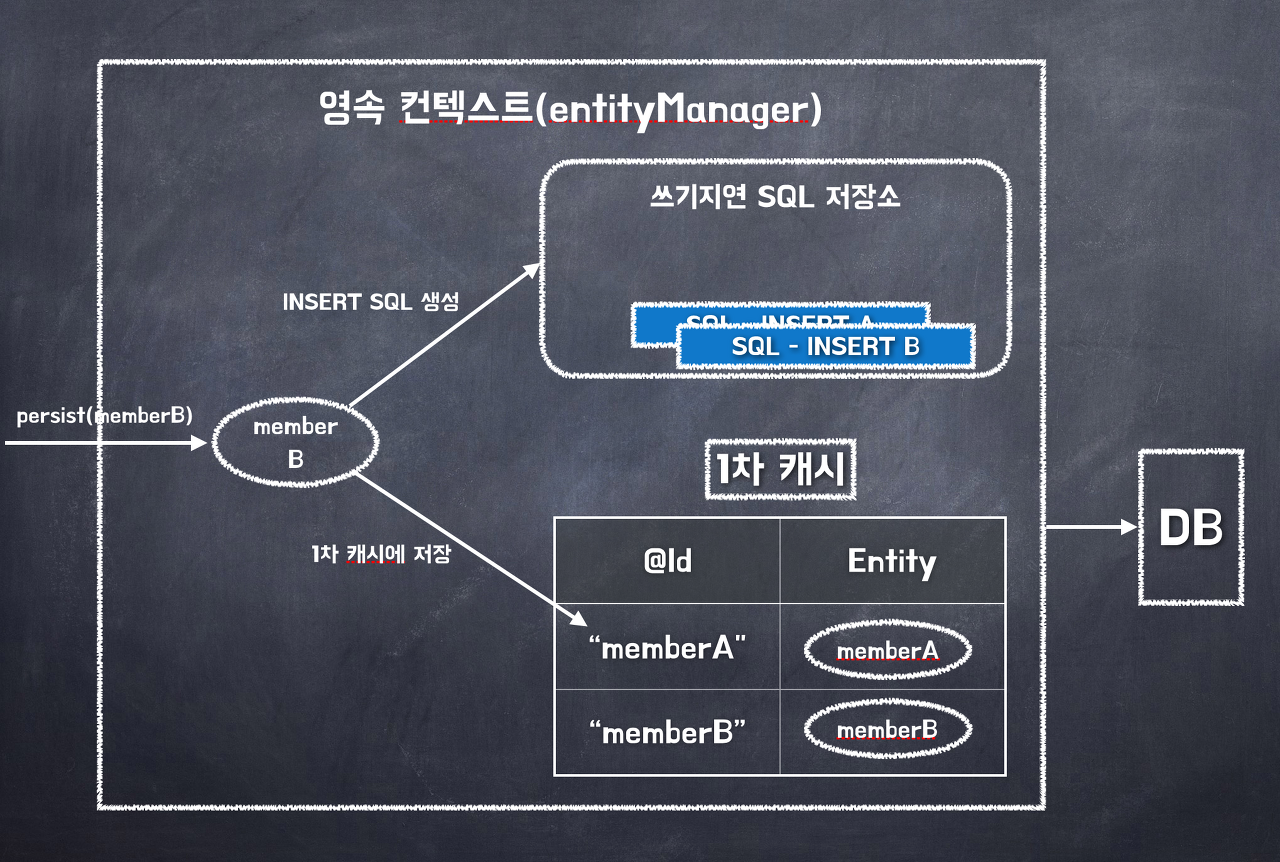
먼저 DB에는 memberA, memberB에 대한 데이터가 저장되어 있지 않다고 가정하자.
Client는 memberA와 memberB라는 데이터를 저장하고 싶은 상황이다. 이때 영속성 컨텍스트에서는 식별자와 Entity 쌍을 1차 캐시에 저장시킨 이후 해당 Entity를 DB에 저장시키는 과정까지 수행해야 함을 인지한다.
이때 1차 캐시에는 바로 Entity를 등록시키지만, DB에 memberA와 memberB 데이터를 저장시키는 Query문을 바로 실행하지는 않는다. 대신 영속성 컨텍스트 내에 존재하는 "쓰기 지연 SQL 저장소" 공간에 INSERT A와 INSERT B에 대한 Query문들을 저장해 놓는다.
즉, 이 상태에선 DB에는 memberA와 memberB라는 데이터가 실제로는 존재하지는 않지만 JPA에서는 1차 캐시에서 선행적으로 Entity가 존재하는지 Search 하기 때문에 애플리케이션 입장에서는 마치 DB에 해당 데이터가 존재하는 것처럼 행동할 수 있게 되는 것이다.
이제는 Transaction이 종료되었을 때 어떤 상황이 발생하는지 알아보자
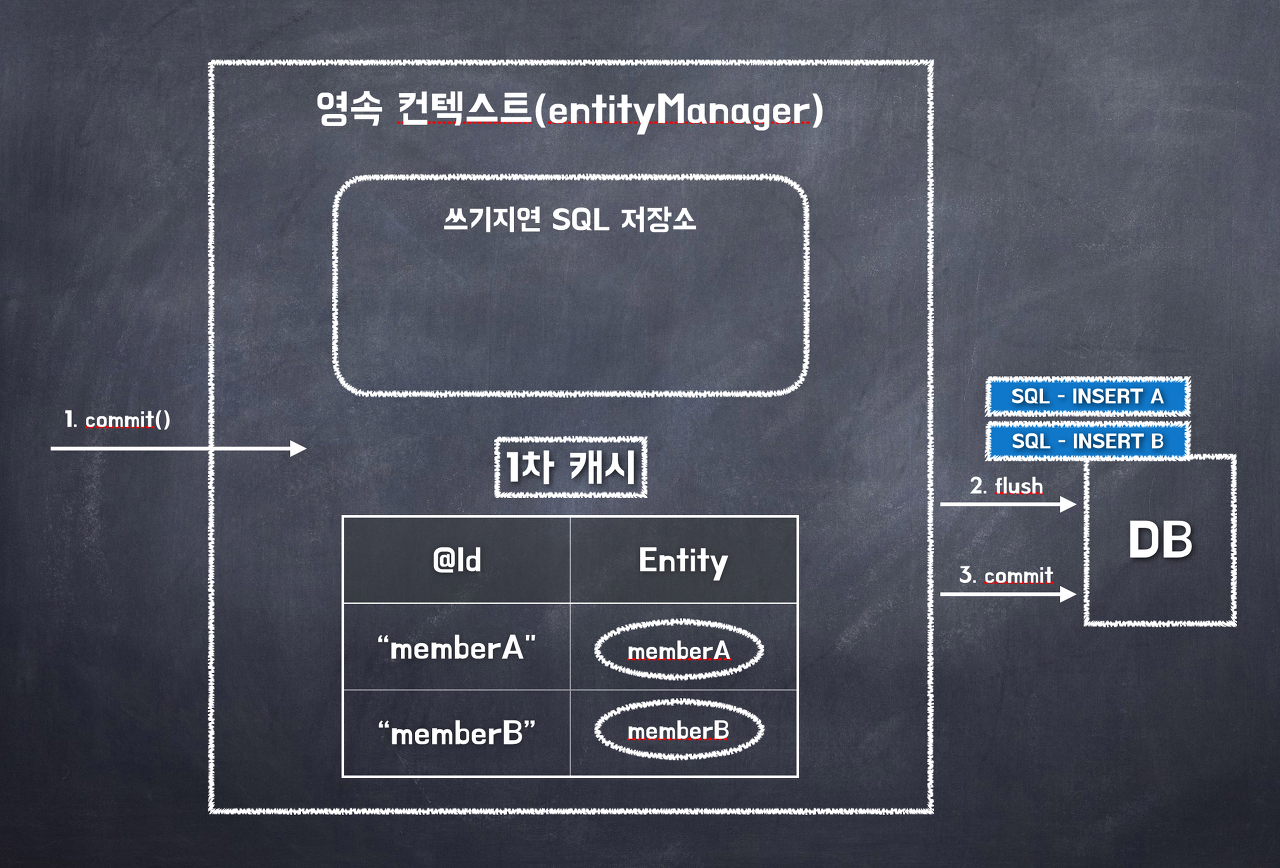
여기서 위에서 배웠던 "flush"라는 과정이 나타나게 된다.
먼저, transaction에 Commit 명령을 수행하면 이 명령은 영속성 컨텍스트로 흘러가게 된다. 영속성 컨텍스트는 commit 명령을 받으면 쓰기 지연 SQL 저장소에 저장되어 있던 모든 SQL 구문들을 flush를 통해 실행시키게 된다.
이전에 말했듯 flush는 영속성 컨텍스트 내용을 DB와 동기화시키는 과정으로써 쓰기 지연 SQL 저장소에 저장되어 있던 Query문을 실행시켜 내가 원하는 상태의 DB로 동기화시키는 과정도 수행한다.
flush를 통해 INSERT문을 모두 시행시켰다면 영속성 컨텍스트는 commit 메서드를 통해 DB 변경점을 확정시킨다.
즉 INSERT A와 INSERT B 구문을 실제 DB에 저장시켜 DB에 데이터를 저장하는 것으로써 쓰기 지연의 과정이 완료되는 것이다.
꼭 기억하자. "flush를 통해 쓰기 지연 SQL 저장소에 저장되어 있던 Query를 수행시킨" 이후에 "commit을 통해 변경점을 적용하는" 과정이 쓰기 지연을 통해 일어나는 것이다.
Entity 수정(변경 감지; Dirty Checking)
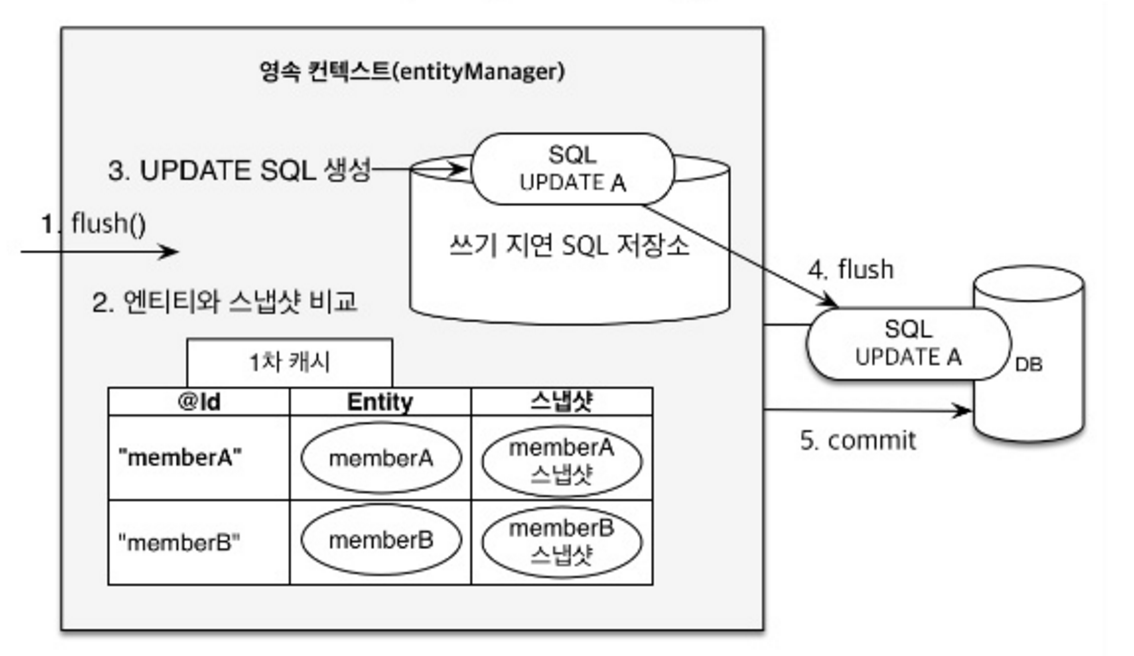
이전에 말했듯 JPA는 수정에 대한 메서드가 따로 존재하지 않는다. 그냥 1차 캐시에 저장된 Entity에 접근한 이후 해당 Entity의 값을 바꾸면 자동으로 데이터에 대한 수정 처리가 수행된다.
그렇다면 JPA(영속성 컨텍스트)는 어떻게 이 과정을 수행하게 될까?
영속성 컨텍스트는 변경 감지(Dirty Checking) 기능을 통해 DB에 수정사항을 적용한다.
이때 먼저 Snapshot(스냅샷)이라는 개념을 먼저 알아야 한다.
DB에 처음 데이터를 뽑아온 상태의 객체가 존재할 것이다. JPA는 이를 "스냅샷" 공간에 저장한다.
위 사진을 보면 memberA라는 Entity와 memberA 스냅샷이라는 2개의 객체가 저장됨을 알 수 있다. memberA Entity는 "내가 실제로 변경하거나 활용할 Entity"이며 memberA 스냅샷은 DB에서 처음 데이터를 추출한 정보를 가지고 있는 객체이다.
자, 그렇다면 Dirty Checking은 이 스냅샷을 어떻게 활용할까?
먼저, 영속성 컨텍스트에 "flush" 요청이 들어가게 된다. 계속해서 말하지만 flush의 목표는 영속성 컨텍스트의 Entity 상태와 DB에 저장된 데이터 상태를 동기화시키는 것이다. 즉, Entity의 변경점이 존재한다면 이를 실제 DB에 적용시키는 것도 flush의 역할인 것이다.
따라서 flush 명령이 들어올 경우 영속성 컨텍스트는 모든 Entity에 대하여 스냅샷과 Entity를 비교하게 된다. 만약 Snapshot과 Entity 상태를 비교했을 때 변경사항이 존재한다면 이 변경사항을 실제 DB에 적용시키기 위해 Update Query문을 생성하여 쓰기 지연 SQL 저장소에 저장시킨다. 모든 비교 과정이 완료되고 Update 쿼리문이 쓰기 지연 SQL 저장소에 저장되었다면 flush가 다시 호출된다. 이 flush는 쓰기 지연 SQL 저장소에 쌓여있는 Query문을 실제 DB에 적용시키는 과정을 수행하는데, 이때 당연히 생성했던 Update Query문도 실행되어 실제 DB에 적용될 것이다.
마지막으로 Commit을 통해 Transaction 변경사항을 DB에 적용시킨다면 변경 감지를 통한 Update 로직 수행이 완료되는 것이다.
JPA는 기본적으로 "모든 필드"를 Update 하는 방식을 선택한다.
예를 들어 (1, A, 010-1111-1111)이라는 데이터가 (1, B, 010-1111-1111)이라는 데이터로 변경되었을 때 A -> B에 대한 Update 쿼리문을 형성하는 것이 아닌 (1, B, 010-1111-1111)이라는 데이터로 변경되었다는 Update Query를 형성하는 것이다.
왜 이런 비효율적인 방법을 사용하나 싶겠지만, 이는 "속도 향상"에 도움을 주기 때문에 채택한 방식이다.
만약 Column 값마다 Update 쿼리문을 형성한다면 Update 쿼리가 생성될 때마다 새로운 Update문을 형성해야 할 것이다. 하지만 모든 필드를 사용한 Update Query문을 사용하면 항상 동일한 Update Query를 사용하게 될 것이며(데이터만 변수로 적용해주면 될 것이다) 아예 Update Query를 Parsing 하여 활용해 Parsing 된 쿼리를 재사용하여 속도 향상이라는 이점을 가지고 오기 때문이다.
하지만 Field가 너무 많거나 저장되는 내용이 너무 클 경우 "수정된 데이터"만 포함한 Update SQL 구문을 생성하여 활용하는 것이 더 좋을 수도 있다.
이 경우 Hibenrate의 확장 기능인 "@org.hibernate.annotation.DynamicUpdate" 어노테이션을 Entity 클래스에 붙여주면 된다.
Entity 삭제
Entity 삭제는 매우 간단한 방식이다. Entity 수정과 비슷한 방식인데, 그냥 영속성 컨텍스트 내에 삭제할 Entity가 존재하지 않으면 1차 캐시에 스냅샷에는 존재하지만 Entity는 존재하지 않는 상태가 되어 삭제되어야 함을 인지하고 DELETE문을 생성하여 실행하게 되는 것이다.
삭제 과정 또한 당연히 Entity가 1차 캐시에 선행적으로 등록되어야 한다. 그리고 remove() 메서드를 수행하면 객체는 영속성 컨텍스트에서 제거되어 준영속 객체 상태가 되며 이후 엔티티처럼 활용할 수 없게 되는 것이다.
Transaction에 따른 영속성 컨텍스트
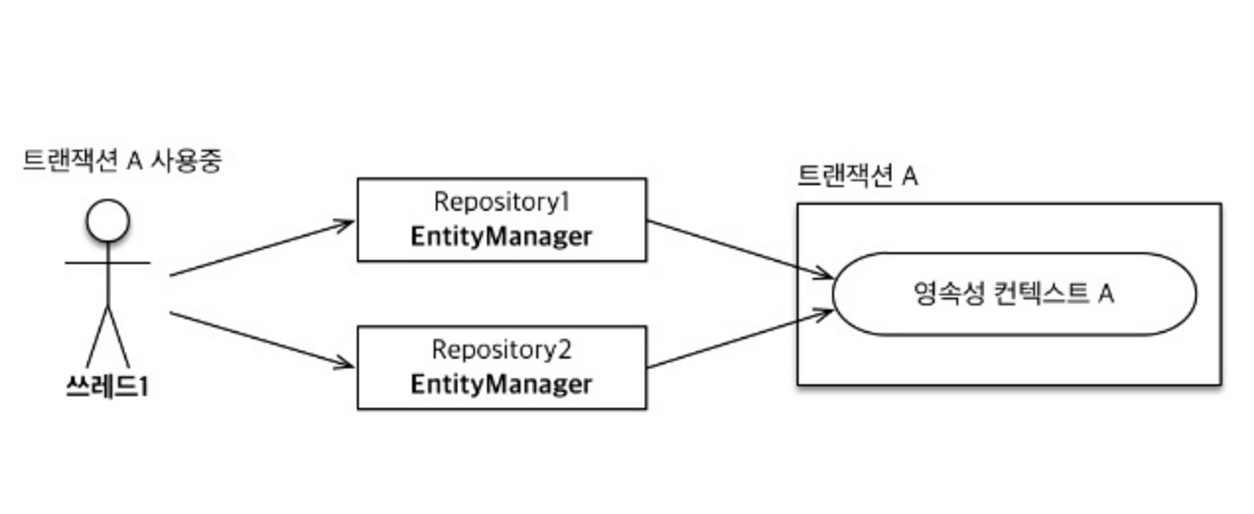
같은 Transaction 사용
다른 Transaction 사용
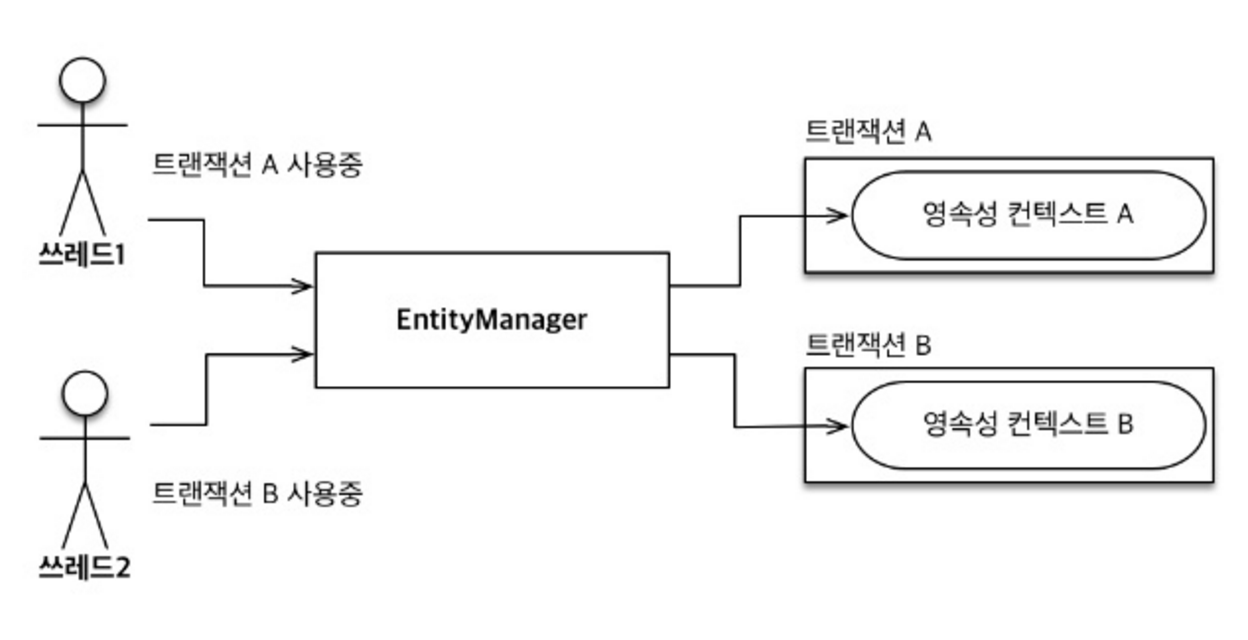
위 2개 사진을 보면 Spring Container는 Thread(Transaction)마다 다른 영속성 컨텍스트를 할당함을 알 수 있다.
이유는 "안전성" 때문이다.
동일한 Transaction일 경우 로직이 "순차적"으로 일어난다. 따라서 여러 가지 Repository(EntityManager)를 활용하더라도 Transaction에서 충돌이 날 위험성은 존재하지 않는다.
하지만 여러 가지의 Transaction이 사용될 때는 상황이 다르다.
Thread1에서는 A라는 User 데이터를 변경하고 있고 Thread 2에서는 B라는 User 데이터를 변경하고 있다고 가정하자.
그런데 만약 영속성 컨텍스트를 공유하면 어떻게 될까?
예를 들어, A라는 user가 패스워드를 변경했다고 가정하자. 그리고 영속성 컨텍스트를 공유하고 있으니 B의 영속성 컨텍스트에도 A가 변경한 User의 패스워드가 적용될 것이다.
그런데 이때 Transaction B에서 flush 이후 Commit 요청이 수행되었다. 그렇다면 A의 변경된 패스워드는 DB에 적용될 것이다. 그런데 A User가 무언가를 잘못 입력하여 Password 변경이 취소되었다고 가정하자. 그리고 A는 투덜대면서 다시 패스워드를 입력할 것이다. 그런데 A는 이전 패스워드를 입력했고, 실제로 A는 변경된 패스워드를 적용시킨 적이 없기 때문에 기존 패스워드가 일치해야 한다. 하지만 Thread 2(Transaction B)에 의해 변경된 패스워드가 저장되었기 때문에 A의 의사와는 관계없이 User A의 비밀번호는 변경되어 버린 것이다.
이런 Transaction 사이의 독립성 유지에 큰 위협이 되기 때문에 Thread가 다를 경우 무조건 Thread마다 고유한 영속성 컨텍스트를 가지고 있어야 하는 것이다.
