실습은 구글 colab 에서 진행 하였습니다.
목표
- 머신러닝 라이브러리인 sklearn의 사용법 숙지
- 머신러닝 모델링을 직접 해보기
- 비만도 데이터를 기반으로 학습하고 예측하는 모델 만들기
모델정의
# KNN알고리즘으로 학습하는 모델을 사용
from sklearn.neighbors import KNeighborsClassifier ## KNN 클래스
bmi_model = KNeighborsClassifier(n_neighbors=5) # 가장 가까운 이웃 수
모델 학습
#데이터 불러오기
# 1. 판다스 import
# 2. csv파일 로딩
# 3. 위쪽 5개 살펴보기
import pandas as pd
l = pd.read_csv('./data/bmi_lbs.csv')
l.head()
# 비만도 컬럼의 종류를 확인해보자.
#l['Label'].value_counts()
l['Label'].unique()# 몸무게를 파운드 -> kg단위로 변경
l['Weight(kg)'] = l['Weight(lbs)'] * 0.453592
l.head()
# 기술 통계 확인
l.describe()
# 문제와 답을 분리
X = l[['Height' , 'Weight(kg)']]
y = l['Label']
bmi_model.fit(X,y)모델예측
# 샘플데이터 추출
X_sample = l.iloc[[10, 76, 111, 342, 485], [2,4]]
X_sample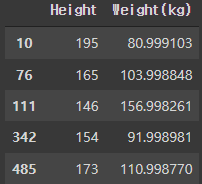
y_sample = l.iloc[[10, 76, 111, 342, 485], 0]
y_sample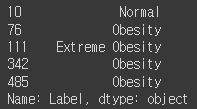
pre = bmi_model.predict(X_sample)
pre
모델평가
# 모델평가 함수 활용하기
from sklearn.metrics import accuracy_score # 정확도(전체중에서 정확히 맞춘 비율)
score = accuracy_score(y_sample, pre)
score문제점
- 500명의 비만도 데이터를 학습하고 그중에 5명을 추출해서 평가를 진행하는 방법은 옳지않다.
- 이미 모델이 500명에대해서 학습했기 때문에 상대적으로 추출한 5명을 잘 맞출 확률이 높다.
- 그래서 머신러닝에서는 훈련용데이터와 평가용데이터를 사전에 구분해서 활용한다.
일반적으로 비율은 7:3 으로 활용한다.
from sklearn.model_selection import train_test_split # 훈련용, 평가용 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=219)
X_train.head()
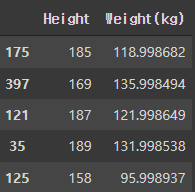
X_train.shape, y_train.shape
X_test.shape, y_test.shape
# 모델 정의 > 모델학습 > 모델예측 >모델예측
bmi_model2 = KNeighborsClassifier()
bmi_model2.fit(X_train,y_train)
pre2 = bmi_model2.predict(X_test)
score2 = accuracy_score(y_test, pre2) # 모델이 예측한 값과 테스트값 비교
score2

# 모델 활용
bmi_model2.predict([[175,70]])
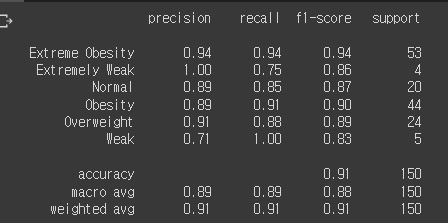
평가지표
- precision(정밀도) : 모델이 해당 클래스로 예측한 것에 대한 정확도
- recall(재현율) : 실제 해당 클래스에대해서 맞춘 비율
- f1-score
- ROC
from sklearn.metrics import classification_report
print(classification_report(y_test ,pre2))