1. Introduction
LLM & Continual Learning
인간은 새로운 정보를 받아들이고 기존 지식과 통합하며 이를 상황에 맞게 활용할 수 있는 능력을 지님.
LLM이 인간 수준의 지능에 도달하기 위해서는 이러한 지속적인 학습(Continual Learning) 능력이 필수적임.
그러나 LLM은 파라미터(Parametric) 기반 구조의 한계를 지님.
새로운 정보를 학습할 때마다 전체 모델을 재학습해야 하며, 이 과정에서 과거의 정보를 잊어버리는 Catastrophic Forgetting이 발생함.
RAG의 등장과 한계
이를 극복하기 위해 RAG(Retrieval-Augmented Generation)이 등장함.
RAG는 외부 지식 소스를 참조하는 Non-parametric 방식으로, LLM이 새로운 지식을 빠르게 확장할 수 있는 단순하면서도 강력한 방법론임.
하지만 기존 RAG는 주로 Vector Retrieval에 의존함.
이로 인해 인간의 장기 기억(Long-term Memory)의 두 가지 핵심 특성을 반영하지 못하는 한계를 지님.
- Sense-making: 불확실하거나 모호한 문맥을 종합적으로 해석하고 이해하는 능력
- Associativity: 서로 관련 없어 보이는 정보들 간의 연결성을 파악하고 추론하는 능력
Advanced RAG의 시도와 과제
기존 RAG의 한계를 극복하기 위해 다양한 Advanced RAG 기법들이 제안됨.
- GraphRAG: 지식 그래프(KG)를 기반으로 지식 구조를 생성하여 Sense-making 능력을 강화하고자 함.
- HippoRAG: 지식 그래프와 Personalized PageRank(PPR) 알고리즘을 결합하여 Multi-hop 추론을 가능하게 함으로써 Associativity 능력을 개선하고자 함.
그러나 이러한 Advanced RAG들은 특정 능력에서는 향상된 성능을 보였으나, 기본적인 QA 성능에서는 오히려 Naive RAG보다 떨어지는 결과를 보임.
이 논문의 기여 (Contribution)
본 논문은 기존 한계를 극복하기 위해 HippoRAG2를 제안함.
HippoRAG2는 다음과 같은 구성 요소를 포함함.
- PPR (Personalized PageRank)
- KG (Knowledge Graph)
- Query-based Contextualization
- Deep Passage Integration
이를 통해 HippoRAG2는 다음 영역에서 성능 향상을 목표로 함.
- 더 나은 사실 기반 기억 (Better Factual Memory)
- 향상된 의미 파악 능력 (Sense-making)
- 강화된 연관 추론 능력 (Associativity)
2. Related Work
LLM을 위한 지속적인 학습 (Continual Learning for LLMs)
LLM이 새로운 지식을 지속적으로 학습하면서 기존 지식을 보존하는 능력의 중요성이 점점 커지고 있음.
1) Continual Fine-Tuning
- 장점: 새로운 언어 패턴이나 추론 능력을 효과적으로 학습할 수 있음.
- 단점: 연산 비용이 매우 크며, Catastrophic Forgetting 문제 발생함.
2) Model Editing
- 장점: 특정 지식만 선택적으로 업데이트 가능하여 경량화된 학습이 가능함.
- 단점: 국소적(Local) 수정에 그치므로 연관된 지식까지 반영하지 못함.
3) Retrieval-Augmented Generation (RAG)
- 장점: 비-파라미터 방식으로 외부 지식을 활용하므로 실시간 적응성과 확장성 측면에서 강점이 있음.
Non-parametric 방식의 지속적 학습
최근 LLM 기반 Encoder 성능의 발전으로 정교한 임베딩 생성이 가능해지면서 RAG의 성능이 크게 향상되었음.
그러나 여전히 다음 두 가지 과제가 남아 있음.
1) Sense-making (복잡한 문맥 이해)
- 문제: 기존 RAG는 여러 문서를 유기적으로 연결하여 복합적인 문맥을 종합적으로 이해하기 어려움.
- 해결 시도: RAPTOR, GraphRAG, LightRAG 등 → 계층적 클러스터링(Hierarchical Clustering) 또는 지식 그래프 활용.
- 남아 있는 과제: 요약 및 구조화 과정에서 LLM이 불필요한 노이즈(Noise)를 생성하여 QA 성능이 저하되는 현상 발생.
2) Associativity (다중 연결 추론 능력)
- 문제: 벡터 기반 검색은 독립적인 결과만 반환하므로 여러 정보 간의 연관성 파악이 불가능함.
- 해결 시도: 지식 그래프(KG)와 Personalized PageRank(PPR)를 활용한 Multi-hop 추론 연구들이 제안됨.
3. Method of HippoRAG2
1. Overview
- LLM
- KG + PPR
- Retrieval Encoder
⇒ 위를 합쳐 HippoRAG 생성
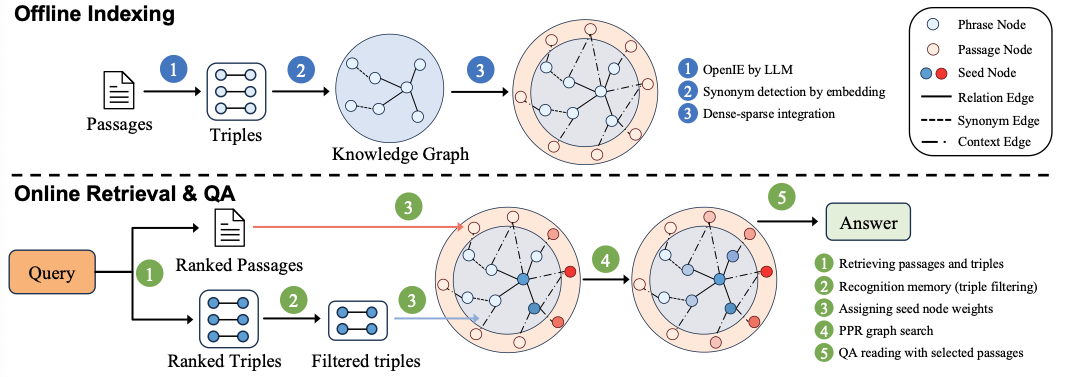
Flow
-
Offline Indexing

-
Triple 추출: LLM으로 passage를 KG triple로 변환 → KG 구성
- 주어·목적어: phrase
- 연결어: edge
-
Synonym 연결: KG 내 phrase node 간 임베딩 유사도 계산 → synonym edge 생성 → 지식 연결성 향상
-
Context 정보 통합: triple 기반 KG + 원문 passage 결합 → context-rich KG 구성
⇒ 개념과 문맥 통합을 통해 정보의 완전성과 정합성을 향상시킴
-
-
Online Retrieval

- Query Mapping: query를 KG triple/passage와 연결 → seed node 후보 탐색
- Triple Filtering: LLM이 query와 관련된 triple만 선택
- PPR 그래프 탐색: 필터링된 시드 노드 기반 Personalized PageRank 수행 → 관련 passage 추출
- 최종 QA: 추출된 passage를 QA 모듈 입력으로 사용
3.2 Dense-Sparse Integration
- KG phrase node: 개념 중심 → sparse coding
- Context: 문맥은 풍부하지만 복잡 → dense coding
⇒ 개념-문맥 trade-off 문제 해결을 위해:
- KG에 passage node 도입
- passage는
containsedge를 통해 phrase node와 연결
KG phrase node → is contained → passage node
→ KG가 개념과 문맥을 함께 표현하는 복합 정보 구조가 됨
3.3 Deeper Contextualization
기존 HippoRAG1는 쿼리를 KG와 연결할 때 NER 기반 방식만 사용
- 문제점
- 개념 중심 편향: 개별 엔티티에만 집중 → 전체 맥락 반영 부족
- 문맥 신호 손실: 쿼리 의도·문장 구조 무시
- 추론 한계: multi-hop, 논리적 연결 필요 시 성능 저하
| 방식 | 설명 | 한계 |
|---|---|---|
| NER to Node | 쿼리 → 엔티티 → phrase node 매핑 | 개념 중심 편향, 문맥 반영 부족 |
| Query to Node | 쿼리 → phrase node 직접 매핑 | phrase node 자체가 단편적 개념 |
| Query to Triple | 쿼리 ↔ triple 전체 임베딩 매칭 (top-k triple) | triple은 관계까지 포함 → 쿼리의 의도·구조·문맥까지 반영 가능 |
3.4 Recognition Memory
인간 기억 체계에서 착안:
- Recall: 외부 단서 없이 기억 꺼내기
- Recognition: 외부 단서를 보고 기억 떠올리기
⇒ HippoRAG2는 query-to-triple 과정을 두 단계로 나눔
- Query to Triple
- 쿼리를 KG triple과 임베딩 기반 비교
- top-k triple 후보 T 추출
- Triple Filtering
- LLM이 후보 triple 중 query와 관련성 높은 것만 선택
- 최종 triple 집합 생성
3.5 Online Retrieval
-
Seed Node 선택
- Triple 존재 시: 필터링된 triple에서 phrase node 추출
- 명사 노드만 PPR 가능
- 최대 K개의 phrase 추출 → 평균 순위 점수 반영
- Triple 부재 시: dense retriever로 top-k passage 직접 검색
- 모든 passage node를 시드 노드로 추가 → broader activation → multi-hop 추론에 효과적
- Triple 존재 시: 필터링된 triple에서 phrase node 추출
-
Reset Probability 할당
- Phrase node: triple 기반 순위 점수 사용
- Passage node: 임베딩 유사도 × weight factor 적용
- 두 노드 간 영향력 균형 조절
-
PPR 실행
- 시드 노드 & reset score 기반 Personalized PageRank 수행
- 각 passage node의 pagerank 점수 계산
-
Top-ranked Passage 선택
- PPR 결과 상위 passage를 최종 QA 입력으로 사용
PPR이란?
- PageRank: 연결 관계 기반으로 노드 중요도를 계산하는 알고리즘
- 더 많은 링크를 받거나 중요한 노드로부터 링크된 노드는 중요도가 높음
- 무작위로 링크를 따라가다 일정 확률로 다시 시작하는 방식
- Personalized PageRank: 특정 seed nodes에서의 reset-score를 높게 설정하여, 집중하고자 하는 노드 주변만 탐색할 수 있도록하는 node-ranking method
Reset Score: seed node로 돌아갈 확률을 나타내는 Score
4. Experiment
1. Baseline
실험에서는 다양한 검색기(retriever)와 구조적 RAG 기법들을 비교 대상으로 설정함.
-
Simple Baselines: 전통적 검색기
- BM25: 단어 빈도 기반 전통적 검색
- Contriever: 대조 학습 기반 dense retriever
- GTR: T5 기반 dense dual encoder
-
Large Embedding Models
- GTE-Qwen2-7B-Instruct
- GritLM-7B
- NV-Embed-v2
-
Structure-Augmented RAG
- RAPTOR: Hierarchical Clustering을 활용하여 문서를 의미 기반으로 그룹화 후 요약
- GraphRAG: Knowledge Graph 기반 문서 구조 활용
- LightRAG: KG + Vector Retrieval 결합
- HippoRAG: KG + PPR 결합
2. Dataset
- Simple QA: 실제 사용자 검색 기반 질의 + 위키피디아 데이터
- Multi-hop QA: 여러 개의 정보를 연결해야 하는 추론 능력(Associativity) 측정
- Discourse Understanding: 긴 문맥 이해(Sense-making) 능력 평가
3. Metrics
- Retrieval 성능: Passage Recall@5(Gold-doc을 잘 검색하는지)
- QA 성능: Token-level F1 Score
4. Results
-
QA 성능
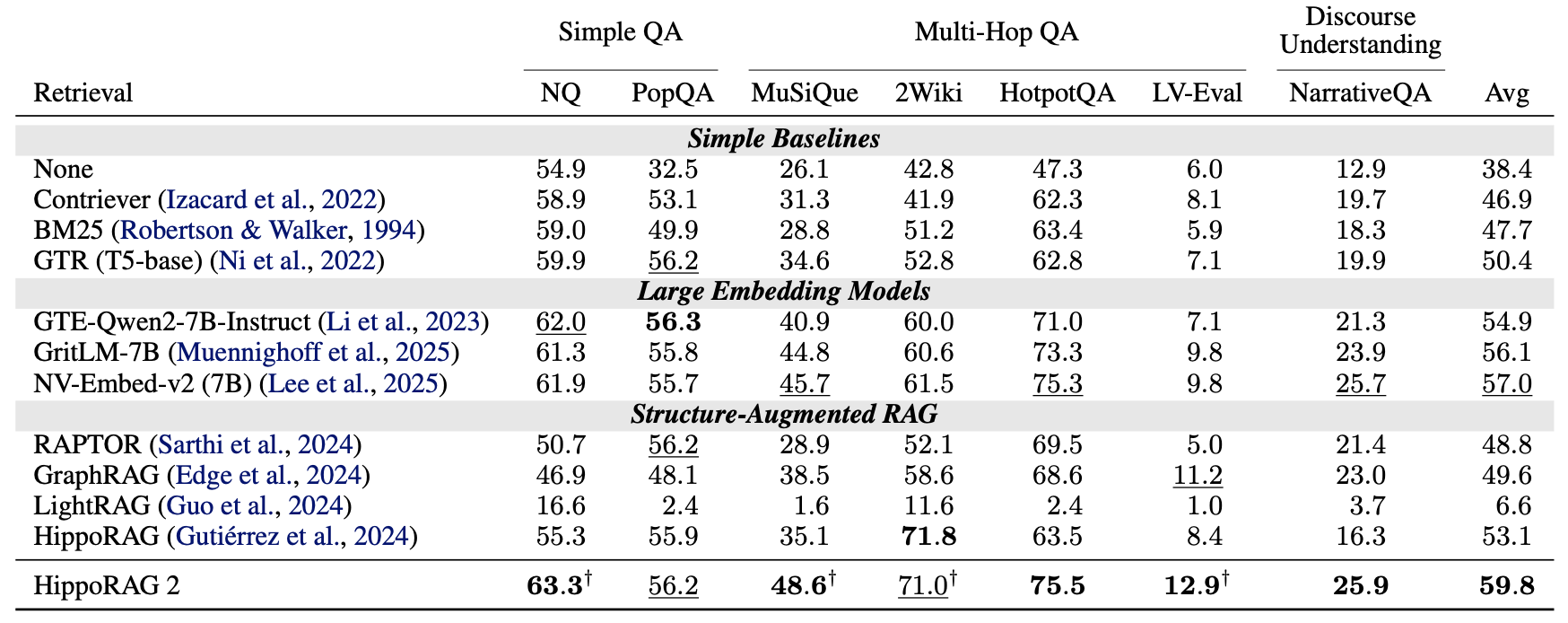
- Generator: LLaMA
- Retriever: NV-Embed-v2
- 결과: HippoRAG2가 다양한 QA Task에서 전반적으로 더 높은 성능을 보임
-
Retrieval 성능
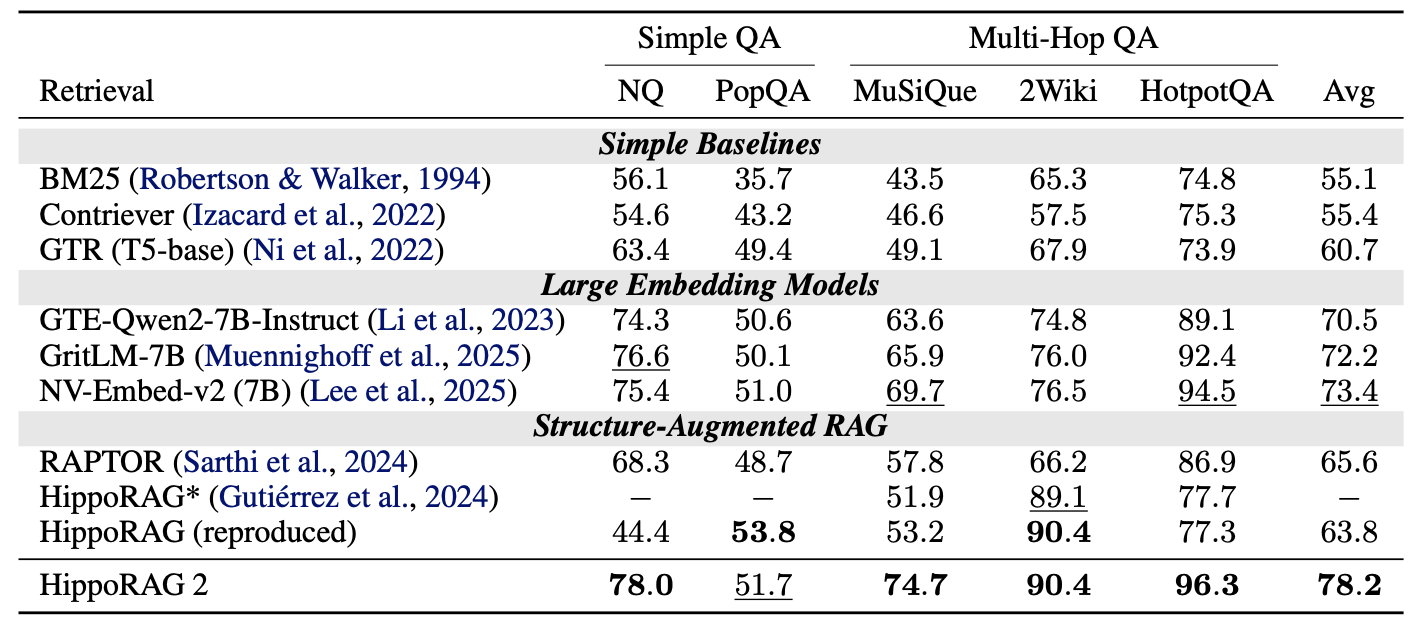
- Passage Recall@5 기준으로도 HippoRAG2가 기존 방법들보다 향상된 결과를 보임
-
Ablation Study
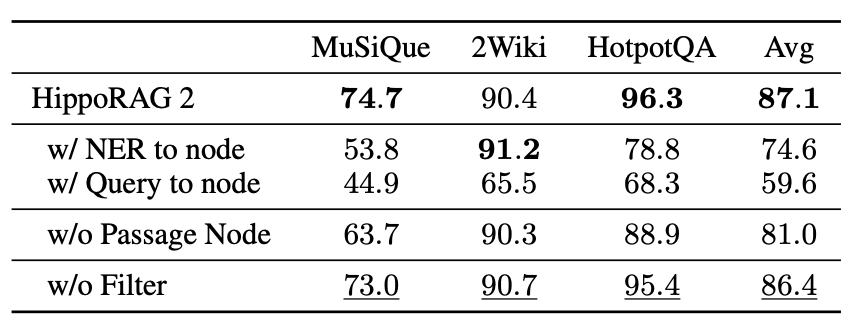
- Passage Node 제거 시 → Multi-hop QA 성능 크게 하락 (KG 확산 범위 축소 때문)
- Triple Filtering 제거 시 → 성능 소폭 저하 발생
- Reset Weight Factor 분석
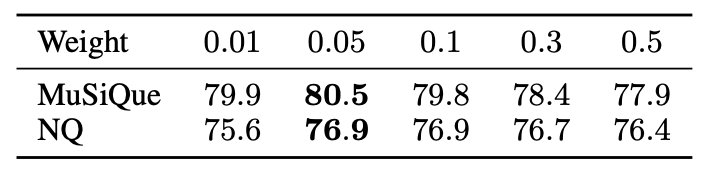
- Passage node의 reset 확률에 가중치를 곱하여 조정
- Weight factor = 0.05일 때 가장 안정적이며 높은 성능 확보
5. Continual Learning 실험
- 구성
- NQ와 MuSiQue Dataset을 4개로 분할
- 1개 분할로 평가하고, 나머지를 점진적으로 corpus에 추가하여 성능 변화 추적
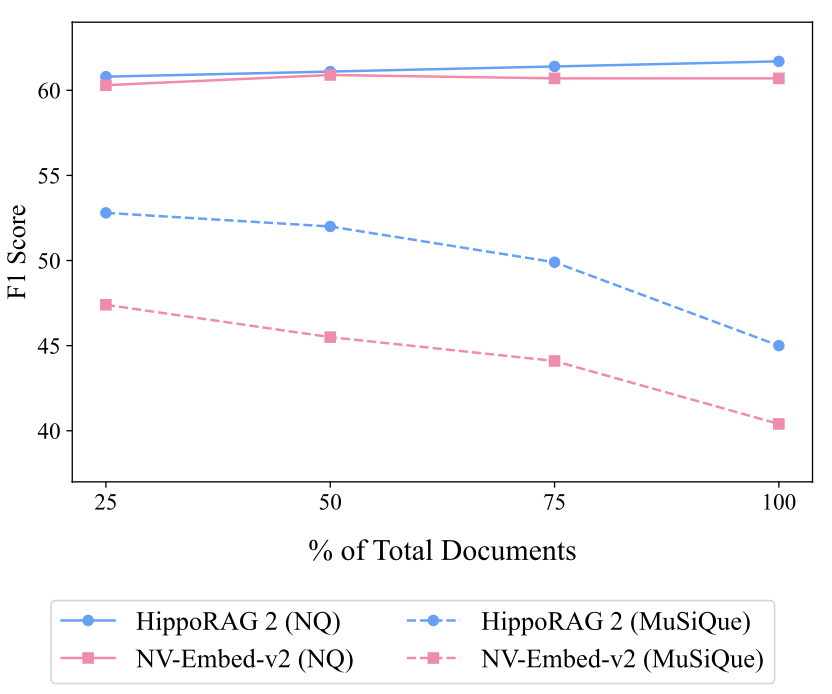
- 결과
- Corpus 확장 시에도 성능이 꾸준히 유지됨
- Multi-hop QA의 경우 전체 성능 하락폭이 NV-Embed-v2와 유사
- 즉, HippoRAG2는 장기적 관점에서 Continual Learning에 강한 모델임
6. Think myself
이 논문을 읽으면서 가장 크게 와닿았던 점은, RAG의 진화가 단순히 "검색 정확도를 높이는 것"을 넘어서, 인간 기억 구조를 어떻게 모사할 수 있는가에 초점을 두고 있다는 것이다.
특히 HippoRAG2는 단순히 KG + PPR을 붙인 것이 아니라 "연관성 있는 것을 상상하고 연결하는" 인간과 유사한 검색 방식을 도입하려 한 것이 인상 깊었음.
- Dense-Sparse 통합을 통해 개념과 문맥의 균형을 잡으려 한 점
- Query-to-Triple 매핑으로 쿼리의 맥락을 더 깊게 반영하려 한 점
- 인간 기억 메커니즘인 Recognition Memory 개념을 도입한 점
실험 파트
- multi-hop QA에서 passage node의 존재가 성능 향상에 결정적이라는 부분은, "문맥 정보와 개념적 구조를 함께 봐야 한다"는 것을 상기하게 됨
- Continual Learning 실험에서, 새로운 데이터를 추가하면서도 LLM이 성능을 유지하는 것으로 보아, long-term memory 기반 RAG에 중요한 reference가 될 것이라는 생각을 하게 됨.
