ResNet : Deep Residual Learning for Image Recognition 논문 링크
Overview
심층 CNN은 이미지 분류에서 큰 성과를 내왔고, 16~30층 수준의 매우 깊은 모델이 선도 성능을 보여왔다. 그러나 초기화·BN으로 기울기 문제를 완화해도, 깊어질수록 퇴화(degradation)가 나타나 정확도가 포화·저하되고 더 깊은 모델의 훈련 오류가 오히려 커지는 문제가 발생한다.(과적합이 원인 아님)
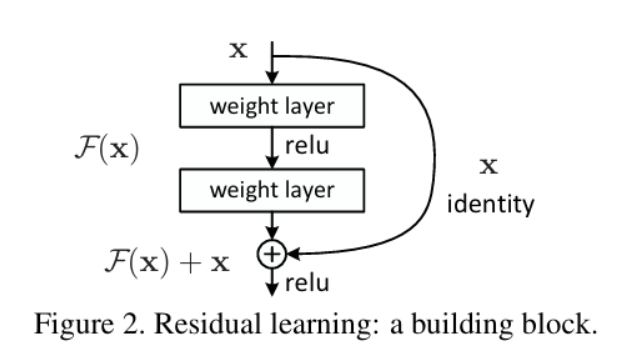
본 논문은 이를 잔차 학습으로 해결한다. 목표 H(x)를 직접 학습하지 않고 잔차 F(x)=H(x)-x를 학습해 출력을 y=x+F(x)로 두며, 항등 지름길(shortcut)로 기울기 경로를 항상 열어 둔다. 이 방식은 추가 파라미터/연산 거의 없이 최적화를 쉽게 만들어, 깊이를 크게 늘려도 성능 향상을 보인다.
결론적으로, 잔차 학습은 깊은 네트워크의 퇴화 문제를 구조적으로 해소하고, 극도로 깊은 표현을 실제로 학습 가능하게 만들어 다양한 시각 과제에서 최고 성능을 달성한다.
Related Work
잔차 표현 (Residual representations)
이미지 인식에서 VLAD과 Fisher Vector는 코드북(사전)에 대한 잔차 벡터로 이미지를 인코딩하며, 벡터 양자화에서도 원본 대신 잔차를 인코딩하는 편이 더 효과적인 것으로 알려져 있다. 다만 이는 피처 인코딩(얕은 표현) 단계의 잔차 사용이다. ResNet은 한 단계 더 나아가 학습 대상 함수 자체를 잔차로 두며 F(x)=H(x)-x, y=x+F(x) 형태로 모델을 재정의한다.
다중격자(Multigrid)·계층적 기저 사전조건화
PDE 해법의 다중격자는 문제를 여러 스케일의 하위 문제로 쪼개고, 각 단계가 거친-세밀 스케일 간 잔차를 푼다. 계층적 기저 사전조건화도 두 스케일 간 잔차 벡터를 명시적으로 다뤄 수렴을 가속한다. "문제를 잔차로 재정의하면 최적화가 단순해진다"는 ResNet의 철학과 통한다.
지름길 연결(Shortcut connections) 관련 선행
초기 MLP의 입력->출력 선형 연결, 중간 층을 보조 분류기에 직접 연결해 기울기 문제를 완화하는 방법, 반응/기울기/오류의 중심화, 인셉션의 지름길 분기+깊은 분기 등이 있다. 그러나 대부분은 연결 형태의 설계에 초점이었지, 블록이 항상 잔차 함수를 학습하도록 목표를 재정의하진 않았다.
Highway Networks vs ResNet
하이웨이는 게이트(매개변수 보유)가 달린 지름길로, 데이터에 따라 열림/닫힘이 결정된다. 게이트가 닫히면 항등 경로가 보장되지 않아 잔차 함수로 해석되지 않을 수 있다.
ResNet은 항등 지름길(매개변수 없음)을 항상 열어 두고, 블록이 항상 잔차 F(x)를 학습하도록 정식화한다 -> 정보/기울기가 항상 통과하여 최적화가 용이하고 깊이 확장이 쉽다.
-> Highway : 매우 깊은 영역에서 이득 제한적
-> ResNet : 더 깊은 네트워크에서 안정적 최적화·성능 향상
Deep Residual Learning
Residual Learning
- 목표 재정의 : 직접 H(x)를 학습하지 않고 잔차 F(x)=H(x)-x를 학습 -> 출력 y=x+F(x)
- 왜 쉬워지나 : 최적해가 항등에 가깝다면 F(x)=0으로 만들면 됨 -> 사전조건화 효과로 최적화 용이
- 퇴화 해결 : 깊어질수록 훈련 오류↑(=퇴화)를 잔차 학습으로 완화
- 실증 근거 : Fig.7-학습된 잔차 반응 크기가 작음(항등 근처에서 작은 보정만)
잔차 F(x) = H(x) - x => 목표 함수와 항등의 차이
(작은 보정이 유리한 이유)
-> 사전조건화 효과 : 최적이 항등에 가깝다면 F(x)≈0이 해답
-> 기울기 경로 보장 : 항등 경로가 있어 기울기가 사라지지 않음
-> 안정적 스케일업 : 큰 변환을 한 번에 하지 않고, 작은 수정들을 많이 누적하니 깊은 층까지 안정적으로 학습됨
*사전조건화 : 변수나 식을 재정의/변환해서 기울기 흐름과 곡률(컨디셔닝)을 좋게 만들고, 수렴을 빠르고 안정적으로 만드는 방법
=> '항등 + 작은 보정'을 직접 배우게 해서 깊은 네트워크도 안정적으로 학습
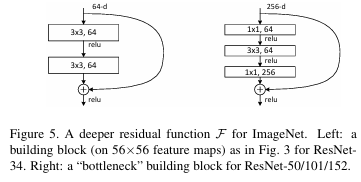
Identity Mapping by Shortcuts
- y=F(x,{Wi})+x
-> F : 보통 2~3층(Conv-BN-ReLU 스택)
-> 덧셈 이후 ReLU 한 번 더 - Shortcut(항등 경로) : 추가 파라미터/연산 거의 없음 -> plain과 공정 비교 가능
- 차원 안 맞을 때 : 1x1 Conv 사영 Ws·x로 정렬(필요할 때만)
y = F(x,{Wi})+Ws·x - 유의 : F가 1층이면 y=W1·x+x인 선형 합과 유사 -> 이점 미미
- Conv에도 동일 적용 : 덧셈은 채널별 원소합
잔차 블록 y = x + F(x)
-> 수식상 역전파 : ∂L/∂x = ∂L/∂y(I+∂F/∂x)
=> I(지름길) 덕분에 큰 수정이 없어도 기울기가 잘 흐름
1) 차원이 같을 때 : y=F(x)+x [항등 지름길]
- 형상 일치 : x와 F(x)가 같은 (C,H,W) -> 바로 원소별 덧셈 가능
- 비용 없음 : 가중치 0, 추가 연산은 덧셈뿐(미미함)
- 최적화 이점 : 역전파에 항등 항(I)이 남아 기울기 경로 보장
2) 차원이 다를 때 : y=F(x)+Ws∗x [사영 지름길, 1x1 conv]
- 형상 정렬 : 채널 수/해상도가 변하면 x를 선형 사영해 F(x)와 정확히 같은 크기로 맞춰야 덧셈이 정의됨
-> Ws : 1x1 conv(필요 시 stride s로 다운샘플링)- 정보·기울기 보존 : 0-padding(채널만 0으로 채움)과 달리, 1x1 사영은 모든 채널 정보를 학습적으로 섞어 전달 -> 모든 채널로 기울리 흐름 확보
- 효율성 : 1x1은 공간 커널이 없어 파라미터/연산 최소
=> 항등 경로를 항상 열어 기울기/정보가 막히지 않게 한다
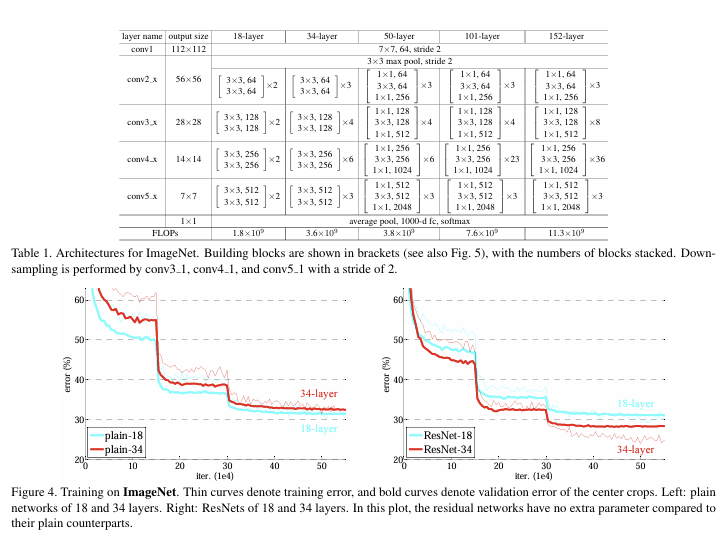
Network Architectures
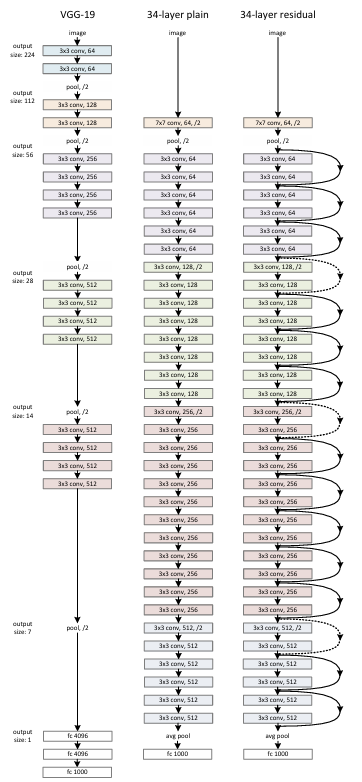
Plain 기준선 (VGG 철학)
- 규칙:
동일 해상도 구간 -> 채널 수 고정
해상도 1/2될 때 -> 채널 x2 - 다운샘플링 : stride=2 Conv
- 헤드 : Global AvgPool -> 1000-way FC
- ex. 34층, 3.6B Flops(VGG-19의 ~18%)
Residual 버전
- plain에 shortcut 삽입
- 차원 동일 -> 항등 shortcut
- 차원 증가 시 2옵션:
(A) 0-padding(무파라미터)
(B) 1x1 projection(Ws) - 해상도 변경은 stride=2
=> 같은 뼈대에 shortcut만 더해 깊이를 늘려도 최적화/성능을 확보
Implementation
- 데이터 증강
- 짧은 변 [256,480] 랜덤 스케일링
- 224x224 랜덤 크롭, 좌우 반전
- 픽셀 평균값 차감, 표준 색상 증강
- 학습 설정
- SGD, Batch 256, Momentum 0.9, Weight decay 1e-4
- LR 0.1 시작 -> 정체 시 10x 감소
- 600k iterations, Dropout 없음
- 테스트
- 기본 : 10-crop
- 최고 성능 : Fully Convolutional로 변환 후 입력 크기 {224,256,384,480,640} 멀티스케일 평균
- 주의
- Conv -> BN -> ReLU 순서
- He 초기화
- Plain/Residual 모두 처음부터 학습 (pretrained 미사용)
Experiments
ImageNet Classification
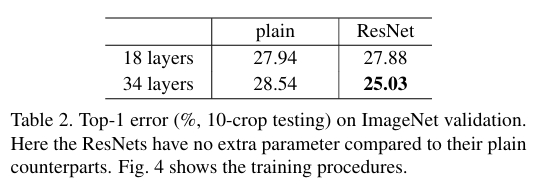
ImageNet-2012(1000 클래스, 학습 128만/검증 5만/테스트 10만)에서, plain 네트워크는 18->34층으로 깊어질수록 훈련·검증 오류가 오히려 상승하는 퇴화가 관찰된다. BN을 사용해도 기울기 소실 문제가 아닌 수렴 지연(최적화 난이도)로 해석된다. 반면 ResNet은 잔차 학습 덕분에 깊어질수록 훈련 오류가 감소하고 정확도는 상승한다.
차원 증가 시 지름길은 (A)0-padding, (B)1x1 projection, (C)전부 projection을 비교했을 때 셋 모두 plain보다 우수했고, (B)≳(A),(C)는 근소 우세지만 파라미터 증가가 있어 필수적이지 않다. 깊이를 크게 늘릴 때는 병목(1x1->3x3->1x1) 블록으로 복잡도를 통제한다.
핵심 수치
- plain 34층 대비 ResNet 34층 : top-1 약 -3.5%p
- ResNet-50/101/152 : 깊이 증가에도 복잡도 통제, ResNet-152 ≈ 11.3B FLOPs < VGG-16/19(15.3B/19.6B)
- ResNet-152 단일 : top-5 검증 4.49%
- 6-모델 앙상블(152 두 개 포함) : 테스트 top-5 3.57%(ILSVRC 2015 1위)
<차원 증가 시 지름길 옵션>
(A) Identity + O-padding (무파라미터)
: 남는 채널을 0으로 패딩해 F(x)와 동일 크기로 만든 뒤 원소별 덧셈
- 장점 : 추가 파라미터/연산 0
- 한계 : 0으로 채운 채널로는 정보/기울기 흐름 없음 -> 성능이 (B)보다 소폭 낮을 수 있음
(B) 1x1 Projection (사영 지름길)
: 1x1 conv로 Cin->Cout 채널 재매핑, 필요 시 stride s로 공간도 정렬
- 장점 : 모든 채널에 정보/기울기 경로 확보, (A) 대비 소폭 더 정확
- 비용 : 파라미터=Cin x Cout (1x1이어서 최소 비용)
(C) All Projection (모든 지름길을 1x1로)
: 모든 블록에서 지름길에 1x1 conv 사용
- 장점 : (B)보다 근소한 성능 이득 가능
- 비용 : 지름길마다 파라미터/연산 증가 -> 메모리·시간 부담
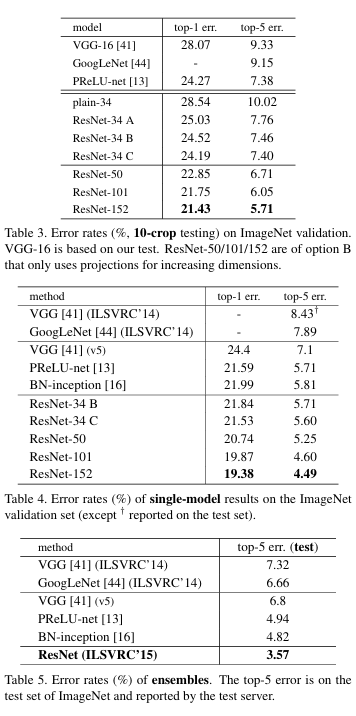
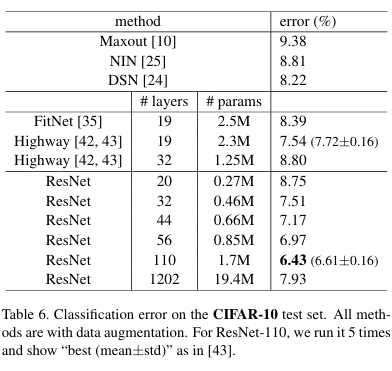
CIFAR-10 and Analysis
CIFAR-10(학습 5만/테스트 1만,10클래스)에서 구조와 학습 조건을 통일해 비교했다. plain은 깊어질수록 훈련 오류 ↑(퇴화), ResNet은 깊어질수록 오류 ↓·정확도 ↑가 재현된다. 층 반응(std) 분석 결과, ResNet은 잔차가 작은 보정만 수행(항등+작은 보정)한다는 가설을 지지한다.
아키텍처는 입력 32x32, 총 층수 6n+2, 해상도 32->16->8(각 2n층), 16/32/64, 다운샘플링은 stride=2 conv, 지름길은 모두 항등(option A). 학습은 batch 128, SGD(m=0.9,wd=1e-4), He 초기화, BN, dropout 없음, Ir 0.1(32k/48k에서 x0.1, 64k 종료), 증강은 4px pad -> 32x32 랜덤 크롭/플립
핵심 수치/포인트
- ResNet-110 : 안정 수렴, 테스트 오류 6.43%
- ResNet-1202(~19.4M 파라미터) : 훈련 <0.1% vs 테스트 7.93% -> 과적합(데이터 대비 과대 모델)
- 워밍업 트릭(110층) : 초기 LR=0.01로 ≈400 iters(훈련오류 <80%)까지 워밍업 후 0.1 복귀
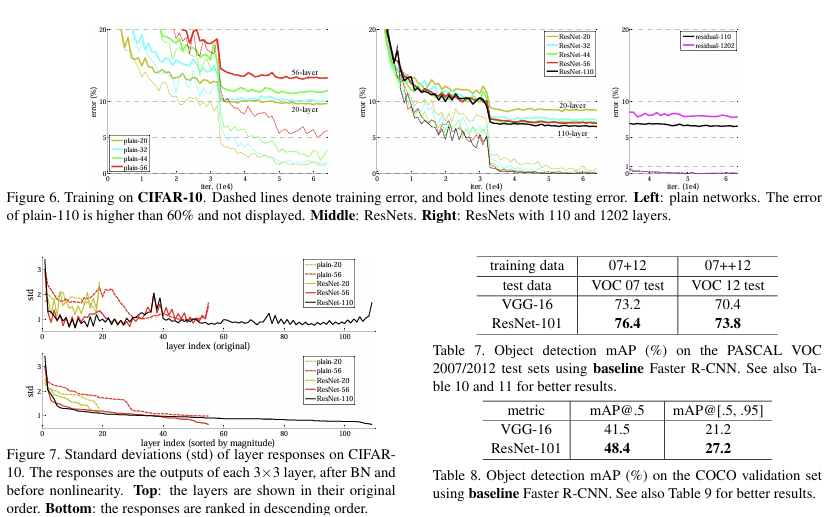
Object Detection on PASCAL & MS COCO
Faster R-CNN 파이프라인에서 백본만 VGG-16 -> ResNet-101로 교체(나머지 동일)하면, PASCAL/COCO 모두 유의미한 향상을 얻는다. (대회 설정에선 BN 통계 고정으로 메모리/안정성 확보)
핵심 수치/포인트
- PASCAL VOC 2007/2012 : ResNet-101이 VGG-16 대비 mAP 상승
- MS COCO(val) : mAP@[.5:.95] + 6.0%p(상대+28%), mAP@.5 + 6.9%p -> 인식력과 정밀 위치 지정 모두 개선
- 대회 성과(2015) : ImageNet Detection/Localization, COCO Detection/Segmentation 모두 1위
Summary
<ResNet 특징 요약>
1) 핵심 아이디어
- 잔차 학습 : 직접 H(x)를 배우지 않고 잔차 F(x)=H(x)-x를 학습하여 y=x+F(x)로 출력
- 지름길(Shortcut) : 입력을 출력으로 그대로 더하는 경로를 항상 열어둠 -> 기울기 흐름 보장, 깊어도 최적화 용이
2) 블록 구성 (두 가지 계열)
- Basic Block (ResNet-18/34)
: Conv 3x3 -> BN -> ReLU -> Conv 3x3 -> BN -> +skip -> ReLU - Bottleneck Block (ResNet-50/101/152)
: 1x1(채널 축소) -> 3x3 -> 1x1(채널 확장, 보통 x4) ->+skip -> ReLU
-> 장점 : 연산/파라미터 효율 높아 깊이 확장에 유리
3) 지름길(Shortcut) 종류
- 항등 지름길 : S(x)=x (차원 같을 때) -> 추가 파라미터 0, 연산은 원소별 덧셈뿐
- 사영 지름길(Projection) : S(x)=Ws*x (1x1 conv, 필요 시 stride)
-> 차원/해상도 바뀔 때 형상 맞춤, 0-padding보다 정보·기울기 보존이 좋음
4) 최적화 측면의 특징
- 기울기 고속도로 : 역전파가 ∂L/∂x = ∂L/∂y(I+∂F/∂x) -> I 덕에 기울기 소실/폭주 완화 -> 깊게 쌓아도 학습 안정
- 항등 해 접근 용이 : 필요하면 F(x)=0으로 바로 항등 구현 (층 추가로 나빠지지 않도록 안전장치)
- "작은 보정" 누적 : 평균적으로 F(x)의 반응 크기가 작게 학습되어 안정적으로 큰 표현 변화를 누적
5) 핵심 과정
기본식 : y = x + F(x)
- 의미 있는 변환이 필요한 위치/샘플/채널에선 F(x)가 큰 쪽으로 학습되어 x를 보정한다
- 변환이 굳이 필요 없으면 F(x)≈0 쪽으로 머물러 거의 항등이 된다
(+) F(x)를 0으로 만드는 별도의 규칙은 없고, 손실 L을 줄이는 방향으로 경사하강이 F의 크기를 자연스럽게 조절한다 (평균적으로 작게 나오는 경향)
=> "항등 + 작은 보정"을 여러 블록에 걸쳐 누적하면, 한 번에 크게 비틀지 않고도 안정적으로 큰 변화를 만들 수 있고, 기울기 소실/폭주도 완화된다
Comment
잔차 학습이 표현을 크게 바꾸는 대신 항등에 작은 보정을 누적하도록 재정의해, 깊이 증가 시 성능이 떨어지던 병목을 깔끔히 해소했다는 점이 인상적이다.
