[논문리뷰]Adaptive Information Routing for Multi-Modal Time Series Forecasting (다중 모달 시계열 예측을 위한 적응형 정보 라우팅)
논문 출처 Adaptive Information Routing for Multi Modal Time Series Forecasting
5줄 요약
-
일반적으로 시계열 데이터는 텍스트 데이터에 비해 Local하고, 구체적이며, 구조화된 정보를 담음
-
텍스트 데이터는 시계열 데이터에 비해 Global하고, 모호하며, 구조화되지 않은 정보가 가득.
-
따라서 두 데이터의 서로 다른 특성을 고려하지 않고 시계열, 텍스트 데이터를 단순히 모델 입력 목적으로 함께 사용하는 방법은 데이터의 활용 능력에서 근본적인 한계를 가짐
-
기존 방식이 텍스트를 보조 입력으로만 쓰는 반면, AIR는 텍스트를 이용해 시계열 정보의 결합 방식과 정도를 조절함.
-
실험 결과, AIR는 예측 정확도를 크게 향상시켰으며, 특히 주가 예측 등 실제 데이터에서도 효과가 뛰어남
1. 서론
-
기존 시계열 예측 모델은 시계열 데이터만 활용하지만, 사람은 다양한 정보(예: 텍스트)를 함께 참고
-
최근에는 LLM의 성공에 힘입어, 텍스트와 시계열 데이터를 결합하려는 연구들이 활발히 진행중
-
이전 연구들은 LLM에 시계열 데이터를 입력하거나, LLM에서 추출한 텍스트 임베딩을 시계열과 합치는 방식 등을 사용 BUT 대부분의 방법은 텍스트를 단순한 보조 정보로만 처리
-
이에 반해, 본 논문에서는 텍스트 정보를 예측 모델의 작동 방식을 조정하는 ‘조정자(controller)’로 사용→ 즉, 텍스트에 따라 시계열 정보가 결합되는 방식과 정도를 동적으로 제어하는 새로운 프레임워크인 AIR (Adaptive Information Routing).
→ 이로써 예측 전 과정에서 텍스트의 영향을 효과적으로 반영 가능
2. 방법 소개
💡AIR 핵심 내용
텍스트 정보를 바탕으로 시계열 예측 모델 내부의 정보 흐름(정보 경로)을 동적으로 조절하는 프레임워크
완전 연결 계층(FC layer)을 두 개의 FC 계층으로 분해하고, 그 사이에 잠재 노드(latent representation)를 두는 것
이 구조에서 각 잠재 노드는 입력과 출력 사이의 특정 연결을 나타내며, 텍스트 임베딩을 통해 이 잠재 노드들에 가중치를 부여
→ 즉, 텍스트 정보에 따라 입력과 출력 사이의 연결 강도를 조절하게 되며, 이를 통해 시계열 모델의 동작 방식을 제어 가능
위와 같은 구조를 바탕으로 Information Routing 모듈을 이용!
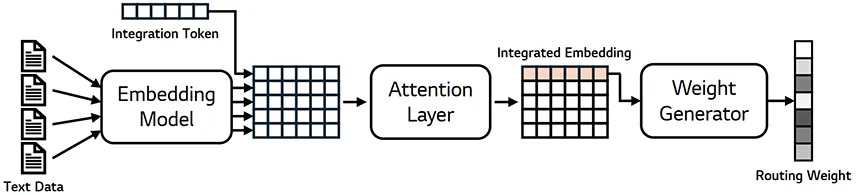
-
텍스트 임베딩 모델 (Embedding Model)
- 각 텍스트 데이터를 고정 크기의 벡터로 변환
- 사용된 모델: Mistral-7B, E5로 파인튜닝
-
임베딩 통합기 (Embedding Integrator)
-
여러 텍스트 임베딩을 하나로 통합
-
구조: Attention Layer + 통합 토큰(integration token)
(통합토큰이란? :
여러 개의 텍스트 임베딩이 입력될 때, 가장 중요한 정보를 추출하여 하나의 대표적인 벡터를 생성)
- 통합 토큰과 텍스트 임베딩을 함께 attention에 넣고, 통합 토큰에 해당하는 출력을 최종 임베딩으로 사용
-
-
가중치 생성기 (Weight Generator)
- 통합된 임베딩을 입력으로 받아 잠재 노드(latent nodes)에 적용할 가중치 생성
- 구조: MLP(다층 퍼셉트론)
- 출력값에 softmax 함수를 적용하여 여러 경로에 대한 가중치를 정규화
- 추가로, 잠재 노드들을 여러 그룹으로 나누고, 각 그룹 내에서 softmax 정규화 수행 → 성능 향상 목적
다시한번 3줄 요약!!
1. 사전 학습된 임베딩 모델을 통해 텍스트 → 고정벡터로 임베딩
2. Attetion Layer와 학습 가능한 Integration 토큰을 사용해 텍스트 데이터 → 단일 벡터로 통합
3. 다층 퍼셉트론 형태의 가중치 생성기로 가중치 생성
> 💡 TsMixer 핵심 내용
TSMixer의 구조
TSMixer는 Mixer Block이라는 단위 구조를 반복하여 시계열 데이터를 처리
각 Mixer Block은 다음과 같은 두 개의 FC Layer로 구성
- Temporal Mixing (시간적 혼합) → 시간 축을 따라 정보를 통합하는 FC Layer
- Featural Mixing (특성 혼합) → 각 특징(feature) 간의 관계를 학습하는 FC Layer
즉, TSMixer는 시간적인 관계와 특성 간 관계를 각각 학습하는 방식
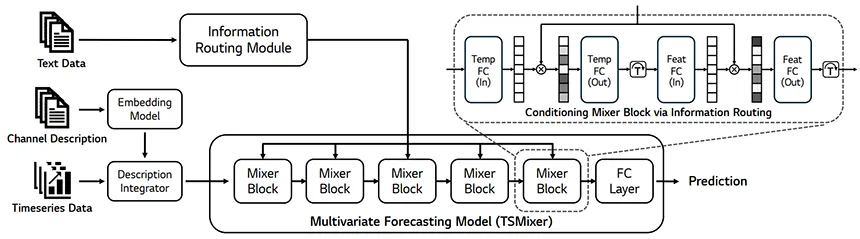
AIR에서의 변형
AIR는 기존 TSMixer의 FC Layer를 더 세밀하게 조정할 수 있도록 변형
변경점:
- 원래 하나였던 각 FC Layer를 두 개의 FC Layer로 분리
- 이 둘 사이에 Latent Representation(잠재 벡터) 추가
- Information Routing 모델이 생성한 가중치를 적용하여 각 Latent 노드의 정보 흐름을 조절
즉, AIR는 기존의 단순한 FC Layer 구조를 더 유연하게 변형하여, 텍스트 정보를 활용
- Information Routing 모델의 역할
AIR의 Information Routing 모델은 단순히 하나의 가중치를 적용하는 것이 아니라,
각 Mixer Block과 각 FC Layer마다 서로 다른 가중치를 생성하여 적용
즉, 텍스트 정보에 따라 블록별로 다르게 정보 흐름을 조절하는 것이 핵심!!
다시한번 3줄 요약!!
- TSMixer는 원래 두 개의 FC Layer를 활용하는 모델
- AIR는 각 FC Layer를 두 개로 분리하고, 그 사이의 Latent에 Information Routing 가중치를 적용
- Information Routing 모델이 각 Mixer Block과 FC Layer별로 다르게 가중치를 생성하여, 텍스트 정보를 기반으로 정보 흐름을 동적으로 조절
3.성능평가
1. Synthetic 데이터 실험
데이터 생성 과정:
- 30개의 랜덤한 시계열 데이터를 생성
- 이 중 2개를 랜덤으로 선택해 평균을 내 Target 데이터로 설정
- 특정한 주기마다 Target 데이터의 구성(사용된 두 개의 시계열)을 변경
- 이 구성 변화 정보를 담은 텍스트 데이터를 함께 생성
실험 목적:
- 텍스트 정보를 활용하지 못하는 모델 → 주기적인 변화 패턴을 인식할 수 없어 예측 성능이 저하됨
- AIR처럼 텍스트 정보를 반영하는 모델 → Target 구성 변화에 적응하여 거의 완벽한 수준의 예측 가능
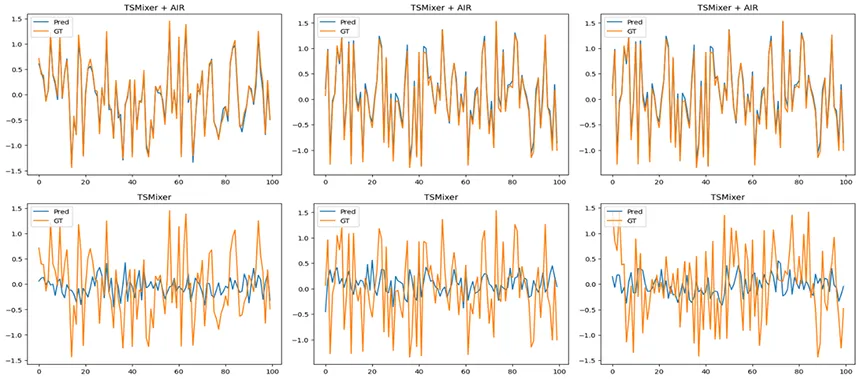
결과해석
- 위쪽 3개 그래프 → TSMixer + AIR 결과
- 아래쪽 3개 그래프 → TSMixer (기본 모델) 결과
- 주황색(GT, Ground Truth) → 실제 시계열 값
- 파란색(Pred, Prediction) → 모델이 예측한 값
TSMixer + AIR (위쪽)
- 예측값(파란색)이 실제값(주황색)과 더 잘 맞음 → 모델이 패턴을 더 정확하게 학습
- 텍스트 정보를 활용하여 시계열 변화 패턴을 조절 가능
TSMixer (아래쪽)
- 예측값(파란색)이 실제값(주황색)과 차이가 큼
- 패턴을 정확히 따라가지 못함 → AIR 없이 텍스트 정보 반영이 불가능하기 때문
주가 데이터 실험 (AIR가 실제 주가 예측에 효과적인지 검증)
데이터 구성:
- 미국 IT 기업들의 주가 종가 시계열 데이터 (대표적인 M7 종목 사용)
- M7: 마이크로소프트(MSFT), 애플(AAPL), 알파벳(GOOGL), 아마존(AMZN), 엔비디아(NVDA), 테슬라(TSLA), 메타(META)
- ChatGPT를 활용해 생성한 관련 텍스트 데이터
- 예: 기업 실적 발표 내용, 경제 뉴스 등 주가에 영향을 미치는 정보
실험 목적:
- AIR가 텍스트 정보를 활용하여 주가 예측 성능을 향상시킬 수 있는지 검증
- 기존 방식보다 더 정확한 시계열 예측이 가능한지 평가
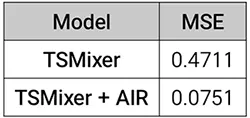

- AIR를 적용한 모델(TSMixer + AIR)은 모든 주식(AAPL, AMZN, GOOGL, META, MSFT, NVDA, TSLA)에서 MSE가 낮아짐
- 평균 16.93%의 성능 향상(IMP) , 최고 23.68%, 최저 12.71% 오차 감소
결과해석
- AIR 적용 시 시계열 예측 정확도가 크게 향상됨 (MSE 감소)
- 주가 예측에서 모든 주식에 대해 고르게 개선 효과를 보임
