Modeling Relational Data with Graph Convolutional Networks 논문 링크
Overview
- 문제 : 기존 지식 그래프는 불완전하며, 매우 다중 관계적인 특성 때문에 기존 GNN 모델로는 처리가 어려움
=> R-GCN은 이 복잡성을 해결하기 위해 GNN을 확장한 모델로, 그래프 구조로부터 여러 추론 단계를 거쳐 증거를 축적하는 방식으로 작동
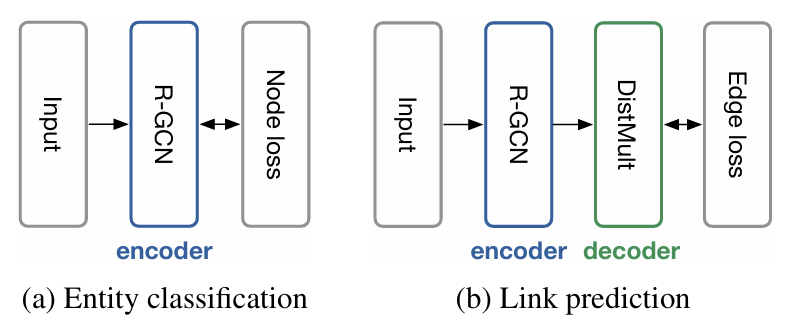
- 엔티티 분류 (Entity Classfication) : 관계형 문맥 정보가 내포된 임베딩을 생성하여 독립형 분류 모델로서의 역할을 가능하게 함
- 링크 예측 (Link Prediction) : 학습된 풍부한 개체 임베딩을 통해 디코더 모델의 성능을 향상시켜 누락된 삼중항 복원의 정확도를 높임
- R-GCN은 다중 관계 처리를 위한 매개변수 규제 기법을 도입했으며, 두 작업에 적용한 결과 특히 링크 예측에서 기존 모델 대비 획기적인 성능 향상을 달성했다.
Introduction
- 지식 기반(KB)은 질의응답, 정보 검색 등 다양한 응용에 활용되지만, DBPedia,Wikidata,Yago와 같은 대형 KB조차 불완전하다.
-> 누락된 정보를 예측하는 것이 통계적 관계 학습(SRL)의 핵심 과제.
지식 기반은 (주어,관계,목적어) 삼중항으로 표현되며, 이를 방향성 라벨 멀티그래프로 모델링할 수 있다.
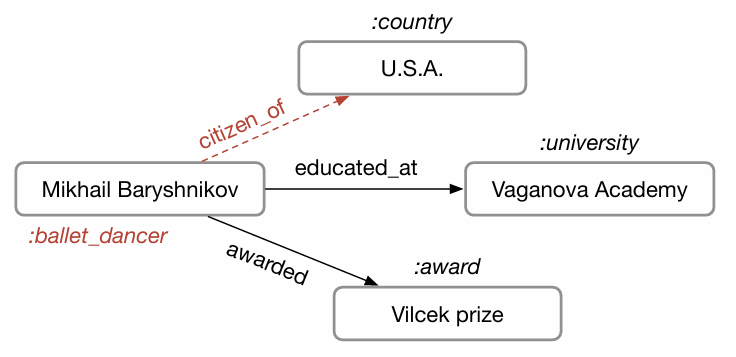
- 노드(entity): Mikhail Baryshnikov, Vaganova Academy, Vilcek prize, U.S.A.
- 엣지(relation): educated_at, awarded
- 노드 라벨(entity type): university, :award, :country
- 빨간색으로 표시된 부분(citizen_of, :ballet_dancer)은 현재 지식 그래프에 빠져 있는 정보
-> 모델이 학습을 통해 새롭게 추론해야 할 대상
삼중항의 s,r,o
- s(subject): 시작 노드 (ex. Mikhail Baryshnikov)
- r(relation): 관계 타입 (ex. educated_at, citizen_of)
- o(object): 도착 노드 (ex. Vaganova Academy, U.S.A.)
제안1. 엔티티 분류 모델:
- 노드 표현을 학습하는 R-GCN -> 소프트맥스 분류기 -> 엔티티 라벨 예측
- 학습은 교차 엔트로피 손실로 최적화
제안2. 링크 예측 모델:
- 오토인코더 구조
- 인코더: 엔티티 잠재 표현을 생성하는 R-GCN
- 디코더: 텐서 분해 모델(ex.DistMult)로 엣지 예측
- 기본 DisMult보다 향상된 성능, 특히 어려운 FB15k-237 데이터셋에서 효과적
Neural Relational Modeling
1. Relational Graph Convolutional Networks (R-GCN)
- 기존 GCN을 관계형 데이터로 확장
- 각 노드 업데이트는 이웃 노드 메시지의 정규화된 합을 기반으로 계산되며, 관계 타입별 가중치 행렬 을 도입
- 자기 자신과의 연결(self-loop)을 추가하여 이전 계층 정보도 반영
- 효율적 구현 : 희소 행렬 곱을 이용, 여러 계층을 쌓아 다중 관계 의존성 학습
(1) 메시지 패싱 일반식
(2) R-GCN 업데이트 식
2. Regularization (과적합 문제 해결)
- 문제점 : 관계 수가 많아질수록 파라미터 수 폭증 -> 과적합 위험
- 해결책:
-
Basis decomposition
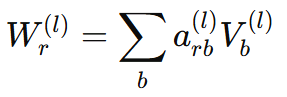 -> 여러 관계가 basis 변환을 공유 (효율적 weight sharing)
-> 여러 관계가 basis 변환을 공유 (효율적 weight sharing)
= 관계별 가중치 를 전부 따로 두지 않고, 공통 basis 행렬 몇 개 를 가중합해 만들어 파라미터 크게 감소 -
Block-diagonal decomposition
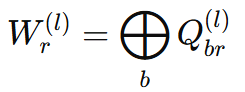 -> 블록 대각 구조로 sparsity 부여, 그룹 내 강한 연관성 반영
-> 블록 대각 구조로 sparsity 부여, 그룹 내 강한 연관성 반영
= 를 대각 블록들만 있는 형태로 제한해 그룹 내부만 섞이고 그룹 간 연결은 0이 되도록 함 (같은 그룹끼리만 강하게 상호작용)
-
- 두 방식 모두 파라미터 수 감소 + 희소성 확보, 드문 관계에서도 과적합 완화
3. 전체 R-GCN 모델
- L계층 R-GCN 스택 구조
- 입력 특징 없으면 one-hot 사용, 필요 시 dense 변환
- 사전 정의된 특징도 활용 가능
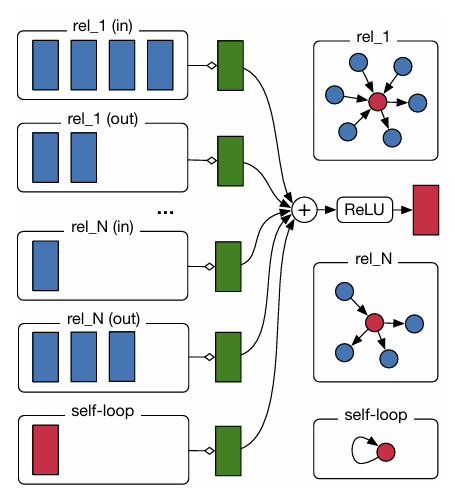
특정 노드(red)의 새로운 표현을 계산하는 과정
1. 이웃 노드들의 임베딩 수집 (blue)
- 각 관계 타입(rel_1,rel_N)별로 in-edge,out-edge가 따로 구분됨
- 이웃 노드들의 d차원 벡터가 모임
- 관계별 변환 (green)
- 관계 r마다 다른 가중치 행렬 을 적용해 이웃 정보를 변환
- self-loop(자기 자신 연결)도 포함해서 자기 정보가 보존됨
- 정규화된 합산 (+)
- 관계별 변환된 벡터들을 모두 더하고, 정규화 계수 로 나눠줌
->이웃 수가 많은 노드도 과도하게 영향받지 않도록 조정
- 비선형 활성화 (ReLU)
- 합산 결과를 활성화 함수에 통과시켜 새로운 노드 표현(red)으로 업데이트
- 병렬 학습 가능
- 그래프 전체 노드가 동일한 공유 파라미터 하에서 동시에 업데이트 가능
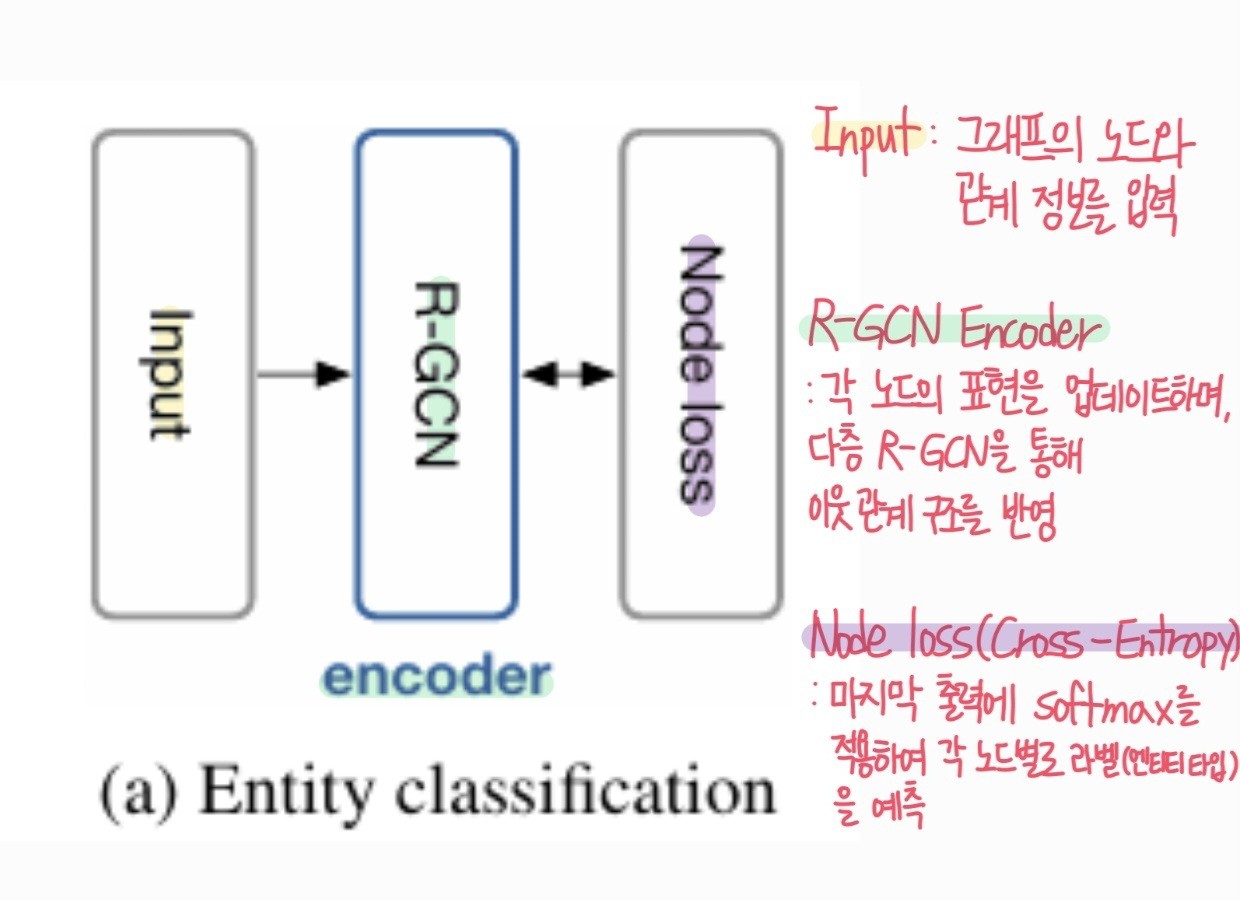
Entity Classification
모델 구조
- R-GCN 업데이트 식 기반 R-GCN 계층을 여러 층으로 쌓음
- 마지막 출력에 대해 노드별 softmax 활성화 함수 적용
- 각 노드의 최종 벡터 표현 -> 엔티티 라벨 예측
손실 함수 (Cross-Entropy)
- 레이블이 있는 노드 집합 Y에 대해서만 계산
- 정답 레이블 과 예측 확률 간의 차이를 최소화
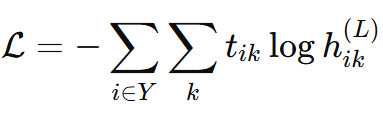
- 레이블이 없는 노드는 학습에서 제외
훈련 방법
- 풀 배치 경사하강법을 사용
- R-GCN 파라미터와 softmax 분류기를 end-to-end로 함께 최적화
=> 노드의 이웃 관계 정보가 전파·누적되어, 단순한 특징 기반 분류보다 더 풍부한 표현 학습 가능
Link Prediction
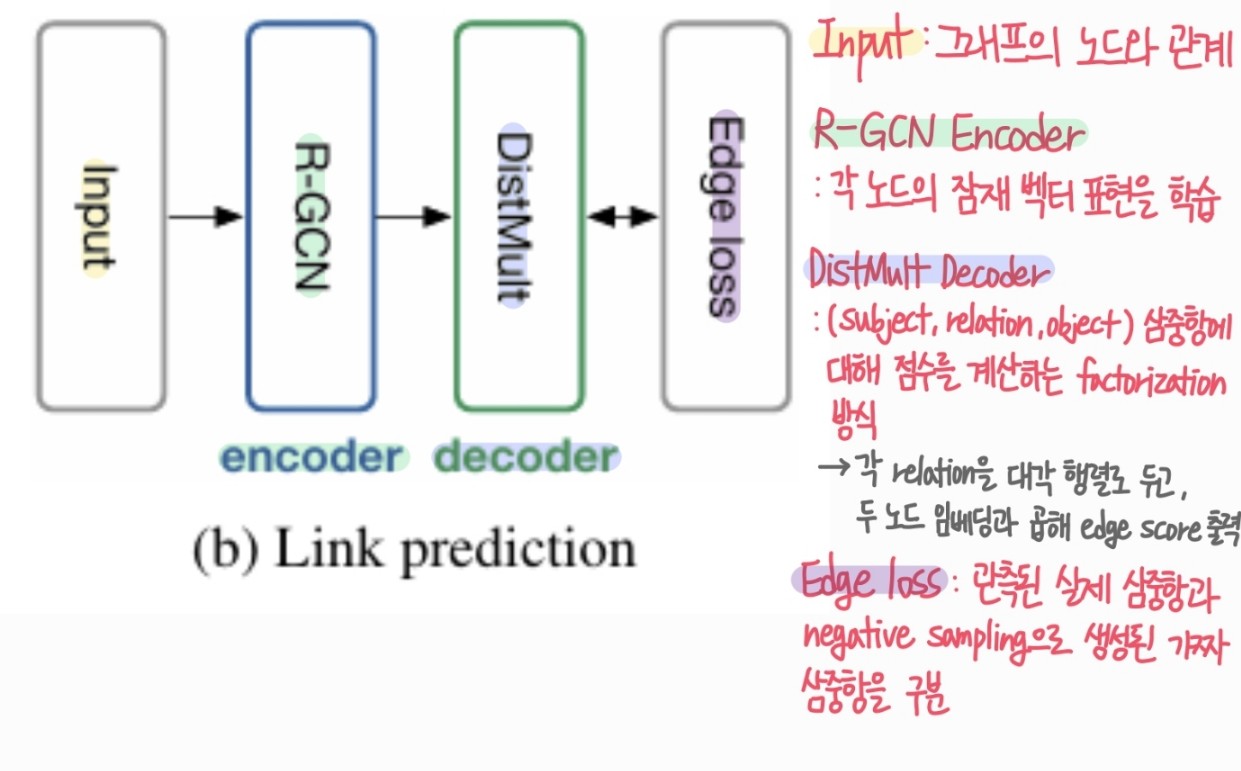
목표
- 불완전한 지식 그래프에서 누락된 삼중항(s,r,o)을 예측
- 스코어 함수 f(s,r,o)로 해당 엣지가 실제 그래프에 속할 확률을 측정
모델 구조
- 인코더: R-GCN -> 각 엔티티 ∈V를 벡터 ∈로 임베딩
- 디코더(스코어링 함수): f:xx->
- 기존 방법과 차별점: 단순 학습 파라미터 벡터 대신 R-GCN 인코더를 통해 표현 을 계산
DistMult 스코어링 함수
- , : subject,object 임베딩
- ∈: 관계 r에 대한 대각 행렬
학습 (Negative Sampling + Cross-Entropy)
- T: 실제 삼중항 + negative sampling된 삼중항 집합
- y: 지표 변수 (y=1:양성,y=0:음성)
- σ: 로지스틱 시그모이드 함수
-> loss는 양성일 때 점수↑, 음성일 때 점수↓ 되도록 조정
Empirical Evaluation
1. Entity Classification Experiments
- 목표: 지식 그래프 내 엔티티의 타입을 분류
- 데이터셋: AIFB, MUTAG, BGS, AM (RDF 포맷)
- 비교: RDF2Vec, WL kernel, Feat 대비
- 결과:
- AIFB, AM → SOTA 성능
- MUTAG, BGS → 고차수 허브 노드 문제로 성능 저하
- 개선 방향: 정규화 대신 attention 메커니즘 활용 가능성
2. Link Prediction Experiments
- 목표: 불완전한 지식 그래프에서 누락된 삼중항 (s,r,o) 예측
- 데이터셋: FB15k, WN18 (역삼중항 문제), FB15k-237 (개선 버전)
- 비교: DistMult, LinkFeat, ComplEx, HolE, TransE 등
- 결과:
- FB15k, WN18 → R-GCN이 DistMult보다 우수, 그러나 LinkFeat엔 미치지 못함
- FB15k-237 → LinkFeat 일반화 실패, R-GCN이 DistMult보다 29.8% 향상
- 인코더(R-GCN)의 중요성 확인
Related Work
1. Relational Modeling
- R-GCN 디코더: DistMult 사용 → RESCAL의 단순화된 효과적 변형
- 다양한 factorization 방법 존재 (CP, Tucker, TransE, ComplEx 등)
- 최근 연구: 엔티티 간 경로(path) 활용
- 보조 삼중항 추가
- 경로/Walk 기반 특징 사용
- 두 방법을 함께 적용
- R-GCN은 이러한 경로 기반 접근 대비 계산 효율적 대안 제공
2. Neural Networks on Graphs
- R-GCN은 GCN 확장판 → 대규모 다중 관계 데이터 처리 가능
- 초기 연구: Graph Neural Network (Scarselli et al. 2009)
- 확장: Gating 기법(Li et al. 2016, Pham et al. 2017)
- R-GCN은 Message Passing Neural Network(Gilmer et al. 2017)의 한 형태
Conclusions
R-GCN은 관계형 데이터를 처리하기 위해 GCN을 확장한 모델로, 링크 예측과 엔티티 분류에서 모두 효과성을 입증했다. 특히 FB15k-237 데이터셋에서 단순 factorization보다 약 30% 성능 향상을 보여 인코더의 중요성을 강조했다.
향후 연구 방향으로는 ComplEx 같은 다양한 디코더 결합, 엔티티 특징 활용, 대규모 그래프 처리를 위한 샘플링 기법, 어텐션 기반 메시지 집계 등이 제시된다.
Comment
R-GCN은 단순히 각 노드의 고유한 특징에 의존하지 않고, 노드 간의 관계 구조 자체를 학습 과정의 핵심 특징으로 삼아 지식 그래프의 본질적인 문제를 직접적으로 다룬다는 점에서 큰 의의가 있다고 생각한다.
