
서론
이번 프로젝트에서 RateLimiter를 구현할 때 Redis의 Sorted set을 활용하여 구현했습니다.
Sorted set은 어떤 자료형으로 이루어져있길래 빠른 정렬이 가능한지 궁금증이 생겨 Redis 오픈소스를 살펴보며 분석해 봤습니다.
우선 Sorted set이 무엇인지 알아보겠습니다.
Redis Sorted set
Redis에서의 Sorted Set은 Hash Table과 SkipList 기반으로 정렬된 데이터를 빠르게 조회해야 할때 사용됩니다.
대표적인 활용 예시
- 실시간으로 변동되는 순위를 보여줄 때
- 시간 기반 데이터 저장 및 조회
- 인기 게시글 추천
주요 특징
- 항상 정렬된 값을 제공합니다.
- 삽입,삭제시 평균적으로 O(log N) 으로 빠른 수정이 가능합니다.
- Hash 기반으로 key를 저장하므로 key기반으로 조회할 시에는 O(1) 입니다.
- score 기반으로 조회시에는 O(log N) 입니다.
- 범위 탐색이 가능합니다.
Hash Table은 많이 사용되는 자료구조이기 때문에 조금은 생소한 SkipList에 대해 알아보겠습니다.
SkipList
SkipList는 빠른 탐색을 위해 다중 레벨을 가진 연결 리스트입니다.

특징
- 헤더가 여러개 있고, 개수는 노드의 최대 높이만큼 있습니다.
- 헤더의 높이는 level이라고 표현됩니다.
- 노드는 각자 다른 높이를 가지고 있고 이는 랜덤으로 지정됩니다.
- 각 노드는 같은 level에 다음 노드 및 아래 level로 연결되어 있습니다.
조회
SkipList의 조회 방식은 다음과 같습니다.
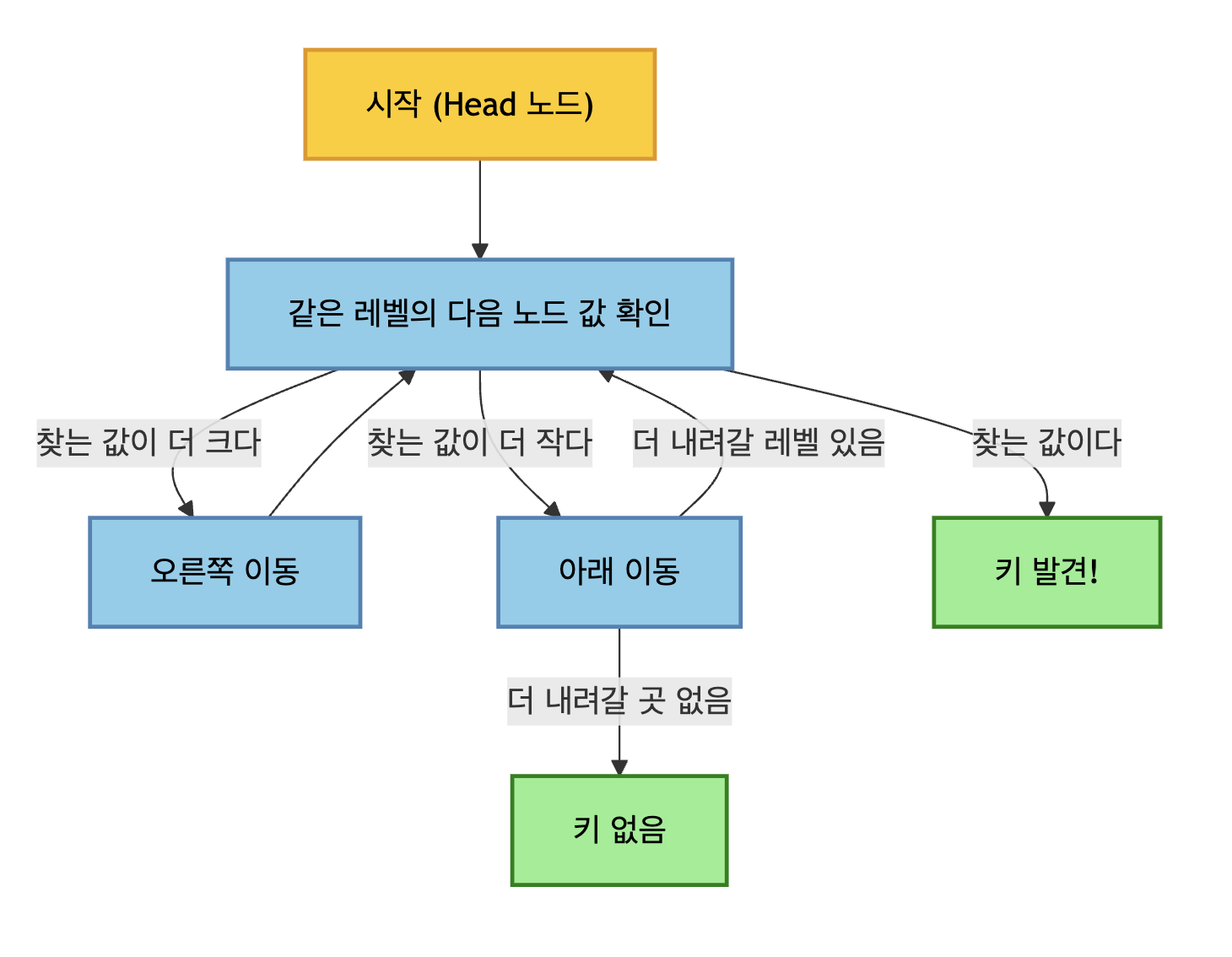
이분 탐색 방식과 유사하다고 보면 될 것 같습니다.
삽입
삽입할 위치를 조회와 같은 방식으로 찾고 삽입을 합니다.
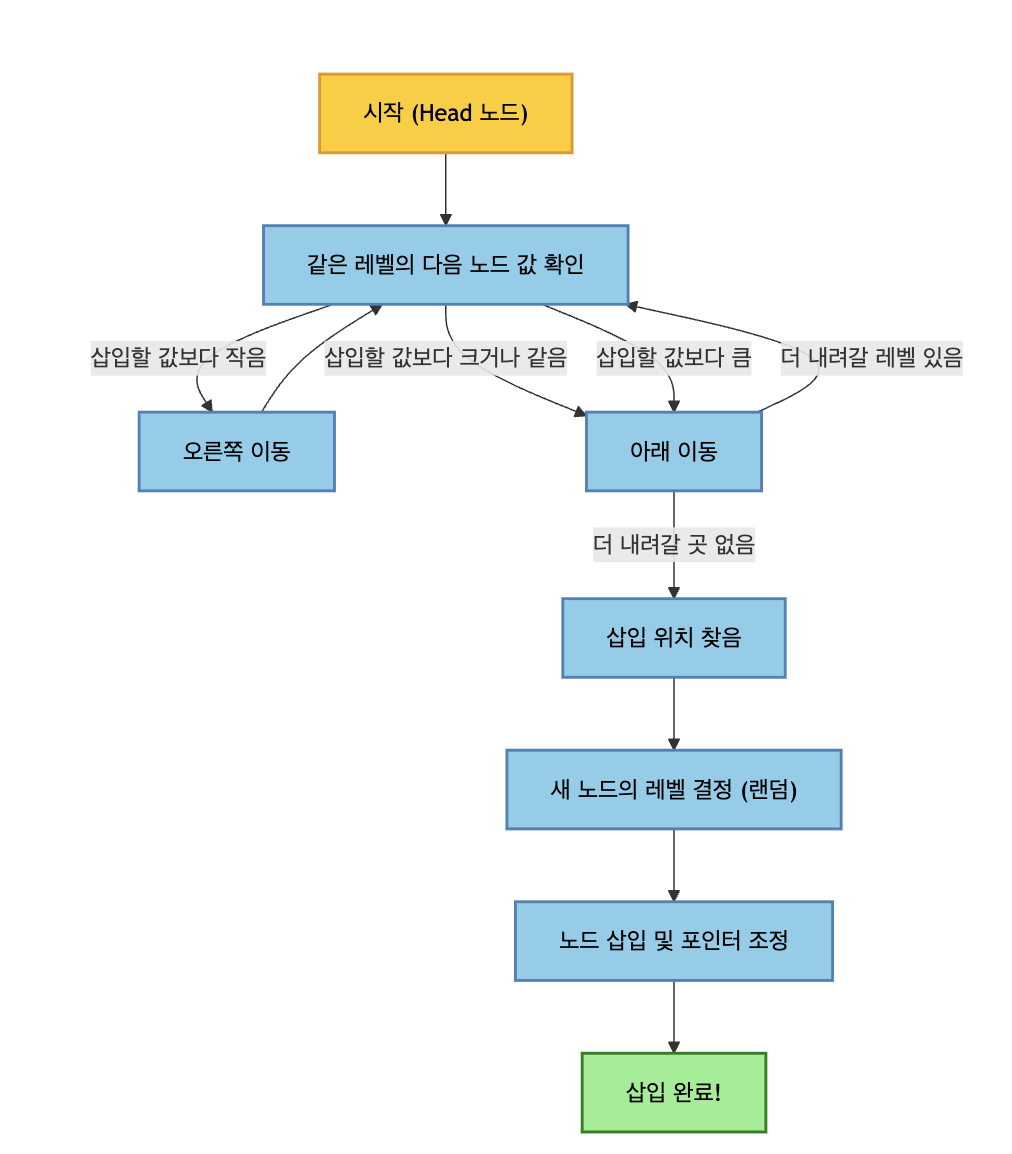
Tree 방식과 달리 삽입을 해도 정렬을 유지하기 때문에 재정렬할 필요가 없습니다.
주목할 점은 새 노드의 레벨을 랜덤으로 지정하는 것 입니다.
랜덤으로 정하는 노드의 레벨?
실제로는 노드의 레벨을 정하는 것이 성능에 큰 영향을 주는 요소이기에 완전한 랜덤은 좋지 못한 방법입니다.
유사한 방식으로 조회를 하는 Tree를 생각해보겠습니다.
Tree는 노드의 개수에 따라 깊어지는 특징이 있습니다.
트리(Tree)는 깊어질수록 더 많은 노드를 포함하며, 이를 통해 O(log N)의 탐색 성능을 보장합니다.
Skip List도 유사한 원리로 레벨이 낮을수록 더 많은 노드를 포함해야 효율적인 탐색이 가능합니다.
완전한 랜덤 방식의 문제점
균형이 깨질 수 있음
- 높은 레벨에 노드가 너무 많아지면 탐색 과정이 사실상 링크드 리스트처럼 동작하여 O(N) 성능이 나올 수도 있습니다.
- 반대로 높은 레벨이 너무 적으면 탐색 경로가 줄어들지 않아 비효율적인 탐색이 발생이 할 수 있습니다.
최적화되지 않은 확률 분포
- 레벨이 log N에 비례해서 줄어들어야 하는데, 랜덤으로 정하면 이 비율이 유지되지 않을 수 있음.
따라서 Skip List는 성능을 최적화하기 위해, 높은 레벨일 수록 적은 확률로 생성되게 해야됩니다.
Redis 오픈소스이기 때문에 이를 어떻게 구현했는지 코드를 통해 알아보았습니다.
Redis 코드 분석
Redis의 Sorted set은 ZSet으로도 불리기에 구조체와 메서드 모두 z를 prefix로 두어 구성되어있습니다.
zskiplist
SkipList의 구조체 입니다.
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // header와 tail 노드
unsigned long length; //전체 노드의 개수
int level; // Skip List의 최대 레벨
} zskiplist;zskiplistNode
SkipList안에 Node의 구조체 입니다.
typedef struct zskiplistNode {
sds ele; // 실제 저장되는 데이터 (zSet의 member)
double score; // 정렬을 위한 score 값
struct zskiplistNode *backward; // 이전 노드 (역순 탐색 용)
struct zskiplistLevel {
struct zskiplistNode *forward; // 다음 레벨의 노드 포인터
unsigned int span; // 현재 레벨에서 다음 노드까지의 거리
} level[];
} zskiplistNode;backward
Redis Zset은 범위 탐색이 가능하기 때문에 역순 조회를 위해 1레벨은 이중 연결 리스트로 되어 있음을 확인할 수 있습니다.
span
Redis는 Rank 기능도 제공합니다. 해당 숫자가 몇번째로 크거나 작은지 빠르게 알기위해 span이 사용됩니다.
단순히 Index를 저장하면 삽입시에 뒤에 있는 노드의 값을 다 바꿔야하기 때문에 연결된 노드의 차이만을 저장합니다.
zslCreate
SkipList 초기화 함수 입니다.
#define ZSKIPLIST_MAXLEVEL 32
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL, 0, NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}Redis는 최대 레벨을 32로 제한되어있습니다.
최대 레벨이 너무 높으면 성능대비 메모리 낭비가 심해질 수 있기 때문인 것 같습니다.
zslRandomLevel
랜덤 노드 레벨 생성 함수입니다.
#define ZSKIPLIST_P 0.25
int zslRandomLevel(void) {
static const int threshold = ZSKIPLIST_P*RAND_MAX;
int level = 1;
while (random() < threshold)
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}ZSKIPLIST_P 0.25 이므로 n+1의 레벨이 반환될 확률은 입니다.
삽입,삭제,조회
삽입, 삭제, 조회 과정은 위에서 설명한 일반적인 Skip List 방식과 유사합니다. 자세한 내용을 확인하려면 아래 참고 자료에 있는 Redis 저장소에서 확인할 수 있습니다.
Redis는 왜 SkipList를 이용했을까?
MySQL과 같이 BTree 기반의 방식도 구현가능할 것 같은데 왜 SkipList로 구현했는지 궁금해 검색해보았고, 같은 질문에 대한 redis 개발자인 antirez의 답변은 다음과 같았습니다.
There are a few reasons:
1) They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
간단하게 요약하면 다음과 같습니다.
- 레벨 생성에 대한 확률 매개변수를 조절하여 btree보다 메모리를 적게 가져갈 수 있다.
- ZRANGE 과 ZREVRANGE 같이 범위 검색에 대해서는 LinkList로 탐색하는 것 이기 때문에 캐시 지역성이 btree보다 좋을 수 있다.
- 구현이 쉽고 유지보수가 편하다.
즉, Redis는 오픈소스로서의 커스텀이 가능한 것과 확장성을 중요시하여 Skip List를 선택했음을 확인할 수 있었습니다.
참고자료
