- 오라클에선 디스크에 저장된 데이터 집합을 데이터베이스라고 한다.
- SGA 공유 메모리 영역과 이를 액세스하는 프로세스 집합을 합쳐 인스턴스라고 한다.
1. 기본 아키텍쳐
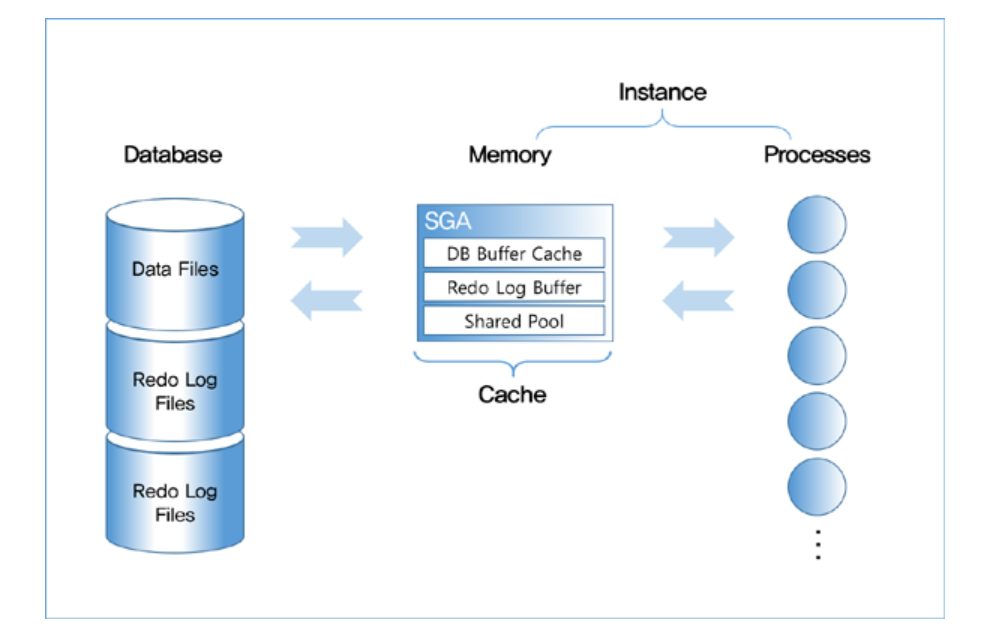
1. 인스턴스(Instance)
-
Sever Process -> SQL 파싱, SQL 최적화, 일련의 작업들 수행
-
SGA
- DB Buffer Cache
- Redo Log Buffer
- Shared Pool - Library Cache, Data Dictionary Cache
-
BackGround Process
- Recoverer(Redo)
- Process Monitor(PMON)
- System Monitor(SMON)
- Database Writer(DBWR)
- Log Writer(LGWR)
- Archiver(ARCn)
2. 데이터베이스(Database)
- Data Files
- Redo Log Files
오라클은 데이터베이스와 이를 액세스하는 프로세스사이에 빠른 데이터 입출력을 위해 SGA라고 하는 메모리 캐시 영역을 두고 있다.
디스크를 경유한 입출력은 물리적으로 액서스 암이 움직이면서 헤드를 통해 데이터를 읽고 쓰는 반면 메모리 캐시를 통한 입출력은 전기적 신호에 불과하기 때문에 디스크 입출력과는 비교할 수 없이 빠르다. 많은 프로세스가 동시에 데이터를 액세스하기 때문에 사용자 데이터를 보호하는 Lock은 물론 공유 메모리 영역인 SGA상에 위치한 데이터 구조에 대한 액세스를 직렬화하기 위한 Lock 메커니즘(Latch= 래치)도 필요해진다.
오라클은 블록 단위로 읽고, 저장할 때도 변경이 발생한 블록만 찾아 블록 단위로 저장한다.
기본적인 구성으로는 오라클을 설치하면 하나의 데이터베이스에 접근하는 하나의 인스턴스를 생성한다.
RAC 환경이란?
하나의 데이터베이스가 여러 인스턴스로 구성가능한 환경, 다중 인스턴스로 구성가능한 환경을 말한다.
RAC 모델은 데이터 파일만 공유하는 과거의 공유 디스크 방식에서 한 층 더 진일보한 공유 캐시 방식을 지원한다.
글로벌 캐시 개념을 사용하므로 로컬 캐시에 없는 데이터 블록을 이웃 노드에서 전송 받아서 서비스한다.
어떤 환경에서도 하나의 인스턴스가 여러 개의 데이터베이스를 액세스하는 것은 불가능하다.
글로벌 캐시 개념을 사용하므로 로컬 캐시에 없는 데이터 블록을 이웃 노드에서 전송받아 서비스할 수 있다. 각 인스턴스를 고속의 전용 네트워크로 연결하기 때문에 가능한 일이다. 심지어 다른 인스턴스에서 갱신하고 아직 커밋하지 않은 Active 상태의 블록까지도 디스크를 경유하지 않고 Dirty 버퍼상태에서 네트워크를 통해 서로 주고받으며 갱신을 수행한다.
2. DB 버퍼 캐시
(1) 블록 단위 I/O
오라클에서 I/O는 블록 단위로 이루어지는데, 메모리 버퍼 캐시에서 버퍼 블록을 액세스할 때 뿐만 아니라 데이터파일에 저장된 데이터 블록을 DB 버퍼 캐시로 적재하거나 캐시에서 변경된 블록을 다시 데이터파일에 저장할 때도 블록 단위로 처리한다. 데이터파일에서 버퍼 캐시로 블록을 적재할 때, 인덱스를 경유한 테이블 액세스 시에는 한 번에 한 블록씩 읽어들이지만, Full Scan 시에는 성능 향상을 위해 한 번에 여러 개 블록을 읽어들인다.
블록 단위로 읽는다는 의미는, 하나의 레코드에서 하나의 컬럼만을 읽고자 하더라도 레코드가 속한 블록 전체를 읽게 됨을 의미한다. 이는 데이터베이스 I/O 성능과 튜닝 원리를 이해하는데 있어 아주 중요한 의미를 갖는다.
(2) 버퍼 캐시 구조
SGA 내에는 수없이 많은 자료구조가 사용되고 있으며 그 중 가장 많이 사용되는 것이 해시 테이블이고, DB 버퍼 캐시도 해시 테이블 구조로 관리된다. DB 버퍼 캐시 내에서 데이터 블록을 해싱하기 위해 사용되는 키값은 데이터 블록 주소(DBA)이다. 즉, 해시 함수에 데이터 블록 주소를 입력해 리턴받은 해시 값이 같은 블록들을 같은 해시 버킷에 연결 리스트 구조로 연결하는 것이다. 각각의 연결 리스트를 해시 체인이라고 한다. 찾고자 하는 데이터 블록 주소를 해시 값으로 변환해서 해당 해시 버킷에서 체인을 따라 스캔하다가 거기서 찾아지면 바로 읽고, 찾지 못하면 디스크에서 읽어 해시 체인에 연결한 후 읽으면 된다. 자신만 읽고 버리는 것이 아니라 다른 사용자들도 사용할 수 있도록 캐싱해 두는 것이다.
(3) 캐시 버퍼 체인
각 해시 체인은 래치에 의해 보호된다. DB 버퍼 캐시는 공유 메모리 영역인 SGA 내에 존재하므로 여러 프로세스에 의한 동시 액세스가 일어날 가능성이 크다. 따라서 같은 리소스에 대한 액세스를 반드시 직렬화해야하고, 이를 위해 구현된 일종의 Lock 메커니즘을 래치라고 부른다.
래치를 획득한 프로세스만이 그 래치에 의해 보호되는 자료구조로의 진입이 허용된다. 예를 들어 두 개 이상의 프로세스가 같은 해시 체인으로 진입해 새로운 버퍼 블록을 연결하고 해제하는 작업을 동시에 진행한다면 문제가 발생할 수 있고, 이를 방지하기 위해 cache buffers chains 래치를 사용한다. 이 외에도 래치 종류는 11g 기준 496개나 된다. 래치는 데이터 자체를 보호하는 게 아니라 SGA에 공유돼 있는 자료구조를 보호하는 것이며, 그 중 cache buffers chain 래치는 버퍼 캐시에 연결된 체인구조를 보호한다. 즉, 해시 체인을 스캔하거나 거기에 블록을 추가, 제거할 때 래치가 요구된다.
(4) 캐시 버퍼 LRU 체인
버퍼 헤더는 해시 체인 뿐 아니라 LRU 체인에 의해서도 연결돼 있다. DB 버퍼 캐시는 한번 읽은 데이터 블록을 캐싱해 두는 메모리 공간이지만 메모리는 유한한 자원이여서 모든 데이터를 캐싱할 수는 없다. 따라서 버퍼 캐시가 사용빈도가 높은 데이터 블록들 위주로 구성될 수 있도록 LRU 알고리즘을 사용해 관리된다. 즉, 모든 버퍼 블록 헤더를 LRU 체인에 연결해 사용빈도 순으로 위치를 옮겨가다가, Free 버퍼가 필요해질 때마다 액세스 빈도가 낮은 데이터 블록들을 우선적으로 밀어냄으로써 자주 액세스되는 블록들이 캐시에 더 오래 남아 있도록 관리하는 것이다.
1. LRU 리스트
- Dirty 리스트 : 캐시 내에서 변경됐지만, 아직 디스크에 기록되지 않은 Dirty 버퍼 블록들을 관리하며, 'LRUW 리스트' 라고도 한다.
- LRU 리스트 : 아직 Dirty 리스트로 옮겨지지 않은 나머지 버퍼 블록들을 관리한다.
2. 버퍼 상태
- Free 버퍼 : 인스턴스 기동 후 아직 데이터가 읽히지 않아 비어 있는 상태이거나, 데이터가 담겼지만 데이터파일과 서로 동기화돼 있는 상태여서 언제든지 덮어 써도 무방한 버퍼 블록을 말한다. 오라클이 데이터 파일로부터 새로운 데이터 블록을 로딩하려면 먼저 Free 버퍼를 확보해야 한다. Free 상태인 버퍼에 변경이 발생하면 그 순간 Dirty 버퍼로 상태가 바뀐다.
- Dirty 버퍼 : 버퍼에 캐시된 이후 변경이 발생했지만, 아직 디스크에 기록되지 않아 데이터 파일 블록과 동기화가 필요한 버퍼 블록을 말한다. 이 버퍼 블록들이 다른 데이터 블록을 위해 재사용되려면 디스크에 먼저 기록되어야 하며, 디스크에 기록되는 순간 Free 버퍼로 상태가 바뀐다.
- Pinned 버퍼 : 읽기 또는 쓰기 작업을 위해 현재 액세스되고 있는 버퍼 블록을 말한다.
3. 버퍼 Lock
(1) 버퍼 Lock이란?
아주 짧은 순간이라도 두 개 이상의 프로세스가 동시에 버퍼 내용을 읽고 쓴다면 문제가 생길 수 있는 것이다. 이를 막기 위해 캐시된 버퍼 블록을 읽거나 변경하려는 프로세스는 먼저 버퍼 헤더로부터 버퍼 Lock을 획득해야 한다. 버퍼 Lock을 획득했다면 래치를 곧바로 해제한다. 버퍼 내용을 읽기만 할 때는 Share 모드, 변경할 때는 Exclusive 모드로 Lock을 설정한다.
버퍼 블록을 읽을 때 대부분 두 번의 래치 획득을 요하지만(버퍼를 찾고 Pin할 때 한 번, Pin을 해제할 때 한 번) 몇몇 오퍼레이션에서는 래치를 쥔 채 버퍼 블록을 읽기 때문에 래치 획득이 한 번만 일어난다.
(2) 버퍼 핸들
버퍼 Lock을 설정하는 것은 자신이 현재 그 버퍼를 사용중임을 표시하는 것으로, 그 버퍼 헤더에 Pin을 걸었다고 표현한다. 버퍼 Lock을 다른 말로 '버퍼 Pin'이라고 표현하기도 하며, Pinned 버퍼가 여기에 해당한다. 변경 시에는 하나의 프로세스만 Pin을 설정할 수 있지만 읽기작업을 위해서라면 여러 개 프로세스가 동시에 Pin을 설정할 수 있다.
버퍼 헤더에 Pin을 설정하려고 사용하는 오브젝트를 '버퍼 핸들'이라고 부르며, 버퍼 핸들을 얻어 버퍼 헤더에 있는 소유자 목록에 연결시키는 방식으로 Pin을 설정한다. 버퍼 핸들도 공유된 리소스이므르 버퍼 핸들을 얻으려면 또 다른 래치가 필요해지는데, 바로 cache buffer handles 래치이다.
(3) 버퍼 Pinning
버퍼를 읽고 나서 버퍼 Pin을 즉각 해제하지 않고 데이터베이스 Call이 진행되는 동안 유지하는 기능을 '버퍼 Pinning'이라고 부른다. 같은 블록을 반복적으로 읽을 때 버퍼 Pinning을 통해 래치 획득 과정을 생략한다면 논리적 I/O 횟수를 획기적으로 줄일 수 있다. 모든 버퍼 블록을 이 방식으로 읽는 것은 아니며, 같은 블록을 재방문할 가능성이 큰 몇몇 오퍼레이션을 수행할 때만 사용한다.
버퍼 Pinning은 하나의 데이터베이스 Call에서만 유효하다. 즉, Call이 끝나고 사용자에게 결과를 반환하고 나면 Pin은 해제되어야 한다. 따라서 첫 번째 Fetch Call에서 Pin된 블록은 두 번째 Fetch Call에서 다시 래치 획득 과정을 거쳐 Pin 되어야 한다.
오라클은 버전이 올라갈수록 버퍼 Pinning을 적용하는 지점을 점차 확대시켜나가고 있다. 9i 에서는 NL 조인 시 Inner 테이블을 룩업하기 위해 사용되는 인덱스 루트 블록을 Pinning하기 시작했고, 11g부터는 Inner 테이블의 인덱스 루트 블록 뿐 아니라 다른 인덱스 블록에 대해서도 Pinning 함으로써 논리적 I/O를 획기적으로 감소시키고 있다. 이 외에도 DML 수행 시 Undo 레코드를 기록하는 Undo 블록에 대해서도 Pinning을 적용한다.
버퍼 Lock은 매우 Internal 한 매커니즘이어서 이해하기 쉽지 않지만 버퍼 Pinning을 통한 블록 I/O 감소효과는 SQL을 튜닝하는데 있어서 중요한 내용이므로 이 원리는 기억할 필요가 있다. 실제로 도저히 튜닝 방안을 찾을 수 없을 때 버퍼 Pinning 효과를 노려 가장 액세스 빈도가 높은 인덱스 키 순서대로 테이블 레코드를 재 정렬함으로써 성능을 획기적으로 개선할 수 있다.
