SQL
1.SQLP 53회차 시험 후기

개인적으로 실기가 51, 52회차와 비교해봤을 때 어려웠다고 생각..이번년도 데이터 직무로 진로를 정하고 6월 SQLD를 취득하면서 쿼리를 더 잘 조작하고 싶고, 어려운 자격증으로 데이터를 다루는 능력과 쿼리의 이해능력 증명하고 싶어 더 상위 자격증을 찾아보다가 8월달
2.SQLP/SQLD 1과목 : 데이터 모델링의 이해

SQL이란 Structured Query Language로 데이터베이스를 직접 액세스 할 수 있는 언어를 말한다복잡한 현실세계를 추상화, 단순화, 명확화해 표현하는 것을 말한다추상화 : 현실세계를 일정한 형식에 맞춰 표현단순화 : 현실세계를 약속한 규약에 의해 언어로
3.SQLP/SQLP 2과목 : SQL 기본 및 활용 (계층형 질의 전까지)
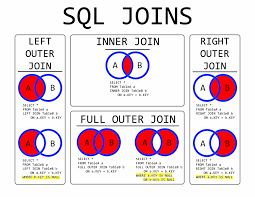
2과목 : SQL 기본 및 활용 데이터베이스와 DBMS 데이터베이스 데이터의 집합이며 데이터의 집합 형식을 갖추지 않아도 엑셀 파일을 모아 둔다면 그것 또한 데이터베이스이다 DBMS 데이터베이스를 관리하기 위한 시스템이다 (Oracle, MySQL등) 관계형
4.SQL) 데이터베이스 계층형 질의(Hierarchical Query)

🐸 계층형 질의란? > 데이터베이스 계층형 질의(Hierarchical Query)는 데이터가 부모-자식 관계로 연결되어 있을 때, 그 계층 구조를 따라가며 조회하는 질의를 말한다 Oracle 계층형 쿼리 문법 (1) 기본 문법 구조 (2) 문법 구성요소별 설명
5.SQL) PIVOT / UNPIVOT
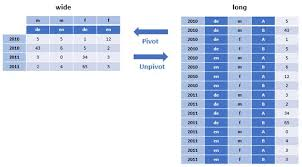
😎 PIVOT 이란? > - 행과 열을 바꾸는 기능이다 세로로 되어 있는 데이터를 가로 형태로 집계할 때 사용한다 데이터의 구조 * 1) LONG DATA (Tidy data)* 하나의 속성이 하나의 컬럼으로 정의되어 값들이 여러 행으로 쌓이는 구조 RDBMS 테
6.SQL) 정규표현식

정규표현식(Regular Expression, RegEx)이란 문자열에서 특정한 패턴을 찾거나, 검사하거나, 바꾸기 위해 사용하는 표현식(패턴 언어)이다 정규표현식 종류정규표현식 함수REGEXP_REPLACE(대상, 찾을문자열, 바꿀문자열, 검색인덱스, 발견횟수, 옵션
7.SQL) Management Statement

😁 관리구문 이란? > 관리 구문(Management Statement)은 데이터베이스에서 객체(테이블, 사용자, 권한, 저장공간 등)를 생성, 변경, 삭제하거나 시스템 자체를 관리할 때 사용하는 SQL 구문을 말함 1. DML (Data Manupulation L
8.SQL) 데이터베이스 아키텍쳐 Ⅰ
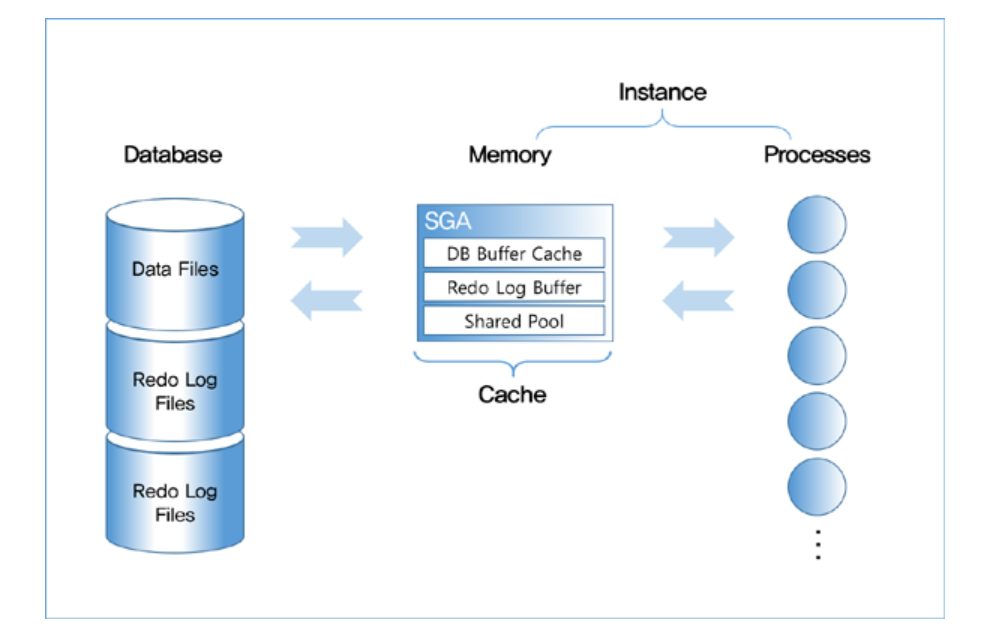
오라클에선 디스크에 저장된 데이터 집합을 데이터베이스라고 한다.SGA 공유 메모리 영역과 이를 액세스하는 프로세스 집합을 합쳐 인스턴스라고 한다.Sever Process -> SQL 파싱, SQL 최적화, 일련의 작업들 수행SGADB Buffer CacheRedo Lo
9.SQL) 데이터베이스 아키텍쳐 Ⅱ
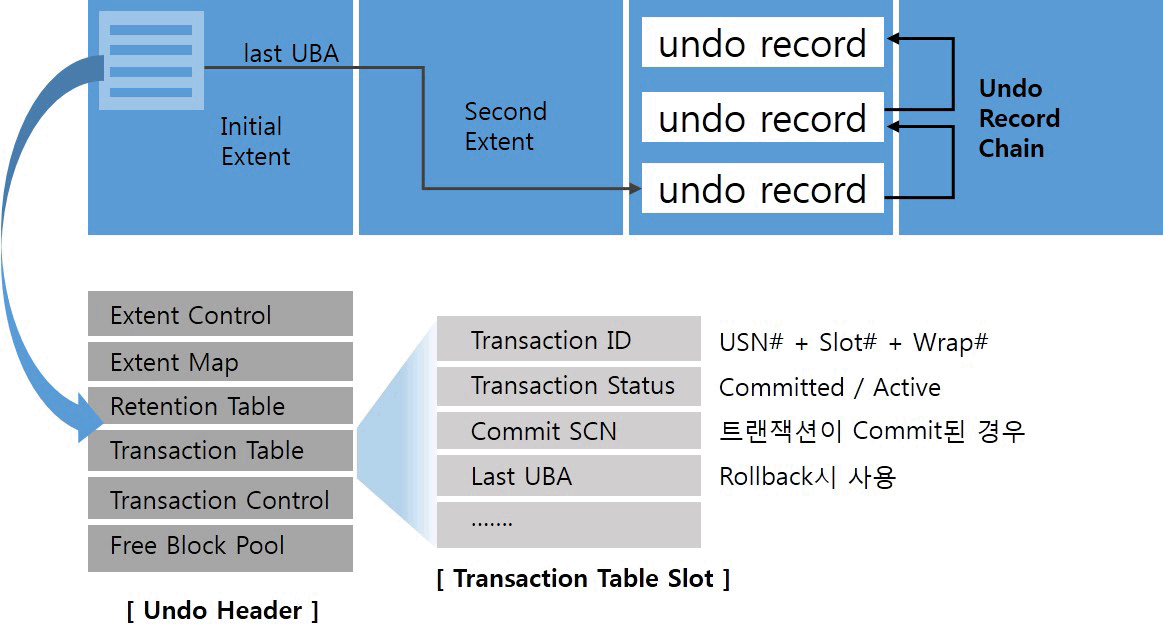
4. Redo 오라클은 데이터 파일과 컨트롤 파일에 가해지는 모든 변경사항을 하나의 Redo 로그 엔트리로서 Redo 로그에 기록한다. Redo 로그는 Online Redo 로그와 Offline(Archived) Redo 로그로 구성된다. Online Redo 로그는
10.SQL) 데이터베이스 아키텍쳐 Ⅲ

6. 문장수준 읽기 일관성 > 데이터베이스에서 읽기 일관성(Read Consistency)이란? 쿼리를 실행하는 동안, 해당 쿼리가 보는 데이터는 “논리적으로 일관된 하나의 시점”이어야 한다는 원칙을 말한다 즉, 내가 SELECT를 실행했을 때 조회되는 데이터는 쿼리
11.SQL) 데이터베이스 아키텍쳐 IV

블록 클린 아웃이 뭐죠?블록 클린아웃은 트랜잭션에 의해 설정된 로우 Lock을 해제하고 블록 헤더에 커밋 정보를 기록하는 오퍼레이션이다. 오라클에서 로우 단위 Lock은 레코드의 속성(Lock Byte)으로 관리되며, 로우 헤더로부터 블록 헤더에 있는 ITL 엔트리를
12.SQL) 데이터베이스 아키텍쳐 Ⅴ

오라클 인스턴스는 많은 프로세스(또는 쓰레드)들이 역할을 분담해서 각자 맡은 바 임무를 수행한다. 함께 일을 하는 동안 프로세스 간 커뮤니케이션과 상호작용이 필요하고 때로는 다른 프로세스가 일을 마칠 때까지 기다려야만 하는 상황이 자주 발생한다. 그러면 오라클 프로세스
13.SQL) 트랜잭션과 Lock Ⅰ

1. 트랜잭션 동시성 제어 > ### 동시성 제어가 뭔데? **동시성 제어(Concurrency Control)이란, 동시에 실행되는 트랜잭션 수를 최대화하면서도 입력, 수정, 삭제, 검색 시 데이터 무결성이 유지될 수 있도록 노력하는것을 말한다.** 여러 개의 트
14.SQL) 트랜잭션과 Lock Ⅱ

동시성 제어는 비관적 동시성 제어와 낙관적 동시성 제어로 나뉜다사용자들이 같은 데이터를 동시에 수정 할 것이라고 가정한다.따라서, 한 사용자가 데이터를 읽는 시점에 Lock을 걸고 조회 또는 갱신처리가 완료될 때까지 이를 유지한다. Locking은 첫 번째 사용자가 트
15.SQL) 트랜잭션과 Lock Ⅲ
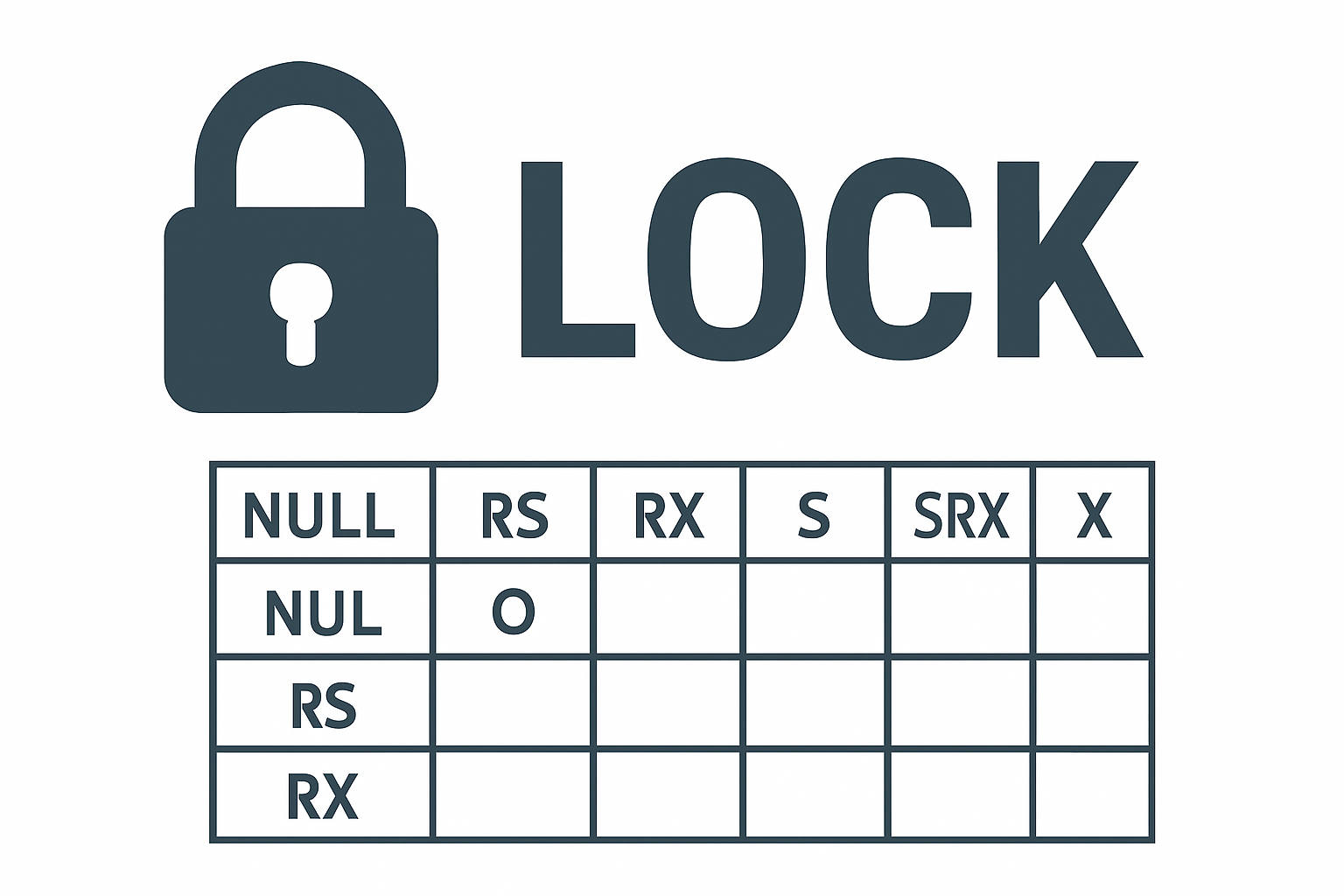
5. 오라클 Lock 오라클은 공유 리소스와 사용자 데이터를 보호할 목적으로 DML Lock, DDL Lock, 래치, 버퍼 Lock, 라이브러리 캐시 Lock/Pin 등 다양한 종류의 Lock 을 사용한다. 이 외에도 내부적으로 많은 Lock이 존재한다. 애플리케
16.SQL) 오라클 성능 관리 Ⅰ

오라클 10g부터는 기본적으로 sys.plan_table 테이블이 만들어진다. 그리고 이를 가리키는 pulbic synonym을 기본적으로 생성해 두기 때문에 사용자가 별도로 plan_table을 만들지 않아도 된다.explain plan for 명령을 수행하고 나면
17.SQL) 오라클 성능 관리 Ⅱ
4. DBMS_XPLAN 패키지 오라클 9.2버전에 소개된 dbmsxplan 패키지를 통해 plantable에 저장된 실행계획을 좀 더 쉽게 출력해 볼 수 있게 되었다. 오라클은 9i부터 plan_table에 더 많은 정보를 담기 시작했고, 이 패키지를 이용하지 않더
18.SQL) 오라클 성능 관리 Ⅲ

7. Response Time Analysis 방법론과 OWI 대기 이벤트를 기반으로 세션 또는 시스템 전체에 발생하는 병목 현상과 그 원인을 해결하는 방법, 과정을 '대기 이벤트 기반' 또는 'Response Time Analysis기반' 성능 관리 방법론이라고 한다. >#### Response Time Analysis 방법론 Response Time...
19.SQL) 라이브러리 캐시 최적화 원리 Ⅰ
SQL 옵티마이저는 최소비용, 최적의 경로를 선택하여 사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 프로시저를 자동으로 생성해 주는 DBMS의 핵심기능이다.사용자가 던진 쿼리 수행을 위해, 후보군이 될만한 실행계획들을 찾아본다데이터 딕셔너리에 미리 수집해 놓은
20.SQL) 라이브러리 캐시 최적화 원리 Ⅱ
커서를 설명하자면, 세 종류의 커서가 있는데 이들을 모두 커서라고 부른다.각 커서들은 상황에 따라 의미도 다르고 저장되는 위치도 다르다.공유 커서 : 라이브러리 캐시에 공유돼 있는 Shared SQL Area세션 커서 : Private SQL Area에 저장된 커서애
21.SQL) 라이브러리 캐시 최적화 원리 Ⅲ
오라클은 자주 수행하는 SQL에 대해서 세션 커서를 세션 커서 캐시에 저장할 수 있는 기능을 제공하는데, 이를 '세션 커서 캐싱' 이라고 한다.이 기능을 활성화하면, 커서를 닫는 순간 해당 커서의 Parse Call 횟수를 보고 그 값이 3보다 크거나 같으면 세션 커서
22.SQL) 라이브러리 캐시 최적화 원리 Ⅳ

Static SQL이란, String형 변수에 담지 않고 코드 사이에 직접 기술한 SQL문을 말한다.String 변수를 사용하지 않아 PreCompile 시 Syntax, Semantics 체크가 가능하다. Dynamic SQL이란, String형 변수에 담아서 기술하
23.SQL) 데이터베이스 Call 최소화 원리 Ⅰ
커서가 파싱하는 과정에 대한 통계로, 실행계획을 생성하거나 찾는 과정에 대한 정보를 포함한다.말 그대로 커서를 실행하는 단계에 대한 통계를 보여준다.select문에서 실제 레코드를 읽어 사용자가 요구한 결과집합을 반환하는 과정에 대한 통계를 보여준다.insert, de
24.SQL) 데이터베이스 Call 최소화 원리 Ⅱ

4. Array Processing 활용 Array Processing 기능을 활용하면 한 번의 SQL 수행으로 다량의 로우를 동시에 insert/update/delete 할 수 있다. 이는 네트워크를 통한 데이터베이스 Call을 감소시켜주고, 궁극적으로 SQL 수행
25.SQL) 데이터베이스 최소화 원리 Ⅲ

PL/SQL이란 PL은 Procedural Language로 절차적 언어를 말하고, 거기에 SQL을 더한 것이다.SQL만으로는 할 수없는 로직들(반복, 조건, 예외처리등)을 절차적 프로그래밍으로 해결한다.대게 이런 구조를 가지고 있다.오라클은 PL/SQL로 작성된 함수
26.SQL) I/O 효율화 원리 Ⅰ
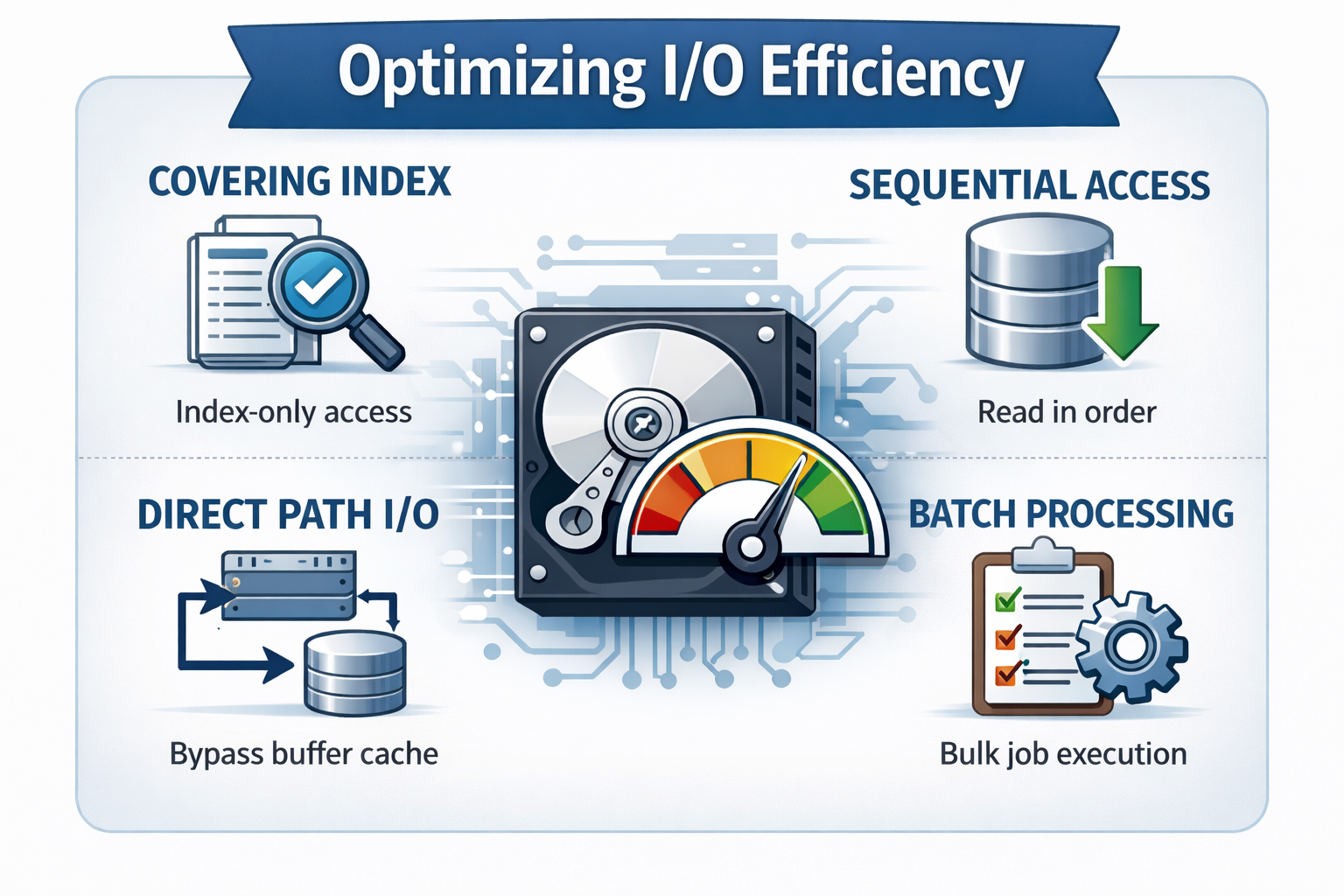
1. 블록 단위 I/O 오라클을 포함한 모든 DMBS에서 I/O는 블록 단위로 이루어진다. 레코드를 하나만 읽을 때도 그 레코드가 포함된 블록을 전체를 읽는다는 의미이다. 위 두 쿼리는 서버에서 발생하는 I/O 측면에서의 일량은 같다. SQL 성능을 좌우하는 가장
27.SQL) I/O 효율화 원리 Ⅱ

데이터베이스 동시 사용자가 많을 때 부하를 분산할 목적으로 시스템마다 다양한 데이터 분산 전략을 사용한다.여러 대의 데이터베이스 서버를 두고 각 서버에서 발생한 트랜잭션 데이터를 상호 복제하는 방식이다.=> 실시간 동기화가 필요할 때는 복제 과정에서 발생하는 부하 때문
28.SQL) 인덱스 원리와 활용 Ⅰ
1. 인덱스 구조
29.SQL) 인덱스 원리와 활용 Ⅱ

쿼리에서 참조되는 컬럼이 인덱스에 모두 포함되는 경우가 아니라면 인덱스 스캔 이후 '테이블 Random 액세스' 가 일어난다.실행계획에서는 'TABLE ACCESS (BY INDEX ROWID) 라고 표시된다.인덱스에 저장돼 있는 rowid는 '물리적 주소정보'라고 보
30.SQL) 인덱스 원리와 활용 Ⅲ

오라클은 Random 액세스가 발생하지 않도록 테이블 아예 인덱스 구조로 생성하는 방법을 제공하는데, 이를 'IOT' 라고 한다.IOT 는 인덱스 구조 테이블이믈 정렬 상태를 유지하며 데이터를 삽입한다.IOT 는 SQL-Server나 Sybases에서 말하는 '클러스터
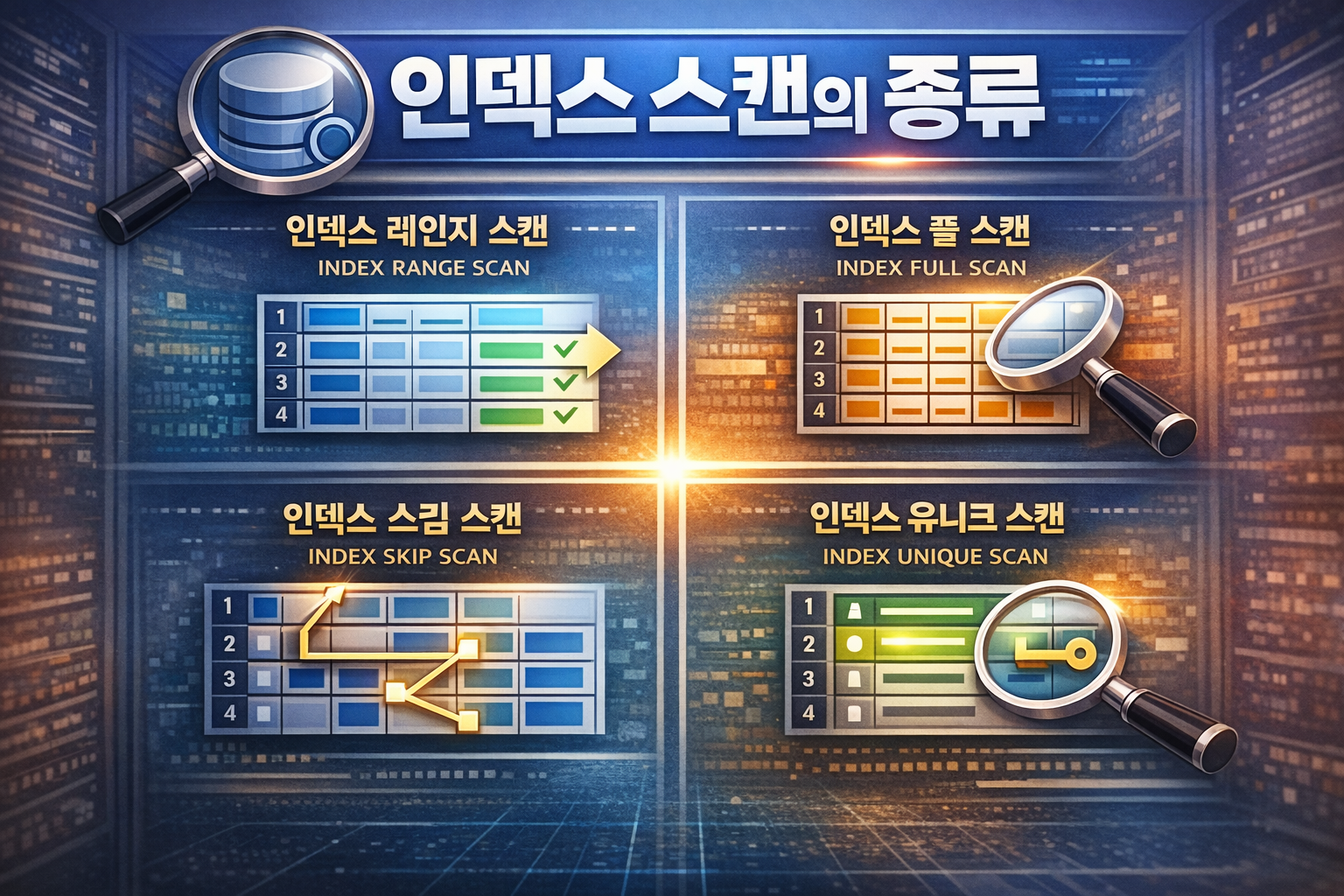
31.SQL) 인덱스 원리와 활용 Ⅳ

7. 인덱스 스캔 효율
32.SQL) 조인 원리와 활용 Ⅰ

1. NL(Nested Loops) 조인 1. 기본 메커니즘 위 Java 이중 for 문 처럼 NL 조인은 'outer 테이블의 하나의 레코드에 inner 테이블의 모든 레코드를 방문한다' 라고 생각하면 된다. 2. 힌트로 NL 조인 제어 위 쿼리에서 order
33.SQL) 조인 원리와 활용 Ⅱ
4. 조인 순서의 중요성 1. 필터 조건이 없을 때 다른 필터 조건이 없는 상황에서는 작은 쪽 집합을 Outer 테이블로 하는 것이 유리하다.
34.SQL) 옵티마이저 원리 Ⅰ

1. 옵티마이저 옵티마이저는 사용자가 요청한 SQL을 가장 효율적이고 빠르게 수행할 수 있는 최적의 처리결로를 선택해 주는 DBMS의 핵심엔진이다. SQL로 사용자가 원하는 결과집합을 정의하면 옵티마이저가 이를 얻는 데 필요한 프리절차를 자동으로 생성해준다. 1.
35.SQL) 옵티마이저 원리 Ⅱ

실행계획을 수립할 때 CBO는 SQL 문장에서 액세스할 데이터 특성을 고려하기 위해 통계정보를 이용한다.따라서 최적의 실행계획을 위해서는 통계정보가 데이터 상태를 정확하게 반영하도록 관리해 주어야 한다.테이블 통계만 수집할 때는 아래 명령어를 사용하며, compute는
36.SQL) 옵티마이저 원리Ⅲ

6. 히스토그램 히스토그램이 있으면 더 정확한 카디널리티를 구할 수 있다. 특히, 분포가 균일하지 않은 컬럼으로 조회할 때 효과를 발휘한다. 히스토그램을 생성하려면 버킷 개수를 2 이상(size 옵션) 지정하면 된다. 히스토그램 정보는 dbahistograms 또는
37.SQL) 쿼리 변환 Ⅰ

쿼리 변환은 쿼리 옵티마이저가 SQL을 분석해 의미적으로 동일하면서도 더 나은 성능이 기대되는 형태로 재작성하는 것을 말한다.본격적으로 최적화를 하기 전에 사전 정지 작업을 하는 것이라고 말할 수 있다.결과만 보장된다면 무조건 쿼리 변환을 수행한다.일종의 규칙 기반 최
38.SQL) 쿼리 변환 Ⅱ

4. 조건절 Pushing 이떤 이유에서건 뷰 Merging 을 실패했을 때, 옵티마이저는 포기하지 않고 2차적으로 조건절 Pushing을 시도한다. 조건절 Pushing은 참조하는 쿼리 블록의 조건절을 뷰 쿼리 블록 안으로 Pushing 하는 기능을 말한다. 조건
39.SQL) 쿼리 변환 Ⅲ

Outer 조인문을 작성하면서 일부 조건절에 Outer 기호(+)를 빠뜨리면 Inner 조인할 때와 같은 결과가 나온다.이럴 때 옵티마이저는 Outer 조인을 Inner 조인문으로 바꾸는 쿼리 변환을 시행한다.옵티마이저가 굳이 이런 쿼리 변환을 시행하는 이유는 조인 순
40.SQL) 소트 튜닝 Ⅲ

6. Sort Area를 적게 사용하도록 SQL 작성 만약 소트 오퍼레이션 처리가 불가피하다면 메모리 내에서 처리를 완료할 수 있게 해야하고, Sort Area의 크기를 늘리는 방법도 있지만 그 전에 Sort Area를 적게 사용하도록 하는 방법을 찾아야 한다. 1
41.SQL) 파티셔닝 Ⅰ
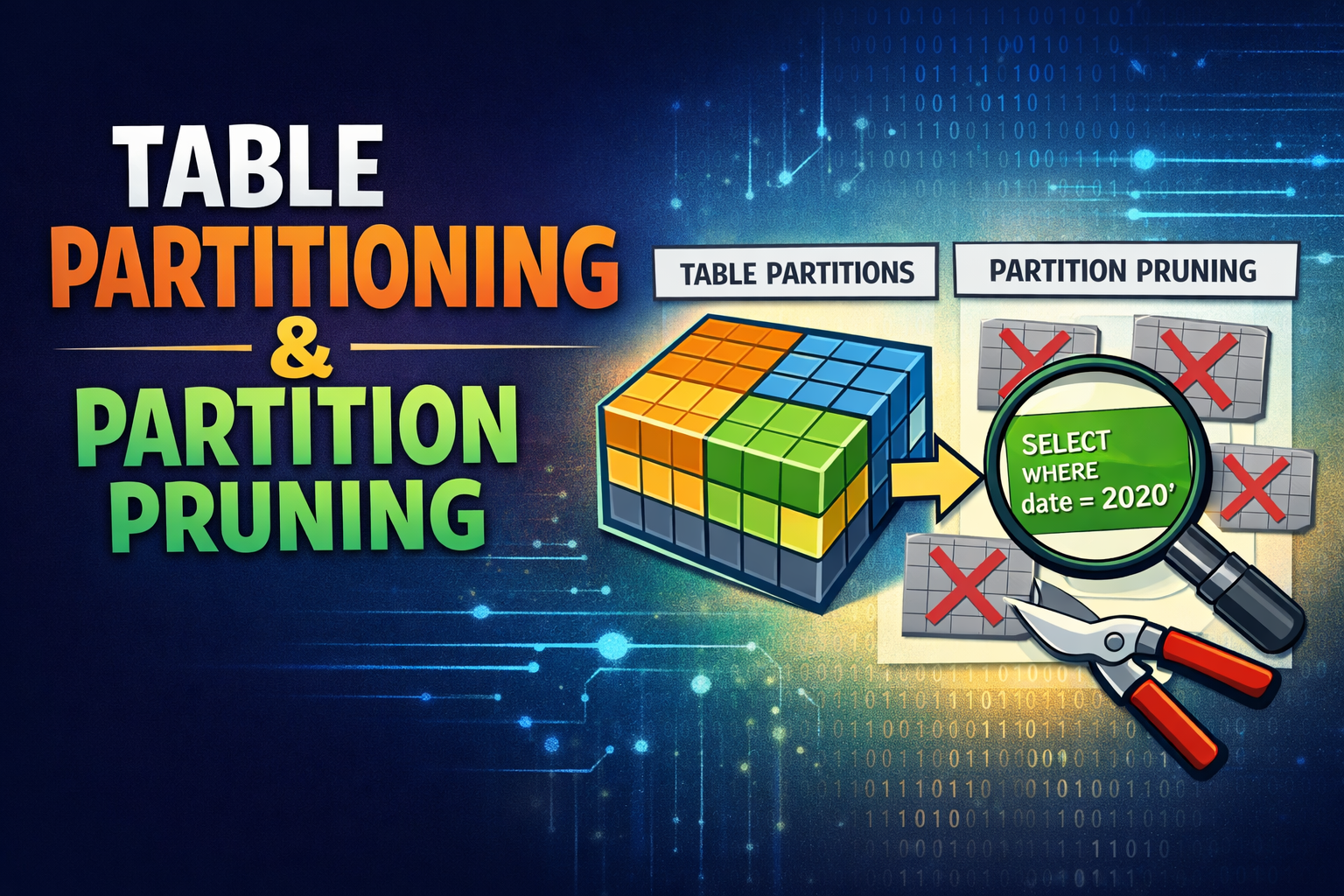
1. 테이블 파티셔닝 파티셔닝은 테이블과 인덱스 데이터를 파티션단위로 나누어 저장하는 것을 말한다. 테이블을 파티셔닝하면 하나의 테이블일지라도 파티션 키에 따라 물리적으로는 별도의 세그먼트에 데이터가 저장되며, 인덱스도 마찬가지다. ✅ 파티셔닝이 필요한 이유 관리적
42.SQL) 파티셔닝 Ⅱ

3. 인덱스 파티셔닝 1. 인덱스 파티션 유형
43.SQL) 병렬 처리 Ⅰ
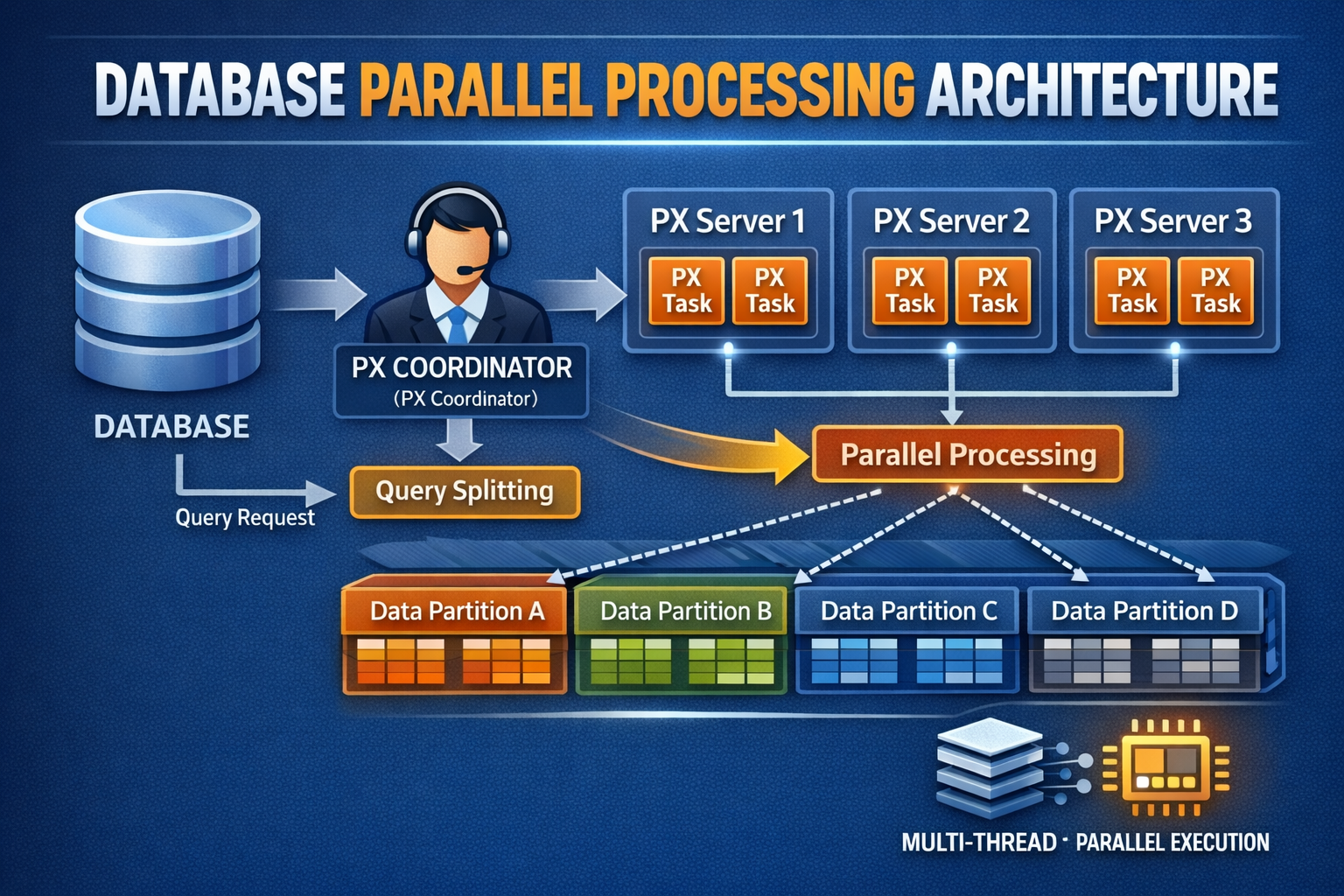
1. 병렬 처리 병렬 처리란, SQL 문이 수행해야 할 작업 범위를 여러 작은 단위로 나누어 여러 프로세스나 쓰레드가 동시에 처리하는 것을 말한다. 1. Query Coordinator과 병렬 서버 프로세스 QC (Query Coordinator) 는 병렬 SQL문을
44.SQL) 병렬 처리 Ⅱ

2. 병렬 Order by와 Group by 1. 병렬 Order by order by를 병렬로 수행하려면 테이블 큐를 통한 데이터 재분배가 필요한데, 쿼리 수행이 완료된 직후에 같은 세션에서 v$pq_tqstat를 쿼리해 보면 테이블 큐를 통한 데이터 전송 통계를
45.SQL) 병렬 처리 Ⅲ

pq_distribute 힌트를 사용해 옵티마이저의 선택을 무시하고 사용자가 직접 조인을 위한 데이터 분배 방식을 결정할 수 있다.Parallel Query Distribution => 병렬 쿼리 분배라는 의미옵티마이저가 파티션된 테이블을 적절히 활용하지 못하고 동적
46.🚨 긴급정리
🚨 SQL 긴급 정리 Undo Retention 트랜잭션이 완료된 후에 바로 Undo 데이터를 재사용하지 말아라고 오라클에게 힌트를 주는 것 슬롯 ITL -> 트랜잭션 ID, status, UBA(Undo Block Address), 커밋 SCN(트랜잭션 성공 시