1. Call 통계
Call 통계 종류
1. Parse Call
커서가 파싱하는 과정에 대한 통계로, 실행계획을 생성하거나 찾는 과정에 대한 정보를 포함한다.
2. Execute Call
말 그대로 커서를 실행하는 단계에 대한 통계를 보여준다.
3. Fetch Call
select문에서 실제 레코드를 읽어 사용자가 요구한 결과집합을 반환하는 과정에 대한 통계를 보여준다.
insert, delete, update, merge 등 DML문은 Execute Call 시점에 모든 처리과정을 서버 내에서 완료하고 처리결과만 리턴하므로 Fetch Call이 전혀 발생하지 않는다.
insert - select문도 마찬가지다. 클라이언트로부터 명시적인 Fetch Call을 받지 않으며 서버 내에서 묵시적으로 Fetch가 이루어진다.
select문일 때 Execute Call 단계에서는 커서를 오픈하고, 실제 데이터를 처리하는 과정은 모두 Fetch 단계에서 일어난다.
for update 구문을 사용하면 Execute 단계에서 모든 레코드를 읽어 Lock을 설정한다.
2. User Call vs Recursive Call
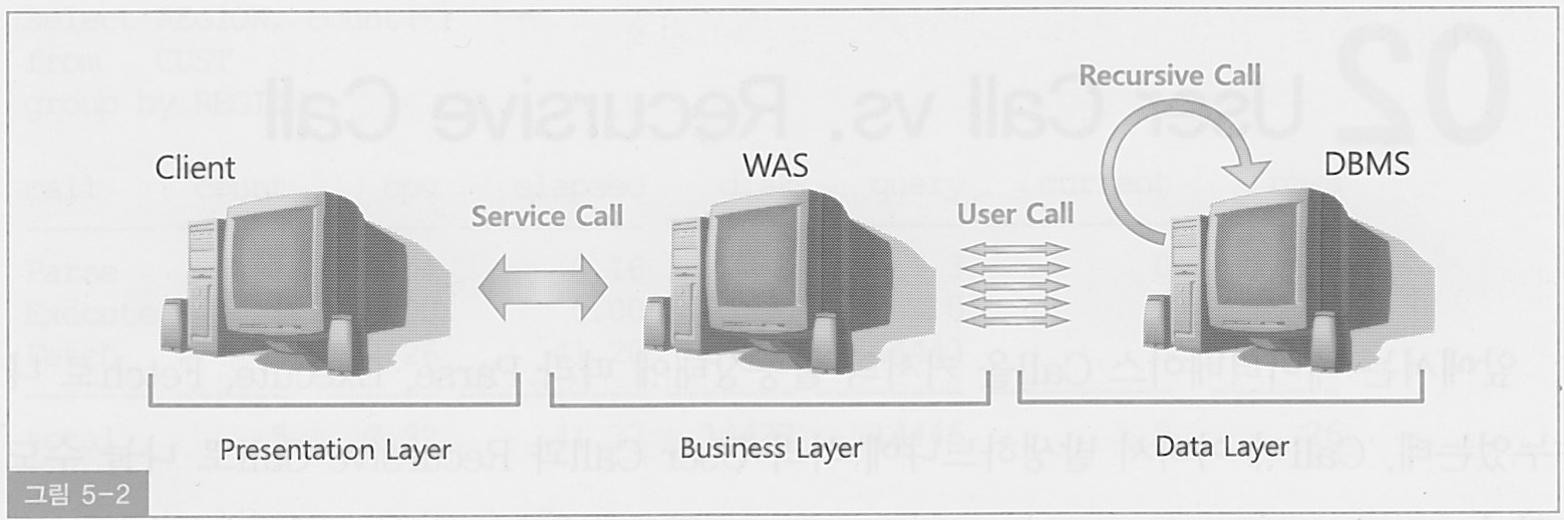
User Call 이란?
User Call 이란 OCI(Oracle Call Interface)를 통해 오라클 외부로부터 들어오는 Call을 말한다. User Call이 클라이언트가 아닌 WAS에서 발생하는 이유는 실제 사용자가 어디에 위치하느냐와는 별개로 DBMS 입장에서의 사용자는 WAS이기 때문이다.
동시 접속자 수자 적을 때는 잘 드러나지 않지만, Peak 시간대에 시스템 장애를 발생시키는 가장 큰 주범은 User Call이다.
DBMS 성능과 확장성을 높이려면 User Call을 최소화해햐 한다.
User Call 을 최소화하는 기능과 기술들
-
Loop 쿼리를 해소하고 집합적 사고를 통해 ONE-SQL로 구현
-
Array:Processing : Array 단위 Fetch, Bulk Insert/Update/Delete
-
부분범위처리 원리 활용
-
효과적인 화면 페이지 처리
-
사용자 정의 함수/프로시저/트리거의 적절한 활용
Recursive Call 이란?
Recursive Call 이란 오라클 내부에서 발생하는 Call을 말한다.
SQL 파싱과 SQL 최적화 과정에서 발생하는 Data Dictionary 조회, PL/SQL로 작성된 사용자 정의 함수/프로시저/트리거 내에서의 SQL 수행이 여기에 해당한다.
Recursive Call 을 최소화하는 방법
-
바인드 변수를 적극적으로 사용해 하드파싱 발생횟수를 줄여야 한다.
-
PL/SQL로 작성한 프로그램이 어떤 특징을 가지고 내부적으로 어떻게 수행되는지를 잘 이해하고 시의 적절하게 사용한다.
-> PL/SQL은 가상머신상에서 수행되는 인터프리터언어이므로 빈번한 호출 시 컨텍스트 스위칭 때문에 성능이 매우 나빠진다. -
대용량 데이터를 조회할 때는 함수를 부분범위처리가 가능한 상황에서 제한적으로 사용해야 하고, 될 수 있으면 조인 또는 스칼라 서브쿼리 형태로 변환한다.
3. 데이터베이스 Call이 성능에 미치는 영향
한 Java 프로그램에서 총 쿼리 소요시간이 127초인데 반해 서버에서의 일량은 훨씬 못 미쳤다.
순수하게 서버에서 처리한 시간은 10여초이고 나머지는 모두 네트워크 구간에서 소비한 시간, 데이터베이스 Call이 발생할 때마다 매번 OS로 부터 CPU와 메모리 리소스를 할당받으려고 소비한 시간이다.
User Call이 Recursive Call보다 더 심각한 부하를 일으키는 이유이다.
그 Java 코드를 ONE-SQL로 통합하니 1초도 채 걸리지 않았다.
이 사실은 ONE-SQL로 로직을 통합했을 때 극적으로 성능 개선이 이루어지는 원리가 데이터베이스 Call 횟수를 줄이는 데에 있음을 반증한다.
물론 ONE-SQL을 구현해 데이터베이스 Call을 줄이는 것도 중요하지만 I/O 효율을 고려한 ONE-SQL을 만들어야 한다.
I/O 효율의 핵심은 동일 레코드를 반복 액세스하지 않고 얼마만큼 블록 액세스 양을 최소화할 수 있느냐에 달려있다.
