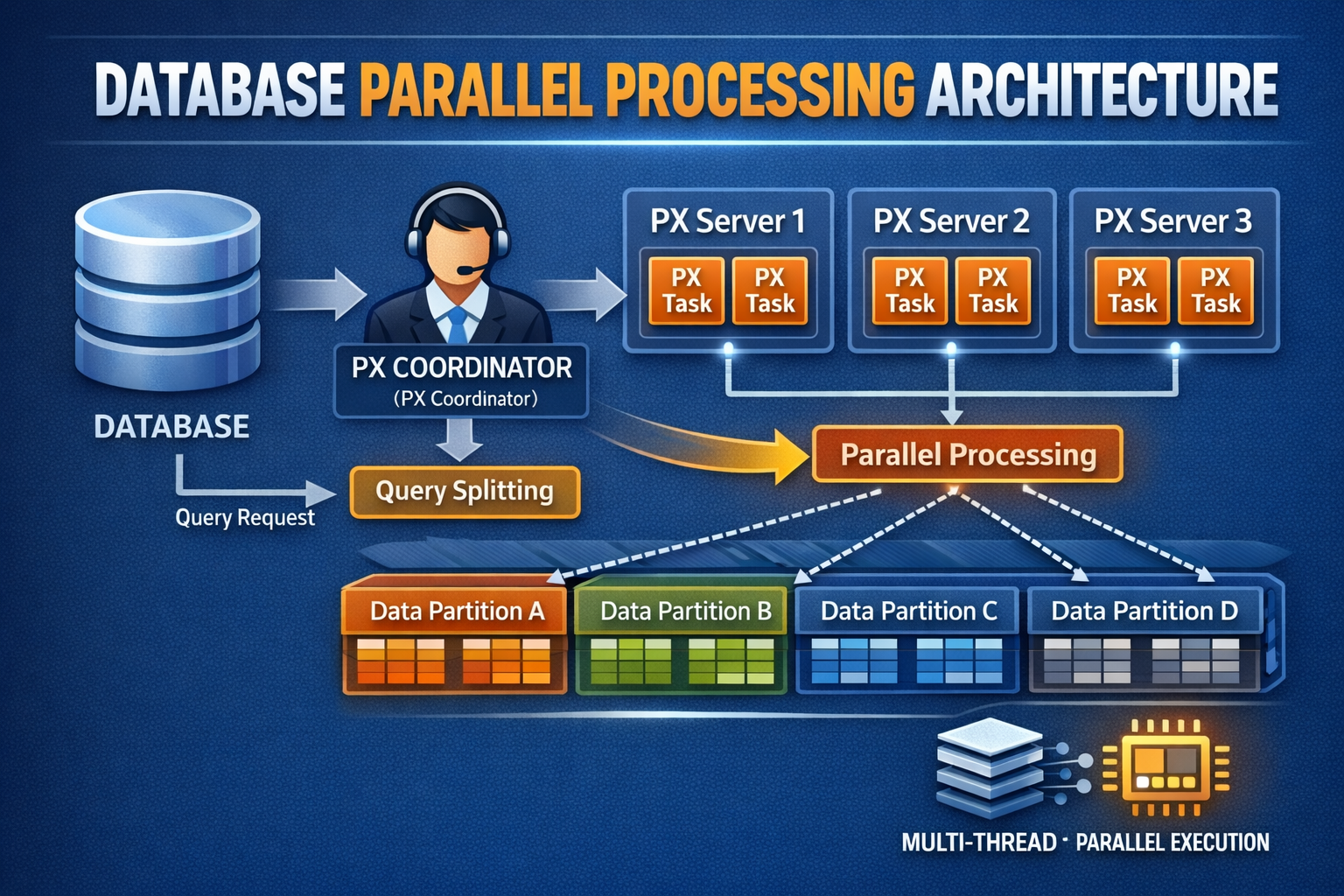
1. 병렬 처리
병렬 처리란, SQL 문이 수행해야 할 작업 범위를 여러 작은 단위로 나누어 여러 프로세스나 쓰레드가 동시에 처리하는 것을 말한다.
1. Query Coordinator과 병렬 서버 프로세스
QC (Query Coordinator) 는 병렬 SQL문을 발행한 세션을 말하고, 병렬 서버 프로세스는 실제 작업을 수행하는 개별 세션들을 말한다.
QC의 역할
-
병렬 SQL이 시작되면 QC는 사용자가 지정한 병렬도(DOP)와 오퍼레이션 종류에 따라 하나 또는 두 개의 병렬 서버 집합을 할당한다.
먼저 서버 풀로부터 필요한 만큼 서버 프로세스를 확보하고, 부족한 서버 프로세스는 새로 생성한다. -
QC는 각 병렬 서버에게 작업을 할당한다.
-
병렬로 처리하도록 사용자가 지시하지 않은 테이블은 QC가 직접 처리한다.
-
QC는 각 병렬 서버로부터 결과를 통합하는 작업을 수행한다.
-
QC는 쿼리의 최종 결과집합을 사용자에게 전송하며, DML 일 때는 갱신 건수를 집계해서 전송해준다.
쿼리 결과를 전송하는 단계에서 수행되는 스칼라 서브쿼리도 QC가 수행한다.
병렬 처리에서 실제 QC 역할을 담당하는 프로세스는 SQL문을 발행한 사용자 세션 자신이다.
2. Operation Parallelism
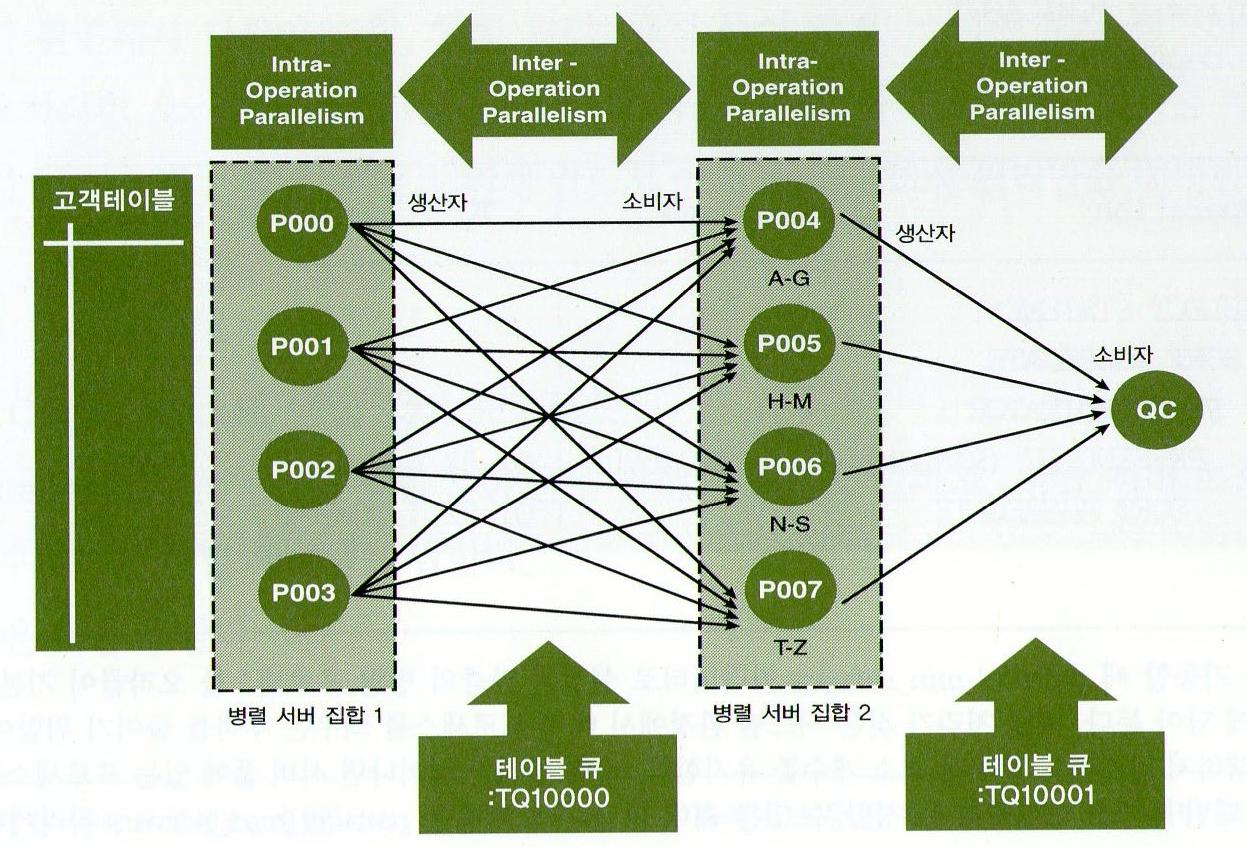
Intra-Operation Parallelism과 Inter-Operation Parallelism으로 나뉜다.
1. Intra-Operation Parallelism
한 병렬 서버 집합에 속한 여러 프로세스가 서로 배타적인 범위를 독립적으로 동시에 처리하는 것으로, 하나의 오퍼레이션을 동시에 병렬처리 하는 것이다.
이때는 절대로 통신이 발생하지 않는다.
2. Inter-Operation Parallelism
서로 다른 오퍼레이션을 동시에 병렬 처리하는 것이다.
이때는 항상 프로세스 간 통신이 발생된다.
3. 테이블 큐
쿼리 서버 집합 간(P->P) 또는 QC와 쿼리 서버 집합 간(P->S, S->P) 데이터 전송을 위해 연결된 파이프 라인을 '테이블 큐' 라고 한다.
테이블 큐에 부여된 :TQ10000, :TQ10001 같은 이름을 '테이블 큐 식별자' 라고 한다.
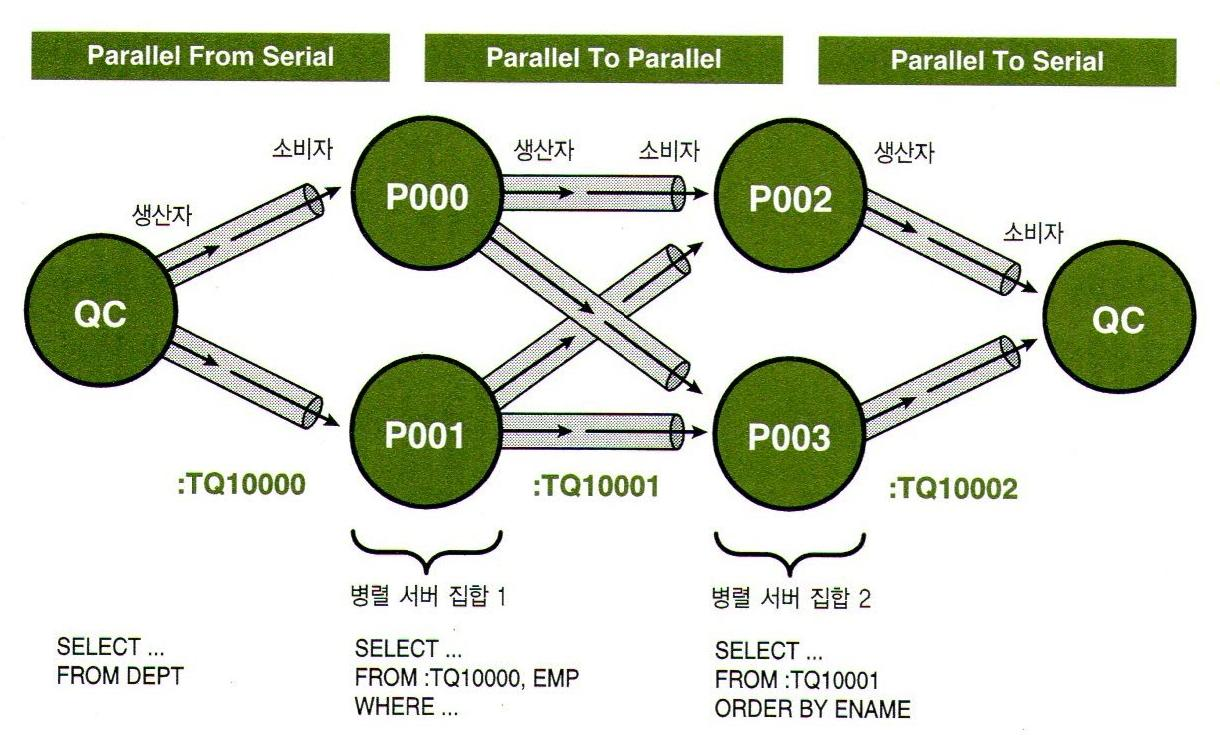
쿼리 서버 집합 간 (P->P) Inter-Parallelism이 발생할 때는 병렬도의 배수(x2)만큼 서버 프로세스가 필요하다.
테이블 큐에는 병렬도의 제곱(^2)만큼 파이프 라인이 필요하다. (P->P)
✅ 소비자 / 생산자 모델
테이블 큐에는 항상 생산자와 소비자가 존재한다.
파이프라인의 시작이 생산자이고 도착이 소비자이다.
select문장의 최종 소비자는 항상 QC가 될 것이다.
Inter-Operation Parallelism이 나타날 때, 소비자 서버 집합은 from절에 테이블 큐를 참조하는 서브 SQL을 가지고 작업을 수행한다.
✅ 병렬 실행계획에서 생산자와 소비자 식별
10g 이후부터는 생산자에 'PX SEND' , 소비자에 'PX RECEIVE' 가 표시되므로 테이블 큐를 통한 데이터 분배 과정을 좀 더 쉽게 알 수 있게 되었다.
각 오퍼레이션이 어떤 서버 집합에 속한 병렬 프로세스에 의해 수행되는지는 'TQ' 컬럼이 보이는 서버 집합 식별자를 통해 확인할 수 있다.
통신이 일어날 때마다 'NAME' 컬럼에 테이블 큐가 표시된다.
4. 'IN-OUT' 컬럼 정보
IN-OUT 컬럼의 정보는 plan_table을 쿼리할 때 other_tag 컬럼에서 가져온 것이며, 병렬 쿼리를 이해하는 데에 매우 중요한 정보를 제공한다.
✅ S->P : PARALLEL_FROM_SERIAL
QC가 읽은 데이터를 테이블 큐를 통해 병렬 서버 프로세스에게 전송하는 것이다.
✅ P->S : PARALLEL_TO_SERIAL
각 병렬 서버 프로세스가 처리한 데이터를 QC에게 전송하는 것이다.
병렬 프로세스로부터 QC로 통신이 발생하므로 Inter-Operation Parallelism에 속한다.
'PQ Distrib' 컬럼에 QC(ORDER) 라고 표시된 것은 QC에게 결과 데이터를 전송할 때 첫 번째 병렬 프로세스부터 마지막 병렬 프로세스까지 순서대로 진행함을 의미하며, SQL이 order by절을 포함할 때 나타난다.
order by가 없을 때는 QC(RANDOM)이라고 표시되며 병렬 프로세스들이 무순위로 QC에게 데이터를 전송함을 의미한다.
✅ P->P : PARALLEL_TO_PARALLEL
P->P가 나타날 때면 해당 오퍼레이션을 두 개의 서버 집합이 처리한다.
따라서 사용자가 지정한 병렬도보다 2배수만큼 병렬 프로세스가 필요하다.
데이터를 정렬 또는 그룹핑하거나 조인을 위해 동적으로 파티셔닝할 때 사용되며, 첫 번째 병렬 서버 집합이 읽거나 가공한 데이터를 두 번째 병렬 서버 집합에 전송하는 과정에서 병렬 프로세스간 통신이 발생하므로 Inter-Operation Parallelsim에 속한다.
✅ PCWP : PARALLEL_COMBINED_WITH_PARENT
한 서버 집합이 현재 스텝과 그 부모 스텝을 모두 처리함을 의미한다.
PCWP도 병렬 오퍼레이션이지만 한 서버 집합 내에서는 프로세스 간 통신이 발생하지 않으므로 Intra-Operation Parallelism에 속한다.
즉, 한 서버 집합에 속한 서버 프로세스들이 각자 맡은 범위 내에서 두 스텝 이상의 오퍼레이션을 처리하는 것이며, 자식 스템의 처리 결과를 부모 스텝에서 사용할 뿐 프로세스 간 통신은 필요하지 않다.
✅ PCWC : PARALLEL_COMBINED_WITH_CHILD
한 서버 집합이 현재 스텝과 그 자식 스텝을 모두 처리함을 의미한다.
PCWC도 병렬 오퍼레이션이지만 한 서버 집합 내에서는 프로세스 간 통신이 발생하지 않으므로
Intra-Operation Parallelism에 속한다.
정리
-
S->P, P->P, P->S는 프로세스 간 통신 발생
-
PCWP, PCWC는 프로세스간 통신이 발생하지 않고, 각 병렬 서버가 독립적으로 여러 스텝을 처리할 떄 나타남. 하위 스텝의 출력 값이 상위 스텝의 입력 값으로 사용
-
P->P, P->S, PCWP, PCWS는 병렬 오퍼레이션인 반면 S->P는 직렬 오퍼레이션이다.
병렬 쿼리 실행계획에 S->P가 나타난다면 해당 오퍼레이션이 병목 지점인지 확인해 봐야 한다.
대용량 데이터량을 처리한다면 병렬 오퍼레이션으로 바꾸는 것을 고려해야 한다.
5. 데이터 재분배
IN-OUT 오퍼레이션 중에서 S->P, P->P가 데이터 재분배와 연관이 있다.
데이터 재분배 방식은 5가지가 있다.
1. RANGE (P->P)
order by 또는 sort group by를 병렬로 처리할 때 사용된다.
정렬 작업을 맡은 두 번째 서버 집합의 프로세스마다 처리 범위를 지정하고 나서, 데이터를 읽는 첫 번째 서버 집합이 두 번째 서버 집합의 정해진 프로세스에게 "정렬 키 값에 따라" 분배하는 방식이다.
2. HASH (P->P, S->P)
조인이나 hash group by를 병렬로 처리할 때 사용된다.
조인 키나 group by 키 값을 해시 함수에 적용하고 리턴된 값에 데이터를 분배하는 방식이다.
3. BROADCAST (P->P, S->P)
QC나 첫 번째 서버 집합에 속한 프로세스들이 각각 읽은 데이터를 두 번째 서버 집합에 속한 "모든" 병렬 프로세스에게 전송하는 방식이다.
병렬 조인에서 크기가 매우 작은 테이블이 있을 때 사용된다.
4. KEY
특정 컬럼들을 기준으로 테이블 또는 인덱스를 파티셔닝할 때 사용하는 분배 방식이다.
실행계획에는 PARTITION(KEY) 로 표시된다.
-
Partial Partition-Wise 조인
-
CTAS문장으로 파티션 테이블을 만들 때
-
병렬로 글로벌 파티션 인덱스를 만들 때
5. ROUND-ROBIN
파티션키, 정렬 키, 해시 함수 등에 의존하지 않고 반대편 병렬 서버에 무작위로 골고루 분배시켜
데이터를 분배할 때 사용된다.
6. Granule
데이터를 병렬로 처리할 때 일의 최소 단위를 'Granule' 이라고 하며, 병렬 서버는 한 번에 하나의 Granule씩만 처리한다.
✅ 블록 Granule
블록 기반 Granule은, 파티션 테이블 여부와 상관없이 병렬 오퍼레이션에 적용되는 기본 작업 단위이다.
9iR2부터는 파티션 여부, 파티션 개수와 무관하게 병렬도를 지정할 수 있다.
실행계획 상에는 'PX BLOCK ITERATOR' 라고 표시된다.
Granule 크기와 총 개수는 오브젝트 사이즈와 병렬도에 따라 QC가 동적으로 결정한다.
✅ 파티션 Granule
파티션 기반 Granule은, 각 병렬 서버 프로세스들이 할당받은 테이블 파티션 전체를 처리할 책임을 진다.
한 파티션을 두 개 프로세스가 함께 처리할 수 없으니 병렬도는 파티션 개수 이하로만 지정할 수 있다.
실행계획 상에는 'PX PARTITION RANGE ALL' 이나 'PX PARTITION RANGE ITERATOR' 이라고 표시된다.
ALL은 파티션 전체, ITERTOR은 일부 파티션만 읽는다.
Granule 개수가 테이블과 인덱스의 파티션 구조에 의해 정적으로 결정된다.
병렬도보다 파티션 개수가 상당히 많을 때 유용하다. (약 3배)
파티션 Granule의 작업 수행
-
Partition-Wise 조인 시
-
파티션 인덱스를 병렬로 스캔하거나 갱신할 때
-
9iR2 이전에서의 병렬 DML
-
파티션 테이블 또는 파티션 인덱스를 병렬로 생성할 때
