1. 인덱스 구조
인덱스랑 대용량 테이블에서 필요한 데이터만 빠르고 효율적으로 액세스할 목적으로 사용하는 오브젝트이다.
인덱스는 키 컬럼 순으로 정렬돼 있기 때문에 특정 위치에서 스캔을 시작해 검색 조건에 일치하지 않는 값을 만나는 순간 멈출 수 있다.
=> 이것을 '범위 스캔' 이라함
테이블에서의 범위 스캔 = IOT
IOT를 제외하면 테이블에서는 범위 스캔을 할 수 없음
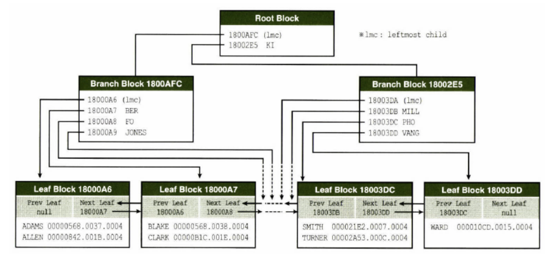
루트 블록, 브랜치 블록 : 하위 노드를 찾아가기 위한 DBA(블록 주소) 정보를 가진다.
리프 블록 : 인덱스 키 컬럼과 함께 테이블 레코드를 찾아가기 위한 주소정보 (rowid)를 가진다.
LMC (LeftMost Child) 란?
브랜치블록은 하위 노드를 찾아가기 위한 DBA(블록 주소)를 가진다고 했는데, 맨 위의 엔트리는 LMC라고 부르며 자식 노드 중 가장 왼쪽의 블록을 가르킨다.
가지고 있는 DBA의 키 값중 가장 작은 값을 나타낸다.
오라클은 인덱스 구성 컬럼이 모두 null인 컬럼은 저장하지 않는다.
이 경우를 제외하면 인덱스와 테이블 레코드 간에는 서로 1:1 대응 관계를 갖는다.
클러스터 인덱스는 1:M 관계를 갖는다.
브랜치 블록에 저장된 레코드 개수는 하위 리프 노드의 개수와 같다.
레코드 = 엔트리 = DBA 같은 뜻이다.
인덱스와 테이블 레코드 간 1:1 대응 관계를 갖기 때문에 테이블 레코드에서 값이 갱신되면 리프 노드 인덱스 키 값도 같이 갱신된다.
하지만, 리프 노드의 엔트리 키 값이 갱신되더라도 브랜치 노드까지 값이 바뀌진 않는다.
인덱스 탐색
인덱스 탐색 과정은 수직적 탐색과 수평적 탐색으로 나뉜다.
수직적 탐색은 수평적 탐색을 위한 시작 지점을 찾는 과정이며, 수평적 탐색은 리프 블록을 인덱스 레코드 간 논리적 순서에 따라 좌우로 스캔하는 것을 말한다.
브랜치 블록을 스캔할 때는 뒤에서부터 스캔하는 방식이 유리하다.
결합 인덱스 스캔시 모든 인덱스 조건에 맞는 리프 블록부터 스캔한다.
rowid 포맷
rowid에는 데이터파일 번호, 블록 번호, 로우 번호 같은 테이블 레코드의 물리적 위치정보를 저장한다.
테이블 레코드를 찾아가는 데 필요한 정보이므로 테이블 자체에 저장되는 것이 아니라 인덱스에 저장된다.
그러면 인덱스를 거치지 않는 쿼리에서 rowid를 어떻게 출력할까?
오브젝트 및 데이터파일 번호, 그리고 그 파일 내에서의 상대적인 블록 번호가 데이터 블록 헤더에 저장돼있기 때문에 레코드를 읽는 시점에, 현재 도달한 블록 헤더와 각 레코드에 할당된 슬롯 번호를 이용해 충분히 가공해 낼 수 있다.
그러면 인덱스에 저장되는 rowid는 얼마만큼의 공간을 차지할까?
이건 오라클 버전과 경우에 따라 다르다.
-
오라클 7 버전 (제한 rowid 포맷)
rowid = 블록번호(8자리) + 로우번호(4자리) + 데이터파일번호(4자리) => 6byte
-
오라클 8 버전 (확장 rowid 포맷)
rowid = 데이터오브젝트번호(6자리) + 데이터파일번호(3자리) + 블록번호(6자리) + 로우번호(3자리) => 10byte
파티션되지 않은 일반 테이블에 생성한 인덱스와 파티션된 테이블에 생성한 로컬 파티션 인덱스는 8버전에도 6byte를 차지한다.
2. 인덱스 기본 원리
B*Tree 인덱스를 정상적으로 사용하려면 범위 스캔 시작지점을 찾기 위해 루트 블록부터 리프 블록까지의 수직적 탐색 과정을 거쳐야 한다.
인덱스 선두 컬럼이 조건절에 사용되지 않거나 가공한다면 범위 스캔을 위한 시작점을 찾을 수 없어 옵티마이저는 테이블이나 인덱스를 전체 스캔한다.
(1) 인덱스 범위 스캔이 불가능한 경우
-
인덱스 컬럼을 조건절에서 가공
-
부정형 비교 사용 (<>, is not null등)
(2) 인덱스 사용이 불가한 경우
is null 조건으로 검색한 경우
=> 그 컬럼이 not null 제약조건이라면 인덱스 사용 가능
=> 인덱스 선두 컬럼이 누락되지 않고 다른 인덱스 구성 컬럼에 is null 이외의 조건식이 하나라도 있으면 인덱스 사용 가능
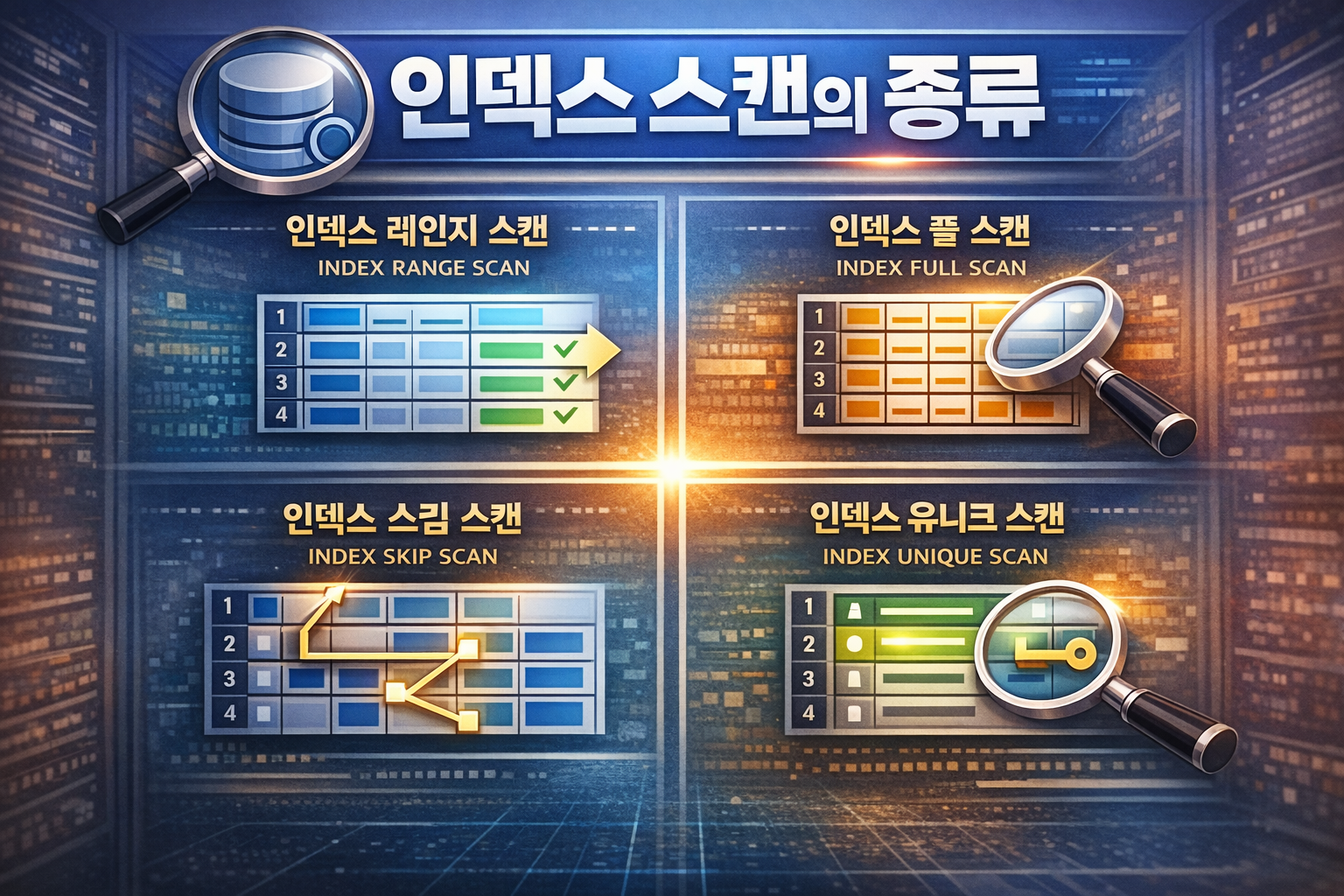
3. 인덱스 스캔 방식
1. Index Range Scan
Index Range Scan 은 인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한후에 리프 블록을 필요 범위만 스캔하는 방식이다.
B*Tree 인덱스의 가장 일반적이고 정상적인 형태의 액세스 방식이다.
인덱스 스캔하는 범위를 얼마만큼 줄일 수 있느냐 그리고 테이블로 액세스하는 횟수를 얼마만큼 줄일 수 있느냐가 관건이며, 이는 인덱스 설계와 SQL 튜닝의 핵심 원리이다.
Index Range Scan이 가능하게 하려면 인덱스 선두 컬럼이 조건절에 사용되어야 한다.
그렇지 못한 상황에서 인덱스를 사용하도록 강제로 힌트를 주게 되면 Index Full Scan 방식으로 처리된다.
Index Range Scan 과정을 거쳐 생성된 결과집합은 인덱스 컬럼 순으로 정렬된 상태가 되기 때문에 이런 특징을 잘 이용하면 소트 연산을 생략하거나 min/max 값을 빠르게 추출할 수 있다.
2. Index Full Scan
Index Full Scan은 수직적 탐색 없이 처음부터 끝까지 수평적으로 탐색하는 방식으로서, 대게는 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택한다.
수직적 탐색이 없다고 하지만 가장 왼쪽 리프 블록을 찾가가기 위해 왼쪽으로만 수직적 탐색을 시도한다.
✅ Index Full Scan 의 효용성
인덱스 선두 컬럼이 조건절에 없으면 옵티마이저는 우선적으로 Table Full Scan을 고려한다.
하지만 대용량 테이블이라 Table Full Scan 을 사용하기에 부담이 크다면 옵티마이저는 인덱스를 활용하는 방법을 다시 생각해 본다.
만약 테이블 전체를 스캔하기보다 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하도록 할 수 있다면 전체적인 I/O 효율 측면에서 이 방식이 유리하고, 이럴 때 Index Full Scan 방식을 선택할 수 있다.
✅ 인덱스를 이용한 소트 연산 대체
Index Full Scan은 Index Range Scan과 같이 결과집합이 인덱스 컬럼 순으로 정렬되므로 소트 연산을 생략할 목적으로 사용될 수도 있다.
3. Index Unique Scan
Index Unique Scan 은 수직적 탐색만으로 데이터를 찾는 스캔 방식으로, Unique 인덱스를 통해 '=' 조건으로 탐색하는 경우에 작동한다.
Unique 인덱스가 존재하는 컬럼은 중복 값이 발생하지 않도록 DBMS가 데이터 정합성을 관리해 준다.
따라서, 해당 인덱스 키 컬럼을 모두 '=' 조건으로 검색할 때는 데이터를 한 건 찾는 순간 더이상 탐색할 필요가 없다.
Unique 인덱스이더라도 범위검색 조건으로 검색할 때는 Index Range Scan으로 처리된다.
또한, Unique 결합 인덱스에 대해 일부 컬럼만으로 검색할 때도 Index Range Scan이 나타난다.
4. Index Skip Scan
오라클 9i부터는 인덱스 선두 컬럼이 조건절에 빠졌어도 인덱스를 활용하는 Index Skip Scan 방식을 사용한다.
이 스캔 방식은 인덱스 선두 컬럼의 Distinct Value 개수가 적고 후행 컬럼의 Distinct Value 개수가 많을 때 유용하다.
Index Skip Scan은 루트 또는 브랜치 블록에서 읽은 컬럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 "가능성이 있는" 리프 블록만 골라서 액세스하는 방식이다.
Index Skip Scan은 첫 번째 리프 블록과 마지막 리프 블록을 항상 방문한다.
✅ 버퍼 Pinning을 이용한 Skip 원리
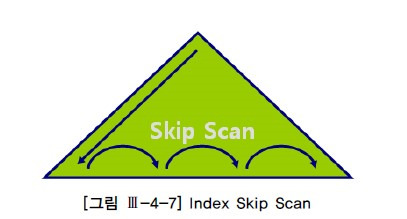
첫 번째 리프 블록을 방문한 후에 다른 리프 블록을 곧바로 점프해 나가는 것 처럼 보이지만
리프 블록에 있는 정보만으로는 다음에 방문할 리프 블록을 찾을 수 없다.
항상 그 위쪽에 있는 브랜치 블록을 재방문해서 다음 방문할 리프 블록에 대한 주소 정보를 얻어야 한다.
그런데 오라클 리프 블록에는 자신의 상위 브랜치 또는 루트 블록을 가리키는 주소 정보를 갖고 있지 않다.
그러면 어떻게 상위 블록을 재방문하는 것일까??
여기서 버퍼 Pinning 기법이 활용된다.
즉, 브랜치 블록 버퍼를 Pinning 한 채로 리프 블록을 방문했다가 다시 브랜치 블록으로 되돌아와 다음 방문할 리프 블록을 찾는 과정을 반복하는 것이다.
브랜치 블록들 간에도 서로 연결할 수 있는 주소정보를 가지고 있지 않기 때문에 하나의 브랜치 블록을 처리하고 나면 그 상위 노드를 재방문하는 식으로 진행된다.
루트 또는 브랜치 블록을 재방문해도 Pinning 한 상태이기 때문에 추가 블록 I/O는 발생하지 않는다.
✅ Index Skip Scan의 작동 조건
-
Distinct Value가 적은 선두 컬럼이 누락되고 후행 컬럼에 Distinct Value가 많은 경우
-
선두 컬럼은 입력하고 중간 컬럼이 누락된 경우
-
Dinstinct Value가 적은 두 개의 선두 컬럼이 모두 누락된 경우
-
선두 컬럼이 부등호, between, like 같은 범위검색 조건인 경우
Index Skip Scan 유도 힌트 = index_ss
Index Skip Scan 방지 힌트 = no_index _ss
5. Index Fast Full Scan
Index Fast Full Scan은 말 그대로 Index Full Scan보다 빠르다.
그 이유는, 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문이다.
✅ Index Fast Full Scan의 특징
쿼리에 사용되는 모든 컬럼이 인덱스 컬럼에 포함돼 있을 때만 사용 가능하다.
-
세그먼트 전체를 스캔
-
결과집합의 순서를 보장하지 않는다
-
Mulitblock I/O
-
인덱션 파티션이 안돼있어도 병렬 쿼리가 가능
-> Direct Path Read 방식을 사용 -
인덱스에 포함된 컬럼으로만 조회할 때 사용 가능
-
힌트는 index_ffs 와 no_index_ffs 사용
-
버퍼 캐시 히트율이 낮아 디스크 I/O가 많이 발생할 때 유리
6. Index Range Scan Descending
Index Range Scan 과 기본적으로 동일하지만 인덱스를 뒤에서부터 앞쪽으로 스캔하기 때문에 내림차순으로 정렬된 결과집합을 얻는다는 점만 다르다.
index_desc 힌트를 이용해 유도할 수 있다.
first row(min/max) 알고리즘이 개발되기 전에는 index_desc + rownum <= n 조건을 사용해야 했다.
7. And - Equal , Index Combine, Index Join
오라클은 두 개이상의 인덱스를 함께 사용하는 방법을 세 가지 방법을 제공한다.
-
And - Equal
And - Equal 메커니즘이 작동하려면 단일 컬럼의 Non-Unique 인덱스여야 함과 동시에 인덱스 컬럼에 대한 조건절이 '=' 이어야 한다.
'=' 조건을 전제로 하므로 인덱스 필터링을 거친 양쪽 집합은 rowid 순으로 정렬된 상태다. 따라서 양쪽을 번갈아 스캔하면서 rowid가 같은 레코드를 찾아 테이블을 액세스하는 방식이다.데이터 분포도가 좋지 않아 단독으로는 테이블 Random 액세스를 많이 발생시키는 단일 컬럼 인덱스를 두 개 이상 결합해 테이블 액세스량을 줄이는 데에 목적이 있다.
-
Index Combine
And - Equal과 마찬가지로 데이터 분포도가 좋지 않은 두 개 이상의 인덱스를 결합해 테이블 Random 액세스량을 줄이는 데에 목적이 있다.
조건절이 '=' 일 필요도 없고, Non-Unique 인덱스일 필요도 없다.
비트맵 인덱스를 이용하므로 조건절이 OR로 결합된 경우에도 유용하다.
-
Index Join
한 테이블에 속한 여러 인덱스를 이용해 테이블 액세스 없이 결과집합을 만들 때 사용하는 인덱스 스캔 방식이다.
Index Join은 해시 조인 메커니즘을 그대로 사용한다.Index Join은 쿼리에 사용된 컬럼들이 인덱스에 모두 포함될 때만 작동한다.
양쪽 모두 포함될 필요는 없고, 둘 중 어느 한쪽에 포함되기만 하면 된다.
