[CoinWhale] 6. "초록색 'online'의 배신" - Spark OOM(137)과 PM2 재시작 루프 탈출기 🚨
암호화폐 실시간 데이터 파이프라인 & 퀀트 구축기
시리즈: 암호화폐 실시간 데이터 파이프라인 & 퀀트 자동매매 구축기
1. 들어가며: 완벽해 보였던 파이프라인, 아침에 눈을 뜨니 멈춰있었다
실시간 파이프라인 아키텍처를 세팅하고, 처음으로 데이터가 쉼 없이 흐르는 것을 볼 때 기분이 정말 좋았습니다. 터미널 위로 쏟아지는 체결 데이터와 대시보드의 숫자들이 갱신되는 것을 보며 "드디어 완성했다, 앞으로 문제가 없을 줄 알았다"라고 생각했습니다.
하지만 파이프라인을 하루 종일 돌려두고 다음 날 아침에 일어나 MobaXterm에 접속해 pm2 list를 확인해보니, 충격적인 숫자가 적혀 있었습니다.
spark 프로세스의 재시작(Restart) 횟수가 무려 88회를 기록하고 있었기 때문입니다.
당연히 실시간 대시보드에서 거래량을 파악하는 기능이나, 고래 마커(대규모 체결 감지) 등 Spark의 집계가 필요한 핵심 기능들은 작동도 하지 않고 있었습니다. 대체 밤사이에 무슨 일이 있었던 걸까요?
🗺️ 마주한 3가지 문제 요약과 이번 글의 목표
운영을 시작하며 마주한 전체적인 문제들은 크게 세 가지로 나눌 수 있었습니다.
- 메모리 부족(OOM)과 프로세스 무한 재시작 루프
- Kafka-ZooKeeper 메타데이터 정합성 문제 (상태 꼬임)
- 재시작 후 쌓인 엄청난 양의 데이터(Lag) 처리 문제
이 글에서는 제가 가장 먼저 마주했던 OOM과 재시작 루프가 발생한 원인을 깊게 분석해 보고, 상태 복구와 메타데이터 이슈까지 묶어서 다뤄보겠습니다.
(데이터 지연(Lag) 처리는 다음 글에서 이어집니다.)
2. '모니터링 착시'와 에러 확인이 늦어진 이유
가장 큰 문제는 시스템이 88번이나 죽고 살아나는 동안, 운영자인 제가 이 장애를 즉각적으로 알아채기 힘들었다는 점입니다. 원인은 프로세스 매니저인 PM2의 상태 표시와 실제 데이터 흐름의 괴리 때문이었습니다.
PM2 화면에서 프로세스는 계속 초록색 online으로 표시되었습니다.
Spark가 재시작된 직후, 완전히 죽기 전까지 몇 초에서 몇 분 동안은 데이터가 찔끔찔끔 처리되어 ClickHouse DB에 저장되었습니다. 대시보드의 지표가 아주 가끔씩이라도 갱신되다 보니, 겉으로는 크게 문제가 없어 보였고 단순히 "네트워크 렉이 걸렸나?"라고 오해하기 딱 좋은 상황이었습니다.
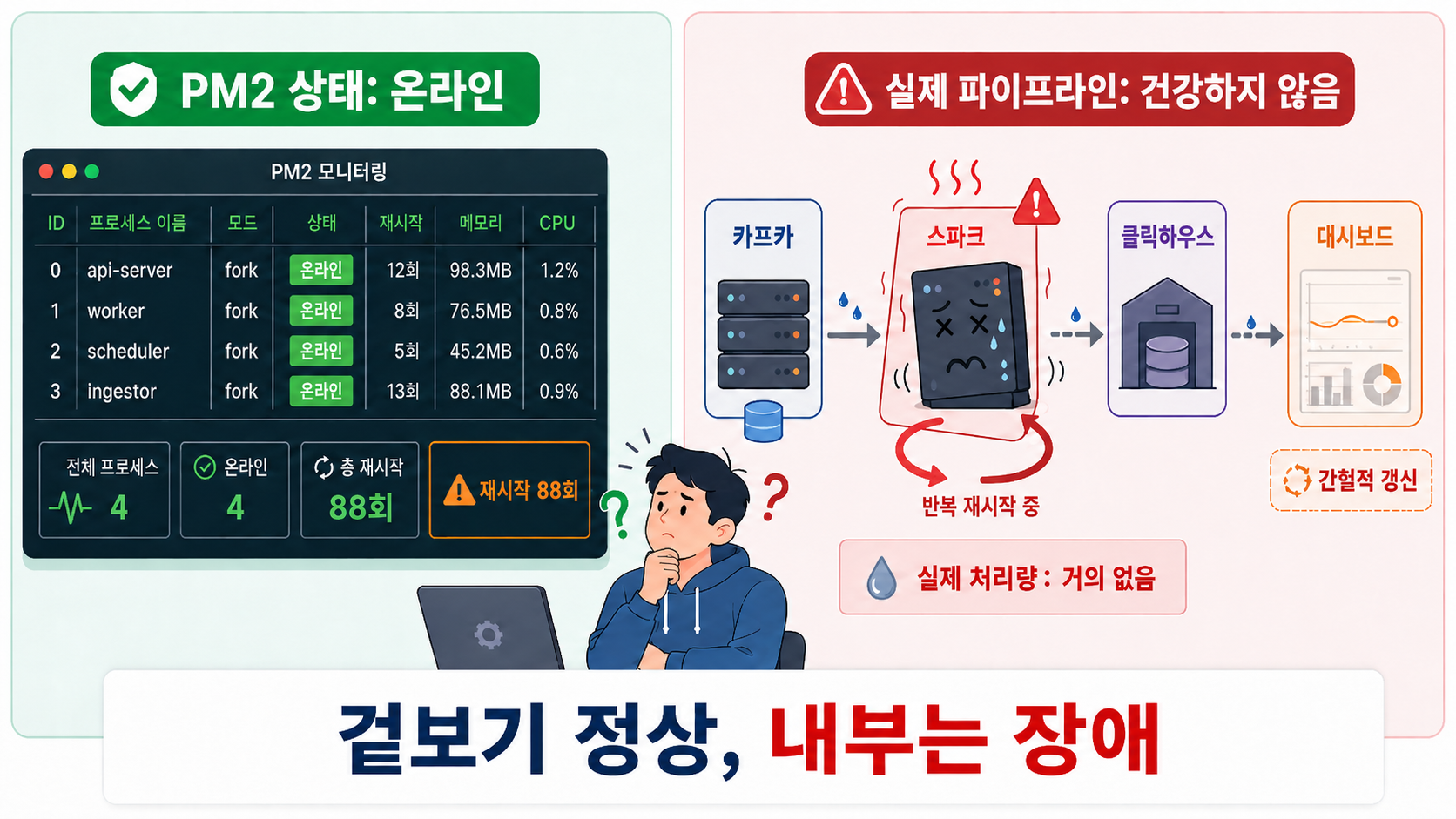
이처럼 표면적으로는 살아있는 것처럼 보였기 때문에, 내부적으로 상태가 심각하게 꼬여가고 있다는 것을 발견하기가 매우 어려웠습니다.
3. exit code: 137의 진짜 의미와 사라진 스택 트레이스
대체 왜 Spark가 자꾸 죽었는지 확인하기 위해 PM2 로그를 열어보았습니다.
[CVDInsight] 시작
[FundingInsight] 시작
[CH] batch 16330 -> stream.oi: 3 rows
Spark 프로세스 종료 (exit code: 137)이 로그를 보고 처음엔 의아했습니다. 보통 Java나 Scala 기반의 애플리케이션(Spark 포함)에서 쿼리가 실패하거나 체크포인트 문제가 생기면 상세한 Java Stacktrace(스택 트레이스)를 쏟아냅니다.
(실제로 ClickHouse 연동 중 에러가 나면 ch_writer.py가 아래처럼 명확하게 에러를 뱉어주도록 짜여 있습니다.)
#ch_writer.py 중 일부: Spark가 불친절한 게 아니다.
if _is_spark_operational_error(error_type):
print(f"[SPARK-OPS] Spark batch action failed - table={table_name}, error={error_type}")
raise하지만 로그에는 친절한 설명 없이, exit code: 137이라는 메세지만 덩그러니 남아있었습니다.
💡 137 코드는 '예외'가 아니라 'OS의 강제 종료'다
137이라는 종료 코드는 리눅스 시스템에서 128 + 9를 의미합니다. 여기서 이 숫자를 분해해 보면 왜 로그가 남지 않았는지 그 이유가 명확해집니다.
128: 프로세스가 스스로 종료된 것이 아니라, 외부 신호(Signal)에 의해 강제 종료되었음을 알리는 리눅스의 기본 꼬리표입니다.
9: 프로세스에게 하던 일을 정리할 시간조차 주지 않고 즉각 처형해버리는 가장 강력한 신호인 SIGKILL을 뜻합니다.
(우리가 흔히 터미널에서 먹통인 프로그램을 끌 때 치는 kill -9 명령어의 그 9입니다.)
즉, 애플리케이션 내부에서 코드가 잘못되어 '예외(Exception)'를 던진 것이 아닙니다. OS나 Docker 시스템이 서버 자원(메모리)을 보호하기 위해 해당 프로세스를 외부에서 강제로 즉각 종료시켜 버린 OOM(Out Of Memory) 상황이었습니다. JVM이 정상 종료 절차를 밟지 못하니 에러 메세지를 남길 기회조차 없었던 것이죠.
💡 저 한 줄의 로그는 누가 찍었나? (래퍼 스크립트)
마지막에 남은 Spark 프로세스 종료 로그조차 Spark 본체가 남긴 것이 아닙니다. 제가 작성했던 실행 쉘 스크립트 내부에서, docker exec가 비정상 종료로 튕겨져 나오자 스크립트가 자체적으로 찍어준 '사망 확인서'입니다.
#start-silver-aggregator-daemon.sh 중 일부
EXIT_CODE=$?
if [ $EXIT_CODE -ne 0 ]; then
echo "Spark 프로세스 종료 (exit code: $EXIT_CODE)"
exit $EXIT_CODE
fi[실무 트러블슈팅 팁]
결론적으로 프로세스가 137로 죽었다면 앱 로그를 뒤질 것이 아니라, 터미널에서 dmesg -T 나 journalctl -k를 쳐서 Out of memory: Kill process ... 라는 시스템 커널 로그를 확인하는 것이 진짜 스택 트레이스를 찾는 지름길입니다.
4. 구조의 덫: Host, Container, 그리고 cgroup
왜 OOM이 발생했을까요? 이를 이해하려면 '컨테이너 자원 격리'라는 당시 아키텍처의 결함을 봐야 합니다.
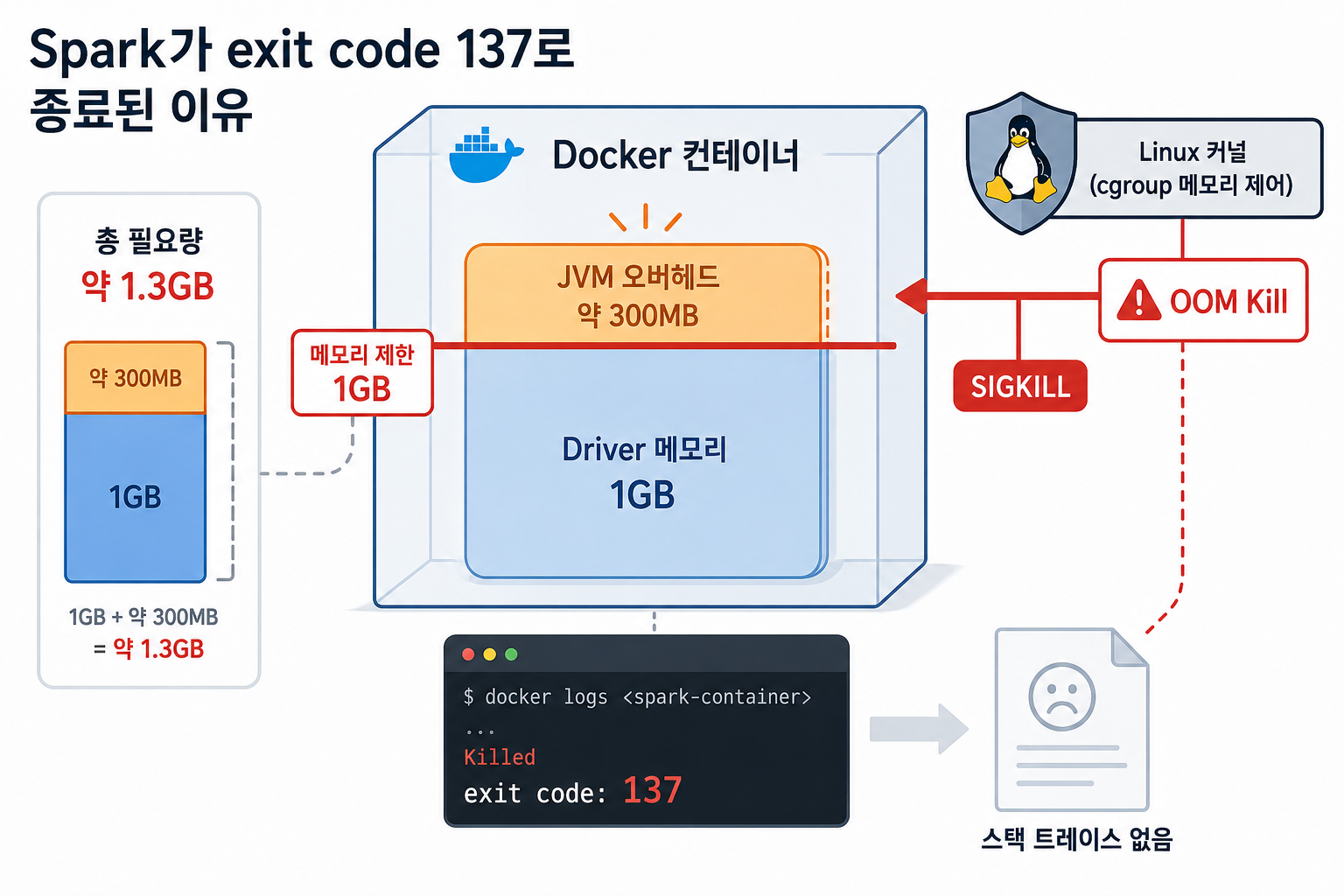
💡 cgroup 메모리 제한과 JVM 오버헤드
Spark의 뇌 역할을 하는 Spark Driver는 제 로컬 호스트 머신에서 직접 도는 것이 아니라, Docker로 띄운 spark-master 컨테이너 내부에서 실행되고 있었습니다.
Docker는 리눅스의 cgroup(Control Group) 기술을 사용해 컨테이너의 메모리 상한선을 제한합니다.
장애 당시 docker-compose.yml에는 spark-master 컨테이너의 상한선(mem_limit)이 1GB로 잡혀 있었습니다. 반면, Spark 명령어에 옵션을 주지 않으면 기본 메모리는 1GB이고, 여기에 JVM 오버헤드 약 300MB가 추가로 붙습니다.
(※ JVM 오버헤드란? 순수 연산에 쓰는 힙(Heap) 메모리 외에도 가비지 컬렉터(GC), 클래스 메타데이터 저장소, PySpark 통신 버퍼 등 JVM 구동 자체에 필수적인 추가 메모리 공간을 뜻합니다.)
결국 컨테이너 최대 허용량은 1GB인데, Spark는 1.3GB를 요구하니 cgroup이 가차 없이 OOM Kill 시켜버린 것입니다.
(이 문제는 드라이버뿐 아니라 워커 노드의 SPARK_EXECUTOR_MEMORY 설정에서도 동일하게 발생했습니다.)
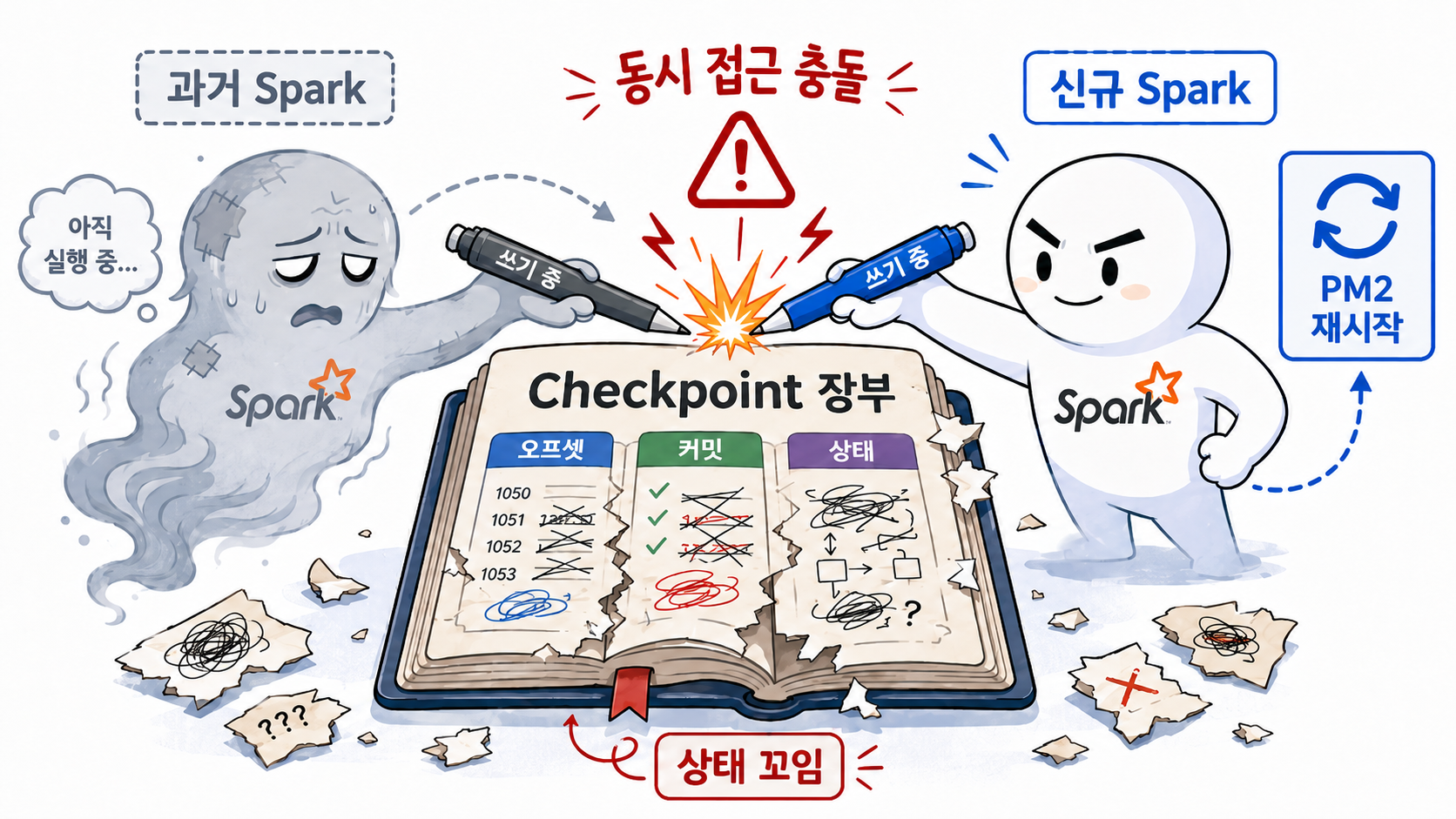
5. 정리되지 않은 이전 Spark 프로세스 프로세스와 Checkpoint 충돌 대참사
더 큰 문제는 PM2가 죽은 프로세스를 되살리는 과정에서 발생했습니다.
PM2는 호스트 머신의 bash 스크립트를 바라보지만, 실제 Spark 쿼리는 컨테이너 안의 JVM에서 실행됩니다. 메모리 부족으로 컨테이너 내부의 Spark 실행이 비정상 종료되거나 연결이 끊기면, PM2는 실행 스크립트가 종료된 것으로 판단하고 “프로세스가 죽었네? 다시 띄워야지” 하며 새 Spark 실행을 시작합니다. 문제는 이 과정에서 이전 SparkSubmit/JVM 프로세스가 컨테이너 내부에서 완전히 정리되지 않은 채 남아 있을 수 있다는 점이었습니다.
이때 'Checkpoint(체크포인트)'라는 시스템의 핵심 요소가 꼬이게 됩니다.
Checkpoint는 Spark Streaming이 "어디까지 읽었고(Offset), 어디까지 처리했으며(Commit), 누적 상태값은 무엇인지"를 디스크에 적어두는 운영 장부입니다.
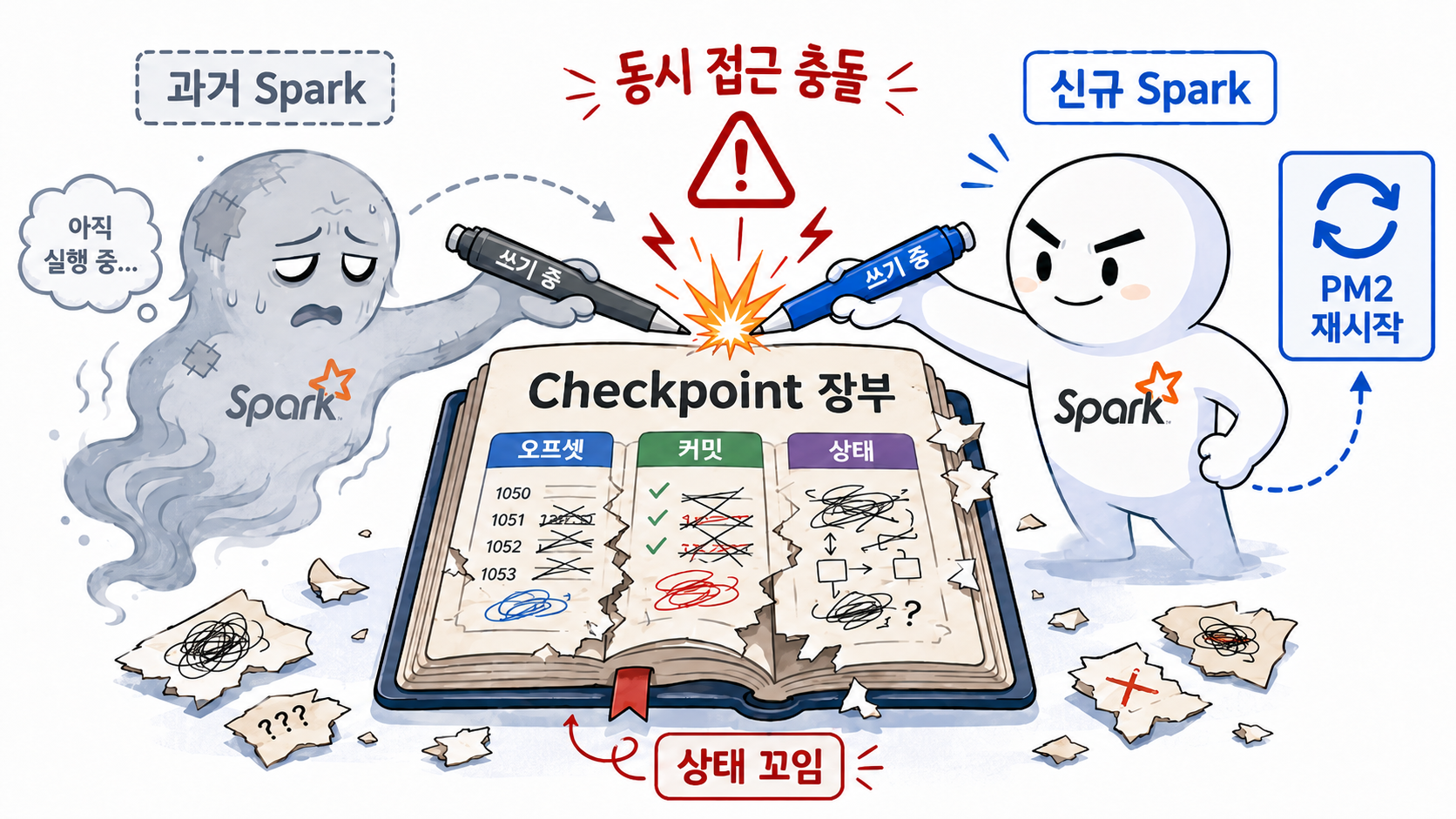
새로 투입된 Spark와 아직 죽지 않은 좀비 Spark가 이 하나의 장부를 두고 서로 글을 쓰려다 충돌하며 파일이 찢어지고 정합성이 붕괴되는 참사가 벌어진 것입니다.
6. 해결책: 메모리 현실화와 상태 클린업(Cleanup) 스크립트
원인을 파악했으니 해결책은 명확해졌습니다.
6-1. 자원 명시와 '컨테이너 재생성'의 차이
먼저 기본값에 의존하던 실행 스크립트에 --driver-memory와 --executor-memory를 명시하고, 컨테이너의 mem_limit도 넉넉하게 늘렸습니다.
(💡 현재 저장소 코드에는 spark-master 16GB, spark-worker 40GB로 상한선이 대폭 상향되어 있습니다.)
여기서 자주 헷갈리는 중요한 차이가 있습니다.
pm2 restart: 호스트의 실행 스크립트만 껐다 켭니다. 컨테이너 메모리 변경은 반영되지 않습니다.
docker restart: 기존 컨테이너를 단순히 껐다 켭니다. 역시 뼈대 설정은 바뀌지 않습니다.
docker compose up -d --force-recreate: mem_limit 같은 핵심 자원을 변경했다면, 반드시 기존 컨테이너를 부수고 새로운 뼈대로 다시 만들어야 설정이 적용됩니다.
6-2. PM2 autorestart 설정의 현실화
무작정 켜두는 자동 재시작은 장애를 숨깁니다. 실제 저장소(ecosystem.config.js)에는 복구 속도와 한계를 제어하는 옵션을 추가했습니다.
autorestart: true,
restart_delay: 30000, // 재시작 전 30초 대기 (무한 루프 방어)
max_restarts: 10, // 10번 넘게 죽으면 멈추고 운영자에게 알림
min_uptime: '10s', // 너무 빨리 죽는 프로세스를 불안정 상태로 간주
kill_timeout: 30000, // 프로세스 종료 시 30초의 여유를 주어 Checkpoint Flush 보장6-3. 진짜 핵심: 장부를 정리하는 '상태 클린업 스크립트'
단순히 억지로 잡고 다시 띄우는 것이 아니라, 띄웠을 때 정합성이 깨지지 않게 준비하는 사전 클린업 작업을 추가했습니다. 실제 반영된 start-silver-aggregator-daemon.sh 스크립트의 일부입니다.
# 1. 정리되지 않은 이전 SparkSubmit 강제 확인 및 사살
existing_pids="$(ps -eo pid=,args= | awk ...)"
kill -9 "$existing_pids" # 2. Checkpoint 메타데이터 Pruning (찌꺼기 청소)
find "$dir/offsets" "$dir/commits" \( -name ".*.tmp" -o -name ".*.crc" \) -delete실제 스크립트는 이보다 훨씬 깊숙이 개입합니다. .tmp 삭제뿐만 아니라, Offset(읽은 지점)이 Commit(처리 지점)보다 앞서 나가버린 역전 현상이나 꼬인 꼬리(Tail)를 잘라내는(Prune) 작업까지 수행합니다. 복구를 명령어가 아닌 '안전한 절차'로 바꾼 것입니다.
7. 추가 이슈: Kafka 메타데이터와 ZooKeeper의 시간차
위 조치를 마쳤음에도 파이프라인이 매끄럽게 복구되지 않는 구간이 있었습니다. 이번엔 OOM이 아니라 이런 에러가 찍혔습니다.
InconsistentClusterIdException: The Cluster ID doesn't match...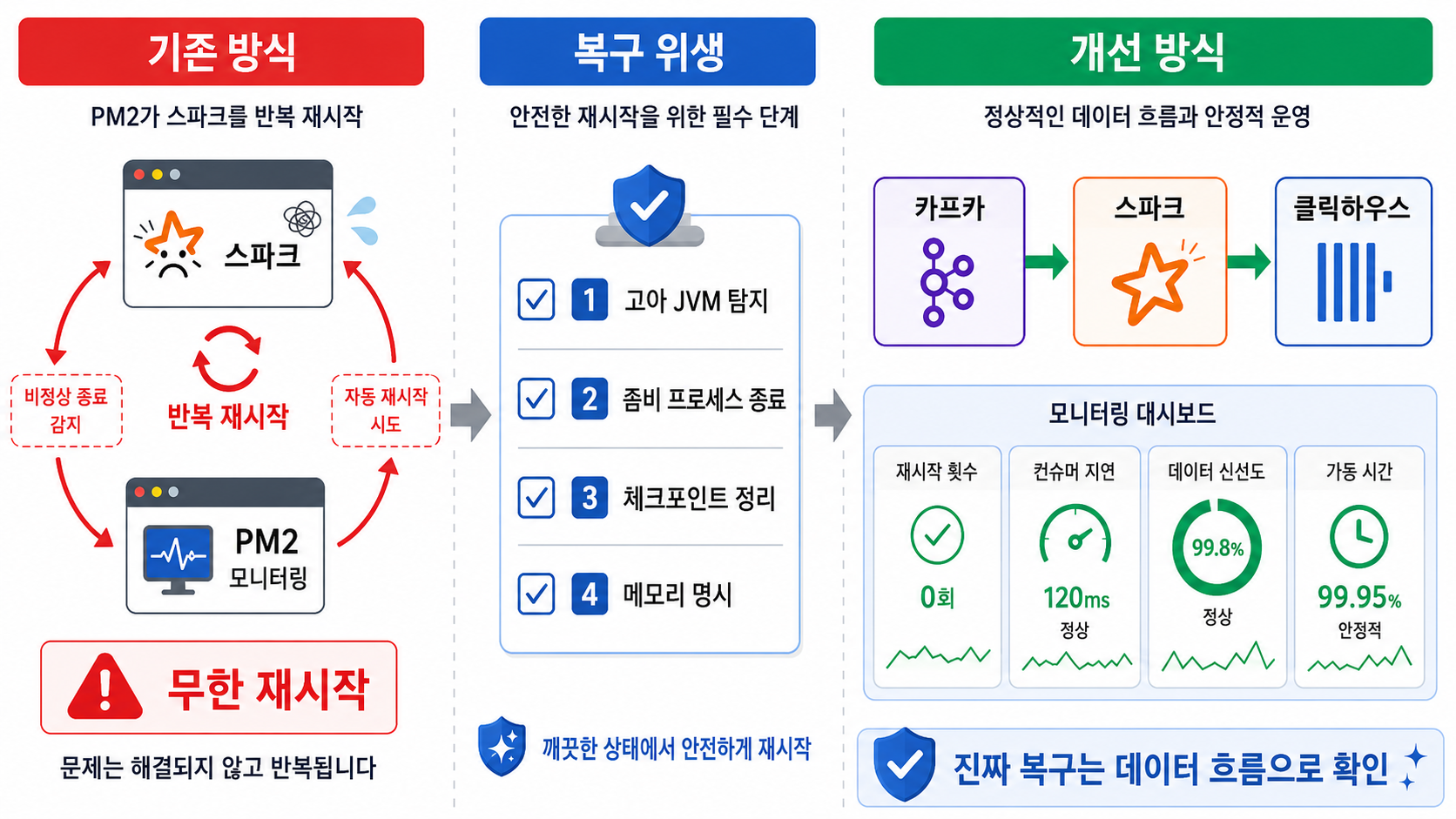
잦은 재시작으로 코디네이터인 ZooKeeper가 초기화되며 새로운 Cluster ID를 발급했는데, 데이터를 쥐고 있는 Kafka 브로커의 로컬 볼륨에는 옛날 ID가 기록되어 있어 서로 결재가 거부되는 상황이었습니다.
이 경험을 통해 장애 복구 시 단순히 컨테이너만 껐다 켤 것이 아니라, "ZK와 브로커를 함께 리셋할지, 브로커의 볼륨 데이터만 지울지" 명확한 운영 규칙을 정하는 계기가 되었습니다.
💡 중간 점검: 과거의 실패를 디딤돌 삼아 바뀐 현재(2026.5) 운영 원칙
이번 6주차의 혹독한 OOM 신고식은 결국 "무거운 프로세스를 운영 시스템 위에 어떻게 안전하게 올릴 것인가"에 대한 뼈저린 교훈이 되었습니다.
당시의 실패를 발판 삼아, 현재 프로덕션 환경의 설계는 다음과 같이 진화했습니다.
자원 명시와 분리: Spark를 하나의 통짜 앱으로 돌리지 않습니다. price/cvd 등 헤비한 스트림과 oi/liquidation 등 가벼운 스트림을 분리하고, 각각 메모리와 코어를 명시적으로 할당합니다.
모니터링 기준의 변화: 더 이상 PM2 화면의 초록색 online 글자만 보고 안심하지 않습니다. 재시작 횟수뿐만 아니라, ClickHouse로 흘러가는 data Freshness, Consumer Lag 같은 실질적인 지표를 직접 확인합니다.
명령어가 아닌 정책: 재시작은 복구가 아니라 징후일 뿐입니다. 장애가 나면 무작정 켜는 것이 아니라, 망가진 상태(좀비 프로세스, Checkpoint 찌꺼기, 메타데이터)를 안전하게 수정하고 확인합니다.
이제 기나긴 OOM 재시작 루프는 완전히 끊어냈습니다!
하지만 산 넘어 산이라고, 시스템이 멈춰있던 시간 동안 댐에 갇힌 물처럼 카프카에는 엄청난 양의 메세지(Backlog)가 쌓여버렸습니다.
다음 글에서는 한 번 살아난 시스템이 이 엄청난 데이터 지연(Lag)을 어떻게 폭발적으로 따라잡고 처리하는지, maxOffsetsPerTrigger 튜닝 이야기를 해보겠습니다. 🚀
