암호화폐 실시간 데이터 파이프라인 & 퀀트 구축기
1.[CoinWhale] 1. "22:20분 비트코인 급등, 이유는?" - 실시간 데이터 파이프라인 구축기
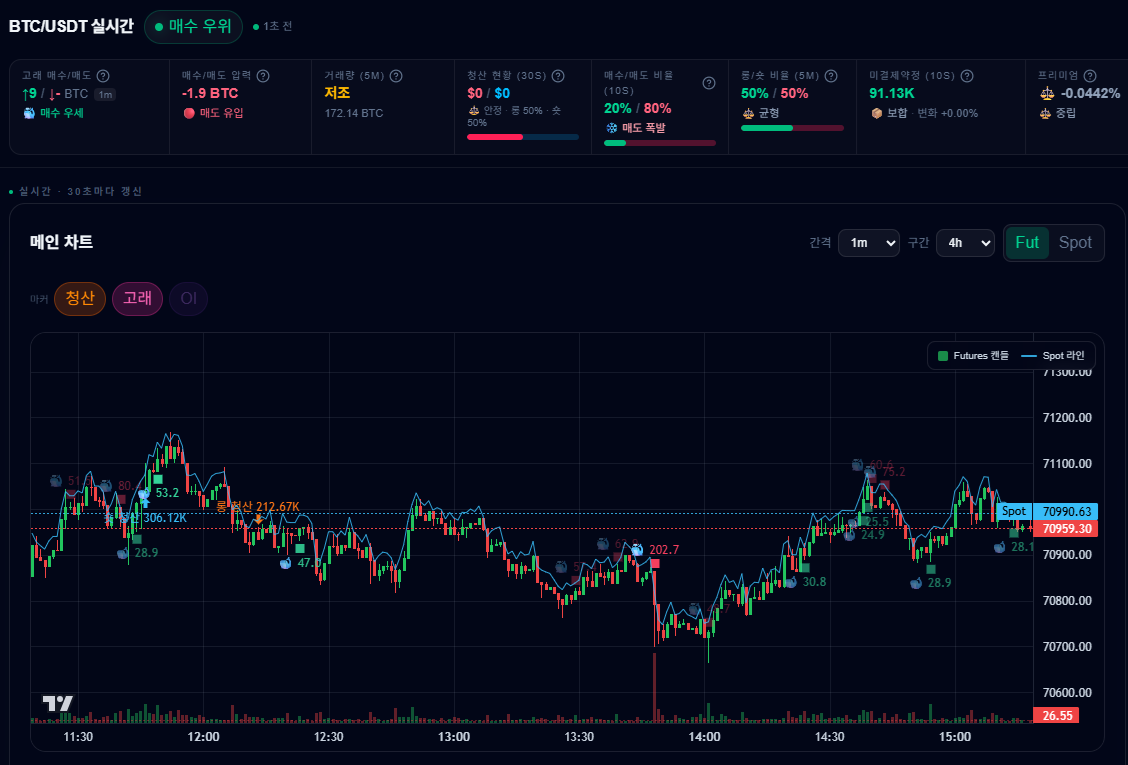
비트코인 급등락의 진짜 원인을 찾기 위해 구축한 실시간 데이터 파이프라인. 개발자가 Kafka, Spark, ClickHouse를 엮어 대용량 데이터를 처리하며 겪은 치열한 아키텍처 설계와 삽질의 과정을 공유합니다.
2.[CoinWhale] 2. "초당 9,100건이 쏟아진다면?" - Kafka 18개 토픽 설계와 Python 비동기 수집기
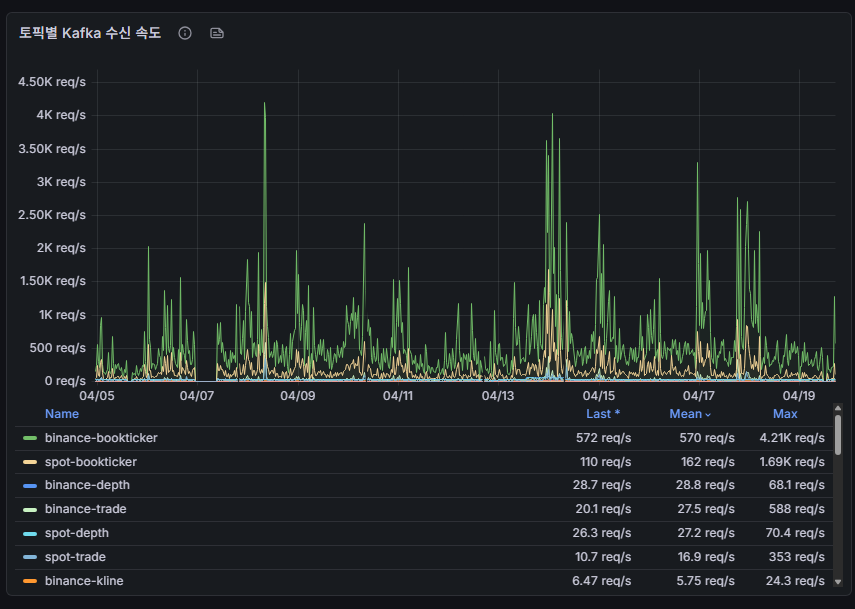
초당 9,100 TPS의 트래픽 폭주를 견디는 코인 실시간 수집기! Binance API 연동, Kafka 18개 토픽 설계, Python Asyncio 최적화 및 현업 트러블슈팅 경험을 기록했습니다.
3.[CoinWhale] 3. "고래의 숨겨진 매수세를 10초 만에 포착하는 법" - Spark 실시간 집계와 메달리온 아키텍처(Silver)
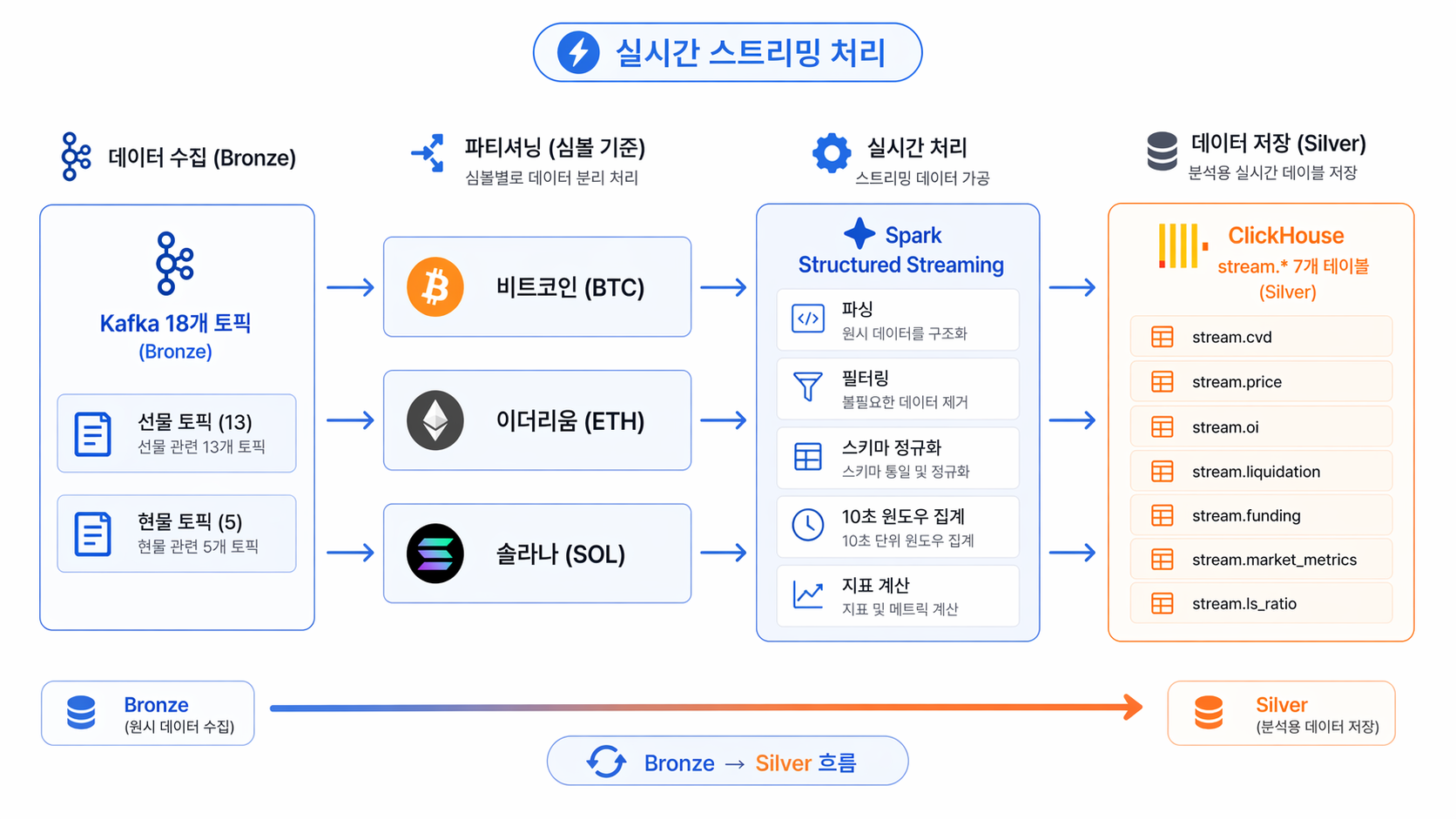
초당 수천 건 쏟아지는 코인 데이터를 어떻게 실시간으로 처리할까요? 판다스(Pandas) 대신 스파크(Spark)를 선택한 이유부터, 10초 윈도우 집계로 원시 데이터를 핵심 지표로 압축하는 과정까지! 무거운 데이터를 가볍게 요약하는 파이프라인 아키텍처를 소개합니다.
4.[CoinWhale] 4. "DB가 뻗지 않는 실시간 뷰" - ClickHouse 메달리온 아키텍처와 Gold VIEW
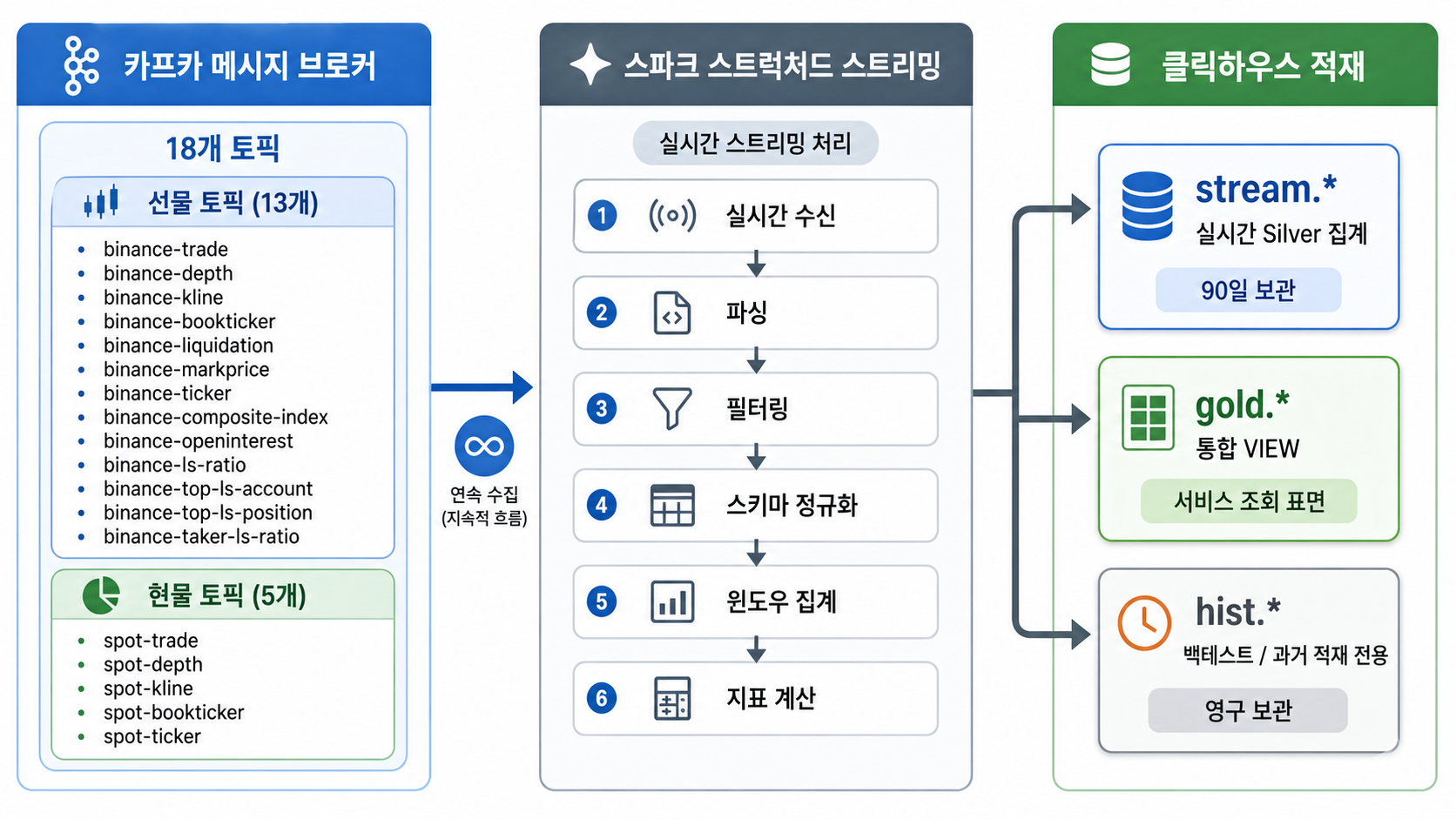
Spark가 가공한 실시간 데이터를 어떻게 저장할까? stream, hist, gold 3계층으로 역할을 분리한 ClickHouse 데이터베이스 모델링과 실시간 뷰(VIEW) 최적화 구축기입니다.
5.[CoinWhale] 5. "완벽한 데이터, 그리고 처참했던 실패" - 퀀트 자동매매 1, 2세대 회고와 11가지 교훈"
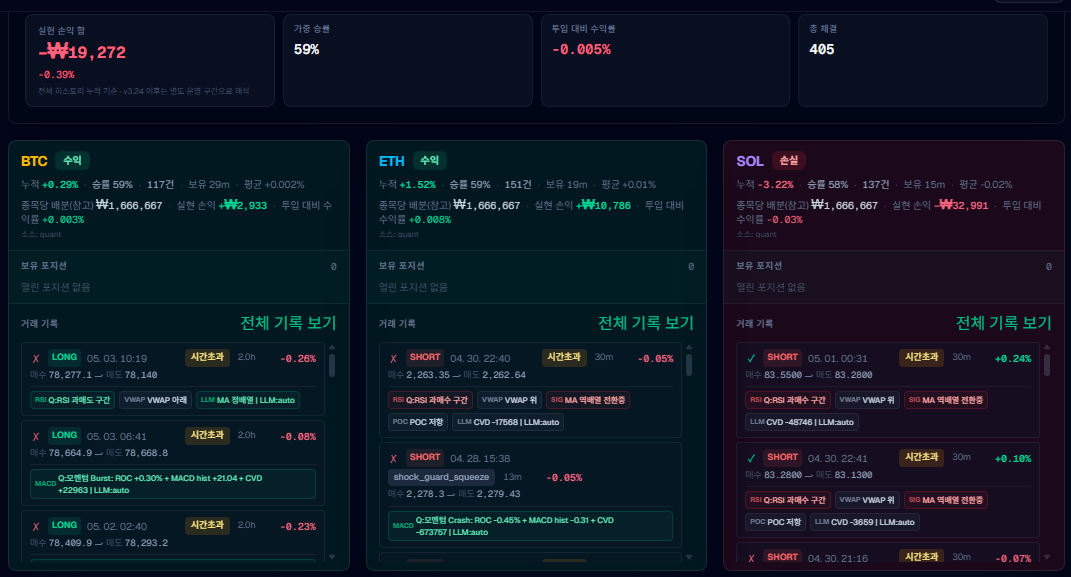
"방향이 안 나와서 8시간 만에 강제 종료." 거래의 73%가 허무하게 끝났습니다. 완벽한 실시간 데이터 파이프라인을 믿고 돌린 자동매매 봇은 왜 목표 수익을 한 번도 내지 못했을까요? 계좌를 녹이며 배운 퀀트 투자의 핵심 교훈 11가지를 담았습니다.
6.[CoinWhale] 6. "초록색 'online'의 배신" - Spark OOM(137)과 PM2 재시작 루프 탈출기 🚨
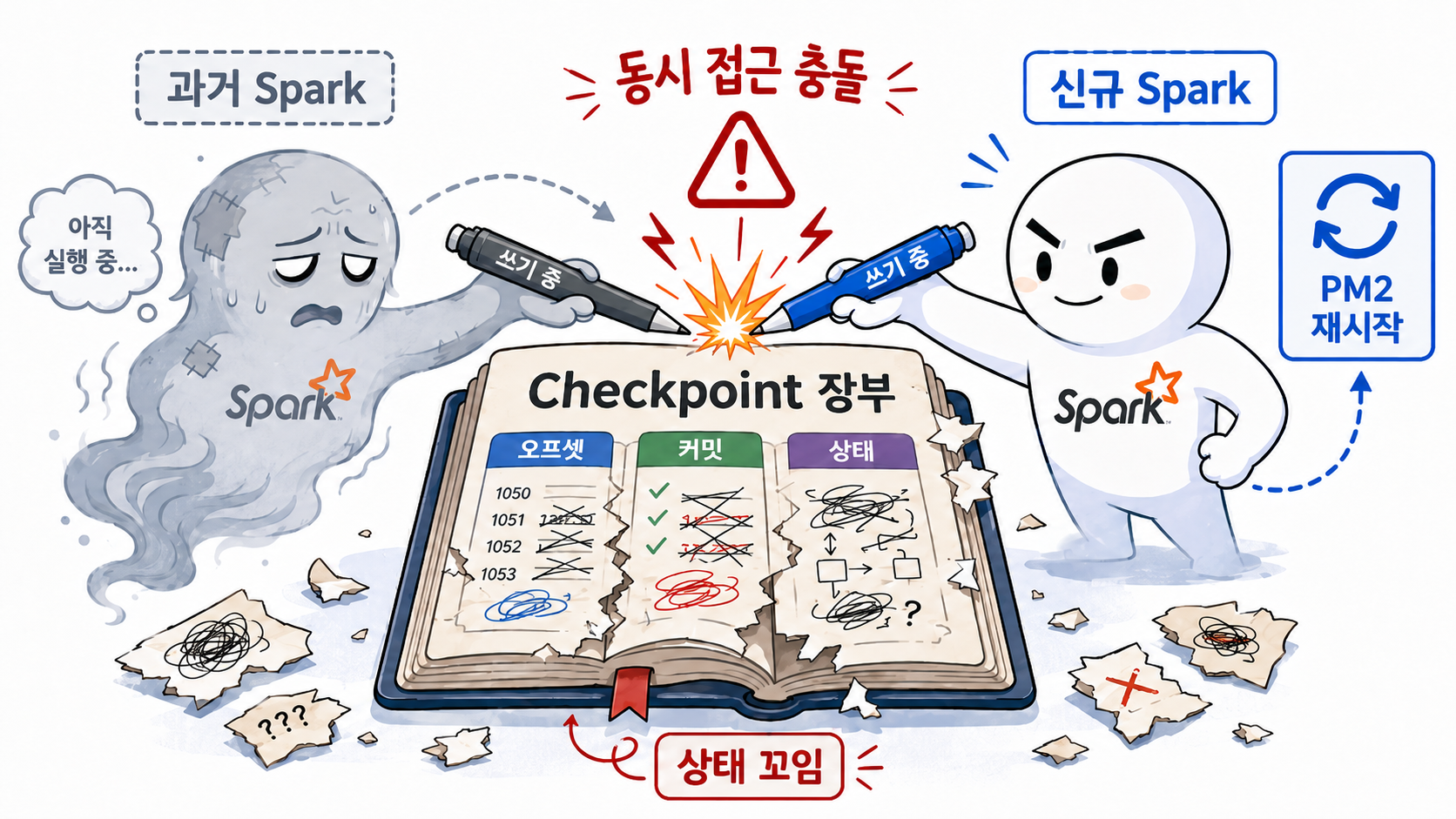
겉으론 정상처럼 보이는 PM2 무한 재시작 루프의 함정을 파헤칩니다! Spark OOM(exit 137) 강제 종료가 좀비 프로세스를 만드는 원인부터, Docker 컨테이너 자원 설계, Checkpoint 복구 위생까지 파이프라인을 살려낸 실무 트러블슈팅 기록입니다.