Catastrophic forgetting : 현재 인공신경망은 단일 작업에 대해선 뛰어난 성능을 보이나, 다른 종류의 작업을 학습하면 이전 학습 내용을 잊어버리는 단점이 있다
Task
- 어떤 Catastrophic forgetting이 현대 인공신경망에서 발생하는지, gradient-based training algorithms과 activation founctions을 비교
- first task와 second task 사이에서 catastrophic forgetting의 관계
Results
- drop out의 old task를 기억하면서, new task를 adapting하는 최선의 training 방법
Dropout
Dropout은 standard stochastic gradient descent training을 수정한다. 학습 중 각 example이 제시될 때, 네트워크의 input states와 hidden unit states가 binary mask로 곱해진다. 이 mask는 example이 제시 될 때마다 임의로 생성이 되고, 고정된 확률 p에 따라 mask의 각 element는 다른 element와 독립적으로 표본 표출이 됩니다.
Dropout은 weights를 공유하는 많은 신경망을 기하급수적으로 훈련시킨 다음 예측을 평균화하는 매우 효율적인 수단으로 볼 수 있습니다.이 것은 일반화 오류를 감소시키는데 도움이 되는 bagging과 유사합니다.
Dropout은 매우 효과적인 regularizer입니다. Dropout의 이전에, 신경망의 일반화 오류를 줄이는 주요 방법 중 하나는 단순히 소수의 hidden unit을 사용하여 용량을 제한하는 것이었습니다. Dropout 눈에 띄게 큰 networks 학습을 가능하게 하였습니다.
가설
최적으로 작용하는 dropout nets의 증가된 크기는 dropout이 첫 번째 작업을 수행하기에 겨우 충분하도록 제한함으로써 정규화된 전통적인 신경망보다 catastropical forgetting 문제에 덜 취약하다고 가설을 세웠습니다.
Experiments
old task와 new task를 정의하고, old task에서의 학습시킨 다음 new task에 대해 훈련된 신경망을 검토합니다. 두 알고리즘, SGD와 Dropout에 대해 activation functions(logstic sigmoid, rectifier, hard LWTA, maxout)을 실험합니다.
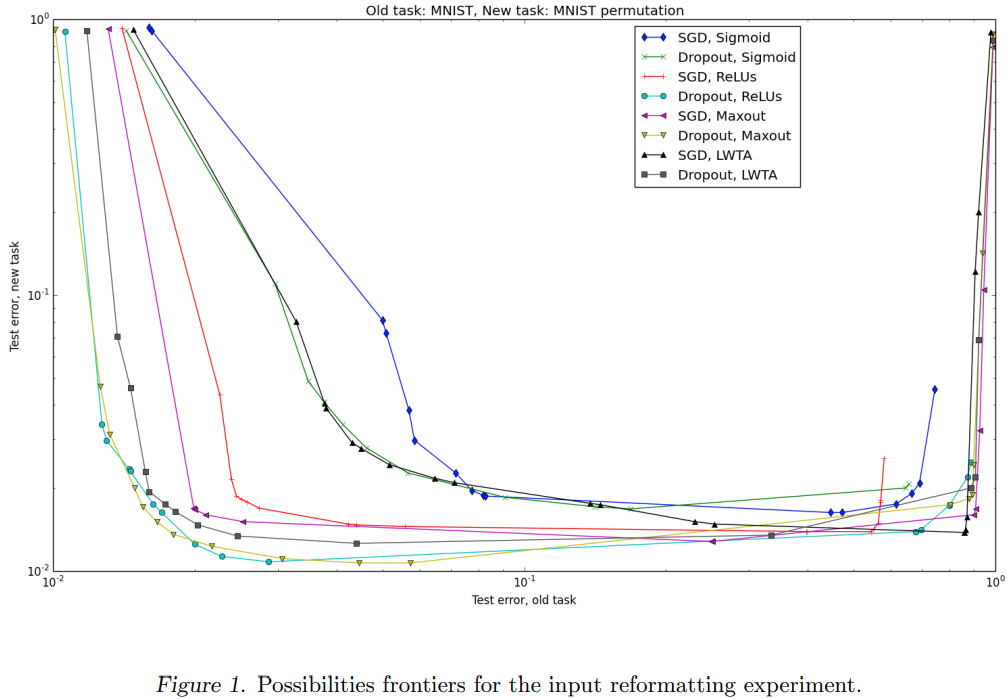
모든 모델에 대하여 Dropout을 사용하였을 때, two-task validation set의 성능이 개선 되었습니다.
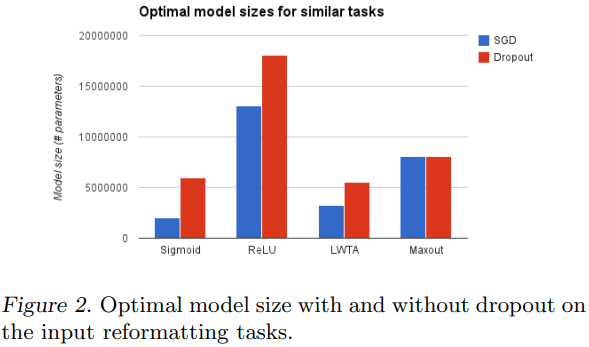
Dropout이 최적의 모델 크기에 미치는 영향을 보면, nets가 이 task에서 기본적으로 성공할 수 있었지만, 기존의 개념에 다른 pixel 세트를 mapping함으로써 그렇게 했다고 믿지 않았습니다.
Best nets의 first layer weights를 시각화 하였고, old task의 학습이 끝나는 시점과 new tak가 시작하는 시점 사이 첫번째 layer weights는 눈에 뜨게 변하지 않았습니다. 이는 하위 계층이 새 input 형식에 적응하는 동안 동일하게 유지되는 대신, 비교적 임의적인 input의 투영을 수용할 수 있도록 net의 higher layer가 변경되었다고 예측할 수 있습니다.
Similar task
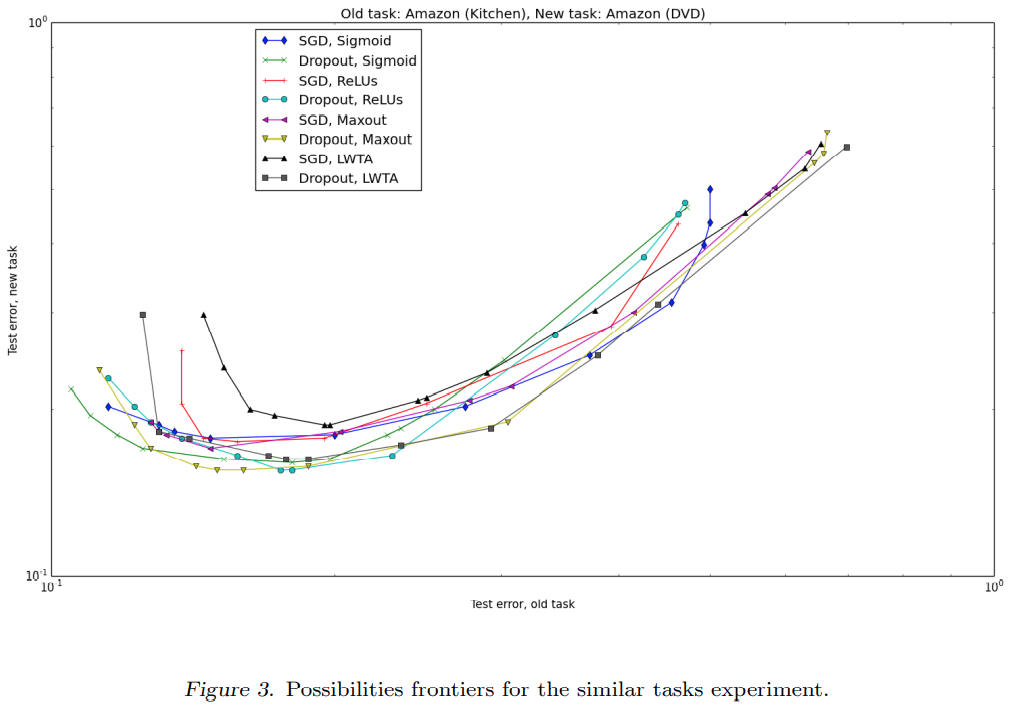
Dropout을 사용하면 모든 모델에 대하여 two-task validation set의 성능이 개선되었습니다.
Dissimilar task
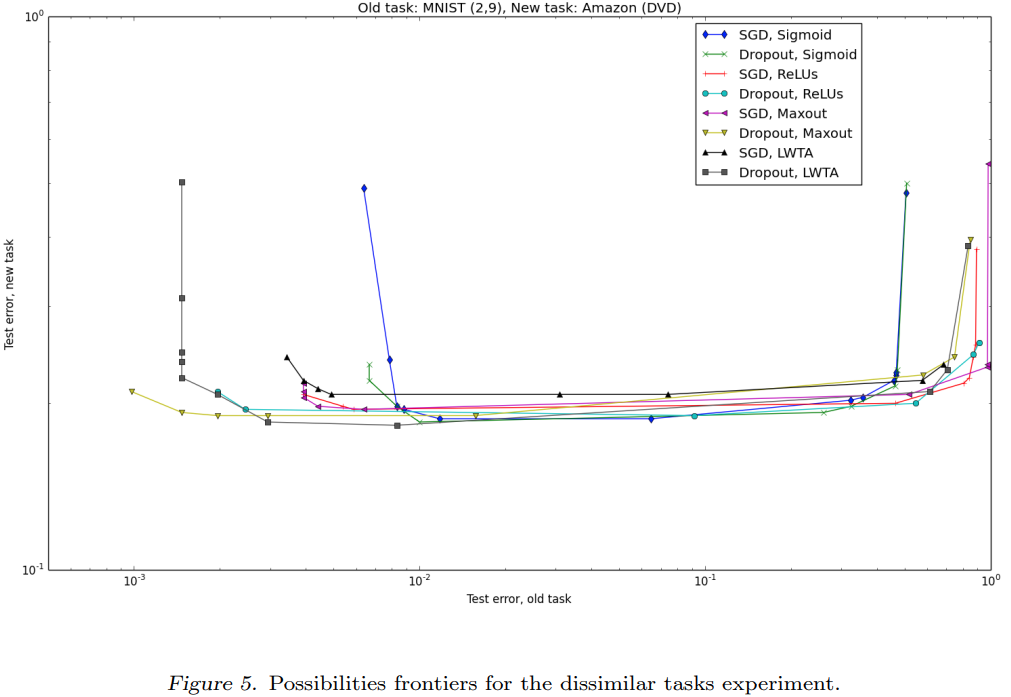
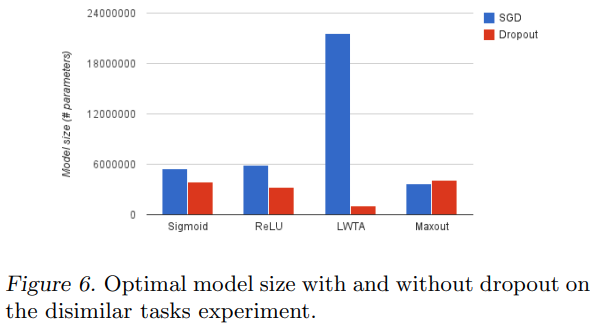
분류 성능 모델은 다음과 같습니다. Dropout을 사용하여 two-task valdation set의 성능을 모든 모델에서 개선되었습니다.
Discussion
Dropout은 three task pairs에 대해 모든 여덟가지 방법 모두 성능을 향상시켰습니다. Dropout은 세가지 task pair 모두에 대해 new task의 성능, old task의 성능 및 이러한 두 극단 사이의 균형을 유지하는 tradeoff curve를 따라 가장 잘 작동합니다.
activation function의 선택은 training algorithm(SDG, Dropout)의 선택보다 더 일관관된 효과가 있었습니다. 서로 다른 종류의 task pari로 실험을 수행했을 때 activation function의 순위는 문제에 따라 매우 달랐습니다. 예를 들어, logistic sigmoid는 어떤 조건에서는 가장 나쁘지만 다른 조건에서는 가장 좋습니다. 이는 activation function의 선택이 계산적으로 가능한 한 항상 교차 검증해야 하는 이유입니다.
