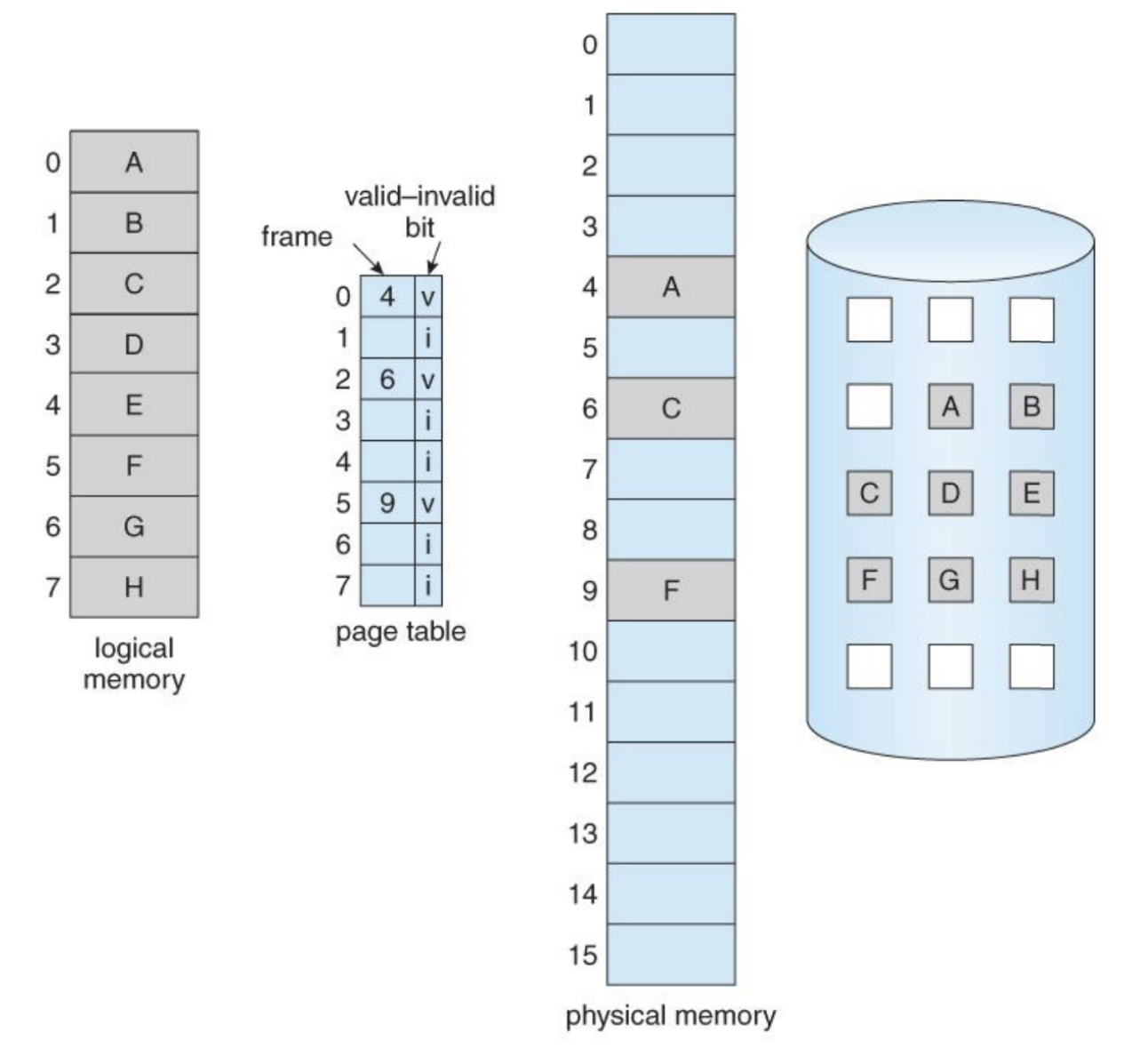
가상 메모리(Virtual Memory System)
오늘부터 PintOS Project3 가상 메모리 구현에 대해서 시작합니다
첫날이어서 책 위주의 공부를 하며 개념을 정리했습니다
메모리 공간의 종류
1. 스택(stack)메모리
할당과 반환은 컴파일러에 의해 암묵적으로 이루어진다. 이러한 이유 때문에 자동(automatic) 메모리라고 불립니다
void func() {
int x; // 스택에 int 형을 선언
}func가 호출될 때 스택에 공간을 확보하고 리턴하면 컴파일러는 메모리를 반환한다. 함수 리턴 이후에도 유지되어야 하는 정보는 스택에 저장하지 않는 것이 좋습니다
2. 힙(heap) 메모리
오랫동안 값이 유지되어야 하는 변수를 위한 메모리 모든 할당과 반환이 프로그래머에 의해 명시적으로 처리됩니다(많은 버그의 원인)
void func() {
int *x = (int *) malloc(sizeof(int));
}이 코드의 주의사항
한 행에서 스택과 힙 할당이 모두 발생합니다
malloc을 호출하여 정수를 위한 공간을 힙으로부터 요구한다. malloc은 그 정수의 주소를 반환한다 이 반환된 주소는 스택에 저장되어 프로그램에 의해 사용됩니다
이런 명시적 성질과 다양한 쓰임새 때문에 힙 메모리의 사용은 사용자와 시스템 모두에게 어려운 숙제입니다.
흔한 오류
1. 메모리 할당 잊어버리기
char *src = “hallo”;
Char *dst;
strcpy(dst, src);이 코드를 실행하면 세그멘테이션 폴트가 발생할 가능성이 높습니다
이 경우, 올바른 코드는 다음과 같을 수 있습니다
char *src = “hallo”;
Char *dst = (char *) malloc(strlen(src) + 1);
strcpy(dst, src);대안으로, strdup()을 사용하여 훨씬 편하게 할 수 있습니다.
2. 메모리를 부족하게 할당받기
이 오류는 메모리를 부족하게 할당받는 것으로, 때때로 버퍼 오버플로우(buffer over-flow)라고 불립니다. 앞의 예에서, 흔한 오류는 목적지 버퍼 공간을 약간 부족하게 할당 받는 것입니다
char *src = “hallo”;
Char *dst = (char *) malloc(strlen(src) + 1); // 너무 작음
strcpy(dst, src); // 제대로 동작세부 사항에 따라서는 이 프로그램이 제대로 동작하는 것처럼 보이는 경우가 종종 있습니다
교훈 : 프로그램이 올바르게 실행된다고 하더라도, 프로그램이 올바르다는 것을 의미하지는 않는다
3. 할당받은 메모리 초기화하지 않기
프로그램은 결국 초기화되지 않은 읽기. 즉 힙으로부터 알 수 없는 값을 읽는 일이 생길 수 있습니다. 재수가 좋으면 잘 동작할 수 있고 아니라면 해로운 값이 읽힐 수 있습니다
4. 메모리 해제하지 않기
메모리 누수를 의미합니다. 장시간 실행되는 응용 프로그램이나 또는 운영체제 자체와 같은 시스템 프로그램에서는 큰 문제입니다. 메모리가 천천히 누수되면 결국 메모리가 부족하게 되고 시스템을 재시작 할 수밖에 없기 때문입니다
중요한 습관 중 하나가 c같은 언어에서 어떻게 메모리를 관리하는지 이해하고 할당받았던 메모리 블럭을 해제하는 것입니다. 메모리 해제 없이도 그럭저럭 개발자로 지낼 수 있겠지만 한 바이트라도 명시적으로 할당받았으면 해제하는 습관을 들이도록 합시다
5. 메모리 사용이 끝나기 전에 메모리 해제하기
Dangling pointer라고 불리며 심각한 실수입니다. 차후 그 포인터를 사용하면 프로그램을 크래시 시키거나 유효 메모리 영역을 덮어쓸 수 있습니다. 예를 들어, free()를 호출하고, 그 후 다른 용도로 malloc()을 호출하면 잘못 해제된 메모리를 재사용합니다
6. 반복적으로 메모리 해제하기
프로그램이 가끔씩 한번 이상 해제하는 경우가 있습니다. 이를 이중 해제(double free)라고 합니다. 결과는 예측하기 어렵습니다. 상상할 수 있듯이 메모리 할당 라이브러리는 어찌할 바 모르게 되고, 모든 종류의 이상한 일을 하게 됩니다. 가장 흔히 일어나는 결과는 크래시입니다
7. free() 잘못 호출하기
free()는 malloc() 받은 포인터만 전달될 것으로 예상합니다. 그 이외의 값을 전달하면 문제가 발생합니다. 유효하지 않은 해제(invalid frees)는 매우 위험하고 당연히 피해야 합니다.
주소 변환의 원리
이 기술은 제한적 직접 실행 방식에 부가적으로 사용되는 기능이라고 생각할 수 있습니다. 주소 변환을 통해 하드웨어는 명령어 반입, 탑재, 저장, 드으이 가상 주소를 정보가 실제 존재하는 물리 주소로 변환합니다. 프로그램의 모든 메모리 참조를 실제 메모리 위치로 재지정하기 위하여 하드웨어가 주소를 변환합니다
동적(하드웨어 기반) 재배치
하드웨어 기반 주소 변환을 이해하기 위하여 먼저 첫 번째 실현 사례를 봤습니다. 1950년대 후반의 첫 번째 시분할 컴퓨터에서 베이스와 바운드(base and bound)라는 아이디어가 채택되었습니다
베이스(base)와 바운드(bound)를 기반으로 한 주소 변환은 메모리 보호 및 가상 주소 관리를 위한 메커니즘입니다. 이 메커니즘은 가상 주소를 실제 물리 주소로 변환하는 데 사용됩니다.
일반적으로 가상 메모리 주소 공간은 프로세스의 주소 공간을 나타냅니다. 가상 주소 공간은 프로세스가 사용하는 메모리에 대한 추상화로, 실제 물리 메모리와는 다른 주소 범위를 가집니다. 가상 주소는 프로세스가 자신만의 독립적인 메모리 공간을 가지는 데 도움이 되며, 여러 프로세스가 동시에 실행될 때 충돌을 방지하기 위해 분리됩니다.
베이스(base)
베이스는 가상 주소 공간의 시작 주소를 나타냅니다. 베이스 값은 가상 주소 공간이 시작되는 물리 메모리 주소를 가리킵니다. 베이스 값은 일반적으로 프로세스의 페이지 테이블이나 페이지 디스크립터에 저장되어 있습니다. 베이스 값은 가상 주소를 물리 메모리 주소로 변환하는 데 사용됩니다
바운드(bound)
바운드는 가상 주소 공간의 크기를 나타냅니다. 바운드 값은 가상 주소 공간의 크기를 제한하는 값으로, 주로 페이지 테이블 또는 페이지 디스크립터에 저장됩니다. 바운드 값은 가상 주소가 유효한 범위 내에 있는지 확인하는 데 사용됩니다.
주소 변환 과정
-
프로세스는 가상 주소를 참조하려고 합니다.
-
가상 주소를 베이스 값과 비교하여 오프셋(offset)을 계산합니다. 오프셋은 가상 주소에서 베이스 값을 뺀 값입니다.
-
오프셋 값이 바운드 값보다 작은지 확인합니다. 작다면, 가상 주소는 유효한 범위 내에 있으므로 접근이 허용됩니다.
-
오프셋 값을 실제 물리 메모리 주소에 더하여 실제 메모리에서의 접근 주소를 얻습니다.
-
이제 프로세스는 실제 메모리에서 해당 주소를 읽거나 쓸 수 있습니다.
베이스와 바운드를 기반으로 한 주소 변환은 가상 메모리 관리 시스템의 일부로 사용되며, 프로세스의 메모리 보호와 가상 주소 공간의 제약을 설정하는 데 도움이 됩니다. 이를 통해 다중 프로세스 시스템에서의 안전성과 격리를 보장할 수 있습니다
