
[내용 정리]
<정렬 알고리즘>
정렬 알고리즘이란?
주어진 데이터 세트를 특정 순서(대개는 숫자의 오름차순 또는 내림차순, 문자열의 사전식 순서)로 배열하는 방법을 제공하는 것이다.
1. 선택 정렬 (Selection Sort)
- 선택 정렬은 배열에서 최소값(또는 최대값)을 찾아 맨 앞(또는 맨 뒤)와 교환하는 방법이다.
- 시간 복잡도 : 최악의 경우와 평균적인 경우 모두 O(n^2)
- 공간 복잡도 : O(1)
<예시> : 선택 정렬 구현 예제
int[] arr = new arr[] { 5, 2, 4, 6, 1, 3 }; for (int i = 0; i < arr.Length - 1; i++) { int minIndex = i; for (int j = i + 1; j < arr.Length; j++) { if (arr[j] < arr[minIndex]) { minIndex = j; } } int temp = arr[i]; arr[i] = arr[minIndex]; arr[minIndex] = temp; } foreach (int num in arr) { Console.WriteLine(num); }
2. 삽입 정렬 (Insertion Sort)
- 삽입 정렬은 정렬되지 않은 부분에서 요소를 가져와 정렬된 부분에 적절한 위치에 삽입하는 방법이다.
- 시간 복잡도 : 최악의 경우 O(n^2), 하지만 정렬되어 있는 경우에는 O(n)
- 공간 복잡도 : O(1)
<예시> : 삽입 정렬 구현 예제
int[] arr = new arr[] { 5, 2, 4, 6, 1, 3 }; for (int i = 1; i < arr.Length; i++) { int j = i - 1; int key = arr[i]; while(j >= 0 && arr[j] > key) { arr[j + 1] = arr[j]; j--; } arr[j + 1] = key; } foreach (int num in arr) { Console.WriteLine(num); }
3. 퀵 정렬 (Quick Sort)
- 퀵 정렬은 피벗을 기준으로 작은 요소들은 왼쪽, 큰 요소들은 오른쪽으로 분할하고 이를 재귀적으로 정렬하는 방법이다.
- 시간 복잡도 : 최악의 경우 O(n^2), 하지만 평균적으로 O(n log n)
- 공간 복잡도 : 평균적으로 O(log n), 최악의 경우 O(n) (재귀 호출에 필요한 스택 공간)
<예시> : 퀵 정렬 구현 예제
void QuickSort(int[] arr, int left, int right) { if (left < right) { int pivot = Partition(arr, left, right); QuickSort(arr, left, pivot - 1); QuickSort(arr, pivot + 1, right); } } int Partition(int[] arr, int left, int right) { int pivot = arr[right]; int i = left - 1; for (int j = left; j < right; j++) { if (arr[j] < pivot) { i++; Swap(arr, i, j); } } Swap(arr, i + 1, right); return i + 1; } void Swap(int[] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } int[] arr = new int[] { 5, 2, 4, 6, 1, 3 }; QuickSort(arr, 0, arr.Length - 1); foreach (int num in arr) { Console.WriteLine(num); }
4. 병합 정렬 (Merge Sort)
- 병합 정렬은 배열을 반으로 나누고, 각 부분을 재귀적으로 정렬한 후, 병합하는 방법이다.
- 시간 복잡도 : 모든 경우에 대해 O(n log n)
- 공간 복잡도 : O(n) (정렬을 위한 임시 배열이 필요함)
<예시> : 병합 정렬 구현 예제
void MergeSort(int[] arr, int left, int right) { if (left < right) { int mid = (left + right) / 2; MergeSort(arr, left, mid); MergeSort(arr, mid + 1, right); Merge(arr, left, mid, right); } } void Merge(int[] arr, int left, int mid, int right) { int[] temp = new int[arr.Length]; int i = left; int j = mid + 1; int k = left; while (i <= mid && j <= right) { if (arr[i] <= arr[j]) { temp[k++] = arr[i++]; } else { temp[k++] = arr[j++]; } } while (i <= mid) { temp[k++] = arr[i++]; } while (j <= right) { temp[k++] = arr[j++]; } for (int l = left; l <= right; l++) { arr[l] = temp[l]; } } int[] arr = new int[] { 5, 2, 4, 6, 1, 3 }; MergeSort(arr, 0, arr.Length - 1); foreach (int num in arr) { Console.WriteLine(num); }
<탐색 알고리즘>
탐색 알고리즘이란?
탐색 알고리즘은 주어진 데이터 집합에서 특정 항목을 찾는 방법을 제공한다. 여기서는 가장 일반적인 탐색 알고리즘 몇 가지를 살펴본다.
1. 선형 탐색 (Linear Search)
- 선형 탐색은 가장 단순한 탐색 알고리즘이다. 배열의 각 요소를 하나씩 차례대로 검사하여 원하는 항목을 찾는다.
- 시간 복잡도 : 최악의 경우 O(n)
<예시> : 선형 탐색 구현 예제
int SequentialSearch(int[] arr, int target) { for (int i = 0; i < arr.Length; i++) { if (arr[i] == target) { return i; } } return -1; }
2. 이진 탐색 (Linear Search)
- 이진 탐색은 정렬된 배열에서 빠르게 원하는 항목을 찾는 방법이다. 중간 요소와 찾고자 하는 항목을 비교하여 대상이 중간 요소보다 작으면 왼쪽을, 크면 오른쪽을 탐색한다.
- 시간 복잡도 : 최악의 경우 O(log n)
<예시> : 이진 탐색 구현 예제
int BinarySearch(int[] arr, int target) { int left = 0; int right = arr.Length - 1; while(left <= right) { int mid = (left + right) / 2; if (arr[mid] == target) { return mid; } else if (arr[mid] < target) { left = mid + 1; } else { right = mid - 1; } } return -1; }
<그래프 (Graph)>
그래프란?
-
정점(Vertex)과 간선(Edge)으로 이루어진 자료 구조
-
방향 그래프(Directed Graph)와 무방향 그래프(Undirected Graph)로 나뉜다.
-
가중치 그래프 (Weighted Graph)는 간선에 가중치가 있음
<그래프 탐색 방법>
-
깊이 우선 탐색 (Depth-First Search, DFS)
DFS는 트리나 그래프를 탐색하는 알고리즘 중 하나로, 루트에서 시작하여 가능한 한 깊이 들어가서 노드를 탐색하고, 더 이상 방문할 노드가 없으면 이전 노드로 돌아가는 방식.- 시간 복잡도 : 최악의 경우 O(V+E) (V는 노드 수, E는 간선 수)
-
너비 우선 탐색 (Breadth-First Search, BFS)
BFS는 트리나 그래프를 탐색하는 알고리즘 중 하나로, 루트에서 시작하여 가까운 노드부터 방문하고, 그 다음 레벨의 노드를 방문하는 방식이다.- 시간 복잡도 : 최악의 경우 O(V+E)
<예시> : DFS, BFS 활용 예제
`
using System;
using System.Collections.Generic;public class Graph
{
private int V; // 그래프의 정점 개수
private List[] adj; // 인접 리스트public Graph(int v) { V = v; adj = new List<int>[V]; for (int i = 0; i < V; i++) { adj[i] = new List<int>(); } } public void AddEdge(int v, int w) { adj[v].Add(w); } public void DFS(int v) { bool[] visited = new bool[V]; DFSUtil(v, visited); } private void DFSUtil(int v, bool[] visited) { visited[v] = true; Console.Write($"{v} "); foreach (int n in adj[v]) { if (!visited[n]) { DFSUtil(n, visited); } } } public void BFS(int v) { bool[] visited = new bool[V]; Queue<int> queue = new Queue<int>(); visited[v] = true; queue.Enqueue(v); while (queue.Count > 0) { int n = queue.Dequeue(); Console.Write($"{n} "); foreach (int m in adj[n]) { if (!visited[m]) { visited[m] = true; queue.Enqueue(m); } } } }}
public class Program
{
public static void Main()
{
Graph graph = new Graph(6);graph.AddEdge(0, 1); graph.AddEdge(0, 2); graph.AddEdge(1, 3); graph.AddEdge(2, 3); graph.AddEdge(2, 4); graph.AddEdge(3, 4); graph.AddEdge(3, 5); graph.AddEdge(4, 5); Console.WriteLine("DFS traversal:"); graph.DFS(0); Console.WriteLine(); Console.WriteLine("BFS traversal:"); graph.BFS(0); Console.WriteLine(); }}
<최단 경로 알고리즘 (Shortest path problem)>
- 다익스트라 알고리즘 (Dijkstra Algorithm)
하나의 시작 정점에서 다른 모든 정점까지의 최단 경로를 찾는 알고리즘이다. 음의 가중치를 갖는 간선이 없는 경우에 사용한다.
<예시> : 다익스트라 알고리즘 예제
using System; class DijkstraExample { static int V = 6; // 정점의 수 // 주어진 그래프의 최단 경로를 찾는 다익스트라 알고리즘 static void Dijkstra(int[,] graph, int start) { int[] distance = new int[V]; // 시작 정점으로부터의 거리 배열 bool[] visited = new bool[V]; // 방문 여부 배열 // 거리 배열 초기화 for (int i = 0; i < V; i++) { distance[i] = int.MaxValue; } distance[start] = 0; // 시작 정점의 거리는 0 // 모든 정점을 방문할 때까지 반복 for (int count = 0; count < V - 1; count++) { // 현재 방문하지 않은 정점들 중에서 최소 거리를 가진 정점을 찾음 int minDistance = int.MaxValue; int minIndex = -1; for (int v = 0; v < V; v++) { if (!visited[v] && distance[v] <= minDistance) { minDistance = distance[v]; minIndex = v; } } // 최소 거리를 가진 정점을 방문 처리 visited[minIndex] = true; // 최소 거리를 가진 정점과 인접한 정점들의 거리 업데이트 for (int v = 0; v < V; v++) { if (!visited[v] && graph[minIndex, v] != 0 && distance[minIndex] != int.MaxValue && distance[minIndex] + graph[minIndex, v] < distance[v]) { distance[v] = distance[minIndex] + graph[minIndex, v]; } } } // 최단 경로 출력 Console.WriteLine("정점\t거리"); for (int i = 0; i < V; i++) { Console.WriteLine($"{i}\t{distance[i]}"); } } static void Main(string[] args) { int[,] graph = { { 0, 4, 0, 0, 0, 0 }, { 4, 0, 8, 0, 0, 0 }, { 0, 8, 0, 7, 0, 4 }, { 0, 0, 7, 0, 9, 14 }, { 0, 0, 0, 9, 0, 10 }, { 0, 0, 4, 14, 10, 0 } }; int start = 0; // 시작 정점 Dijkstra(graph, start); } }
- 벨만-포드 알고리즘 (Bellman-Ford Algorithm)
음의 가중치를 갖는 간선이 있는 그래프에서도 사용할 수 있는 최단 경로 알고리즘이다. 음수 사이클이 있는 경우에도 탐지할 수 있다. - A* 알고리즘 (A-star Algorithm)
특정 목적지까지의 최단 경로를 찾는 알고리즘이다. 휴리스틱 함수를 사용하여 각 정점까지의 예상 비용을 계산하고, 가장 낮은 예상 비용을 가진 정점을 선택하여 탐색한다.
<동적 프로그래밍 (Dynamic Programming, DP)>
동적 프로그래밍이란?
- 동적 프로그래밍은 큰 문제를 작은 하위 문제로 분할하여 푸는 접근 방식이다.
- 작은 하위 문제의 해결 방법을 계산하여 저장하고, 이를 이용하여 큰 문제의 해결 방법을 도출한다. 이러한 저장 과정을 "메모제이션(Memoization)"이라고 한다.
- 일반적으로 재귀적인 구조를 가지며, 하향식(Top-down)과 상향식(Bottom-up) 두 가지 방법으로 구현할 수 있다.
- 동적 프로그래밍은 최적 부분 구조와 중복 부분 문제의 특징을 가진 문제들을 효과적으로 해결할 수 있다.
<예시> : DP로 피보나치 수열 구현
public int Fibonacci(int n) { int[] dp = new int[n+1]; dp[0] = 0; dp[1] = 1; for (int i = 2; i <= n; i++) { dp[i] = dp[i - 1] + dp[i - 2]; } return dp[n]; }
<그리디 알고리즘>
그리디 알고리즘이란?
- 각 단계에서 가장 최적인 선택을 하는 알고리즘이다.
- 각 단계에서 가장 이익이 큰 선택을 하여 결과적으로 최적해에 도달하려는 전략을 따른다.
- 지역적인 최적해를 찾는데 초점을 맞추기 때문에 항상 전역적인 최적해를 보장하지는 않는다.
- 그리디 알고리즘은 간단하고 직관적인 설계가 가능하며, 실행 시간이 매우 빠르다는 특징이 있다.
<예시> : 주어진 동전들로 특정 금액을 만드는데 필요한 최소 동전 수를 구하는 함수
public int MinCoins(int[] coins, int amount) { Array.Sort(coins); int count = 0; for (int i = conis.Length-1; i >= 0; i--) { while (amount >= coins[i]) { amount -= conis[i]; count++; } } if (amount > 0) { return -1; } return count; }
- 위 함수는 주어진 동전들로 특정 금액을 만드는데 필요한 최소 동전 수를 리턴해주는 함수이다.
- 이 문제를 해결하는 데는 그리디 알고리즘을 사용하였으며, 시간 복잡도는 동전의 개수에 비례하므로 O(n)이고, 공간 복잡도는 O(1)이다.
<분할 정복 (Divide and Conquer)>
분할 정복이란?
- 큰 문제를 작은 부분 문제로 분할하므로 문제의 크기에 따른 성능 향상이 가능하다.
- 재귀적인 구조를 가지므로 문제 해결 방법의 설계가 단순하고 직관적이다.
- 분할된 부분 문제들은 독립적으로 해결되므로 병렬 처리에 유리하다.
- 하지만 문제를 분할할 때 발생하는 부분 문제들 간의 중복 계산이 발생할 수 있다. 이런 경우에는 중복 계산을 피하기 위한 메모이제이션 등의 기법을 활용하여 성능을 향상시킬 수 있다.
<예시> : 퀵 정렬을 통해 주어진 배열을 정렬하는 함수
public void QuickSort (int[] arr, int low, int high) { if (low < high) { int pi = Partition(arr, low, high); QuickSort(arr, low, pi - 1); QuickSort(arr, pi + 1, high); } } int Partition (int[] arr, int low, int high) { int pivot = arr[high]; int i = (low - 1); for (int j = low; j <= high - 1; j++) { if (arr[j] < pivot) { i++; Swap(arr, i, j); } } Swap(arr, i+1, high); return (i + 1); } void Swap (int[] arr, int a, int b) { int temp = arr[a]; arr[a] = arr[b]; arr[b] = temp; }
- 위 코드는 주어진 배열을 퀵 정렬 알고리즘을 사용하여 정렬하는 코드이다.
- 이 문제를 해결하는 데는 분할 정복을 사용하였으며, 시간 복잡도는 평균적으로 O(n log n)이고, 최악의 경우 (O^2)가 된다. 공간 복잡도는 O(log n)이다.
[1. Largest Rectangle in Histogram_LeetCode 84번]
<문제>
Given an array of integers heights representing the histogram's bar height where the width of each bar is 1, return the area of the largest rectangle in the histogram.
<번역>
heights 히스토그램의 막대 높이를 나타내는 정수 배열이 주어지고 각 막대의 너비가 인 경우 히스토그램에서 가장 큰 사각형의 면적을1 반환합니다.
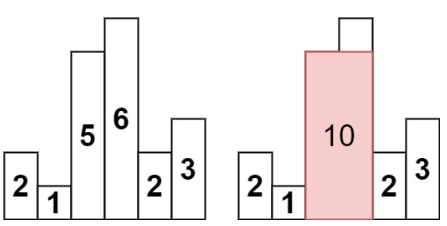
입력 : [2, 1, 5, 6, 2, 3]
출력 : 10
설명 : The above is a histogram where width of each bar is 1.
The largest rectangle is shown in the red area, which has an area = 10 units.
public class Solution { public int LargestRectangleArea(int[] heights) { Stack<int> st = new Stack<int>(); int result = 0; for(int i = 0; i < heights.Length; i++) { while(st.Count() != 0 && heights[i] < heights[st.Peek()]) { int h = heights[st.Peek()]; st.Pop(); int w; if(st.Count == 0){ w = i; } else{ w = i - st.Peek() - 1; } result = Math.Max(result, h * w); } st.Push(i); } while(st.Count != 0) { int h = heights[st.Peek()]; st.Pop(); int w; if(st.Count == 0){ w = heights.Length; } else{ w = heights.Length - st.Peek() - 1; } result = Math.Max(result, h * w); } return result; } }
<풀이>
힌트를 보고 스택을 이용해서 풀면 되겠다고 생각하여 스택을 활용해서 해결했다.
-
스택에 막대의 주소(i)를 저장하며 순회하면서, 각 바에 대해서 아래와 같이 수행하면 된다.
1. 스택이 비어 있지 않고, 현재 바의 높이가 스택 top의 막대 높이보다 낮을 경우
현재 막대는 제외하고 스택 top의 바를 기준으로 만들 수 있는 가장 큰 직사각형을 구하고 최대 넓이를 갱신한다. 높이(h)는 스택 top의 막대 높이이고, 너비(w)는 새로운 top(이전에 pop을 한번 진행하였으므로 스택의 2번째 인덱스라고 할 수 있음)에 존재하는 막대와 현재 막대 사이에 존재하는 막대의 너비이다.
2. 스택이 비어 있고, 현재 바의 높이가 스택의 top 막대 높이보다 낮을 경우
스택top의 막대를 pop했을 때, 해당 막대가 1번째 막대거나 전에 push했던 막대들이 전부 해당 막대보다 높은 경우이므로 너비(w)는 i가 된다. 나머지 처리는 1번과 같다.
3. 순회가 끝난 후 스택에 막대가 남아 있는 경우
이들도 위와 같은 처리를 해주면서 최대 넓이를 갱신해주면 된다.
[2. Flood Fill_LeetCode 733번]
<문제>
You are given an image represented by an m x n grid of integers image, where image[i][j] represents the pixel value of the image. You are also given three integers sr, sc, and color. Your task is to perform a flood fill on the image starting from the pixel image[sr][sc].
To perform a flood fill:
Begin with the starting pixel and change its color to color.
Perform the same process for each pixel that is directly adjacent (pixels that share a side with the original pixel, either horizontally or vertically) and shares the same color as the starting pixel.
Keep repeating this process by checking neighboring pixels of the updated pixels and modifying their color if it matches the original color of the starting pixel.
The process stops when there are no more adjacent pixels of the original color to update.
Return the modified image after performing the flood fill.
<번역>
이미지는 정수 이미지의 m x n 격자로 표시되며, 여기서 image[i][j]는 이미지의 픽셀 값을 나타냅니다. 또한 세 개의 정수 sr, sc, color가 주어집니다. 당신의 임무는 픽셀 이미지[sr][sc]에서 시작하여 이미지에 플러드 채우기를 수행하는 것입니다.
플러드 채우기 수행하기:
시작 픽셀부터 시작하여 색상을 color로 변경합니다.
각 픽셀에 대해 동일한 프로세스를 수행합니다(원래 픽셀과 한 면을 수평 또는 수직으로 공유하는 픽셀). 시작 픽셀과 동일한 색상을 공유합니다.
업데이트된 픽셀의 인접 픽셀을 확인하고 시작 픽셀의 원래 색상과 일치하는지 색상을 수정하여 이 과정을 계속 반복합니다.
원래 색상의 인접 픽셀이 더 이상 업데이트되지 않으면 프로세스가 중지됩니다.
플러드 채우기를 수행한 후 수정된 이미지를 반환합니다.
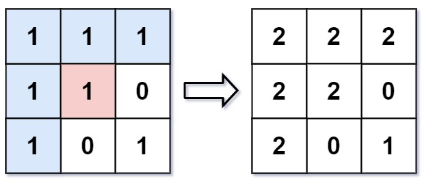
입력 : [[1, 1, 1], [1, 1, 0], [1, 0, 1]], sr = 1, sc = 1, color = 2
출력 : [[2, 2, 2], [2, 2, 0], [2, 0, 1]]
설명 : From the center of the image with position (sr, sc) = (1, 1) (i.e., the red pixel), all pixels connected by a path of the same color as the starting pixel (i.e., the blue pixels) are colored with the new color.
Note the bottom corner is not colored 2, because it is not horizontally or vertically connected to the starting pixel.
public class Solution { int[] dx = new int[] {1,0,-1,0}; int[] dy = new int[] {0,1,0,-1}; public void DFS(int x, int y, int[][] image, int color, int startColor){ if (image[x][y] != startColor) { return; } image[x][y] = color; for(int i=0;i<4;i++){ int next_x = x + dx[i]; int next_y = y + dy[i]; if (next_x >= 0 && next_x < image.Length && next_y >= 0 && next_y < image[0].Length) { DFS(next_x,next_y, image, color, startColor); } } } public int[][] FloodFill(int[][] image, int sr, int sc, int color) { if (image[sr][sc] == color) { return image; } DFS(sr,sc,image,color,image[sr][sc]); return image; } }
<풀이>
해당 문제는 DFS를 활용하여 해결할 수 있다.
-
시작 위치의 색이 바꿀 색상과 같으면 색변경이 필요 없으므로 바로 image를 return 한다.
-
DFS를 통해 시작위치와 색이 같으며 인접한(상하좌우로 연결되어 있으면 인접해 있다고 정의한다) 위치에 존재하는 픽셀을 새로운 색으로 바꾼다. 이때, DFS 함수를 활용해서 재귀적으로 호출하면 인접한 픽셀의 색을 모두 바꿀 수 있다.
[3. Longest Increasing Subsequence_LeetCode 300번]
<문제>
Given an integer array nums, return the length of the longest strictly increasing subsequence.
<번역>
주어진 정수 배열에서, 최장 증가 부분 수열을 반환하라.
입력 : nums = [10, 9, 2, 5, 3, 7, 101, 18]
출력 : 4
설명 : The longest increasing subsequence is [2,3,7,101], therefore the length is 4.
public class Solution { public int LengthOfLIS(int[] nums) { int[] dp = new int[nums.Length]; for(int i=0;i<nums.Length;i++){ dp[i] = 1; } int result = 0; for(int i=0;i<nums.Length;i++){ for(int j=0;j<i;j++){ if(nums[i] > nums[j]){ dp[i] = Math.Max(dp[i], dp[j] + 1); } } result = Math.Max(result, dp[i]); } return result; } }
<풀이>
여러가지 방법이 있겠지만, 나는 DP를 이용해서 해결했다.
간단하게 설명하면 배열을 순회하며 각 부분까지의 최장 증가 부분 수열의 길이를 구해 dp배열에 저장하고, 최대값을 갱신하는 식으로 문제를 해결했다.
