
Introduction
오늘도 알수없는 유튜브 알고리즘이 날 여기로 이끌었다...

넋놓고 유튜브를 몇시간째 보신 분들은 위의 댓글을 보신적이 있으실 겁니다. 처음 내가 원하는 영상을 보다보면, 어느 순간 평소에 관심도 없던 유튜브를 보고 있는 제 자신을 발견할 때가 종종있습니다. 저같은 경우엔 "패트병으로 재활용 아이디어"라든지, "10년 전 가수 무대 영상"이라든지.. 분명 게임 영상을 보고 있었는데 알수없는 유튜브 알고리즘에 빠져 관련없는 영상을 본 경우가 매우 많습니다.
위에서 말한 유튜브 알고리즘의 핵심은 추천 시스템입니다. 이번 포스팅에서는 Isinkaye, F. O., Folajimi, Y. O., & Ojokoh, B. A. (2015). Recommendation systems: Principles, methods and evaluation. Egyptian Informatics Journal, 16(3), 261-273. 논문의 리뷰로서 추천 시스템 분야의 전체적인 개요에 대해 알아보도록 하겠습니다.
추천 시스템(Recommendation System)이란?
추천 시스템이란, 유저의 선호도 및 과거 행동을 바탕으로 개인에 맞는 관심사를 제공하는 분야를 말합니다. 이러한 추천 시스템은 위에서 말했듯이 유튜브와 같은 비디오추천에도 쓰이지만, 온라인 쇼핑몰이나 뉴스 추천, 금융 상품 추천, 검색 시스템 등 다양한 분야에서 사용되고 있습니다.
추천 시스템은 서비스 제공자와 유저에게 모두 이득이 될 수 있습니다.
- 서비스 제공자 : quailty가 높은 상품 제공으로 인한 수익 창출
- 유저 : 원하는 상품을 찾기 위한 시간 절감, 새로운 상품에 대한 접근 용이
랭킹 시스템(Ranking System)과 추천 시스템의 차이
사용자에게 Top N개의 상품을 추천해주는 것은 추천 시스템에 추천 시스템 분야에는 잘 포함하지는 않습니다. 그 이유는 개인의 성향이나 과거의 행동에 대한 정보가 반영되지 않았다는 점입니다.
추천 시스템 방법론
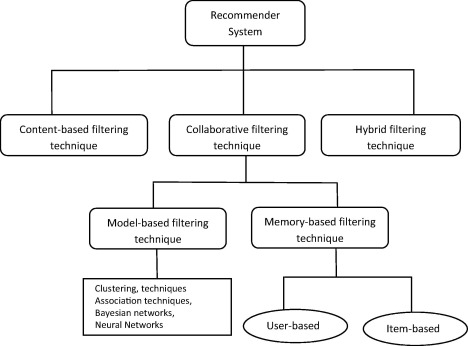
1. Content-based Filtering
콘텐츠 기반 필터링(Content-based Filtering)은 해당 아이템의 도메인을 활용한 것으로 유저가 관심있는 아이템의 속성을 분석하여 새로운 아이템을 추천해주는 것입니다. 뒤에서 설명드릴 Collaborative Filtering(Item-based)와 다른 점은 다른 유저의 정보가 사용되지 않는다는 점입니다.
예를 들면, 내가 산 옷과 비슷하게 생긴 옷을 추천해주거나 뉴스 기사가 비슷하거나 관련된 다른 뉴스를 추천해주는 경우에 자주 사용됩니다.
이러한 콘텐츠 기반 필터링은 아이템들의 feature를 잘 추출하기 위한 TF-IDF(Term Frequency - Inverse Document Frequency)나 Word2Vec과 같은 Feature Extraction 방법론이 사용됩니다. 또한, 추출된 feature를 통해 아이템을 비교할 유사도(Similarity)에 대한 선택도 중요합니다.
- 장점 : 유저의 선호도에 대한 정보 없이, 아이템 정보만으로 추천 가능
- 단점 : 아이템을 설명할 수 있는 데이터(item's metadata) 구축이 필요.
2. Collaborative Filtering
협업 필터링(Collaborative Filtering, CF)은 유저-아이템의 관계(User-Item interaction)로부터 도출되는 추천 시스템입니다.

- 장점 : 아이템에 대한 콘텐츠의 정보 없이 사용 가능
- 단점1 Cold Start : ‘새로 시작할 때 곤란함’을 의미하며, 새로운 유저나 아이템의 초기 정보 부족의 문제점
- 단점2 Data Sparsity : 수 많은 유저와 아이템 사이에 경험하지 못한, 구매해보지 못한 경우가 데이터의 대부분을 차지함 (Ex. 온라인 쇼핑몰에서 내가 구매한 목록보다 구매하지 않은 목록이 압도적으로 많음)
- 단점3 Scalability : 유저와 아이템의 수가 많아질수록 데이터의 크기가 기하급수로 커짐
2_1. Memory-based Filtering
User-Item Matrix로부터 도출되는 유사도 기반으로 아이템을 추천을 합니다.
2_1_1. User-based
유저 간의 선호도(아이팀에 대한 점수)나 구매 이력을 비교하여 추천하는 방법을 User-based CF라고 합니다.
예를 들면, 유저 A가 [라면, 삼각김밥, 김치, 콜라]를 샀다고 하면, 유저 A와 가장 유사한 쇼핑 목록을 갖고 있는 유저 B [라면, 삼각김밥, 김치]에게 [콜라]를 추천해주는 것입니다.
2_1_2. Item-based
User-based와는 반대로 아이템 간의 유저 목록을 비교하여 추천하는 방법입니다.
예를 들면, 라면을 [유저 A, 유저 B, 유저 C, 유저 D]가 구매를 했다면, 라면을 산 유저의 목록과 가장 비슷한 삼각김밥 [유저 A, 유저 B, 유저 C, 유저 E]을 유저 D에게 추천하는 것입니다. 또는, 유저 E에게 라면을 추천해줄 수도 있습니다.
2_2. Model-based Filtering
Model-based CF는 User-Item interaction을 머신러닝이나 딥러닝과 같은 모델을 학습하는 것을 말합니다.
장바구니 분석(Association rule)과 같이 아이템 간의 관계를 학습할 수도 있고, Clustering을 통해 유사한 아이템이나 유저 간의 그룹을 형성할 수도 있습니다. 이 외에도 Matrix Factorization, Bayesian Network, Decision Tree 등 많은 방법론이 사용됩니다.
3. Hybrid Filtering
콘텐츠 기반 필터링과 협업 필터링은 장단점이 있기 때문에 두 방법을 같이 활용하는 방법을 Hybrid Filtering이라고 합니다.
정말 많은 파생 방법론이 있지만, 대표적으로 데이터가 적은 초기단계에는 콘텐츠 기반 필터링으로 하다가 어느정도 데이터가 누적이 되면 협업 필터링으로 변경하는 것도 포함이 됩니다.
Doodles
개인적으로 추천 시스템을 공부하게 된 이유는 크게 세 가지 가지가 있습니다.
첫 번째, 추천 시스템 분야는 다양한 방법론으로 구성되어 있다는 점이다. 단 하나의 방법론으로는 추천 문제를 풀 수는 없습니다. 데이터 Sparsity, Scalability를 해결하기 위한 Matrix Factorization, Feature Extraction으로 시작해서 아이템(혹은 유저)사이의 유사성, 또는 제3의 모델링 등 여러 단계가 필요하기 때문에 알고 싶은 것도 많고, 해보고 싶은 것도 많습니다.
두 번째, 논리적 구성을 필요로합니다. 가령, 예측력만 요구하는 task에선 모델링 가정 없이 여러 모델을 사용하여 가장 좋은 것을 선택하는 경우가 있습니다. 하지만, 추천 시스템의 논문들을 보면 "어떠한 가정을 갖고, 이렇게 방법론을 구성하였습니다."라는 고민의 흔적이 있습니다.
세 번째, "개인화"라는 단어의 인식 변화입니다. 과거의 개인화는 개인 인적 정보나 세상과 고립된 무언가에 자주 쓰이던 단어였는데, 최근에는 실시간으로 개인의 성향과 니즈에 맞춰 알맞는 경험을 할 때 자주 쓰입니다. 심지어, 초개인화라는 단어가 나올 정도로 앞으로의 미래는 점점 개인에 맞춘 특별한 경험을 중요시하게 될 것 같습니다.
앞으로의 포스팅에는 추천 시스템 관련 논문을 주로 리뷰하도록 하겠습니다.

안녕하세요, 포스팅에 사용하신 이미지와 일부 정리 내용들을 혹시 스터디 활동에서 정리겸 작성하는 위키독스 문서에 사용 가능할까요?(영리목적이 없고, 출처를 기재해 놓겠습니다!)