목표
3회차: 23/07/22 13:00~16:00
계획: YOLO 논문 분석 (1)
방향: 'A COMPREHENSIVE REVIEW OF YOLO: FROM YOLOV1 AND
BEYOND' 논문 분석
결과
개요
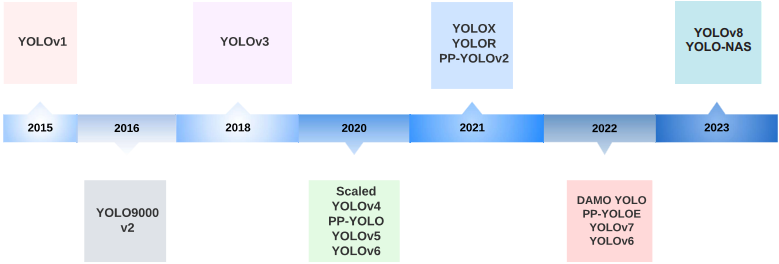
YOLO 모델의 버전별 진화 과정(YOLOv1 ~ YOLOv8)을 분석한 논문입니다. 모델의 버전에 따라 도입된 네트워크 구조 및 학습 기법 등의 소개하고, YOLO 모델의 미래 연구 방향을 제시합니다.
real-time Object Detection의 포문을 연 YOLO는 수많은 Object Detection 알고리즘 중에서 speed와 accuracy 두 측면의 밸런스를 유지했다는 평가를 받습니다. YOLO 모델은 network design, loss function, anchor box, input resolution scaling 등의 변화를 적용해 진화를 거듭했습니다.
본문
YOLOv1
- You Only Look Once Objcet Detection을 네트워크를 한 번 지남으로써 수행할 수 있음 → 1-stage 프로세스
- 이전까지의 모델(Fast R-CNN)에서는 Regional Proposal을 진행한 후 Classification을 진행하는 2-stage 프로세스를 활용
- 1-stage 프로세스를 진행함으로써 더 빠른 detection을 가능 → real-time
- Process
 bounding box(이하 bbox)를 detect하는 과정을 동시에 진행
bounding box(이하 bbox)를 detect하는 과정을 동시에 진행- input image를 크기의 grid로 나눔
- 모든 grid에서 개의 bbox와 모든 클래스의 confidece 를 각각 예측
- 는 하나의 grid에서 detect하는 bbox의 개수
- (bbox의 confidence score)와 , (bbox의 중심 좌표), , (bbox의 높이와 너비)로 구성됨
- 는 , , , (: 클래스 개수)으로 구성됨
- output: 크기의 tensor
- 는 하나의 grid에서 detect하는 bbox의 개수
- NMS(Non-Maximum Suppression)을 적용해 중복된 bounding box 제거

- Architecture 24개의 Conv layer와 2개의 FC layer로 구성
-
모든 layer에서 leaky rectified linear unit activation 사용
-
Conv layer를 사용해 feature map과 parameter의 수를 줄임
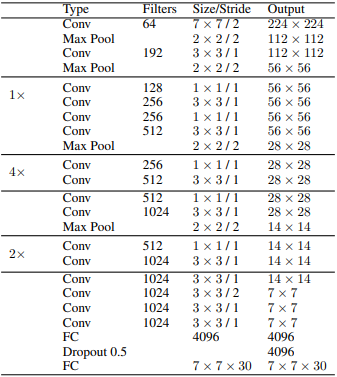
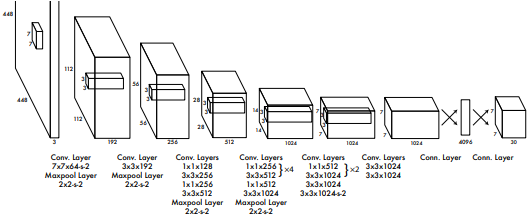
-
- Loss Function localization, confidence, classification에 대한 loss의 합으로 구성 detect한 bbox에 object가 없을 시에는 낮은 가중치를 부여

- Strengths and Limitations
- Fast R-CNN과 비교했을 때 speed가 개선되어 real-time detect가 가능
- 하지만 localization error는 더 높음
- 하나의 grid에서 최대 2개의 객체만 탐지를 하게 해서 인접한 물체에 대한 예측 성능이 떨어짐
- 학습 데이터와 종횡비가 다른 물체에 대해서는 예측 성능이 떨어짐
- down-sampling layer을 이용해 추출된 feature의 품질이 떨어짐
Architecture
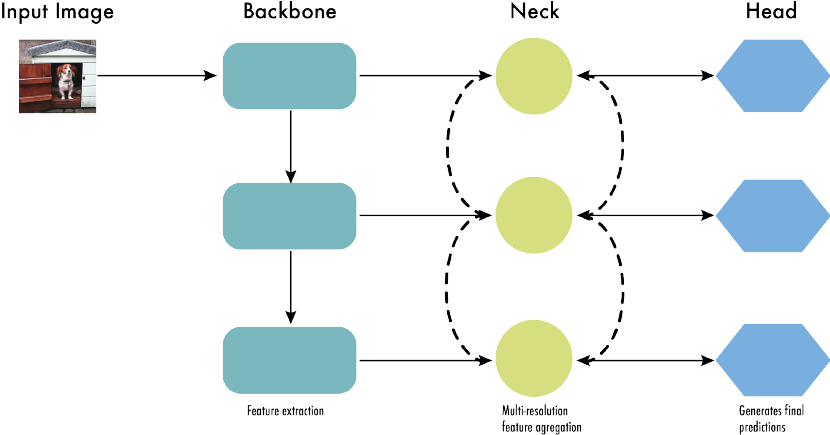
CNN 모델은 대체적으로 위와 같은 형태로 구성됨
- Backbone: feature 추출
- Neck: feature 정제 및 강화
- Head: 예측 수행
YOLOv2(YOLO9000)
J. Redmon and A. Farhadi, “Yolo9000: better, faster, stronger,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017
- Developments
- Batch Normalization: 모든 convolutional layer에 도입해 convergence 개선 및 overfitting 감소
- High-Resolution Classifier: 더 큰 이미지()을 이용해 finetune → 큰 이미지에 대한 성능 개선
- Fully Convolutional: dense layer를 제거하고, fully convolutional하게 만듦
- Use Anchor Boxes to Predict Bbox: 미리 정의된 shape의 anchor box를 각 grid마다 도입해 anchor box의 좌표와 class를 예측
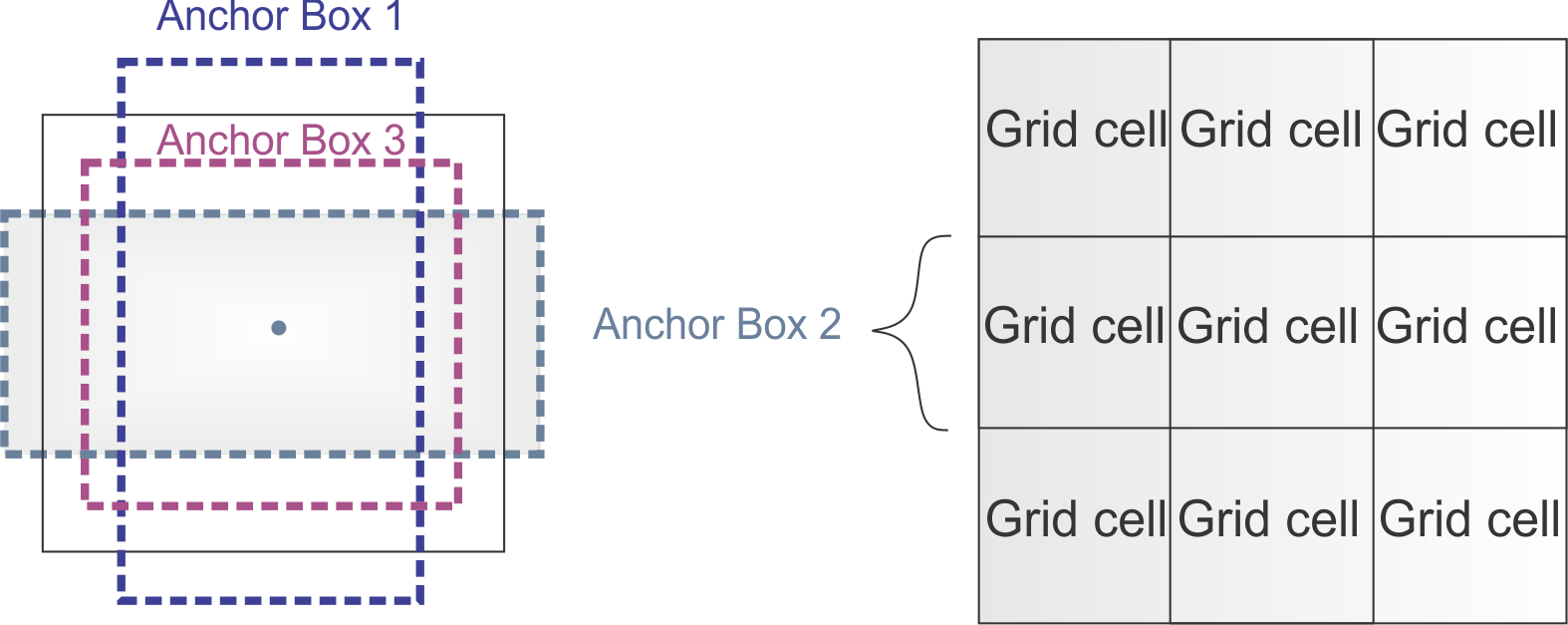
- Dimension Clusters: 적절한 shape의 anchor box를 선정하기 위해 k-mean clustering을 이용해 학습해 각 grid마다 5개의 achor box를 선정
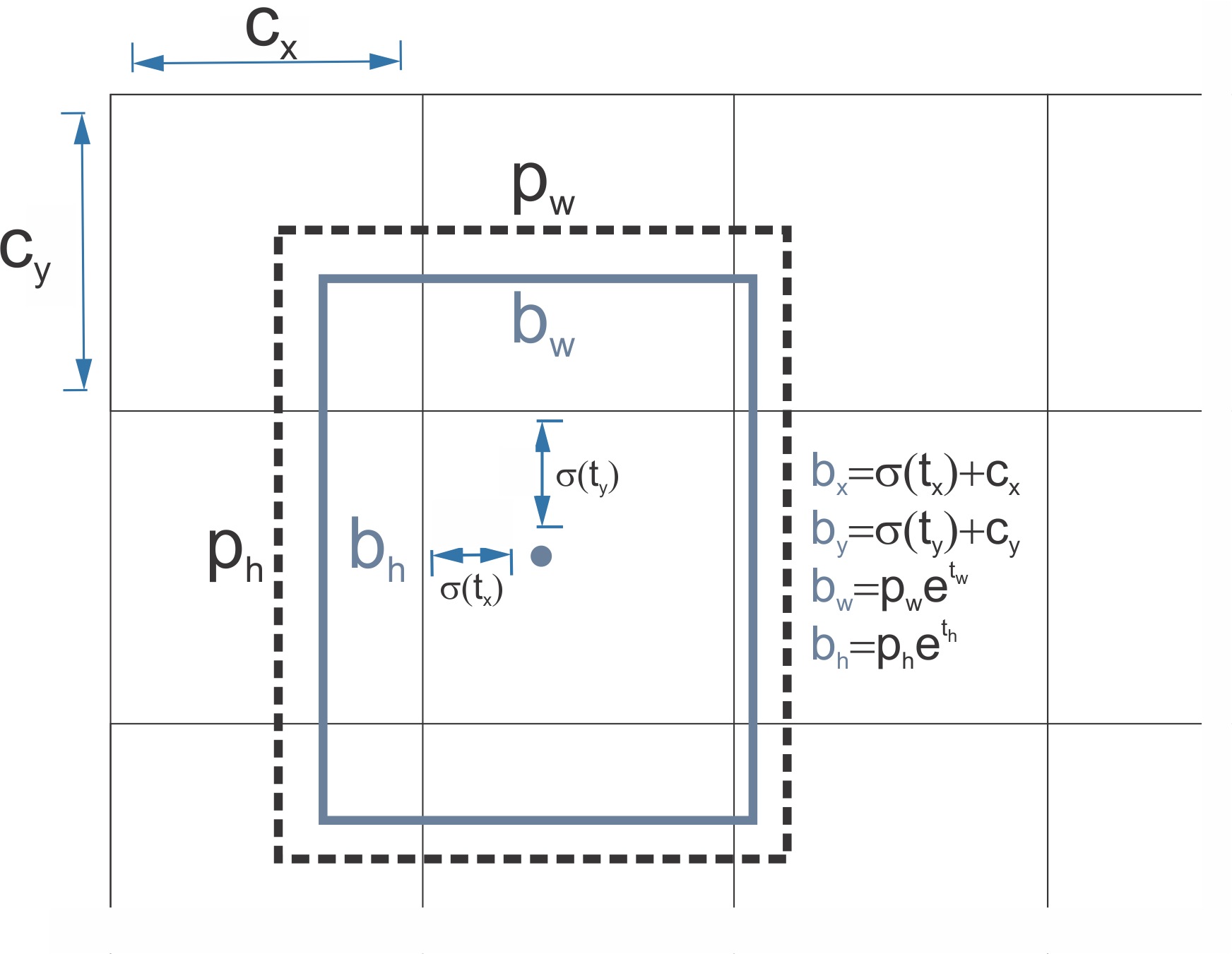
- Direct Location Prediction: YOLOv1에서와 유사하게 각 grid 별로 예측, 각 grid 내의 bbox마다 , (bbox 중심 좌표), , (bbox의 너비와 높이), (confidence score)를 예측
- Finner-Grained Features: passthrough layer를 사용해 주변 feature map을 feature map으로 reorganize(인접한 feature를 쌓는 구조) → subsampling으로 인해 소실되는 feature를 보존
- Multi-Scale Training: FC layer를 사용하지 않아 다양한 크기의 이미지를 input으로 사용 가능, 이를 활용해 다양한 크기의 이미지를 활용( ~ )해 학습을 진행 → 다양한 크기의 객체를 detect하는 데 도움
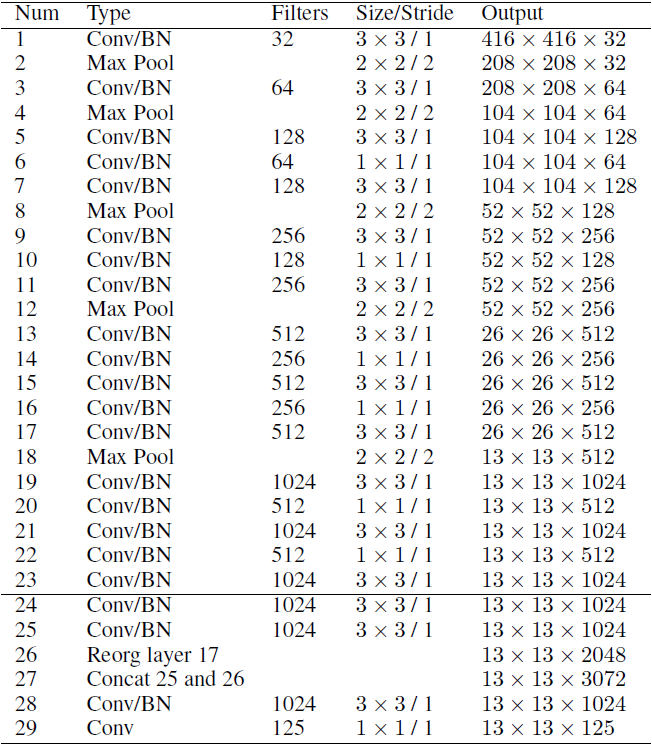
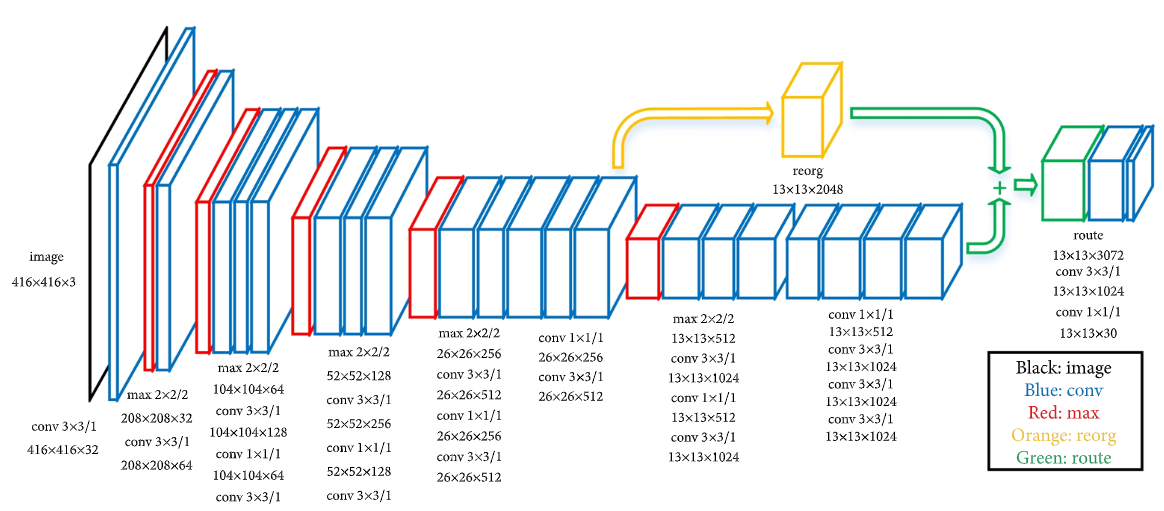
- Architecture
-
Darknet-19를 backbone으로 사용(19개의 convolutional layer와 5개의 pooling layer로 구성)
-
~ convolutional layer를 사용해 parameter 수를 줄임
-
passthrough layer 도입
-
마지막에는 1000개의 convolutional layer와 global average pooling layer, 그리고 softmax로 구성
-
