
MOS7 기반 퍼블릭 클라우드 구축은 완성됐고 이제부터 서비스 운영의 시간이다.
알 수 없는 무작위의 고객들과 무작위의 서비스들을 클라우드로 받아들이기 시작한 것이다.
서비스 운영에 대한 회고를 하기 위해선 핵심적인 두가지 구조의 설명과 함께 진행해야 하는데 첫번째는 네트워크 레이어(neutron) 이고 두번째는 스토리지 레이어(cinder) 이다.
네트워크 레이어는 "Neutron + OpenVSwitch + DVR" 의 조합으로 구성된 구조이다.
먼저 하드웨어 셋업은 아래와 같다.
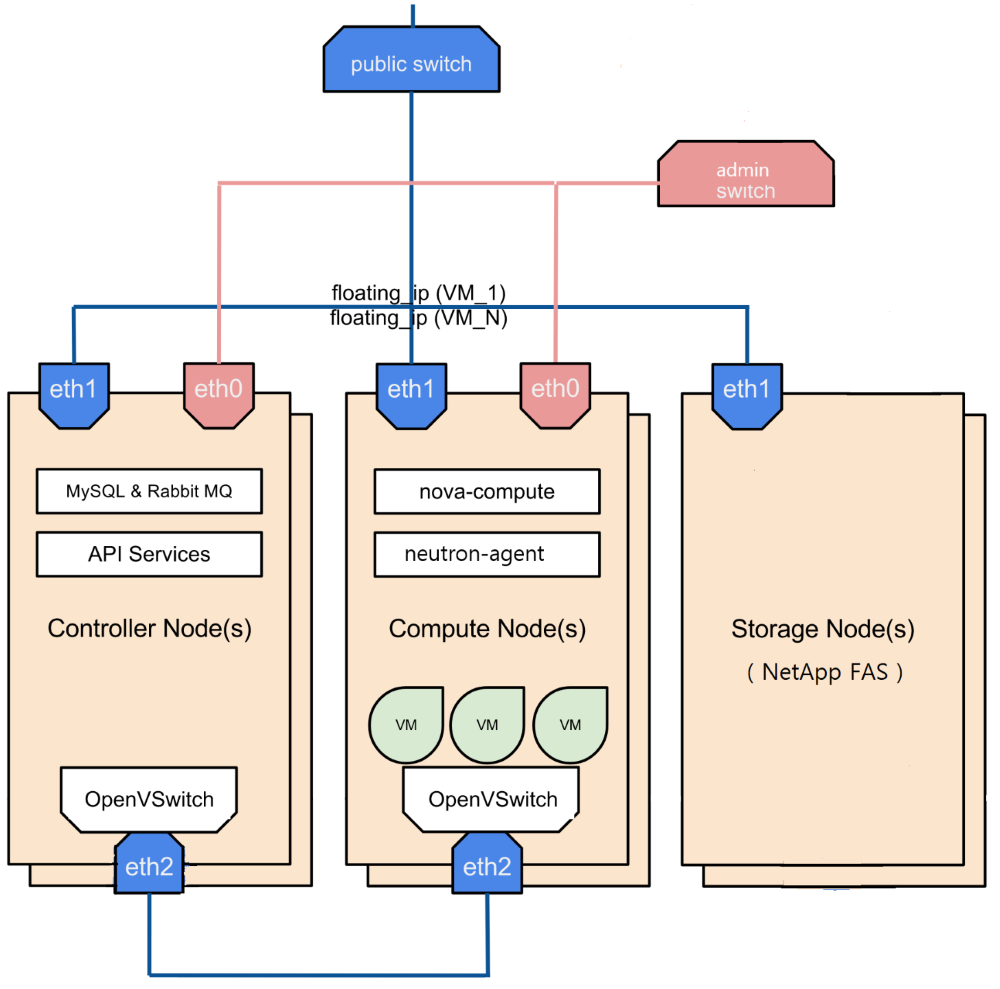
네트워크 인터페이스 설명
eth0: 클라우드 서비스 배포/설치 및 노드 관리 용도eth1: VLAN Tagging 을 통해 2개의 가상 인터페이스로 나누어 사용
- 외부 용: VM 이 외부와 통신하는 용도로 사용 ex)
eth1.101- 관리 용: OpenStack 컴포넌트 간의 통신 또는 스토리지의 데이터 경로 용도로 사용 ex)
eth1.102eth2: VM 에서 VM 으로 통신하는 용도로 사용
MOS 에는 Mirantis 에서 제공하는 Fuel 이란 배포 전용 소프트웨어가 있다.
Fuel 노드는 배포 대상 전체 노드들과 eth0 를 통해 연결되어 있고 PXE 를 이용해서 MOS 를 배포/설치한다.
그림의 admin switch 는 pxe 통신을 제공하기 위해 별도로 분리된 스위치로 생각하면 된다.
Controller Nodes 와 Compute Nodes 사이에는 많은 OpenStack 컴포넌트들이 서로 요청 메세지를 주고 받는데, 해당 통신은 eth1.102 를 통해 이뤄진다.
Compute Nodes 와 Storage Nodes(NetApp) 사이에는 API 요청을 전달하거나 실제 데이터가 오고 가는데, 이 통신도 eth1.102 를 통해 이뤄진다. 하지만 이 부분은 다음 세대 클라우드 서비스 구축때 별도의 VLAN Tagging 인터페이스로 분리하는 방향으로 변경되었다.
Compute Nodes 내부의 VM 이 외부와 통신할때는 eth1.101 을 사용하고 VM 과 VM 사이의 통신은 eth2 를 사용한다.
아래는 DVR 에 대한 설명이다.
L3 agent:iptables를 기반으로 네트워크 라우팅 기능 제공
Router Namespace: 가상 라우터 역할을 하는 네트워크 네임스페이스(netns)로 L3 agent 에 의해 각 테넌트 별로 OS 레벨에서 만들어진다.
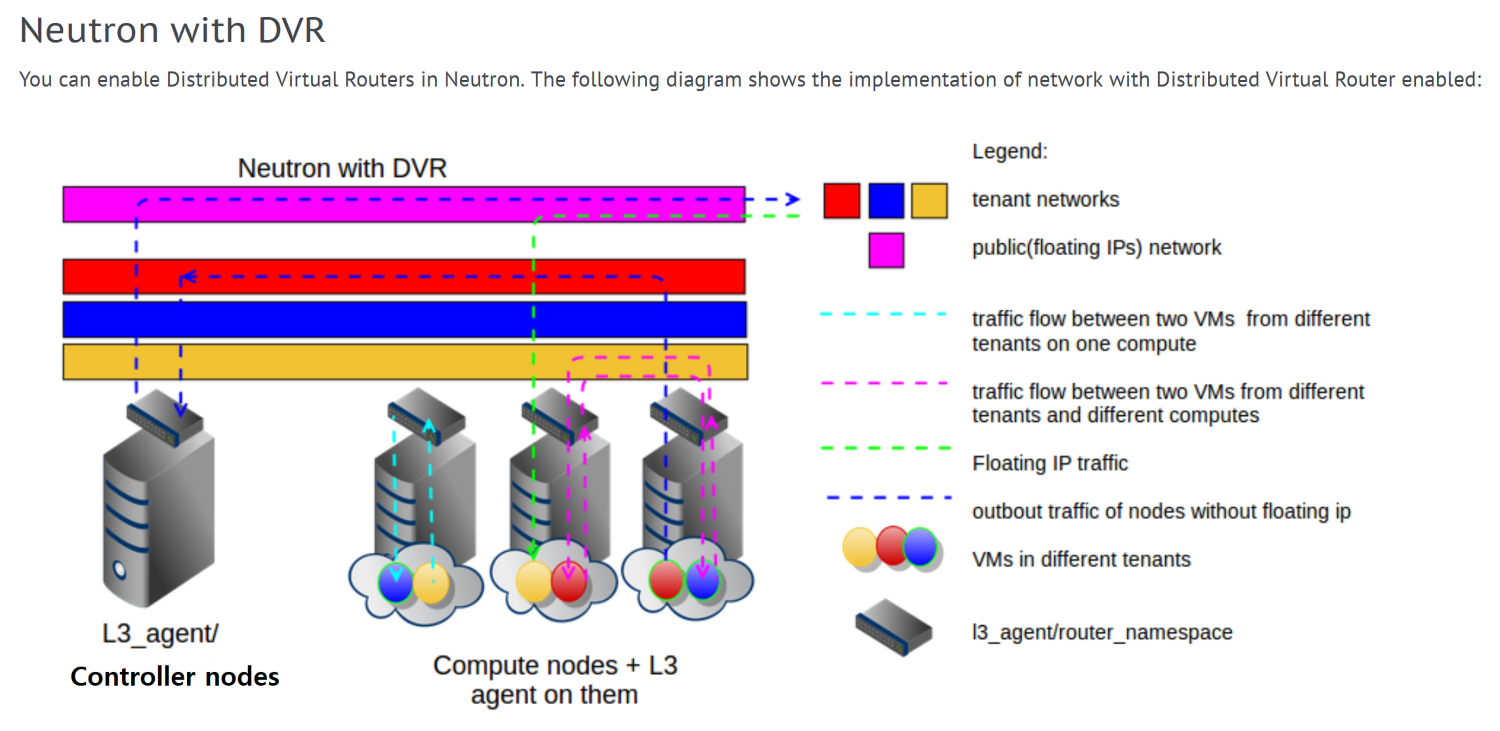
위 그림을 보면 각 노드마다 L3 agent 가 분포되어 있다. 이를 통해 VM 은 호스팅되고 있는 Compute Node 에서 바로 외부로 통신이 가능하다.
예전에는 네트워크 전용 노드를 통해서 외부로 통신이 이뤄지는 Centralized 방식을 사용했는데 이는 Single Point of Failure 와 같은 여러가지 단점이 있었다.
이를 개선하고자 나온 DVR 은 Distributed 방식을 사용하여 더 높은 안정성과 효율성을 제공한다.
Neutron 은 가상의 네트워크 레이어를 구현하는 컴포넌트이고 여기서 L2 레벨은 OpenVSwitch, L3/L4 레벨은 L3 agent 를 이용하여 전체 네트워크 기능을 구현한다.
VM to Internet 의 네트워크 흐름은 대략 아래와 같다.
1. VM 에서 출발한 패킷은 VETH Pair 를 통해 OpenVSwitch 용 브릿지 인터페이스로 전달된다.
- VM 내부의 인터페이스는 실제론 VETH 디바이스로 구현되며 해당 VETH Pair 의 하나는 VM, 다른 하나는 OpenVSwitch 용 브릿지 인터페이스에 연결된다.
2. OpenVSwitch 용 브릿지 인터페이스에서 도착지가 외부 네트워크임을 확인하고 패킷을 가상 라우팅 용 네트워크 네임스페이스로 전달한다.
- OpenVSwitch 용 브릿지 인터페이스는 L2 레벨의 네트워크 흐름을 제어하며 가상의 MAC 주소와 VLAN 정보를 확인하고 패킷 도착지가 내부 네트워크인지 외부 네트워크인지 판별한다.
3. 가상 라우팅 용 네트워크 네임스페이스에는 iptables 의 Chain FORWARD,PREROUTING,POSTROUTING 을 이용하여 만들어진 라우팅 룰이 있다. 전달된 패킷은 해당 라우팅 룰에 의해 외부 인터넷으로 보내진다.
VM to VM 의 네트워크 흐름은 대략 아래와 같다.
1. VM 에서 출발한 패킷은 VETH Pair 를 통해 OpenVSwitch 용 브릿지 인터페이스로 전달된다.
2. OpenVSwitch 용 브릿지 인터페이스는 도착지가 내부 네트워크임을 확인하고 패킷을 eth2 와 연결된 브릿지 인터페이스로 전달한다.
3. 패킷은 eth2 를 통해 다른 노드의 eth2 로 전달되고 해당 노드의 OpenVSwitch 용 브릿지 인터페이스로 다시 전달된다
4. OpenVSwitch 용 브릿지 인터페이스는 MAC 주소와 VLAN 을 확인하고 노드에 등록된 VM 에게 패킷을 전달한다.
Neutron 은 위와 같이 다양한 기술과 모듈의 조합으로 전체 네트워크 기능을 구현한다.
서비스를 운영하면서 네트워크 레이어에서 가장 중점적으로 다뤄야 했던 부분은 컴포넌트 기능의 기반이 되는 기술들이었다.
왜냐하면 만약 VM 통신에 문제가 있거나 패킷 흐름이 이상하면 팀은 결국 서비스의 가장 아래 레벨까지 가서 원인을 파악해야 했기 때문이다.
대표적으로 아래와 같은 작업이 예시가 될 수 있다.
iptables을 확인하여 SNAT/DNAT 룰이 정상적으로 등록되어 있는지 확인한다.- 네트워크 네임스페이스 안에 있는 가상 인터페이스의 패킷 처리 상태를 확인한다
- Compute Node 의
nf_conntrack_count를 확인하여 과도한 트래픽 또는 DDoS 공격이 발생 중인지 확인한다.
다양한 기술로 이루어진 컴포넌트이지만 결국 근간은 리눅스의 기능에 기반하고 있고 이 부분을 자세히 다룰줄 알아야 서비스도 안정적으로 운영할 수 있었다.
특히 네트워크 레이어는 문제가 발생하면 노드 단위로 발생되는 경우가 많기 때문에 다수의 VM 으로 장애 범위가 확산되므로 더욱 더 신경써야 했다.
스토리지 레이어는 백엔드 스토리지는 넷앱 제품을 사용하였고 "Cinder + iSCSI + DM-Multipathing" 의 조합으로 구성된 구조였다
구조 설명
- 넷앱 스토리지는 HA 를 위해 2개의 컨트롤러를 사용하고 각 컨트롤러는 전용 네트워크 포트를 갖는다.
- 두 컨트롤러로 부터 스위치로 2개의 Path 가 연결되고 이 경로를 통해 데이터가 전달된다.
- iSCSI 프로토콜은 백엔드 볼륨으로 LUN 을 사용한다.
- 하나의 LUN 이 생성되면 2개의 Path 를 통해 Compute Node 전달되기 때문에 노드에서는 2개의 볼륨 디바이스를 인식한다.
- 하지만 실제로 이 두 디바이스는 하나의 LUN 이기 때문에 VM에서 사용하기 위해선 두 디바이스를 하나로 묶어줘야 한다.
- 두 디바이스를 하나의 디바이스로 묶는 작업은
dm-multipath를 통하여 이뤄지고 생성된 DM 디바이스가 VM 에게 전달된다.
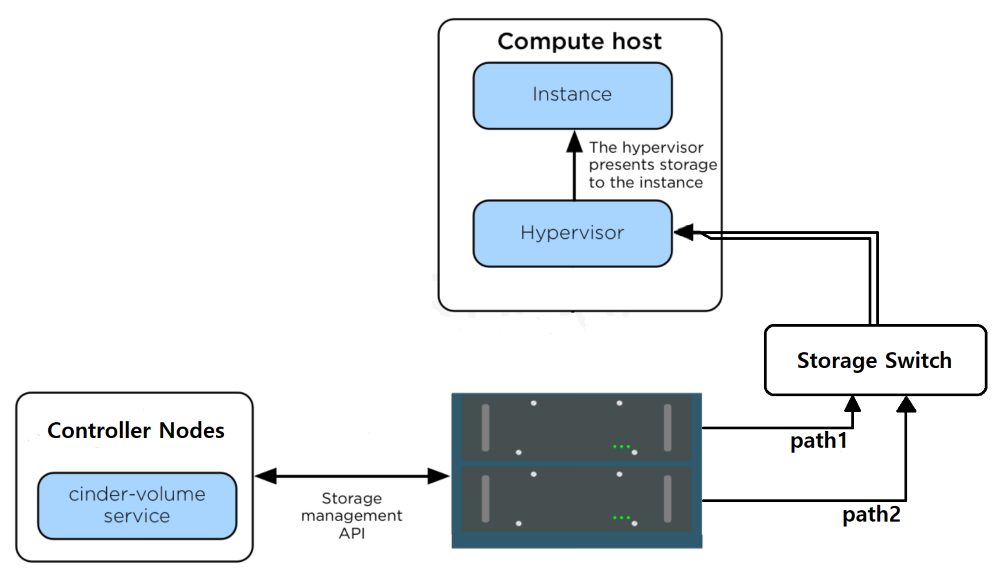
넷앱 스토리지는 서로 구분되는 2개의 컨트롤러를 사용하는 구조이기 때문에 iSCSI 프로토콜을 사용한다면 반드시 dm-multipath 를 함께 사용해야 한다.
그래서 이렇게 구현된 스토리지 레이어를 관리하기 위해서는 기반 기술의 유틸리티인 iscsiadm 과 multipath 를 자세히 다룰줄 알아야 한다.
다음은 운영에 자주 사용한 대표적인 유틸리티 커맨드이다.
- iSCSI 세션 상태를 확인한다.
# iscsiadm -m session
tcp: [1] StorageController#1:3260,1028 iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3
tcp: [2] StorageController#2:3260,1029 iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3- 노드에 타켓 스토리지가 정상적으로 인식(discovery) 되었는지 확인한다.
# iscsiadm -m discovery -t st -p StorageController#1
StorageController#1:3260,1028 iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3
StorageController#2:3260,1029 iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3
# iscsiadm -m discovery -t st -p StorageController#2
StorageController#2:3260,1029 iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3
StorageController#1:3260,1028 iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3- iSCSI 세션 로그인/로그아웃을 진행한다
# iscsiadm -m node -l
tcp: [1] StorageController#1:3260,1028 iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3 logged in
tcp: [2] StorageController#2:3260,1029 iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3 logged in
# iscsiadm -m node -u -T iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3
Logging out of session [sid: 2, target: iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3, portal: StorageController#1,3260]
Logout of [sid: 2, target: iqn.1992-08.com.netapp:sn.ecb222a99a0111e6b5dc00a098a7bccd:vs.3, portal: StorageController#1,3260] successful.- DM 디바이스 상태를 확인한다.
# multipath -ll
3600a0980383038524a5d497962322d4d dm-5 NETAPP ,LUN C-Mode # 정상 DM 디바이스
size=50G features='0' hwhandler='0' wp=rw
|-+- policy='round-robin 0' prio=50 status=active
| `- 3:0:0:1 sdg 8:96 active ready running
`-+- policy='round-robin 0' prio=10 status=enabled
`- 2:0:0:1 sdf 8:80 active ready running
3600a09803830384c652b497954596f43 dm-23 NETAPP ,LUN C-Mode # 비정상 DM 디바이스
size=50G features='0' hwhandler='0' wp=rw
|-+- policy='round-robin 0' prio=50 status=active
| `- 2:0:0:10 sdx 65:112 failed faulty running
`-+- policy='round-robin 0' prio=10 status=enabled
`- 3:0:0:10 sdy 65:128 failed faulty running- 사용하지 않는 DM 디바이스를 정리한다.
# multipath -F
# multipath -ll
3600a0980383038524a5d497962322d4d dm-5 NETAPP ,LUN C-Mode # 정상 DM 디바이스만 남는다
size=50G features='0' hwhandler='0' wp=rw
|-+- policy='round-robin 0' prio=50 status=active
| `- 3:0:0:1 sdg 8:96 active ready running
`-+- policy='round-robin 0' prio=10 status=enabled
`- 2:0:0:1 sdf 8:80 active ready running서비스 운영시 VM 에 연결된 cinder 볼륨에서 I/O 가 안되거나 볼륨이 갑자기 떨어지는 것과 같은 장애가 발생하면 대부분은 위의 유틸리티를 사용하여 OS 레벨에서 자세히 살펴봐야 했다.
그리고 OpenStack 컴포넌트의 로그와 데몬 로그 그리고 백엔드 스토리지의 로그 등을 통합적으로 살펴보며 문제의 전체 흐름을 파악할 수 있는 능력도 매우 중요했다.
퍼블릭 클라우드 서비스 운영에 대한 회고를 핵심적인 두가지 구조와 함께 진행해보았다.
3년 간 서비스 구축 및 운영을 하며 당시로선 꽤 새롭고 복잡한 기술을 배울수 있었고 다양한 장애를 통해 운영에 대한 많은 경험을 할 수 있었다.
대형 장애로 인해 몇 일을 잠도 못자고 퇴근도 미루며 장애 처리를 하기도 하고 개발팀과 One Team 이 되어 서로 도와주며 서비스를 만들기도 했다.
기술적인 측면이나 개인적인 측면에서 엔지니어로서 매우 큰 성장을 할 수 있는 시간이었다고 생각된다.
이것으로 OpenStack 업무에 대한 회고를 마친다.
