
SQL의 격언중에는 다음과 같은 말이 있다고 한다.
"조건 분기를 WHERE(HAVING)구로 하는 사람은 초보자다. 잘하는 사람은 SELECT구만으로 조건 분기를 한다"
여기에서 조건 분기를 WHERE(HAVING)로 한다는 의미는
UNION을 주로 활용하는 것이라고도 할 수 있다.
조건을 WHERE(HAVING) 절으로 구분하고, SELECT 결과값들을
UNION을 통해 결합하는 방식이기 때문이다.
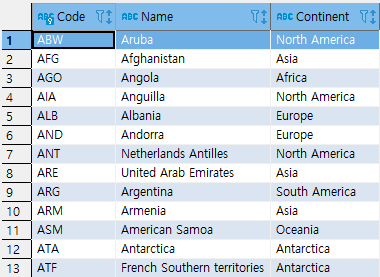
만약 다음과 같은 DATA를 가진 Table이 존재하고
대륙(Continent)내에 20개 이하의 나라(name)를 가진 대륙을 '작은 대륙'
20~40개 이하를 '중간 대륙', 40~60개 이하를 '큰 대륙'이라고 임의로 분류한다면
이를 union을 활용해 구하는 SQL, 결과, 실행계획은 다음과 같다.
select continent as '대륙명', count(name) as '대륙안에 있는 나라수', '작은 대륙' as '분류'
from country
group by continent
having COUNT(*) < 20
union
select continent as '대륙명', count(name) as '대륙안에 있는 나라수', '중간 대륙' as '분류'
from country
group by continent
having COUNT(*) >=20
and COUNT(*) < 40
union
select continent as '대륙명', count(name) as '대륙안에 있는 나라수', '큰 대륙' as '분류'
from country
group by continent
having COUNT(*) >= 40
and COUNT(*) < 60;
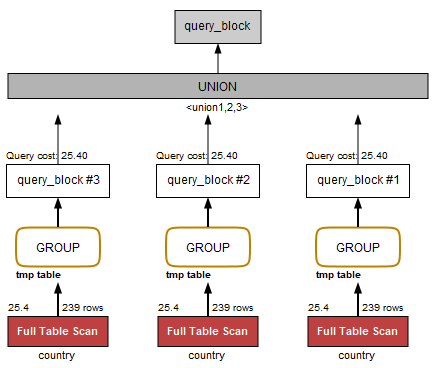
위의 SQL이 부정확한 결과를 가져오지는 않지만
성능상으로는 아쉬운 부분이 있다.
바로 continent 테이블을 3번 스캔하고 있다는 점이다.
앞의 DBMS 글에서 적은 것과 같이 SQL 처리에서 가장 많은 자원을 소모하는
작업 중 하나는 테이블 스캔이라고 할 수 있다.
데이터가 많아지면 많아질 수록 읽어야할 ROW가 늘어나기 때문에 부하는 더 늘어날 것이다.
그에 반해 아래의 SQL은 같은 결과가 나오지만
continent 테이블을 단 1번 스캔하므로 속도는 3배 가량 빠르다고 할 수 있다.
select continent as '대륙명',
count(name) as '대륙안에 있는 나라수',
case
when count(name) < 20 then '작은 대륙'
when count(name) >= 20 and count(name) < 40 then '중간 대륙'
when count(name) >= 40 and count(name) < 60 then '큰 대륙'
end as '분류'
from country
group by continent;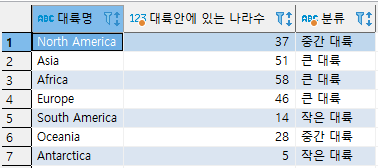

이와 같은 성능의 차이는 분기를 어디에서 하느냐에 따라 갈릴 수 있다.
분기를 WHERE(HAVING)절에서 하는 경우는 SQL문의 실행순서(FROM -> WHERE -> SELECT)상
WHERE절에서 버려지는 데이터가 너무 많고 버려진 후 재활용도 불가하다.
그에 반해 SELECT절 정확히는 CASE에서 분기를 처리할 경우 조건(분기)에 따라
FROM 절에서 가져온 전체 데이터를 버리지 않고 모두 분류 할 수 있으므로 낭비가 적어진다.

그렇다고 해서 UNION절이 항상 좋지 않은 것은 아니다.
크게 2가지 경우에서는 UNION절을 활용하는 것이 좋은데 이는 다음과 같다.
- 합쳐야하는 대상 Table이 다른 경우(A + B)
- Table의 크기가 크고, WHERE절에서 선택되는 레코드 수가 적을 경우(INDEX 사용을 가정)
참고한 책의 말미에는 '구문'이 아니라 '식'으로
'절차 지향적 코드'에서 '선언형 코드'를 지향하는 것이 SQL 능력 향상의 핵심이라고 말한다.
https://boxfoxs.tistory.com/430 글을 보며 위의 말이 조금 더 이해 되긴 하였으나
이를 SQL에 어떻게 녹여내야 하는지는 더 공부가 필요하다는 생각이 들었다.
참고도서 : SQL 레벨업(한빛미디어)
