DB
1.DBMS
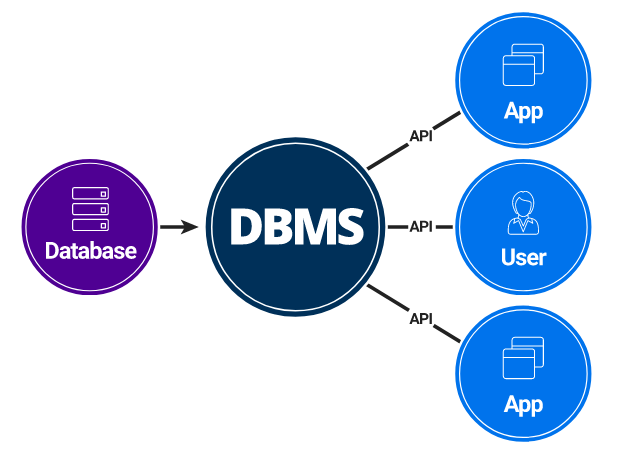
DB에 대한 공부를 더욱 진행 해야겠다는 생각으로온라인에서 추천받은 'SQL 레벨업'이라는 책을 선택하게 되었다.(절반 정도 읽었는데 새로운 내용이나 잘 정리된 내용들이 많아서 추천!)DBMS의 전체적인 구조이다.책에 있는 이미지와 가장 유사한 이미지라 가지고 와봤다.
2.CASE와 UNION

SQL의 격언중에는 다음과 같은 말이 있다고 한다. "조건 분기를 WHERE(HAVING)구로 하는 사람은 초보자다. 잘하는 사람은 SELECT구만으로 조건 분기를 한다"여기에서 조건 분기를 WHERE(HAVING)로 한다는 의미는UNION을 주로 활용하는 것이라고도
3.반복계와 포장계

RDB를 처음 생각해냈던 Codd라는 사람은 이러한 말을 했다고 한다.관계 조작(SQL)은 관계 전체를 모두 조작의 대상으로 삼는다. 이러한 것의 목적은 반복을 제외하는 것이다.이처럼 초기 설계단계에서부터 SQL은 반복문을 지양하며 만들어진 언어라 한다.그리고 그렇게
4.JOIN

SQL 성능을 결정하는 결정적인 요소 중 하나는 JOIN이다.기준이 되는 Data(FROM)를 만드는 과정이기 때문에 Table 스캔이 빈번하게 일어나고관련 Table간의 연결도 만들어야 하기 때문에 많은 자원이 소요된다.조인에 주로 사용되는 알고리즘은 위의 세가지이지
5.INDEX
한동안은 DB에 관한 마지막 글이 될 것 같다.DB를 정리하기 전에 INDEX를 빼먹고 가면 뭔가 찜찜해서 짚고 넘어가고자 한다.사실 index에 관해서는 깊이있게 잘 정리된 글들이 이미 존재해서 링크로 대신하는 것이 쓰는 사람의 시간과 읽는 사람의 시간 모두를 아낄
6.SQL 튜닝(Why)

왜 SQL 튜닝인가?(Why)Application 성능을 향상 시키는 방법에는 Caching, DB Replication, Shading, Scale up/out... 등이 있겠지만가장 가성비가 좋고(추가적인 요소나 비용이 들지 않고)근본적인 해결책은 SQL 튜닝이므로
7.SQL 튜닝(What)
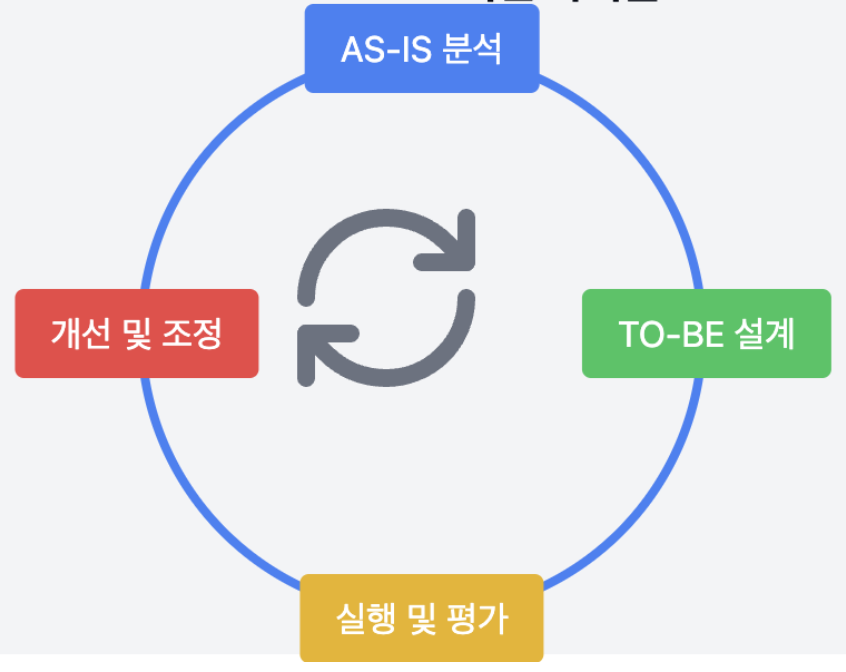
SQL 튜닝이라는 것은 결국 AS-IS와 TO-BE를 비교해서 더 나은 것은 선택하는 과정이고이러한 선택에는 기준 즉 비교할 Data가 필요하다.이러한 비교 Data는 아래 2가지로 알 수 있다.실행 시간실행 계획실행 계획을 분석하는 것도 중요하지만 결국은 실제 동작을
8.SQL 튜닝(How - 1. 복합 Index? 단일 Index? )

SQL 튜닝을 위해 Index를 활용해야 하는 것도 알겠고어떤 기준(실행 시간/계획)으로 판단하며 진행 해야하는지도 알게된 상황에서그럼 각 Case에 따라서 어떻게(How) Index를 적용해야 하는지 알아보자!문제가 되는 Query가 위와 같다고 가정해보자(data는
9.SQL 튜닝(How - 2. WHERE vs ORDER BY)
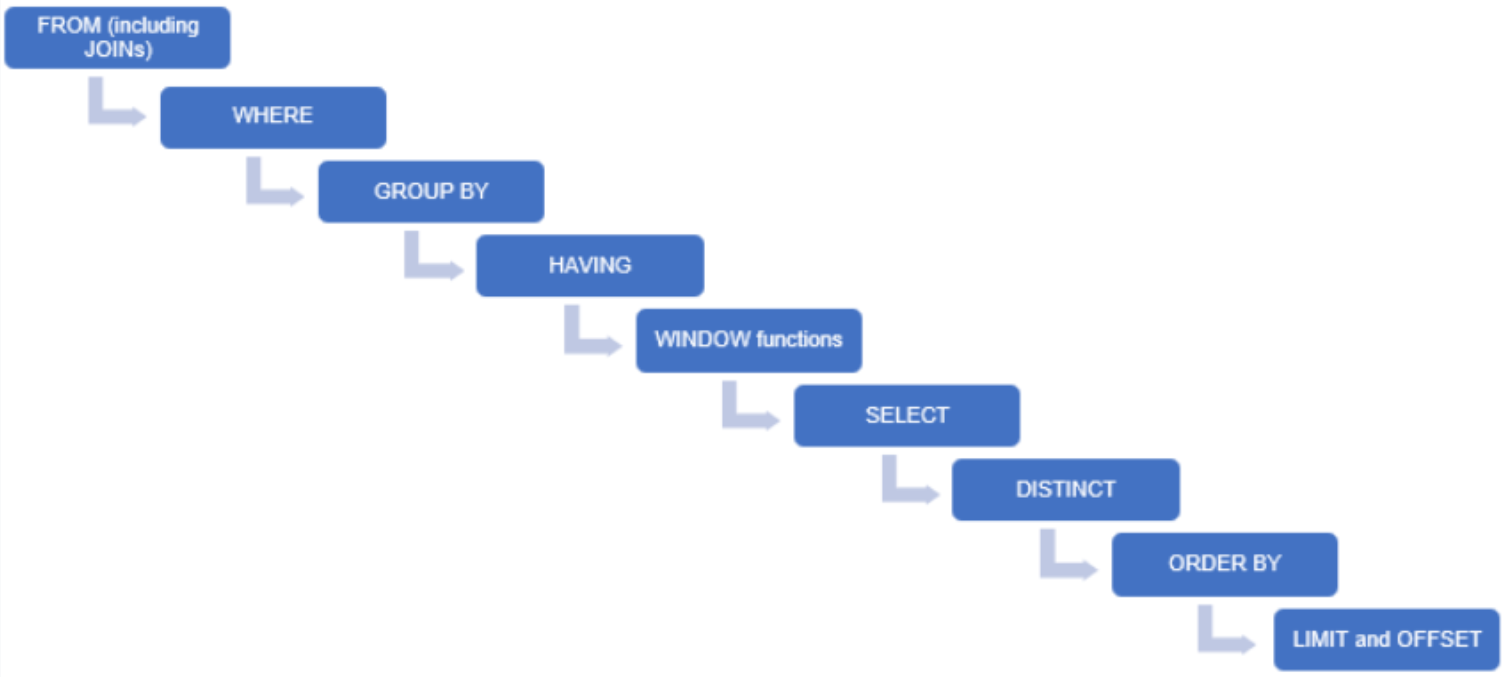
SQL 튜닝에서 절대적인 원칙은 없다. 실행 시간과 실행 계획을 실제로 분석하여 Index를 적합하게 적용하자.(DBMS마다도 다르다 - 위 image는 mysql의 sql 실행 순서 : oracle은 조금 다르다)튜닝을 해볼 Query는 위와 같다.Index 적용이
10.SQL 튜닝(How - 3. HAVING 절에 Index 적용?)
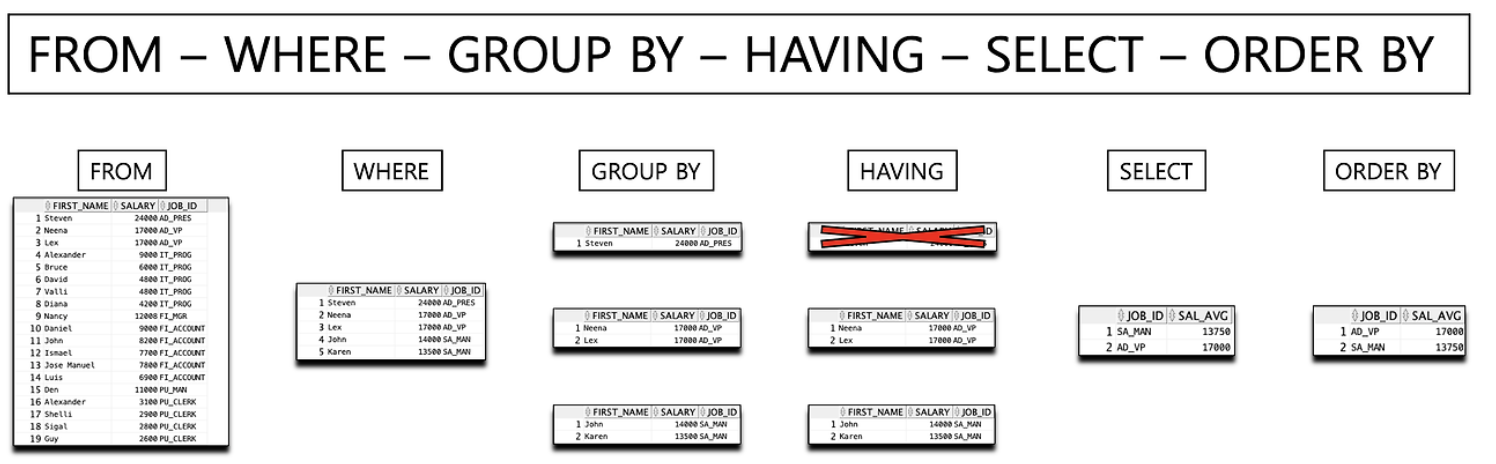
SQL 실행 순서를 더 직관적으로 이해할 수 있는 좋은 이미지다.결국 튜닝에서도 기본 개념이 중요하다는 생각이 들었다. 튜닝을 해볼 Query는 위와 같다.적용해 볼 컬럼은 age 하나로 보이는데 age에 index를 적용하면 어떻게 될까?실행 시간 : 263ms실행