오늘은 react 데이터 흐름에 대해 알아보자!
앞 블로그 포스트에서 설명했듯이 React의 개발 방식의 가장 큰 특징은 페이지 단위가 아닌, 컴포넌트 단위로 시작한다는 점이다.
아래 그림과 같이 앱의 프로토타입을 전달받았다면 먼저 컴포넌트를 찾아보자!

프로토타입에서 그림과 같이 컴포넌트를 찾아냈다!
이렇게 먼저 컴포넌트를 만들고, 다시 페이지를 조립해나가야 한다!
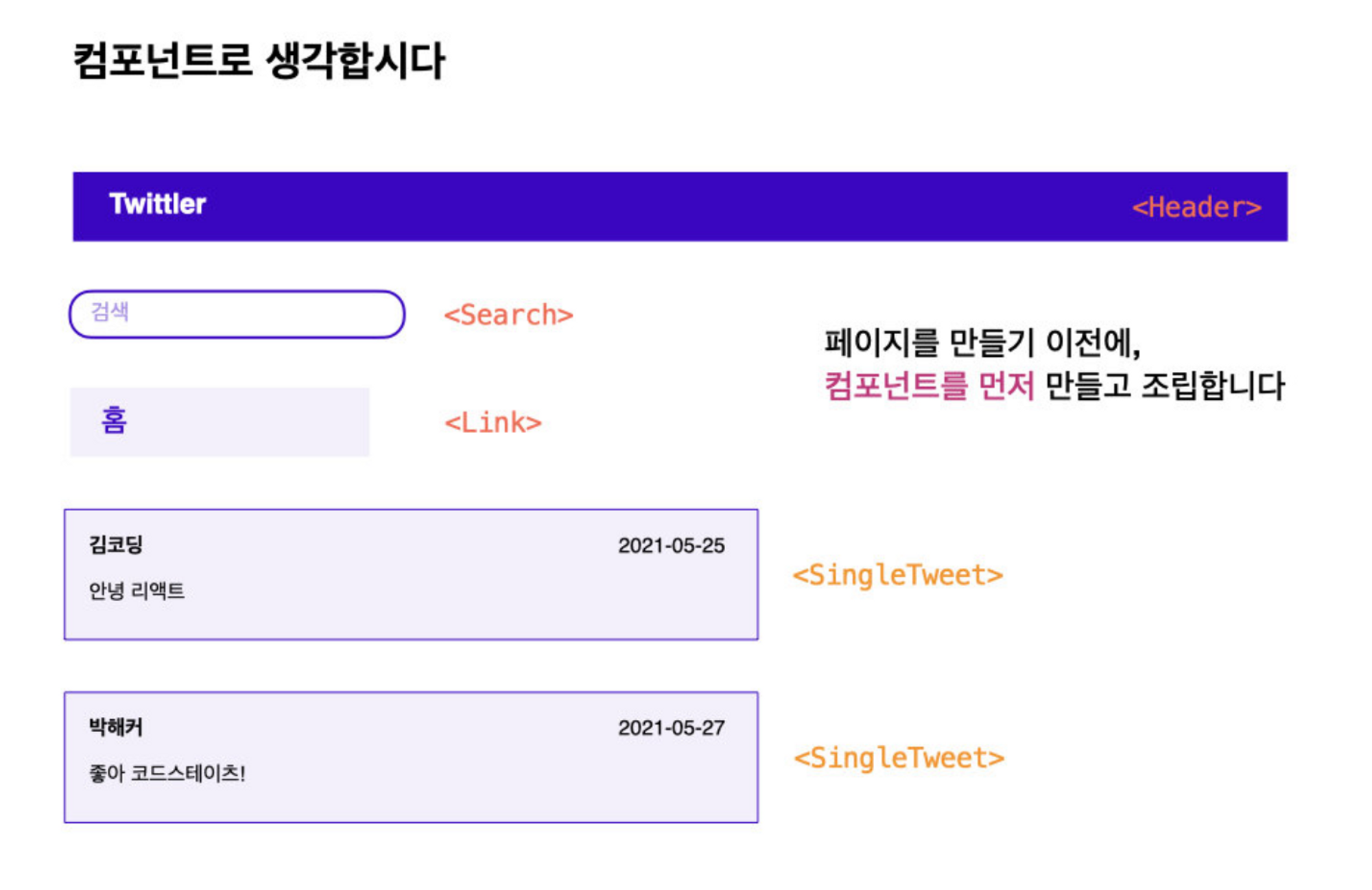
그림과 같이 상향식(bottom-up)으로 앱을 만들어야 한다.
상향식의 가장 큰 장점은 테스트가 쉽고 확장성이 좋다.
그래서 기획자나 PM, 또는 UX 디자이너로부터 앱의 디자인을 전달받고 나면, 이를 컴포넌트 계층 구조로 나누는 것이 가장 먼저 해야 할 일이다!
여기, 단순한 트위터 클론이 있다...

여기서 컴포넌트로 나누면 이런 형식이 된다!
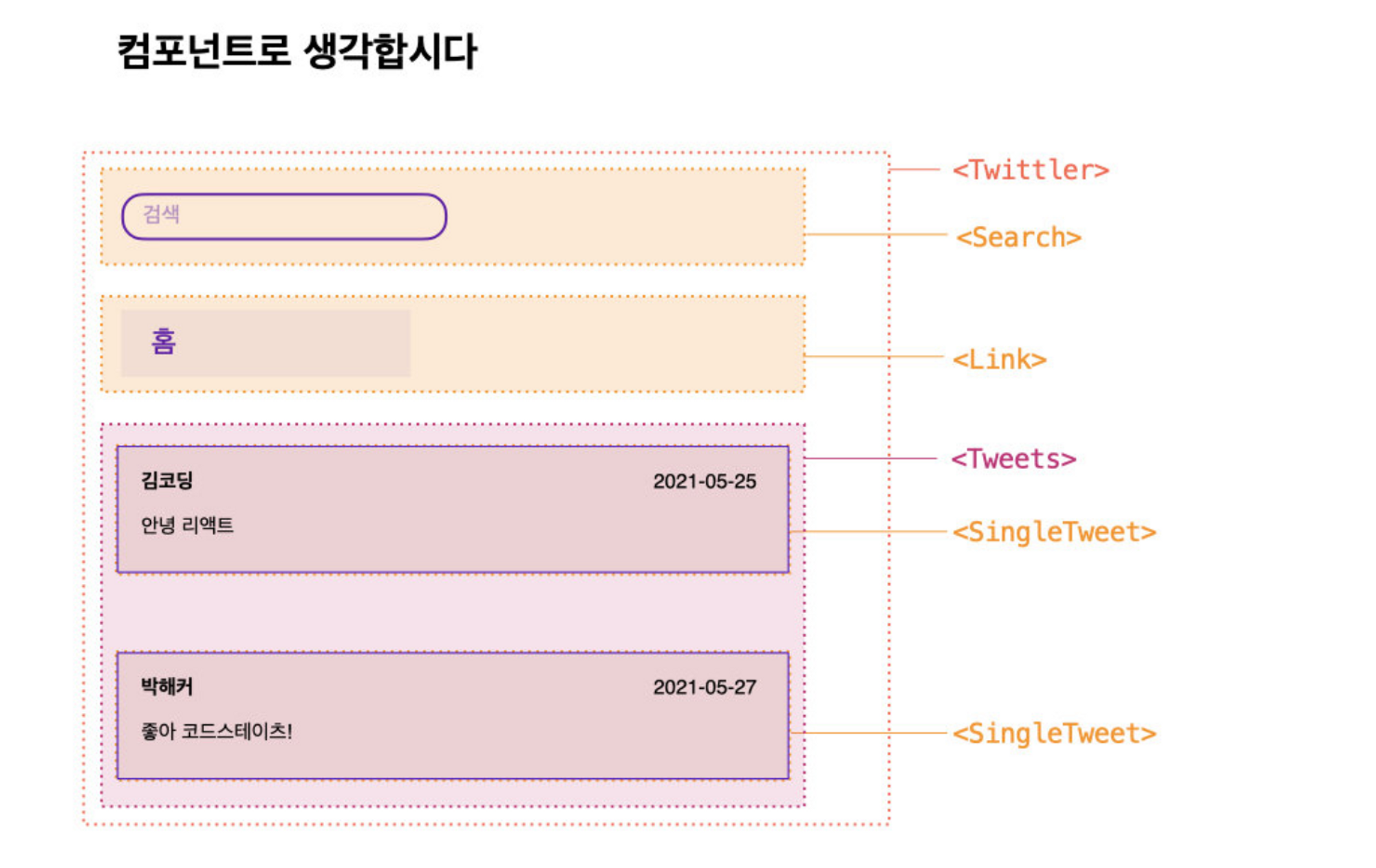
여기서 드는 의문...
왜 굳이 하나하나 컴포넌트로 나눠야 할까?
- 단일 책임 원칙에 따른 구분 때문이다!
하나의 컴포넌트는 하나의 일만 하기 때문에 각각의 컴포넌트로 나눠야 한다.
이를 트리 구조로 나타내면 다음 그림과 같다!
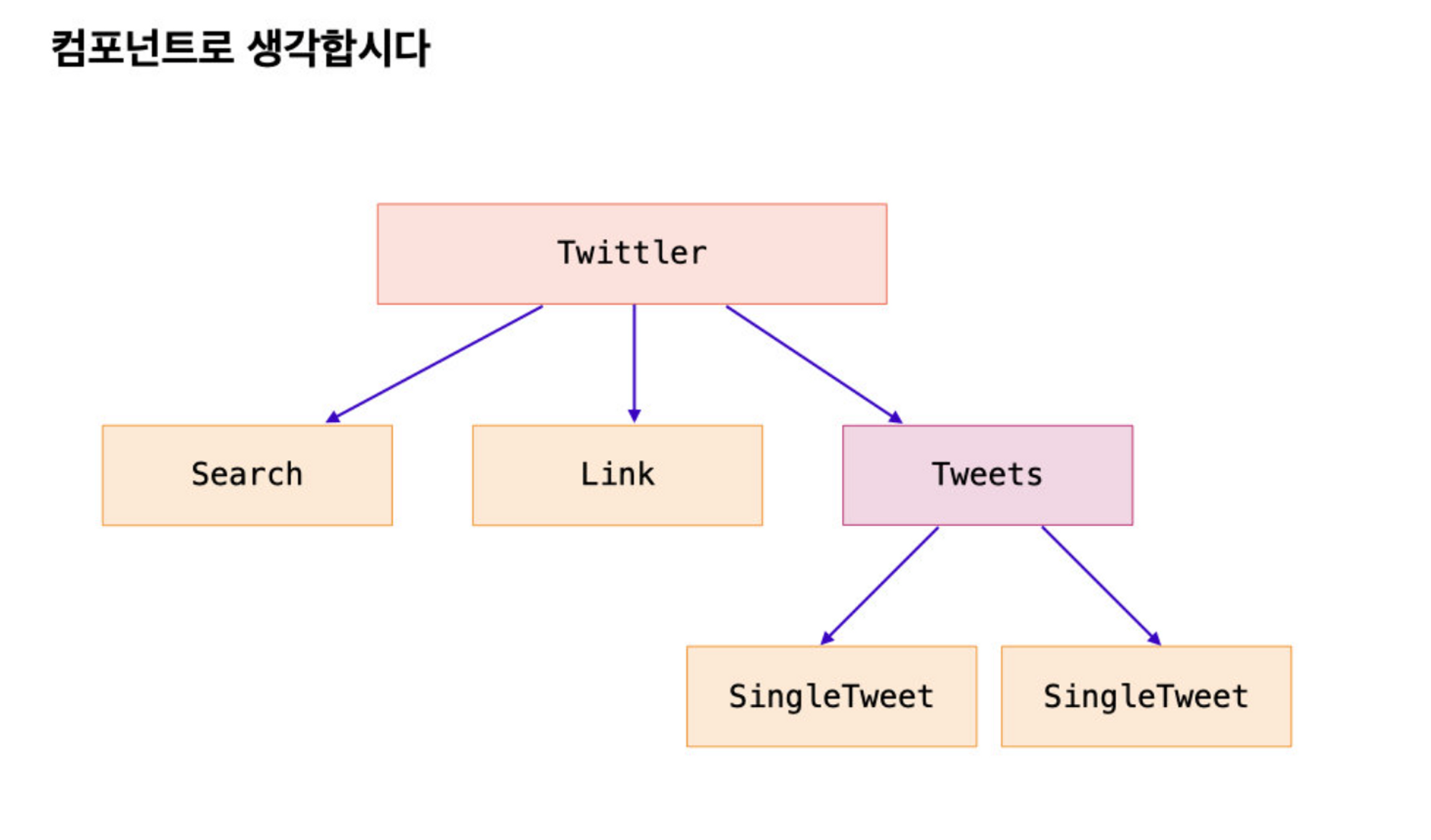
흠... 컴포넌트로 다 나누긴 했는데... 그 다음엔 어떻게 해야할까...?
이제는 데이터를 어디에 둘지 결정해야 한다!
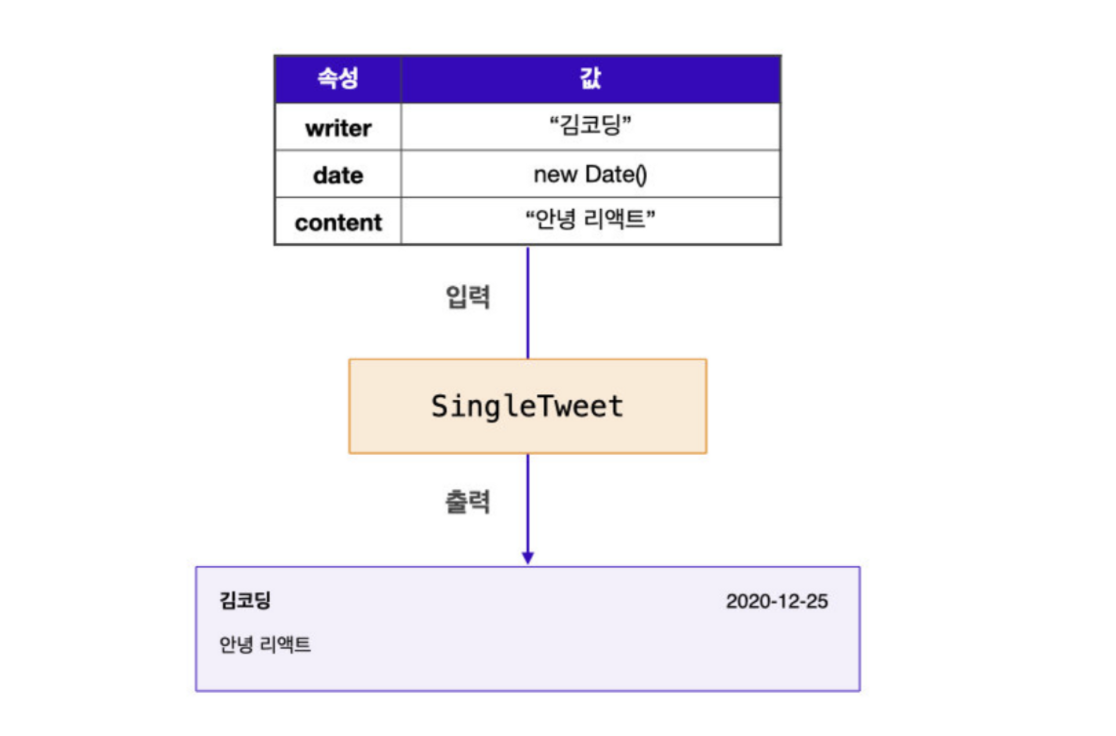
컴포넌트는 컴포넌트 바깥에서 props를 이용해 데이터를 마치 인자(arguments) 혹은 속성(attributes)처럼 전달받을 수 있다
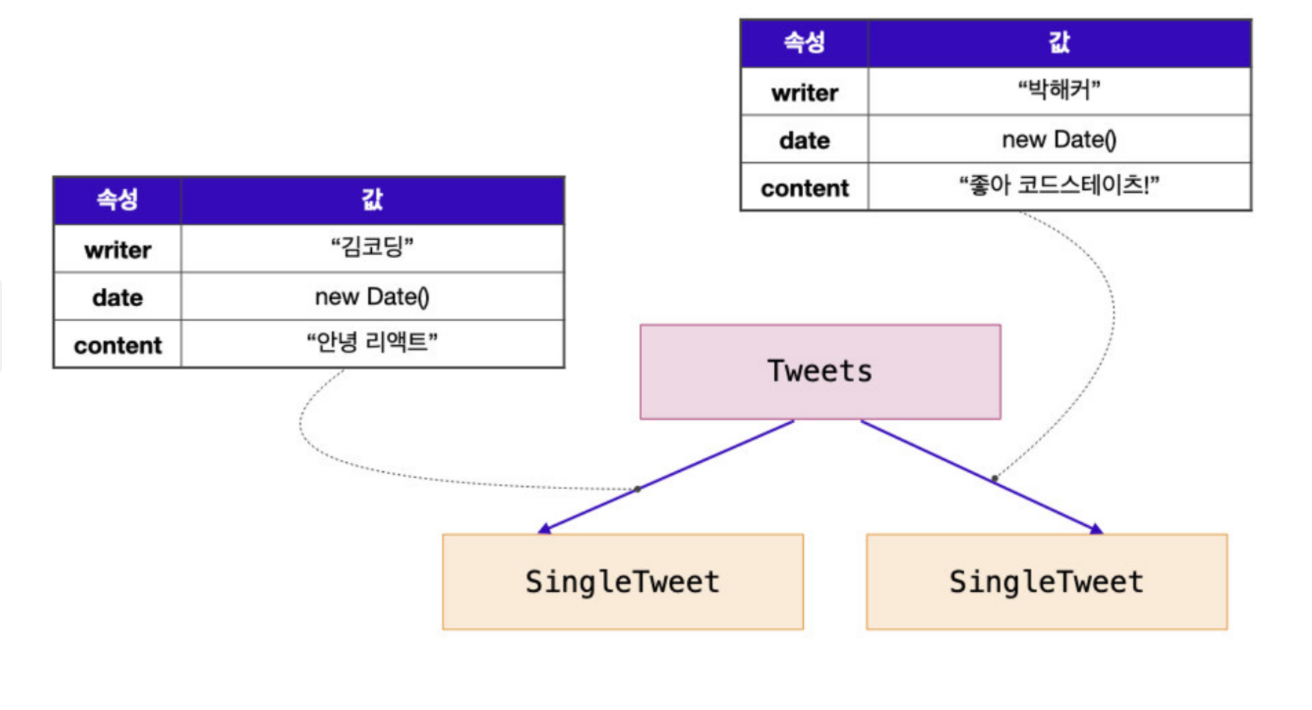
즉 위 그림에서 볼 수 있듯이 데이터를 전달하는 주체는 부모 컴포넌트가 된다.
이는 데이터 흐름이 하향식(top-down) 임을 의미한다!
이 원칙은 매우 중요하다!!
얼마나 중요하냐면, 단방향 데이터 흐름(one-way data flow)이라는 키워드가 React를 대표하는 설명 중 하나일 정도이다.
또한 컴포넌트는 props를 통해 전달받은 데이터가 어디서 왔는지 전혀 알지 못한다.
예를 하나 들어보자...

애플리케이션에서 필요한 데이터가 무엇인지 먼저 정의해보자. 다음과 같은 데이터를 생각해 볼 수 있다.
- 전체 트윗 목록
- 사용자가 작성 중인 새로운 트윗 내용
하지만, 모든 데이터를 상태로 둘 필요는 없다.
사실 상태는 최소화하는 것이 가장 좋다. 상태가 많아질수록 애플리케이션은 복잡해진다.
어떤 데이터를 상태로 두어야 하는지는 다음 세 가지 질문을 통해 판단해 보자!
- 부모로부터 props를 통해 전달됩니까? 그러면 확실히 state가 아닙니다.
- 시간이 지나도 변하지 않나요? 그러면 확실히 state가 아닙니다.
- 컴포넌트 안의 다른 state나 props를 가지고 계산 가능한가요? 그렇다면 state가 아닙니다.
그렇다면 상태는 어디에 위치시켜야할까?
상태가 특정 컴포넌트에서만 유의미하다면, 특정 컴포넌트에만 두면 되니까 크게 어렵지 않지만, 만일 하나의 상태를 기반으로 두 컴포넌트가 영향을 받는다면 이때에는 공통 소유 컴포넌트를 찾아 그곳에 상태를 위치해야 한다.
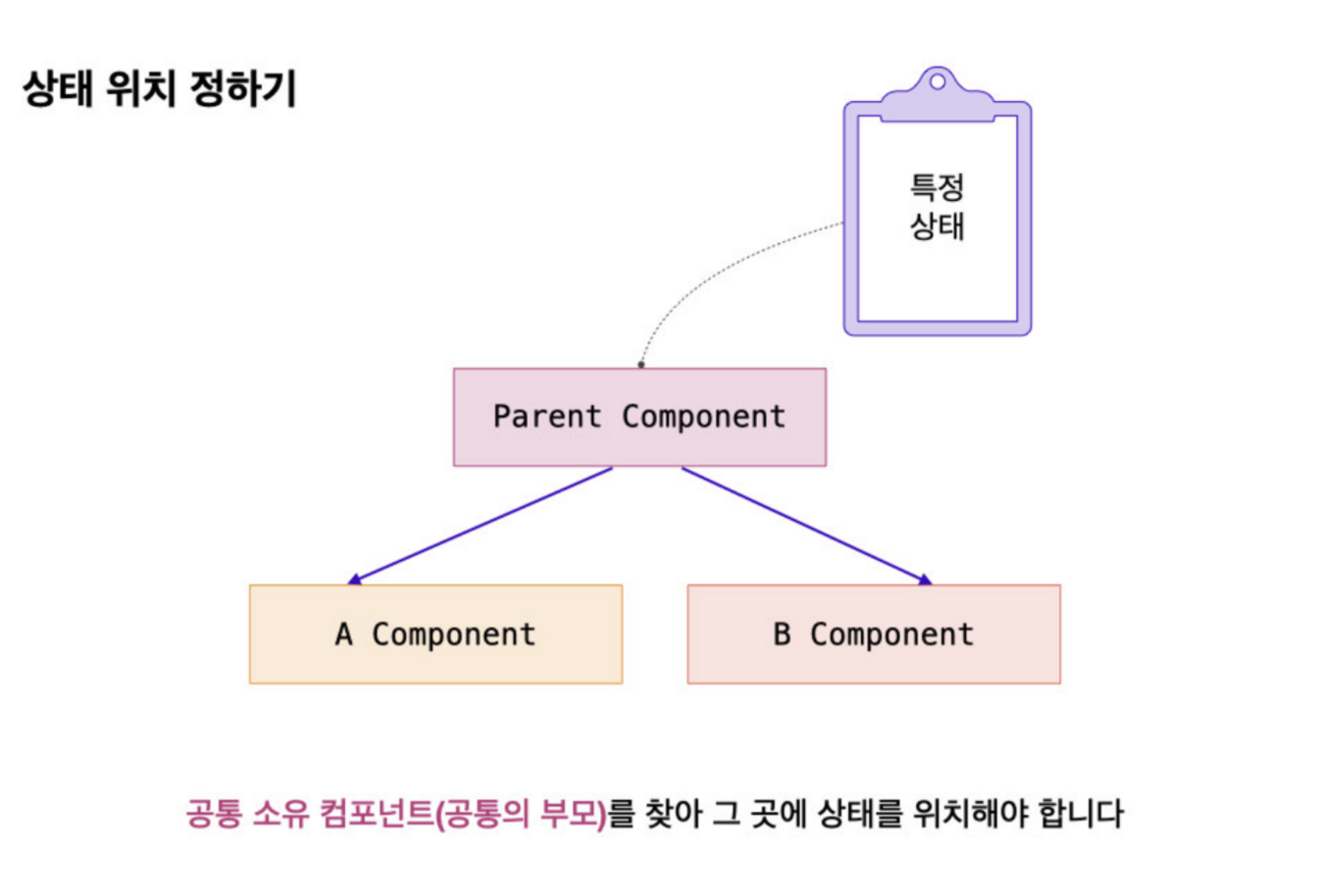
즉, 두 개의 자식 컴포넌트가 하나의 상태에 접근하고자 할 때는 두 자식의 공통 부모 컴포넌트에 상태를 위치해야한다.
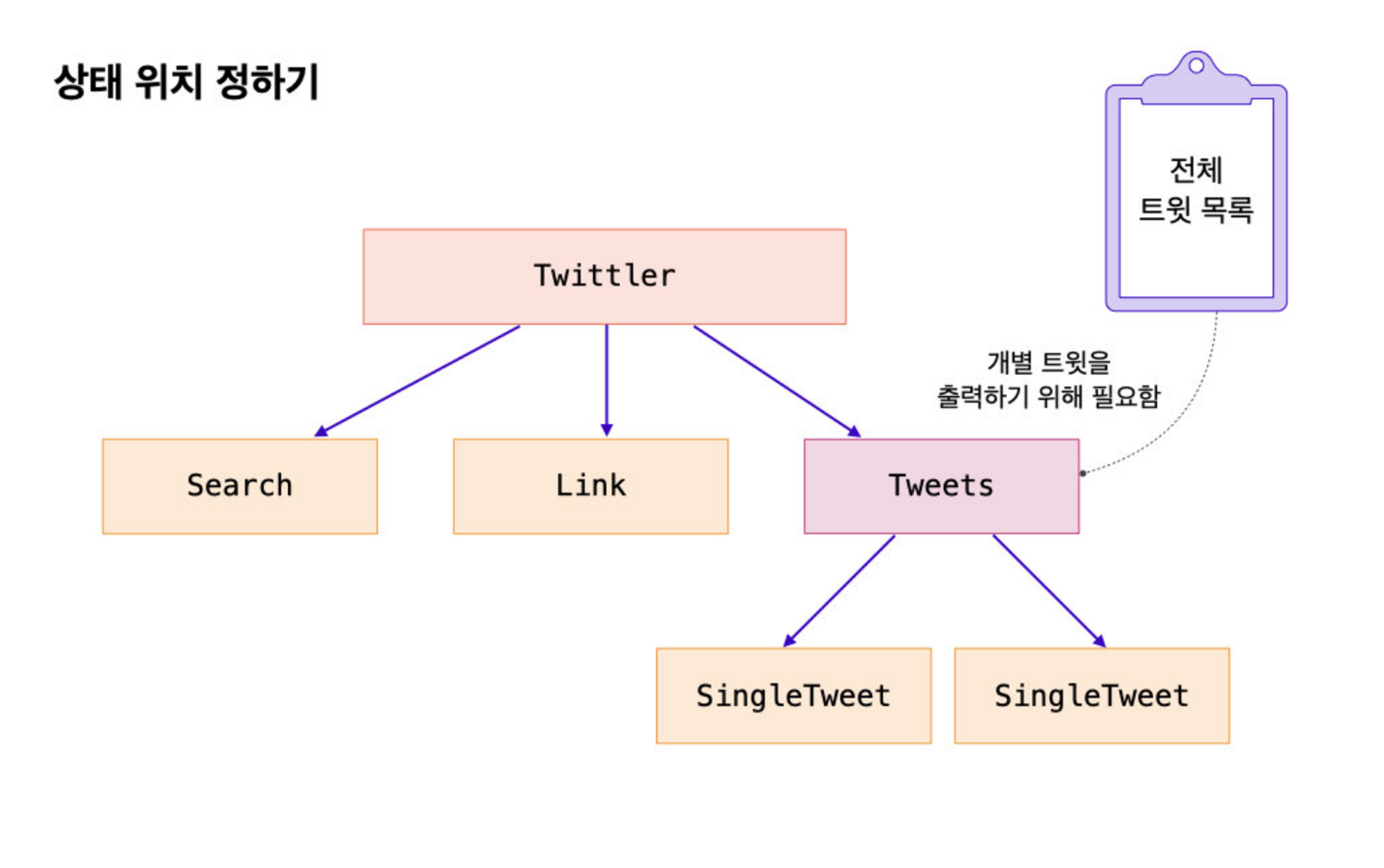
앞서 정의한 데이터를 기반으로 위치를 정해보자. "전체 트윗 목록" 상태는 어디에 위치하는 것이 좋을까?
- 전체 트윗 목록은 Tweets에서 필요로 하는 데이터이고, SingleTweet 컴포넌트들은 모두 전체 트윗 목록에 의존한다.
그렇다면 SingleTweet 컴포넌트들의 부모는 무엇인가?
- 바로 Tweets이다. 따라서 전체 트윗 목록 상태는 여기에 위치해야 한다.
이처럼 React에서 데이터를 다룰 때는 컴포넌트들 간의 상호 관계와 데이터의 역할, 데이터의 흐름을 고려하여 위치를 설정해야 한다.
