[Paper Review] Calibrated One-class Classification for Unsupervised Time Series Anomaly Detection
[Paper Review] Seminar
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다
01. Introduction
이상탐지는 데이터마이닝 및 분석의 주요한 분야 중 하나로, 데이터 내 대다수의 데이터와 크게 다른 형태를 띄는 데이터를 찾는 것이다.
real-world에서는 라벨링 작업의 비용 및 어려움 때문에 시계열 이상 탐지는 종종 라벨이 없는 훈련 데이터를 사용한 비지도 학습으로 구성이 됨
Challenges
비지도 학습의 한계와 문제점
1. 훈련 데이터 세트에 포함된 이상치의 존재: 비지도 학습에서 모든 훈련 데이터가 정상이라고 가정하는데, 이 가정은 항상 맞지 않으며 일부 이상치가 포함될 수 있음. 이상이 섞여 있는 데이터는 오염된 이상으로 인하여 학습 과정을 방해하여 과적합 문제를 초래할 수 있음.
2. 이상치에 대한 지식의 부재: 이상치에 대한 정보가 없기 때문에 정상 행동의 범위를 정확히 정의하기 어렵고, 이로 인해 부정확한 정상성 경계를 학습할 수 있음.
Prior Art
- 대부분의 기존 방법들은 생성 모델을 사용하여 입력 데이터를 복원하거나 미래 데이터를 예측하는 방식으로 정상성을 암묵적으로 학습함.
- 이러한 방법들은 더 깊은 지표 간 상관관계, 장기적인 시간 의존성 및 다양한 패턴을 포괄적으로 설명하기 위해 고급 네트워크 구조와 새로운 재구성/예측 학습 목표를 설계함.
- 그러나 이러한 방법들은 이상 오염 문제를 처리할 수 있는 구성 요소가 부족하여 학습 과정에서 이상 오염의 부정적 영향을 받음.
New Insights
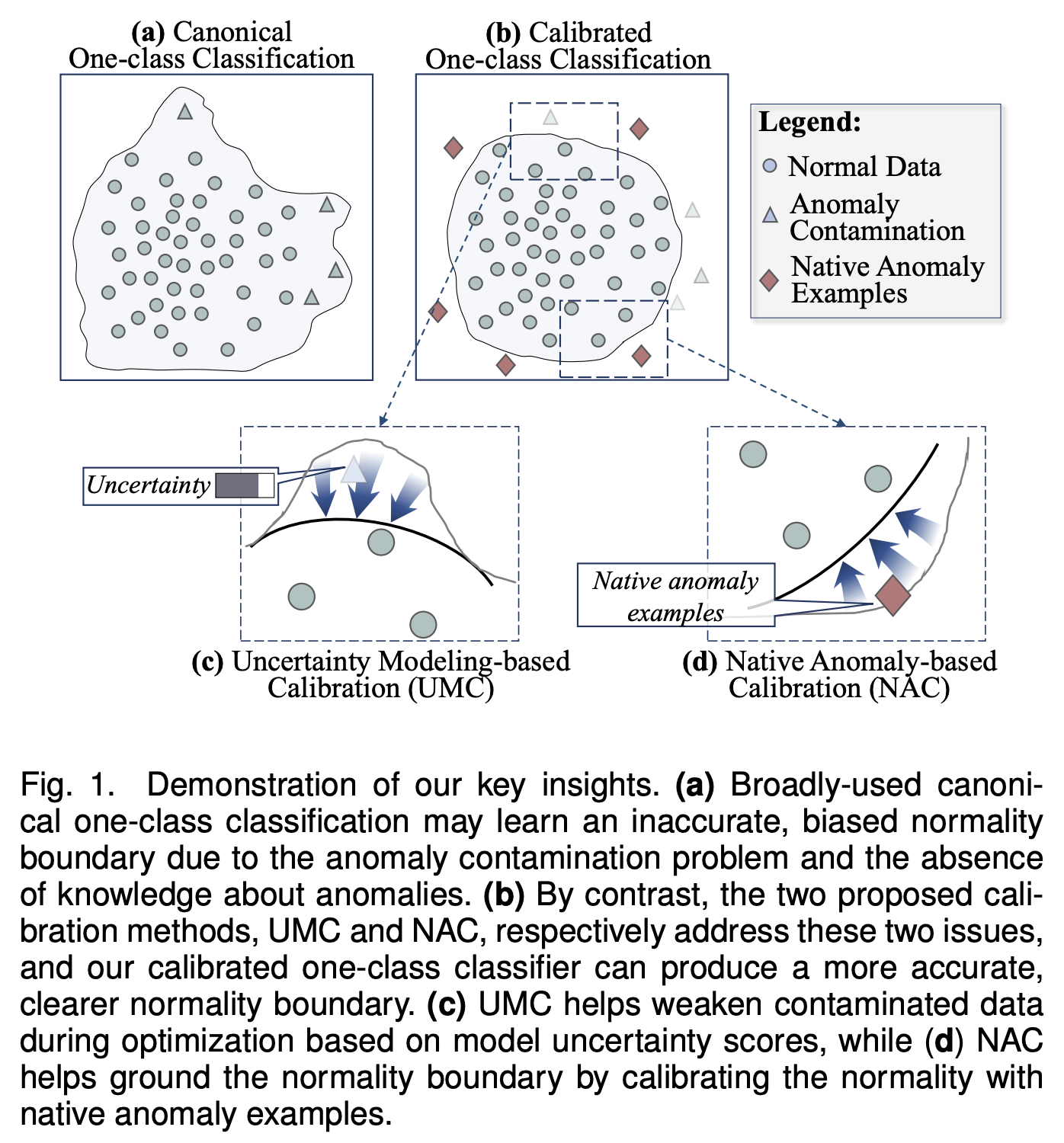
1. noisy samples의 부정적 영향 완화:
- 모델 불확실성을 활용하여 학습 과정에서 잡음 샘플의 기여를 제거
- 이상 데이터는 드물고 일관되지 않은 행동을 동반하기 때문에, 모델은 이러한 데이터에 대해 확신 없는 예측을 함
- 불확실성 개념을 내장한 새로운 학습 목표를 설계하여 불확실한 예측에는 패널티를 부과하고, 확신 있는 예측을 장려하여 학습 과정에서 해로운 이상을 구별함
2. 이상에 대한 지식 도입:
- 데이터 자체에서 감독 신호를 생성하는 self-supervised 학습에서 영감을 받음.
- 현재 self-supervised 이상 탐지 방법은 입력 데이터의 명확한 의미를 학습하는 데 중점을 두지만, 이상과 관련된 정보를 도입하지 않음
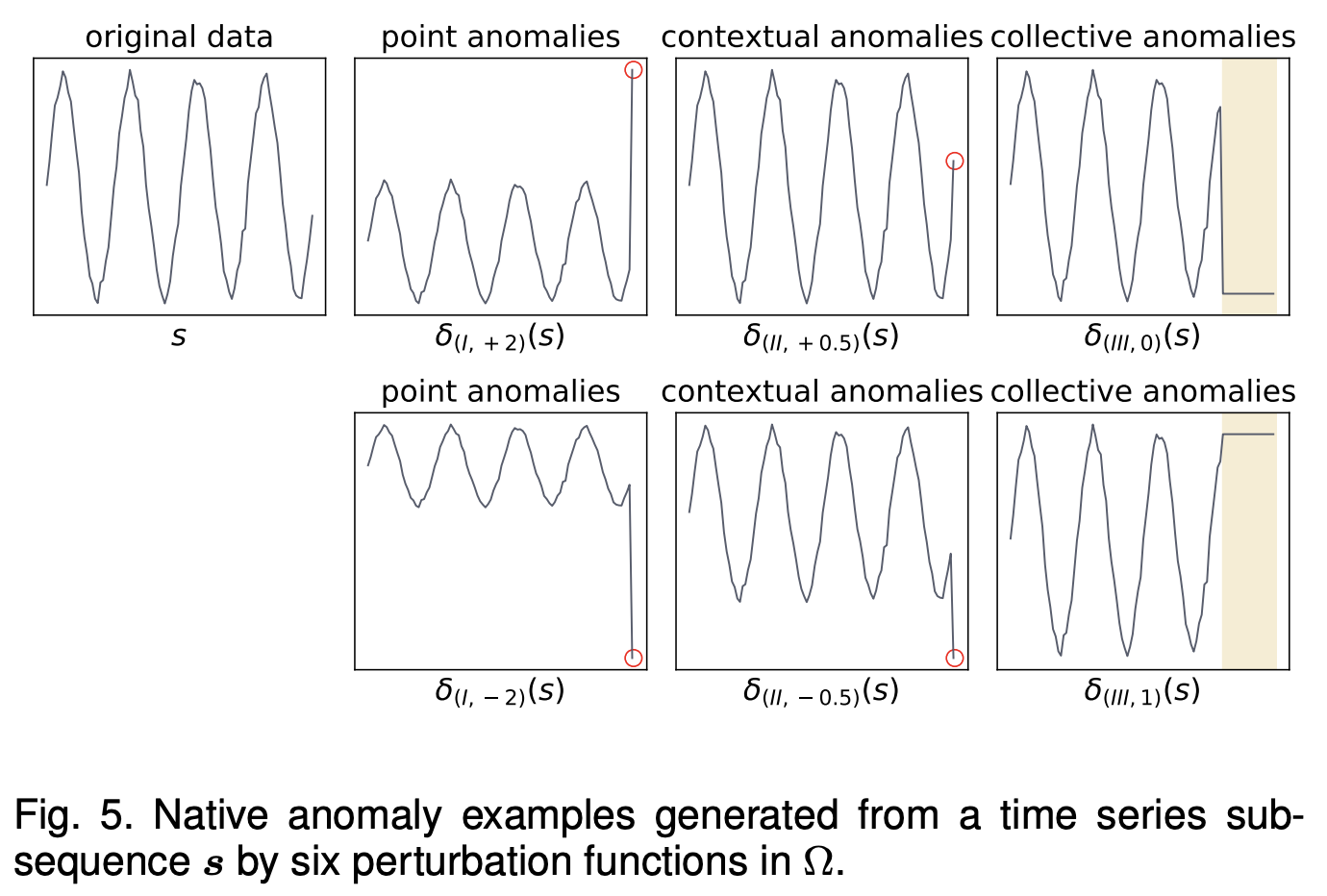
- 시간 시계열 이상이 point, contextual, collective 이상으로 정의되어 있으므로, 이러한 정의를 활용하여 맞춤형 데이터 변형 작업을 통해 비정상 행동을 시뮬레이션함
The Proposed Approach
새로운 비지도 시계열 이상 탐지 방법 Calibrated One-class classification-based Unsupervised Time series Anomaly detection(COUTA)을 제안
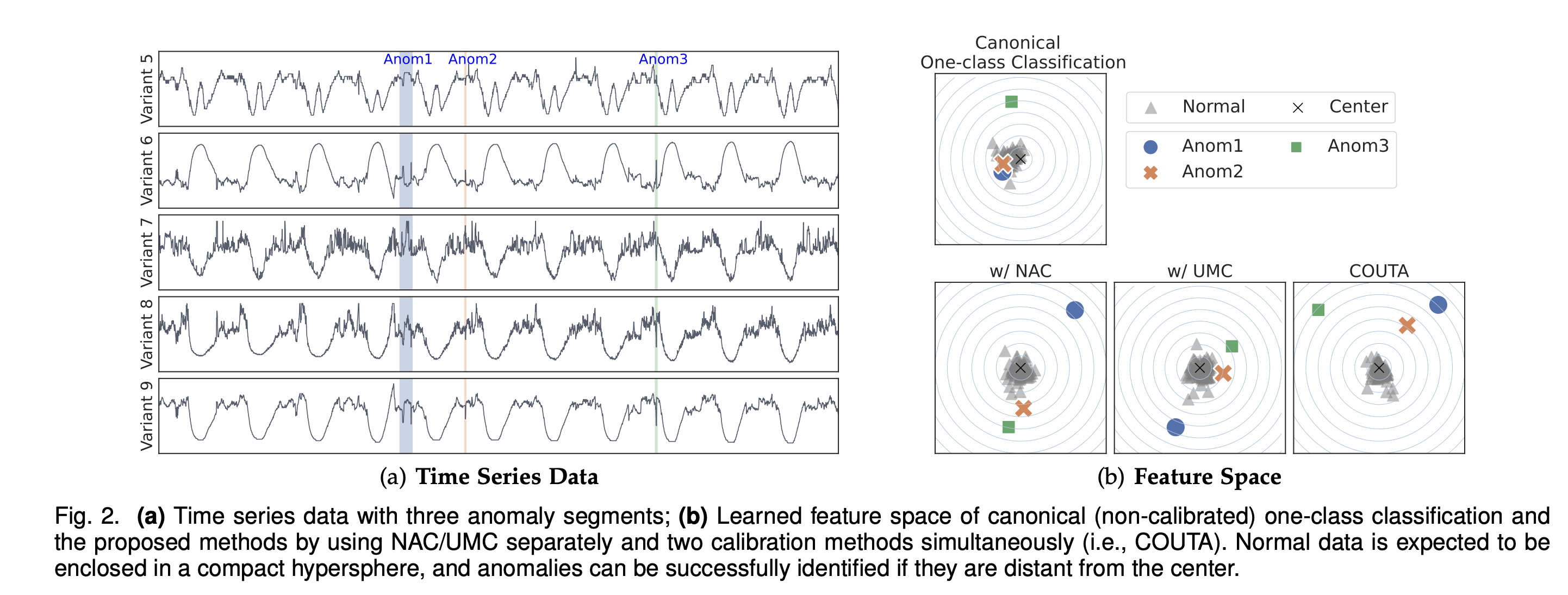
COUTA는 불확실성 모델링 기반 보정(UMC)과 원본 이상 기반 보정(NAC)을 포함합니다.
UMC (Uncertainty Modeling-based Calibration):
- 새로운 보정된 one-class 손실 함수를 사용하여 예측 불확실성을 포착함
- 불확실한 예측에는 패널티를 부과하고, 확신 있는 예측을 장려하여 모델을 보정함
NAC (Native Anomaly-based Calibration):
- 원본 시계열 하위 시퀀스를 기반으로 간단하지만 효과적인 데이터 변형 작업을 통해 이상 예제를 생성함
- 새로운 감독 학습 브랜치를 통해 학습된 정상성을 더욱 구별할 수 있도록 보정함
제안 모델 COUTA는 이상 오염에 강하고 초기 이상 행동을 구별할 수 있는 더 정확한 데이터 정상성 경계를 생성하며, 실제 데이터셋에 대한 실험을 통해 각 보정의 장점을 시연하고, 기존의 one-class classification 방법들보다 더 나은 성능을 보임
2 RELATED WORK
2.1 Anomaly Detection in Time Series
- 전통적인 방법들은 분해, 클러스터링, 거리, 패턴 마이닝 등의 기술을 사용하며, 이동 평균, 자기 회귀 모델들은 예측 값과 실제 값을 비교하여 이상을 탐지함
- 딥러닝 방법들은 생성적 one-class 학습 모델을 사용하여 입력 데이터를 복원하거나 미래 데이터를 예측하며, 다양한 고급 네트워크 구조와 새로운 학습 목표를 통해 성능을 향상시킴
- 그러나, 이상 오염과 이상에 대한 지식 부족 문제가 여전히 존재하며, 이를 해결하기 위한 기술들이 검토됨
2.2 Anomaly Contamination and Label-noise Learning
- 일부 연구는 셀프 트레이닝이나 추가적인 오토인코더를 사용하여 가능한 이상 샘플을 필터링하고, 모델 매개변수를 업데이트하는 동안 이진 라벨을 추론함
- 그러나 이러한 필터링 과정은 여전히 anomaly contamination problem로 인해 고통받으며, 네트워크 훈련에 중요한 어려운 정상 샘플을 잘못 필터링할 수 있음
2.3 Self-supervised Anomaly Detection
데이터 자체에서 감독 신호를 생성하는 셀프 슈퍼바이즈드 학습 방법을 설명
- 다양한 증강 작업을 통해 클래스 라벨을 할당함
- 그러나 이러한 작업들은 여전히 이상과 관련된 정보를 제공하지 못함
- 단순한 데이터 변형을 통해 비정상적인 행동을 신뢰성 있게 시뮬레이션할 수 있다는 점이 간과됨
2.4 Anomaly Exposure
추가적인 이상 정보를 제공하여 이상에 대한 지식 부족 문제를 해결하는 방법을 설명
- 보조 자연 데이터셋에서 데이터를 가져오는 대신, 원본 데이터에 데이터 변형을 수행하여 가상 이상 예제를 만드는 방법을 제안
- 이미지 이상 탐지와 관련된 다른 연구들과 차별화됨
3 THE PROPOSED METHOD: COUTA
3.1 Problem Formulation
시계열 데이터셋의 이상 탐지 문제를 정의
- 시계열 데이터셋은 D 차원 벡터로 설명되는 관측치의 순서가 있는 시퀀스로 정의되며, 다변량 또는 단변량 시계열로 분류됨
- 비지도 시계열 이상 탐지는 라벨 정보 없이 각 관측치의 이상 정도를 측정하고 이상 점수를 부여하는 과정(점수가 높을 수록 이상으로 분류됨)
- 시간 의존성을 모델링하기 위해 슬라이딩 윈도우를 사용하여 훈련 세트를 하위 시퀀스로 변환하며, 추론 단계에서는 동일한 방법으로 테스트 세트를 처리함
- 각 하위 시퀀스의 이상 정도를 평가하여 최종 이상 점수 목록을 생성함
3.2 Overall Framework
제안 방법인 COUTA의 프레임워크
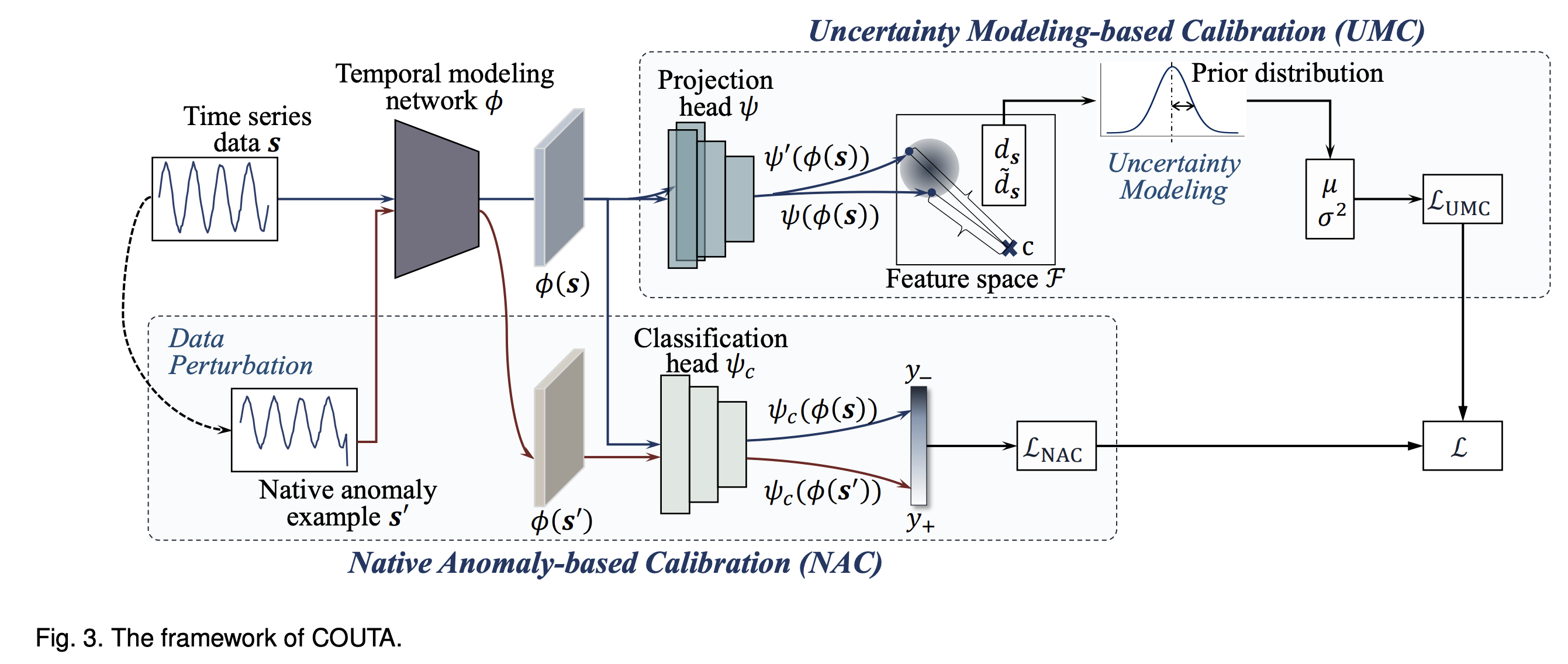
- Temporal Convolutional Network(TCN)를 사용하여 시간축 의존성과 변수 간 상호작용을 모델링하며, 다층 퍼셉트론 구조를 통해 데이터를 고차원 특징 공간으로 매핑함
- 불확실성 모델링 기반 보정(UMC)과 원본 이상 기반 보정(NAC)을 도입하여 학습 과정에서의 이상 오염 문제를 해결하고, 시계열 데이터의 이상 행동을 분류함
- 최종 손실 함수는 두 가지 보정 손실 함수를 결합하여 계산되며, 신경망 내 학습 가능한 매개변수는 이 손실 함수에 의해 공동으로 훈련됩됨
- 추론 단계에서는 테스트 세트를 하위 시퀀스로 전처리하여 이상 정도를 측정함
3.3 Calibrated One-class Classification
3.3.1 UMC for Contamination-tolerant One-class Learning
목표: 훈련 데이터 내의 이상 오염 문제를 해결하여, 신뢰할 수 없는 예측을 완화하고 정확한 예측을 촉진
- 최소 반경의 초구체를 학습하여 데이터를 포함하도록 하고, 초구체 중심까지의 거리를 사용하여 데이터의 이상 정도를 측정
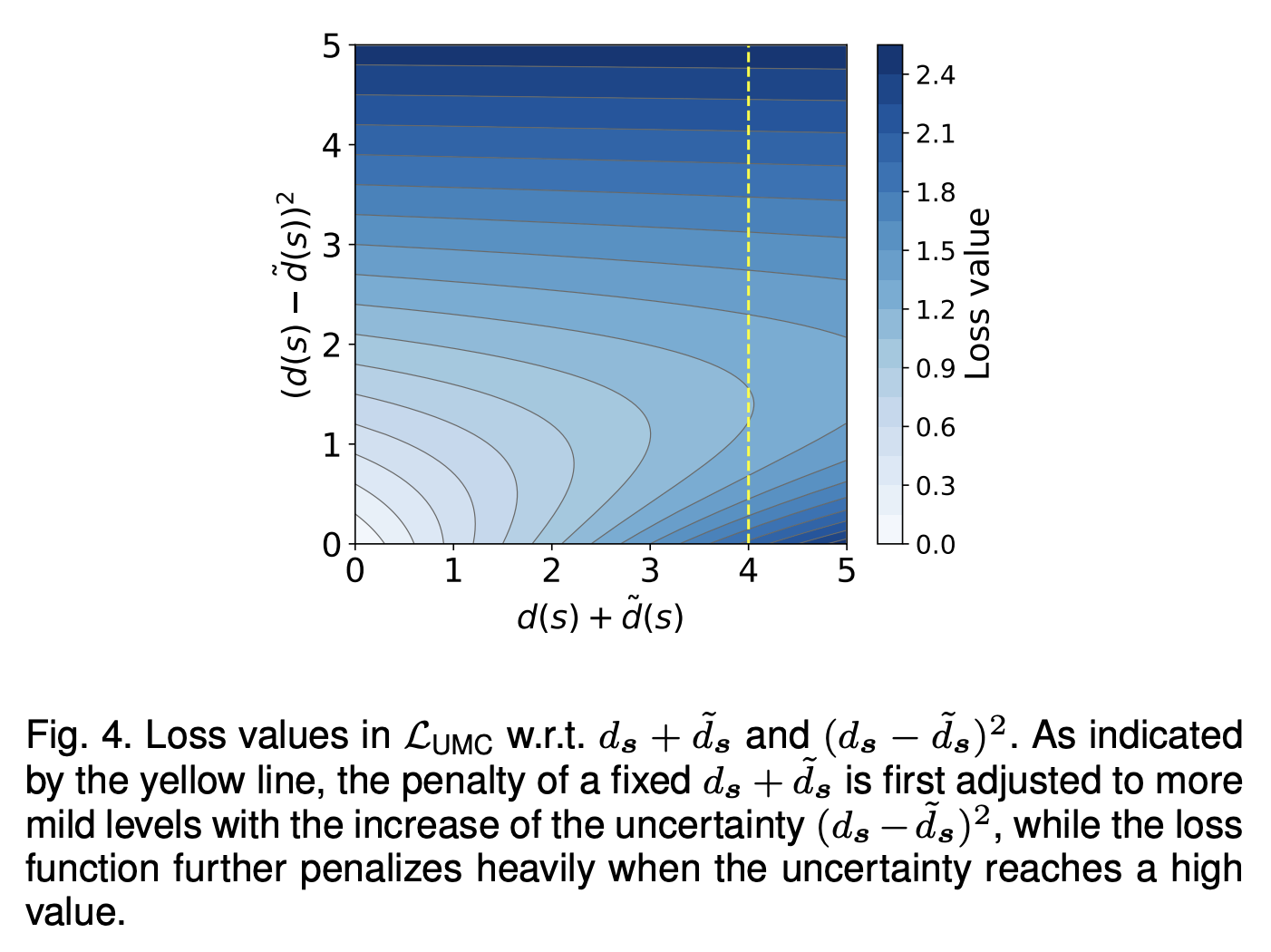
- 단일 거리 값에 사전 확률 분포(가우시안 분포)를 부과하고, 모델 불확실성을 나타내는 분산을 사용하여 새로운 손실 함수를 설계
- 불확실성이 높은 예측에는 온건한 패널티를 부과하고, 확신 있는 예측을 장려하여 어려운 정상 샘플의 최적화를 보장
결과: 새로운 손실 함수는 이상 오염을 마스킹하고, 높은 불확실성을 가진 데이터 샘플의 손실 값을 적응적으로 조정하여 더 신뢰할 수 있는 예측을 생성
3.3.2 NAC for Anomaly-informed One-class Learning
목표: 시계열 데이터의 이상에 대한 지식을 도입하여 더 정확한 정상성 경계와 이상 탐지 성능을 개선
- 원본 시계열 데이터를 기반으로 맞춤형 데이터 변형 작업을 통해 가상 이상 예제를 생성
- 새로운 감독 학습 브랜치와 분류 헤드를 추가하여, 이러한 가상 이상 예제를 통해 one-class 분류기를 보정
- 평균 제곱 오차를 사용하여 원본 데이터와 이상 예제의 출력을 각각 회귀시키고, 새로운 손실 함수를 정의
결과: NAC는 self-supervised 학습 과정으로서 one-class 학습을 강화하며, 데이터 정상성의 더 정확한 추상화와 명확한 경계를 형성하여 이상 탐지 성능을 향상시킴
3.4 Anomaly Scoring
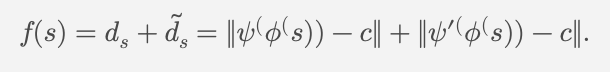
3.5 Discussion
Discriminative vs. Generative
- COUTA는 재구성 또는 예측 기반 생성 모델을 사용하는 대신 판별 방식(Discriminative)으로 동작
- 인코더-디코더 구조의 오토인코더와 달리, COUTA는 인코딩된 특징을 원래 형태로 복원할 필요가 없어 시간 효율적
- COUTA는 압축된 초구체를 학습하여 데이터 정상성을 명시적으로 모델링하여 이상 탐지와 직접적으로 관련된 최적화를 가능하게 함
The Choice of Hypersphere Center
- Hypersphere Center c 를 최적화 변수로 포함하면 매개변수가 0으로 설정되어 학습이 제대로 이루어지지 않고, 모델이 데이터를 제대로 표현하거나 구별하지 못하는 결과 초래이어질 수 있음
- 이를 피하기 위해 초기화된 네트워크를 사용하여 평균 표현으로 설정함
- 이는 최적화 과정이 빠르게 수렴하고 “Hypersphere Center 붕괴” 문제를 피하는 경험적으로 좋은 전략
Anomaly Types in Native Anomaly Generation
- 여섯 가지 변형 함수를 정의하여 사전 지식을 학습 과정에 통합
- 특정 현실 세계 응용 프로그램은 자체적인 이상 정의를 가질 수 있음
- 예를 들어, 데이터 센터의 IT 운영은 집합적 이상에 중점을 두고 점 이상을 생략할 수 있음
- 이 변형 방법은 일반적인 이상 정의를 기반으로 설계되었으며, 생성된 가상 이상이 대상 시스템에서 정상인 경우 부정적인 영향을 미칠 수 있음
- 그러나 대부분의 현실 세계 데이터셋에서 효과적임이 입증
Anomaly Scoring Strategy
- 이상 점수 함수는 분류 헤드 에 의해 보고된 예측 결과를 사용하지 않음
- 대신, 이상에 대한 지식을 제공하여 시간 모델링 네트워크 의 최적화를 도움
- 모든 훈련 데이터를 정상 클래스로 간주하여 학습 작업이 이상 오염 문제로 인해 잘못될 수 있음
- 이러한 가상 이상 예제는 항상 신뢰할 수 없을 수 있으며, 단순히 이 분기의 출력을 추가하면 탐지 성능이 저하될 수 있음
- UMC와 NAC에 의해 보정된 one-class 학습 결과를 활용하여, 초구체 중심까지의 거리로 데이터 이상성을 측정
4 EXPERIMENTS
- Effectiveness: COUTA와 현재 최신 방법들이 실제 데이터셋에서 얼마나 정확한 이상 탐지 결과를 산출하는가?
- Generalization ability: COUTA가 다양한 시계열 이상 유형에 일반화될 수 있는가?
- Robustness: 훈련 세트의 다양한 이상 오염 수준에 대한 COUTA의 견고성은 어떠한가?
- Scalability: COUTA가 기존 방법에 비해 시간 효율성이 높은가?
- Sensitivity: COUTA의 하이퍼 파라미터가 탐지 성능에 어떤 영향을 미치는가?
- Ablation study: 제안된 보정 방법들이 탐지 성능을 충분히 향상시키는가?
4.1 Experimental Setup
4.1.1 Datasets and Preprocessing Methods
사용된 데이터셋:
다변량 데이터셋:
• ASD (Application Server Dataset): IT 운영 데이터, 클러스터 내 서버 상태 및 리소스 활용도.
• SMD (Server Machine Dataset): IT 운영 데이터, 클러스터 내 서버 상태 및 리소스 활용도.
• SWaT (Secure Water Treatment): 산업 데이터, 다양한 센서 및 액추에이터.
• WaQ (Water Quality): 화학 및 물리적 메트릭스를 기반으로 물의 불쾌한 변화를 식별.
• Epilepsy: 모션 센서 데이터, 세 가지 활동(걷기, 달리기, 톱질)에서 발생하는 간질 발작 탐지.
• DSADS (Daily and Sports Activities Dataset): 모션 센서 데이터, 격렬한 활동이 정의된 이상 데이터.단변량 데이터셋:
• UCR-Fault: 바이오메카닉스 연구실 데이터, 발 센서의 결함.
• UCR-Gait: 바이오메카닉스 연구실 데이터, 헌팅턴병을 앓고 있는 개인의 보행.
• UCR-ECG-s: 심전도 데이터, 심실 상부 비트 포함.
• UCR-ECG-v: 심전도 데이터, 심실 비트 포함.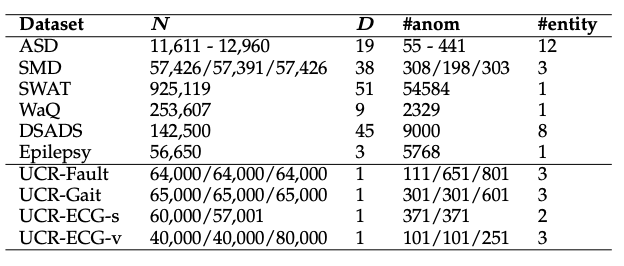
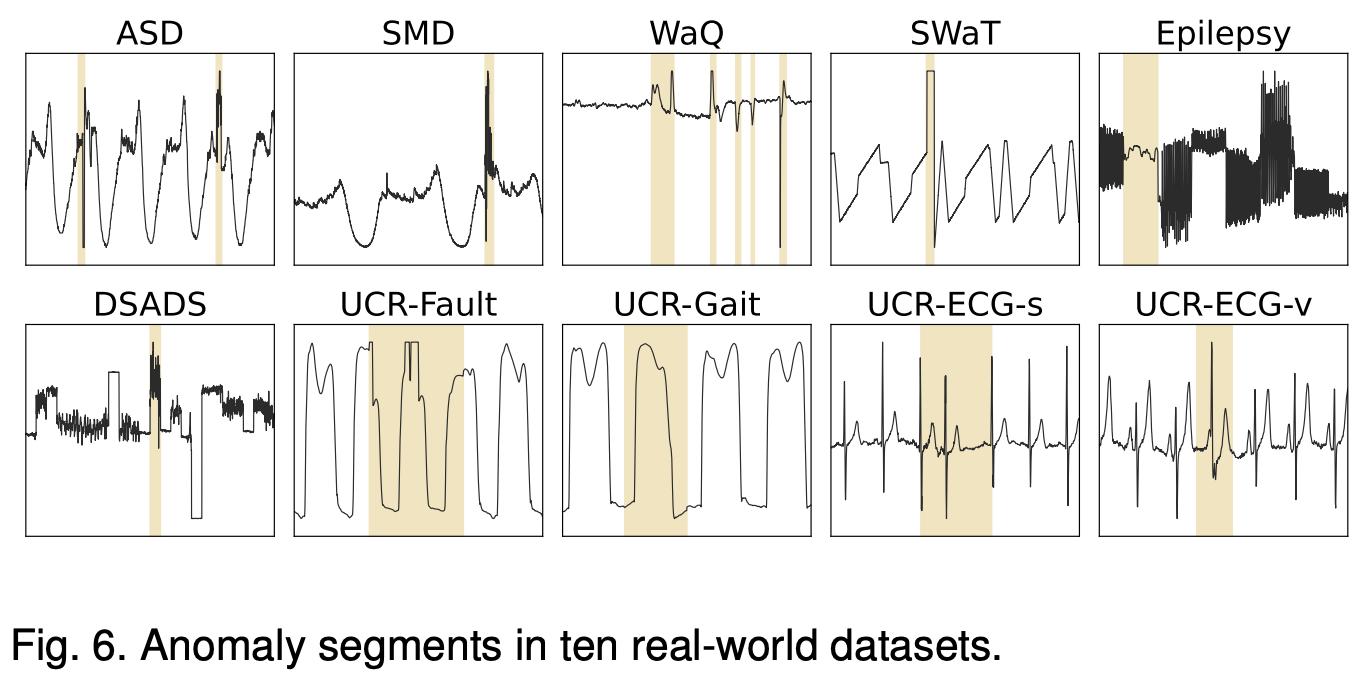
위 그림에 있는 10가지의 데이터셋을 활용
4.1.2 Competing Methods
COUTA는 16개의 이상 탐지 방법들(ARMA, OCSVM, GOAD, ECOD, DAGMM, LSTM-ED, LSTM-Pr, Tcn-ED, DSVDD, MSCRED, Omni, USAD, TranAD, AnomTran, 등.)과 비교
4.2 Effectiveness
COUTA의 이상 탐지 정확도를 평가하기 위해 다양한 데이터셋에서 실험을 수행
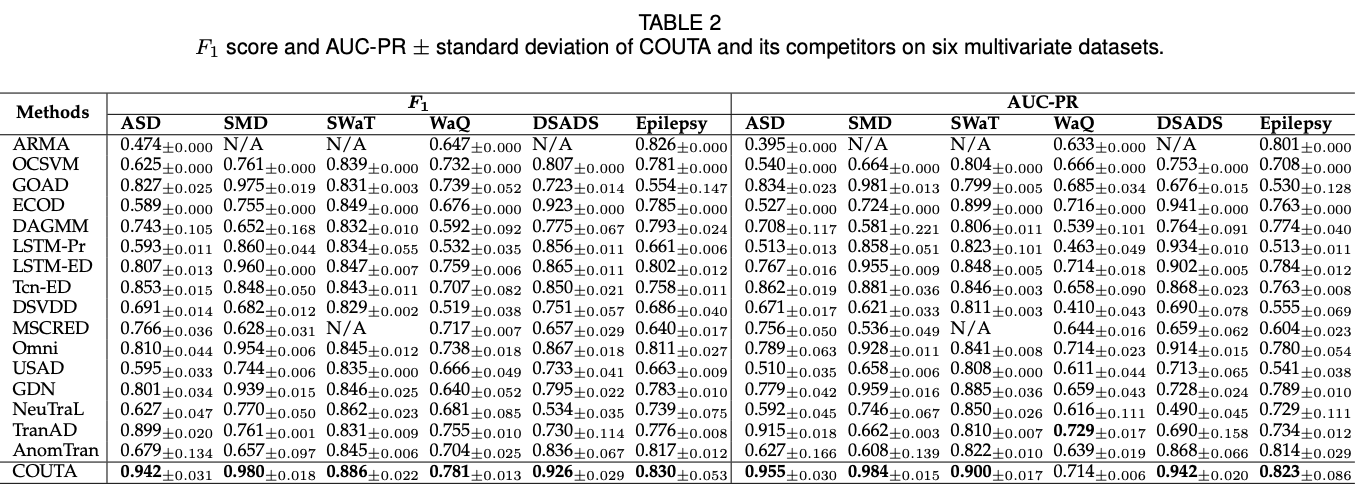
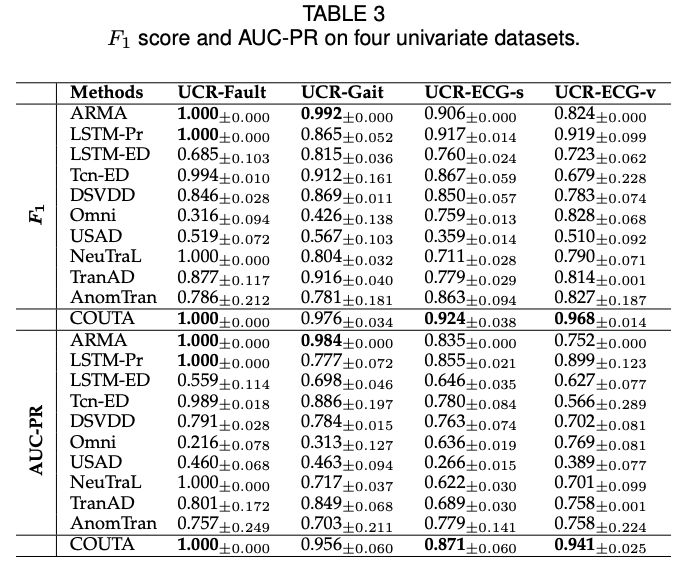
- Table 2와 3은 다변량 및 단변량 데이터셋에서 COUTA와 다른 최신 방법들의 F1 점수와 AUC-PR을 보여줌
- 결과적으로, COUTA는 대부분의 데이터셋에서 다른 방법들보다 높은 F1 점수와 AUC-PR을 기록
4.3 Generalization Ability to Different Types of Time Series Anomalies
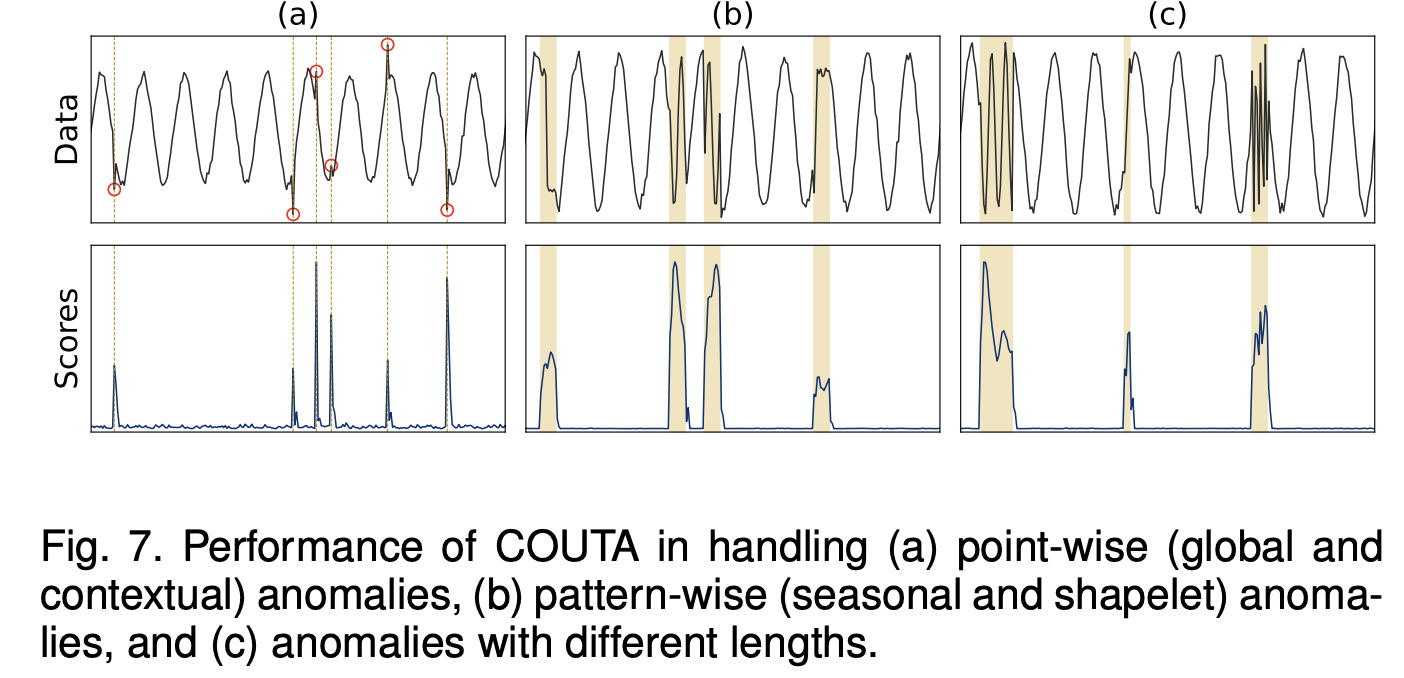
- Table 2와 3은 다변량 및 단변량 데이터셋에서 COUTA와 다른 최신 방법들의 F1 점수와 AUC-PR을 보여줌
- COUTA가 다양한 시계열 이상 유형에 대해 잘 일반화되는지 평가
- 세 가지 합성 데이터셋을 생성하여 각각 1000개의 관측치를 포함하고 두 차원으로 설명
- COUTA는 다양한 유형의 이상에 대해 높은 정확도로 이상을 탐지하는 것으로 나타남
4.4 Robustness w.r.t. Anomaly Contamination
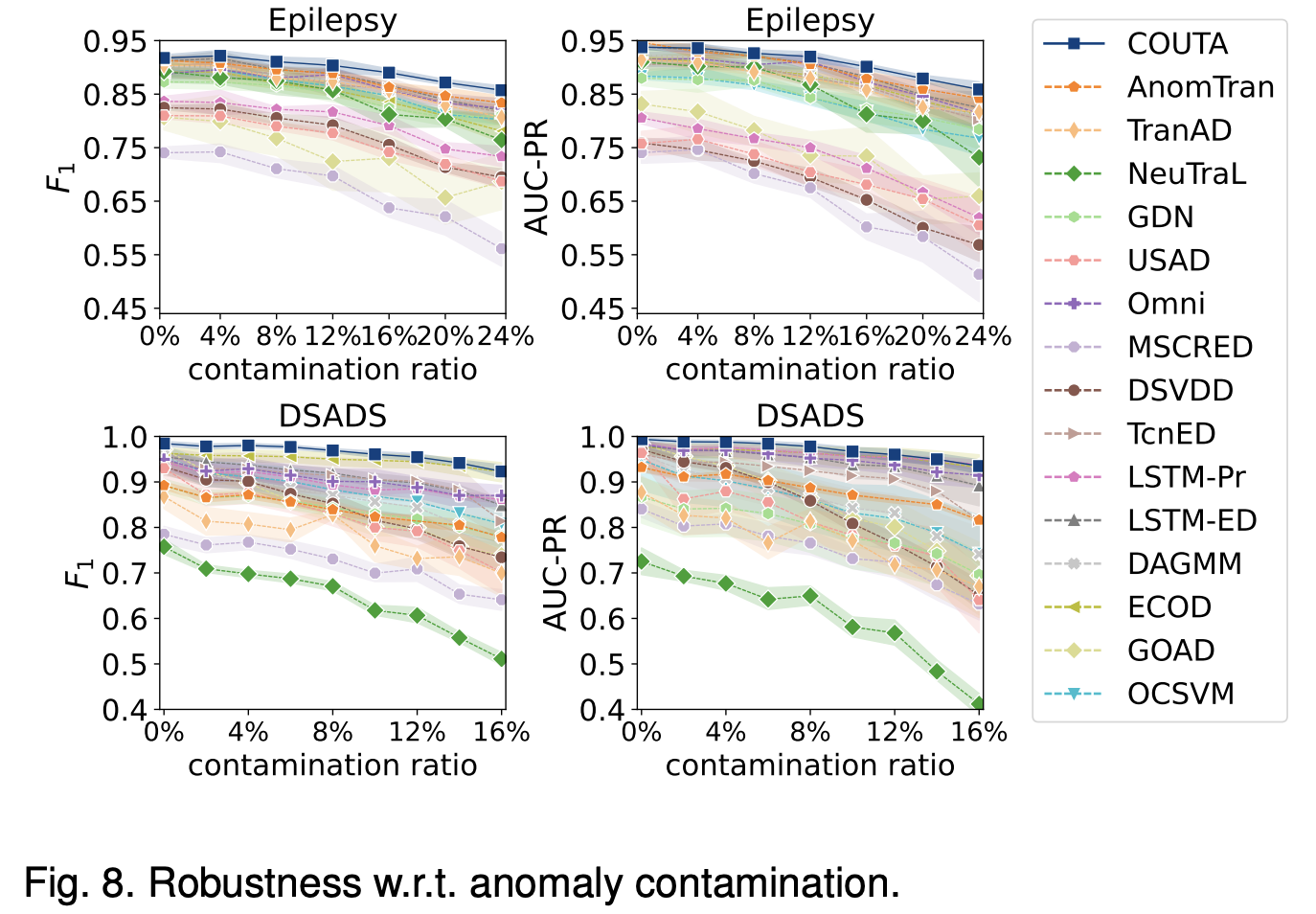
- Fig. 8은 COUTA와 다른 방법들이 다양한 이상 오염 비율에서 어떻게 성능이 변하는지 보여줌
- Table 2와 3은 다변량 및 단변량 데이터셋에서 COUTA와 다른 최신 방법들의 F1 점수와 AUC-PR을 보여줌
- COUTA는 높은 오염 비율에서도 다른 방법들보다 더 나은 견고성을 보임
4.5 Scalability Test
- COUTA의 확장성을 평가
- 다양한 길이와 차원을 가진 시계열 데이터셋에서 시간 효율성을 측정
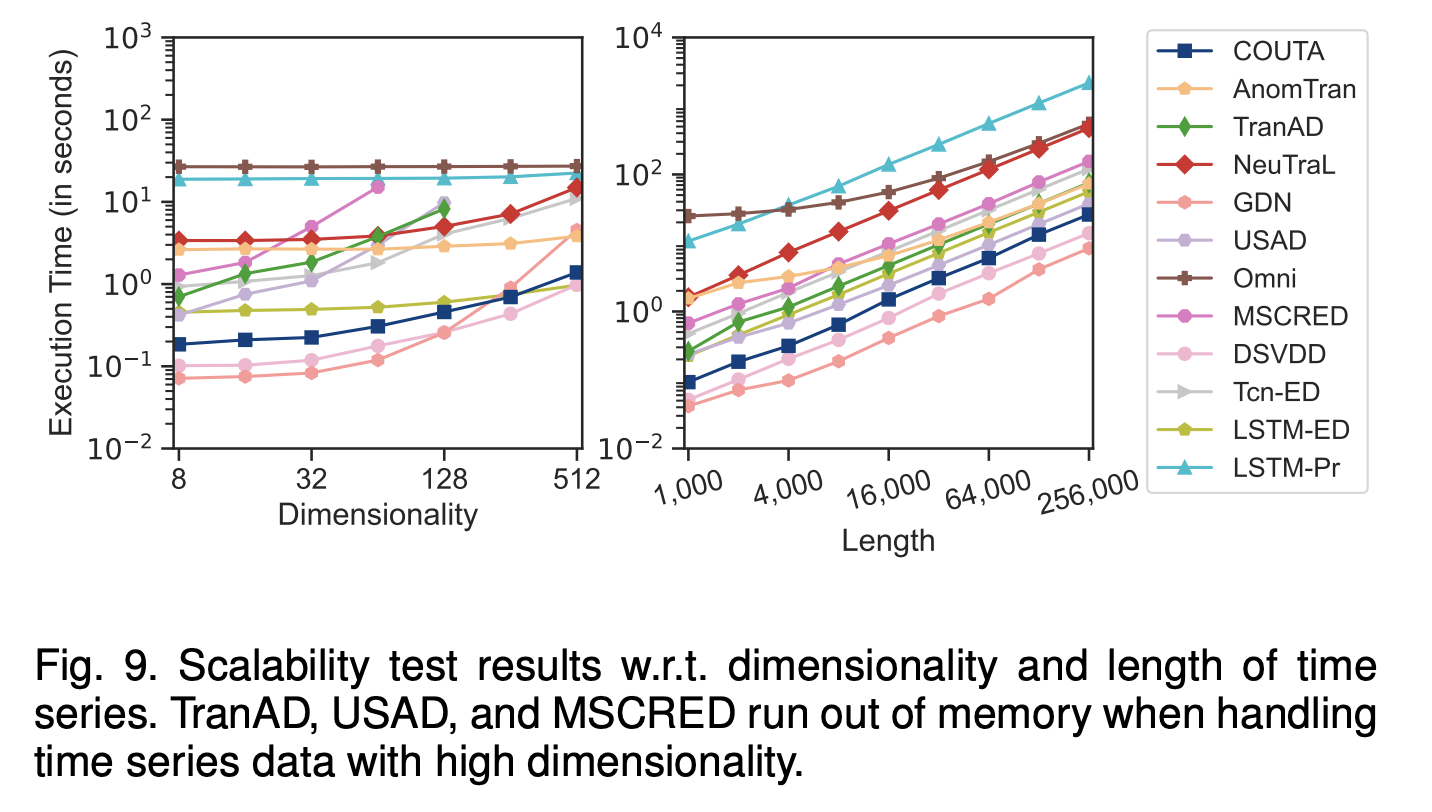
- Fig. 9는 COUTA와 다른 최신 방법들이 다양한 크기의 시계열 데이터셋에서 얼마나 효율적으로 동작하는지 보여줌
- COUTA는 대부분의 방법들보다 좋은 확장성을 보임
4.6 Sensitivity Test
- COUTA의 하이퍼 파라미터가 탐지 성능에 미치는 영향을 평가
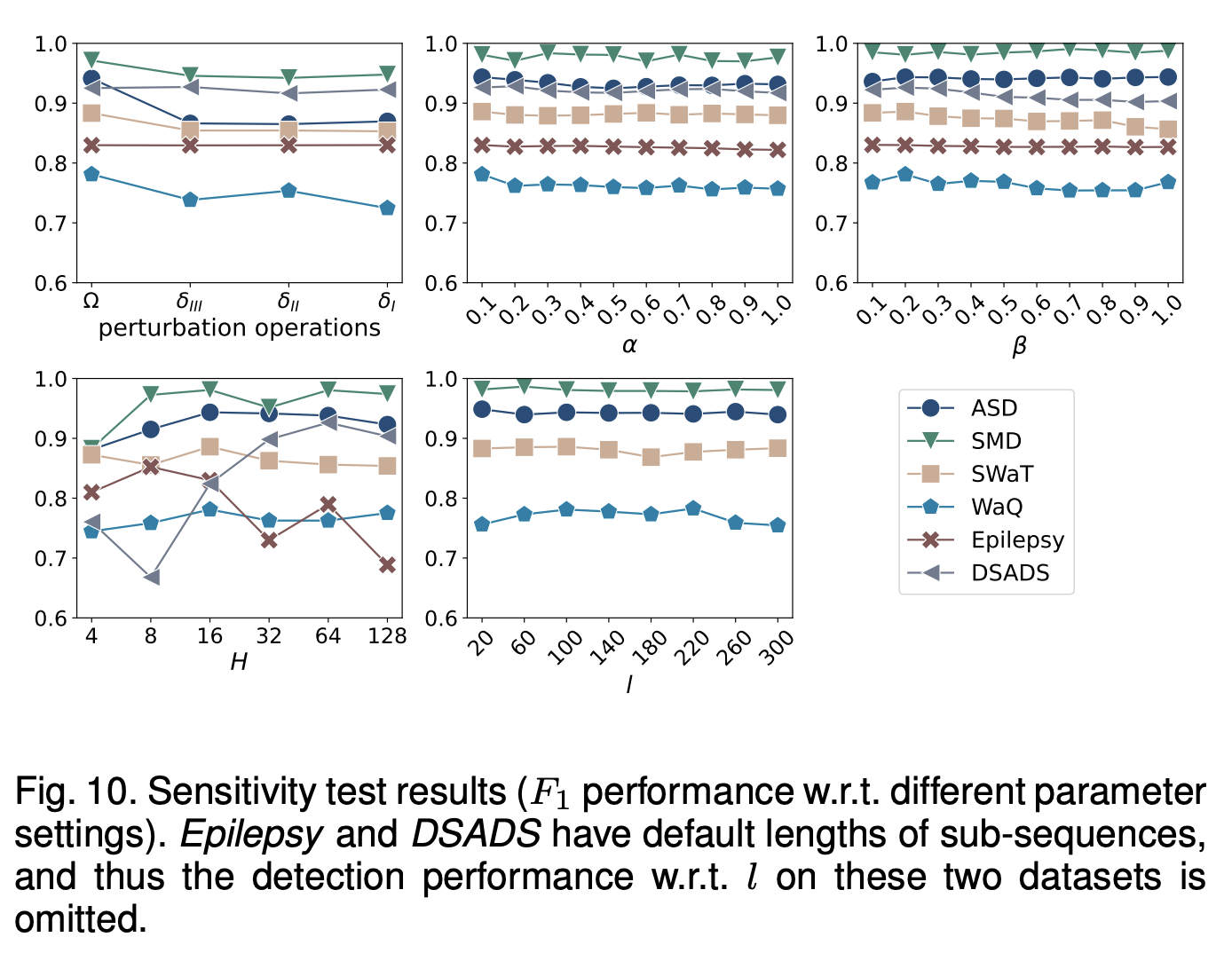
- Fig. 10은 다양한 파라미터 설정에서 COUTA의 F1 성능을 보여줌
- COUTA는 다양한 하이퍼 파라미터 설정에서도 안정적인 성능을 유지함
4.7 Ablation Study
-
UMC와 NAC 보정 방법들이 COUTA의 성능에 미치는 영향을 평가
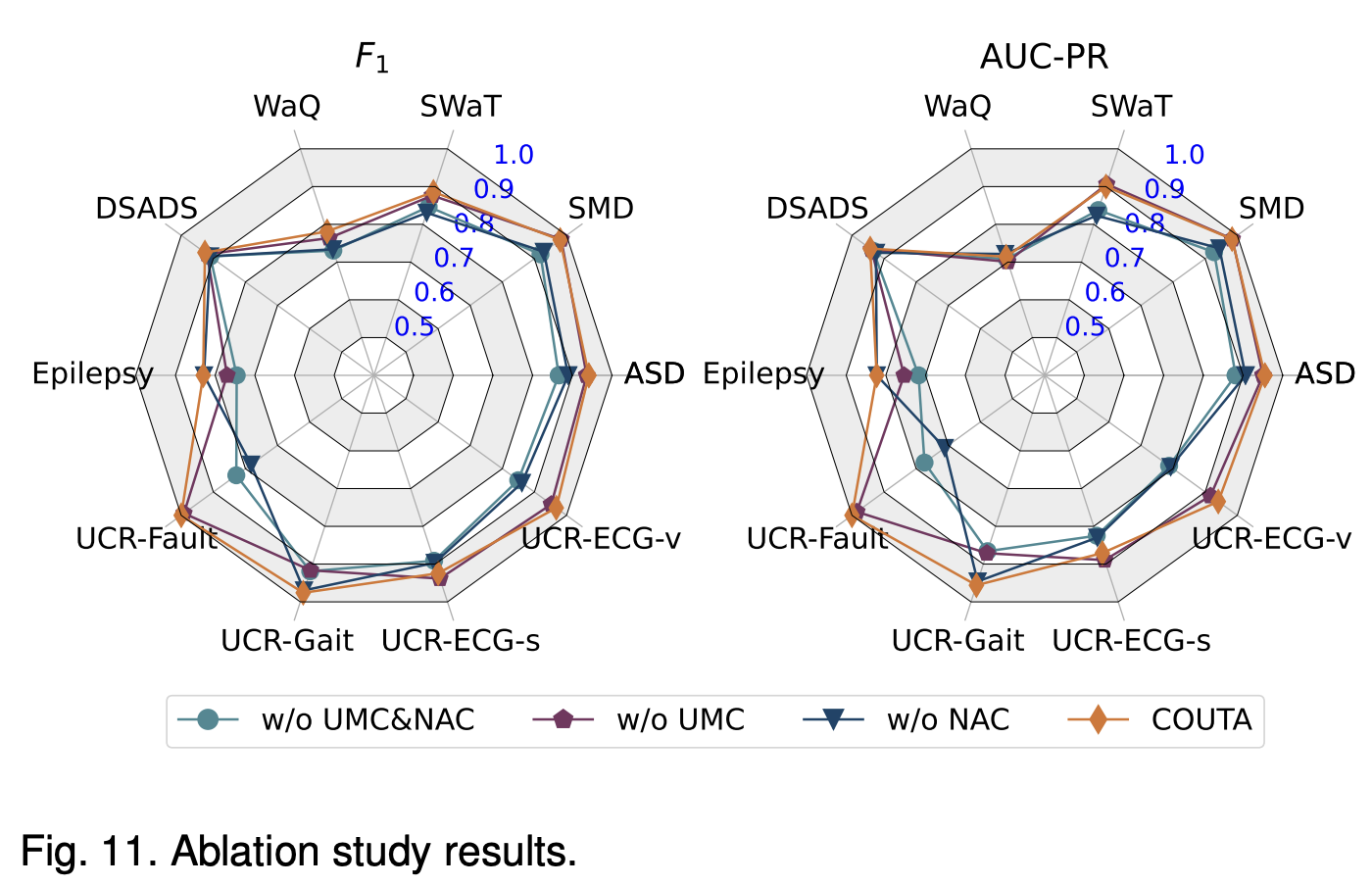
-
Fig. 11은 COUTA와 UMC, NAC가 각각 제거된 변형 모델의 F1 점수와 AUC-PR 성능을 비교
-
UMC와 NAC는 COUTA의 성능을 크게 향상시키는 것으로 나타났습니다. UMC는 F1 점수에서 11%, AUC-PR에서 14%의 향상을 가져옴
-
NAC는 ASD 데이터셋에서 F1과 AUC-PR에서 각각 약 8%의 향상을 가져옴
5. Conclusions
본 논문은 보정된 one-class classification에 기반한 비지도 시계열 이상 탐지 방법인 COUTA를 소개함
Uncertainty Modeling-based Calibration (UMC):
- One-class 거리 값에 사전 분포를 부과하여 모델 불확실성을 얻습니다.
- 이론적으로 동기부여된 새로운 학습 목표를 통해 높은 불확실성을 가진 잡음 데이터를 제어하고, 동시에 확신 있는 예측을 장려하여 어려운 정상 샘플의 효과적인 학습을 보장합니다.
Native Anomaly-based Calibration (NAC):
- 원본 시계열 데이터를 기반으로 가상 이상 예제를 생성하기 위해 맞춤형 데이터 변형 작업을 설계합니다.
- 이는 초기 이상 행동에 대한 귀중한 지식을 제공하여 one-class classification이 데이터를 더 잘 학습할 수 있게 합니다.
COUTA의 여러 특성을 검증하여 다양한 이상 유형에 대한 우수한 일반화 능력, 이상 오염에 대한 뛰어난 견고성, 그리고 좋은 확장성을 확인함
계절적이고 많은 반복 패턴이 있는 시계열 데이터에 적합하지만, 시간적 드리프트가 발생할 때 실패할 수 있음
COUTA는 이상 오염과 이상 지식의 부재라는 두 가지 주요 문제를 해결하고, 다양한 데이터셋에서 우수한 성능을 보여주는 강력한 비지도 시계열 이상 탐지 방법임
