[Paper Review] Nominality score conditioned time series anomaly detection by point/sequential reconstruction
[Paper Review] Seminar
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다
Abstract
본 논문에서는 비지도 학습을 기반으로 한 시계열 이상 탐지 프레임워크를 제안
이 프레임워크는 point 기반 모델과 시퀀스 기반 모델을 사용하여 점 이상과 문맥적 이상을 정량화함
재구성 오류의 비율에서 명목 점수를 계산하고, 이를 이상 점수와 통합하여 유도된 이상 점수를 도출함
01. Introduction
시계열 이상 탐지는 데이터 시퀀스에서 비정상적인 패턴이나 이벤트를 식별하는 것으로, 금융, 의료, 제조, 운송 등 다양한 분야에서 중요함
최근 연구에서는 레이블이 없는 데이터로도 보이지 않는 이상을 잘 탐지할 수 있는 비지도 학습 접근 방식이 선호됨
대부분의 비지도 시계열 이상 탐지 방법은 각 시간 지점에서 이상 점수를 계산하고 이를 임계값과 비교하여 이상을 탐지함
이러한 방법은 1)Reconstruction-based, 2)Prediction-based, 3)Dissimilarity-based의 세 가지 주요 그룹으로 나눌 수 있음
본 논문에서는 1)point 이상과 2)contextual 이상 두 가지 유형에 초점을 맞추고 있음
point 이상은 단일 시간 지점에서 탐지할 수 있지만, contextual 이상은 특정 문맥에서 벗어난 데이터를 의미하며 시간 정보를 필요로 함
contextual 이상을 탐지하는 모델은 시간 종속 관계를 학습해야 하지만, 이는 point 이상을 찾는 정확도에 영향을 미칠 수 있음
최신 시퀀스 기반 재구성 모델들은 point-contextual 탐지 상충 관계에 직면하여 잡음이 많은 재구성 결과와 차선의 성능을 보임
이에 대한 대안으로, 우리는 분산이 낮은 점 기반 재구성 방법을 실험하였으며, 시간 정보 없이도 경쟁력 있는 성능을 보일 수 있음을 발견
이를 보완하기 위해, 우리는 명목 점수를 도입하고, 이를 기반으로 유도된 이상 점수를 계산하여 원래의 이상 점수보다 우수한 성능을 보임을 증명함
본 연구에서 제안된 방법인 Nominality score conditioned time series anomaly
detection by Point/Sequential Reconstruction(NPSR)은 단일 및 다중 엔티티 데이터셋에서 최신 기술들을 능가하는 성능을 보임
03. Methods
3.1 Problem Formulation
주어진 다변량 시계열 데이터 와 이에 대응하는 레이블 를 기반으로, 각 시간 point에 대해 이상 점수를 계산하여 이상 탐지를 수행하는 문제를 정의
성능 평가는 포인트-와이즈 F1 점수(F1*)를 사용하여 최대한 정확한 이상 탐지를 목표로 함
3.2 Nominal Time Series and Two-stage Deviation
명목 시계열 데이터와 두 단계 편차를 정의하여 시계열 데이터에서 이상을 탐지하는 방법을 설명
- 관측된 데이터와 명목 시계열 데이터 간의 편차를 두 가지 요소로 나누고, 이를 통해 점 이상과 문맥적 이상을 정량화함
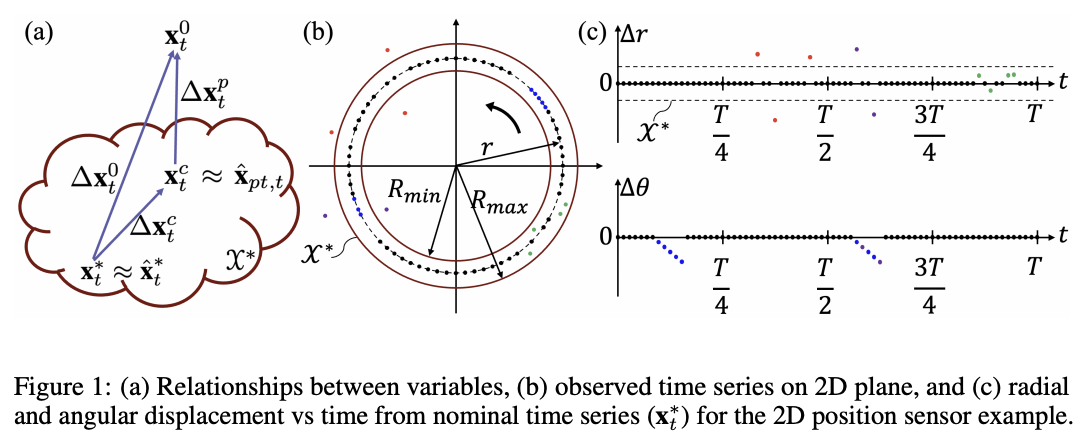
Fig. 1은 다양한 변수 간의 관계를 나타냄(예시)
ex)2D 위치 센서 데이터의 경우, 명목 시계열 데이터는 중심 원점을 중심으로 한 원운동
3.3 The Nominality Score
명목 점수(Nominality Score)의 개념을 도입하고 이를 이상 탐지에 적용하는 방법을 설명
- 명목 점수는 특정 시간 포인트가 정상인지 비정상인지를 나타내며, 제곱 L2-노름의 비율로 정의됨
명목 점수(Nominality Score) 개념화:
- 명목 점수 는 이상 점수와 유사하게 특정 시간 포인트가 얼마나 정상적인지를 나타냄
- 명목 점수 가 적절하려면, 모든 가능한 에 대해 이어야 함
즉, 명목 점수가 보다 큰 정상 포인트의 비율이 이상 포인트의 비율보다 커야 함
명목 점수 정의:
- 이 연구에서는 명목 점수를 와 의 제곱 L2-노름의 비율로 정의함
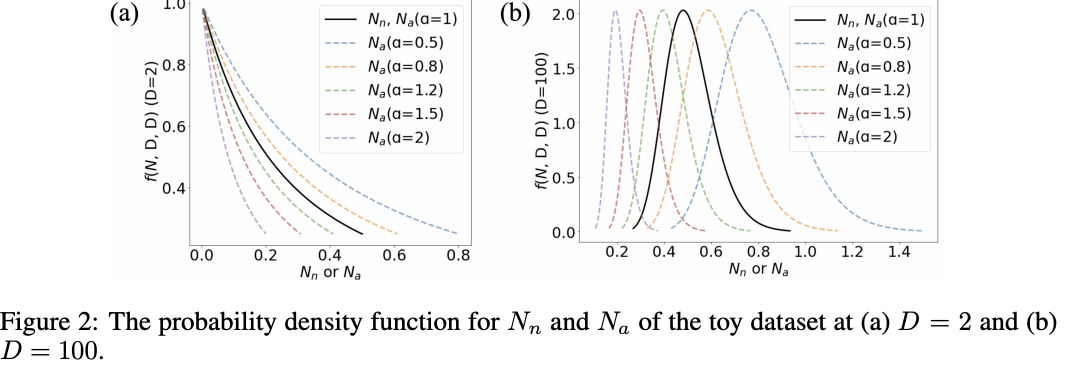
명목 점수의 적절성을 평가하기 위해 예제 데이터셋을 사용하여 명목 점수 분포를 F-분포로 나타내고, 명목 점수가 이상 탐지에 어떻게 활용될 수 있는지를 이론적으로 설명함
명목 점수 분포:
- 과 의 분포를 F-분포로 나타냄
- 이면, 는 적절한 명목 점수가 됨
3.4 The Nominality Score
명목 점수와 이상 점수를 결합하여 유도된 이상 점수를 정의하고, 이를 통해 시계열 데이터에서 이상 탐지의 성능을 향상시키는 방법을 설명
유도된 이상 점수는 명목 점수에 기반한 변환 함수를 사용하여 계산되며, 소프트 및 하드 게이트 함수를 통해 더 나은 이상 탐지 성능을 보장함
유도된 이상 점수 (Induced Anomaly Score) 정의:
- 명목 점수 와 이상 점수 를 결합하여 유도된 이상 점수 를 정의합니다.
- 유도된 이상 점수는 특정 시간 포인트 에서의 이상 가능성을 통합하여 계산됩니다.
여기서 는 유도 길이
유도된 이상 점수의 성질:
- 유도된 이상 점수는 명목 점수를 기반으로 이상 점수를 개선하여 계산
- 두 가지 경우를 고려합니다: 소프트 게이트 함수와 하드 게이트 함수.
- 소프트 게이트 함수 사용:
•
• 모든 정상 포인트에 대해 이면, 유도된 이상 점수가 원래의 이상 점수보다 더 나은 점수를 가짐 - 하드 게이트 함수 사용:
•
• 특정 임계값 이하의 모든 이상 포인트에 대해 이면, 유도된 이상 점수가 원래의 이상 점수보다 더 나은 점수를 가짐
이론적 증명을 통해 유도된 이상 점수가 특정 조건 하에서 원래의 이상 점수보다 더 나은 성능을 보임을 입증함
3.5 Point-based Reconstruction Models
Point-based 재구성 모델 정의:
- 각 시간 포인트 를 포인트 단위로 재구성하는 모델 를 고려
- 를 사용하여 재구성된 포인트 = , 를 얻음
- Point-based 재구성 평균 제곱 오류 = 를 사용하여 이상 점수를 계산
이상 점수의 문제점과 해결:
- 이 접근 방식의 한 가지 문제는 시간 종속 관계를 고려하지 않는다는 점
- 그러나 단순한 Point-based 모델 이 이미 경쟁력 있는 성능을 달성할 수 있음을 발견
- 은 모든 정상 포인트 데이터의 분포를 포착하며, 가 에 속하거나 그와 매우 가까운 것으로 가정
Point-based 모델의 학습:
은 포인트 단위로 원래 데이터를 재구성할 수 있는 능력이 있는 어떤 모델이라도 될 수 있음
- Performer 기반 오토인코더 모델을 사용하여 최적의 성능을 달성했음을 발견
- 이 모델은 복잡한 시간 종속 관계를 찾기보다는 각 시간 포인트를 개별적으로 재구성하는 것이 더 쉽움
모델은 단순하지만 인상적인 점수를 달성할 수 있음
이는 Point-based 재구성 모델이 시간 종속 관계를 고려하지 않아도 경쟁력 있는 성능을 보일 수 있음을 시사함
3.6 Sequence-based Reconstruction Models
Sequence-based 재구성 모델 정의:
- 시간 종속 관계를 고려하여 시계열 데이터를 재구성하는 모델 를 사용
- 이 모델은 시간 포인트의 시퀀스를 입력으로 받아서 명목 시계열 데이터를 근사
= =
훈련 데이터와 모델 용량:
- 가 를 얼마나 잘 근사하는지는 훈련 데이터와 모델의 용량에 따라 다름
- 실제로는 계산 효율성을 위해 의 일부 섹션만 입력으로 사용하여 재구성
- 중간 포인트를 예측하는 Performer 기반 스택 인코더 를 사용
Point-based와 Sequence-based 모델의 비교:
Point-based 모델은 개별 포인트를 재구성하는 반면, Sequence-based 모델은 시간 종속 관계를 고려하여 시퀀스를 재구성함
- 와 를 얻기 위해 와 를 사용
- 이 두 모델을 결합하여 명목 점수 와 유도된 이상 점수 를 계산
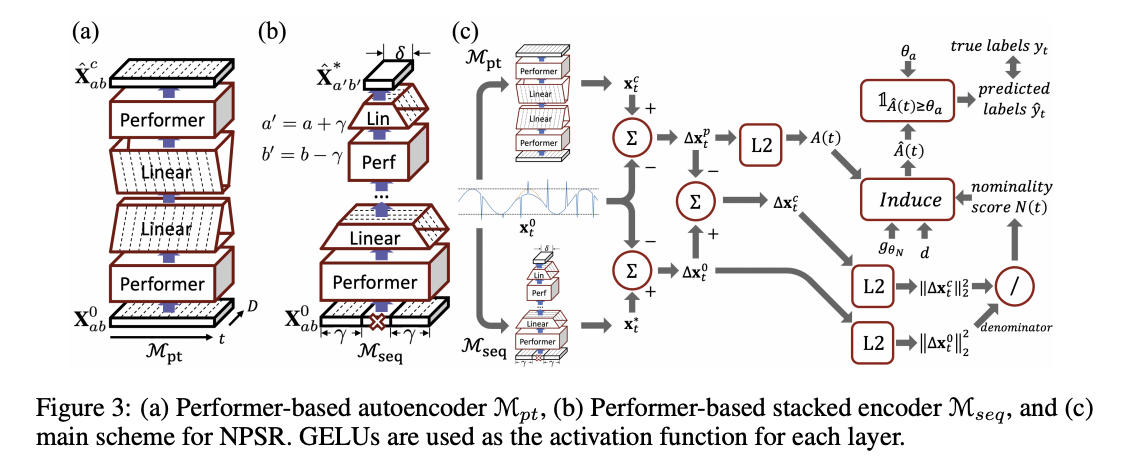
알고리즘:
- 알고리즘 1은 소프트 게이트 함수를 사용하여 와 를 평가
- 와 를 재구성하고, 이상 점수 와 명목 점수 를 계산
- 최종적으로 를 계산하여 점수를 평가

4 Experiments
4.1 Datasets
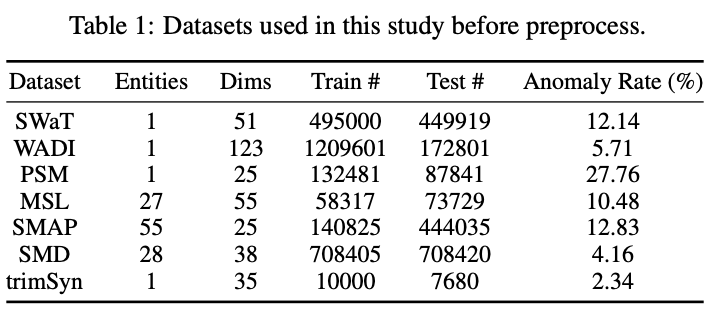
데이터 셋은 위와 같이 7개를 사용함
4.2 Baselines
NPSR 성능 평가:
- NPSR의 성능을 여러 딥러닝 알고리즘 및 간단한 휴리스틱과 비교하여 평가
- 다양한 데이터셋과 알고리즘을 최적화하는 데 많은 시간이 소요되므로, 세 단계 접근법을 사용하여 표 2를 채움:
1. 원본 논문에서 값을 참조
2. 다른 출판물에서 보고된 최고 값을 검색
3. 공개 코드가 있는 경우 코드를 실행하여 값을 구함 - PSM 데이터셋에 대한 보고된 값을 찾을 수 없어 공백으로 남김
4.3 Main Results
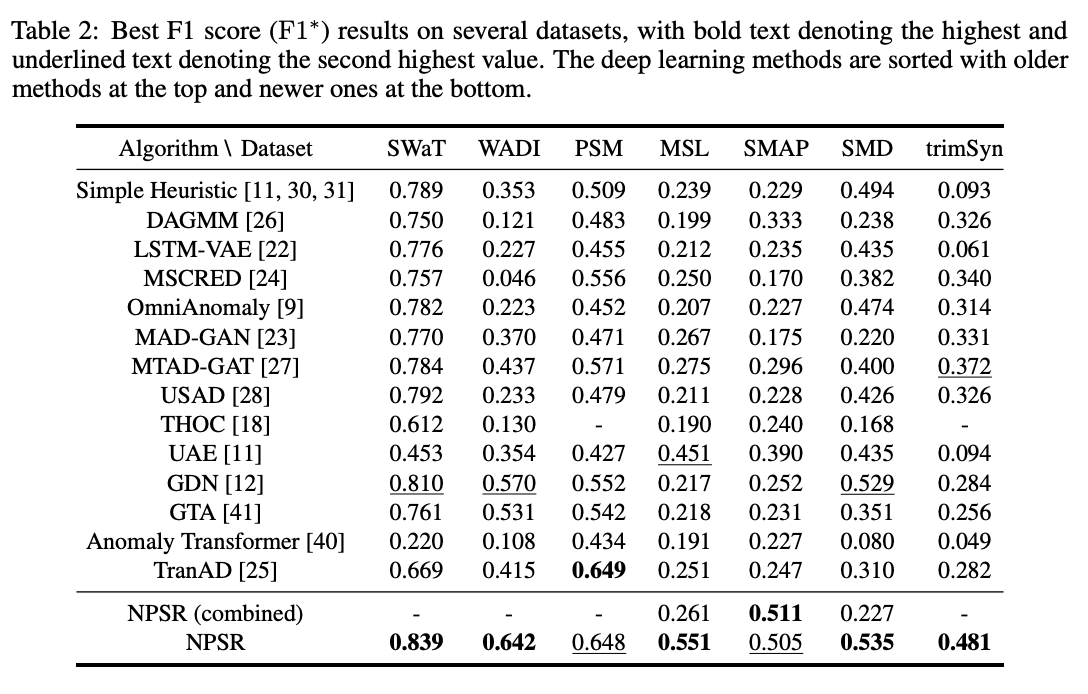
- NPSR은 거의 모든 다른 알고리즘보다 일관되게 더 나은 성능을 보임
- PSM 데이터셋에서는 TranAD보다 약간 낮은 성능을 보임
- NPSR은 낮은 오탐률로 점 이상을 정확히 포착
- NPSR은 최신 연구 방법과 비교했을 때 일관되게 높은 성능을 보임
- 간단한 휴리스틱도 높은 F1* 점수를 기록했으나, NPSR이 유일하게 일관되게 더 높은 성능을 보임
4.4 Ablation Study
Ablation Study 목적:
제안된 방법의 여러 측면을 조명하고, 다른 이상 점수 또는 를 생성하는 다섯 가지 방법의 성능을 비교합
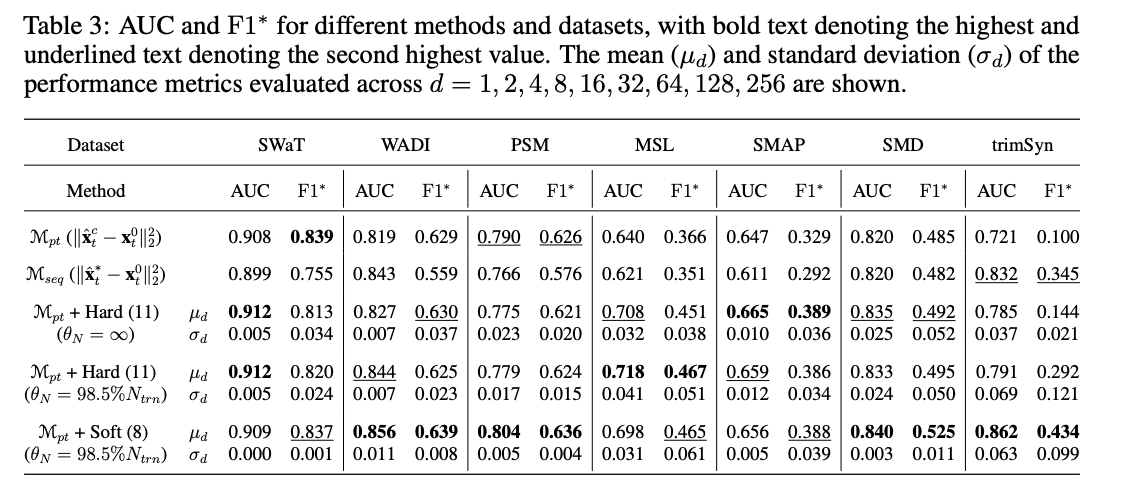
- 는 보다 높은 성능을 보이며, 특히 시간 종속 관계를 모델링하지 않음에도 불구하고 우수한 결과를 보임
- 스무딩된 는 대부분의 데이터셋에서 성능을 향상시키는 좋은 방법
- 소프트 게이트 함수와 명목 점수를 결합하면 가장 높은 점수를 달성
- 하드 게이트 함수는 특정 상황에서 성능이 더 높을 수 있지만, 데이터셋에 따라 성능이 다를 수 있음
명목 점수 분포:
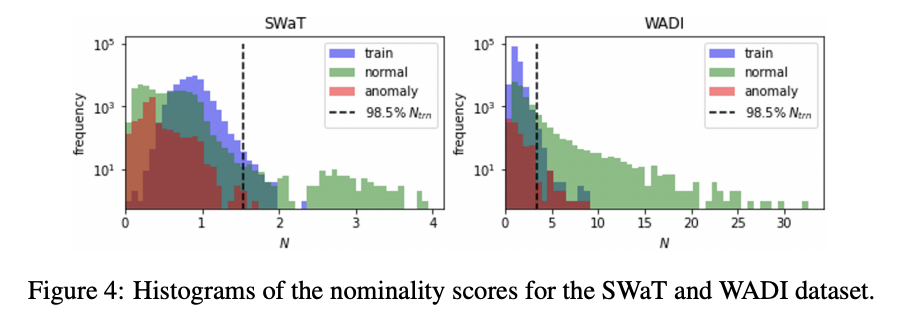
SWaT와 WADI 데이터셋에 대한 명목 점수의 분포는 정상 포인트와 이상 포인트 간의 분포가 적절하게 분리되어 있음을 확인
4.5 Detection Trade-off Between Point and Contextual Anomalies
point 이상과 contextual 이상 탐지 간의 트레이드오프를 설명하고, NPSR의 성능과 이를 관련
point 이상 탐지는 개별 시간 포인트의 이상을 찾는 데 중점을 두며, contextual 이상 탐지는 시간 종속 관계를 고려하여 이상을 탐지함
트레이드오프 설명:
- 이상을 잘 탐지하는 모델은 contextual 이상을 잘 탐지하지 못할 수 있으며, 그 반대의 경우도 마찬가지
- 시간 종속 관계를 모델링하는 것은 contextual 이상 탐지에 중요하지만, point 이상 탐지에서는 필수적이지 않을 수 있음
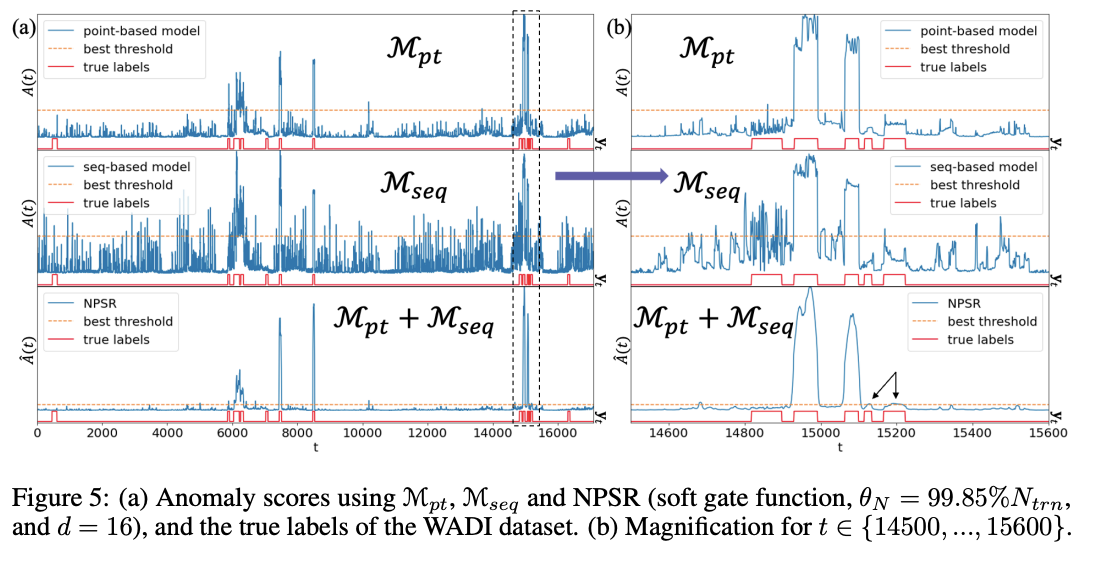
- , , NPSR을 사용한 이상 점수를 시각화
- 특정 시간 범위에서의 이상 점수 확대를 보여줌
- 는 포인트 이상을 잘 탐지하지만, 시간 종속 관계가 있는 문맥적 이상을 잘 탐지하지 못할 수 있음
- 는 문맥적 이상을 잘 탐지하지만, 포인트 이상 탐지에서는 성능이 떨어질 수 있음
- NPSR은 두 종류의 이상을 모두 잘 탐지할 수 있는 균형 잡힌 성능을 보임
5. Conclusion
본 논문에서는 비지도 학습 기반 시계열 이상 탐지를 위한 개선된 프레임워크인 NPSR을 소개함
NPSR은 포인트 이상과 문맥적 이상을 모두 포착하여 높은 성능을 보이며, 광범위하게 적용 가능함
NPSR은 결함 모니터링에 필요한 노동력을 줄이고, 의사 결정을 가속화하며, 에너지 낭비와 시스템 고장을 방지하여 AI 지속 가능성에 기여할 수 있는 잠재력을 가지고 있음
