[Paper Review] ClipSAM: CLIP and SAM collaboration for zero-shot anomaly segmentation (Neurocomputing_2025)
[Paper Review] Seminar
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2025년 논문세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- Zero-Shot Anomaly Segmentation, ZSAS를 위한 새로운 프레임워크인 ClipSAM을 제안함
- 기존의 연구들은 CLIP과 SAM이라는 두 가지 기초 모델을 활용하였지만, 각 모델에 의존할 경우 몇 가지 제한 사항이 발생함
- CLIP은 전반적인 특징 정합성을 중시하지만 미세한 이상 부위의 정확한 분할에는 어려움이 있으며, SAM은 불필요한 마스크를 생성하여 복잡한 사후처리를 요구함
- ClipSAM은 CLIP의 의미 이해 능력을 활용해 이상을 구역화하고 초기 분할을 수행한 후, SAM을 통해 세분화된 결과를 정교화하는 방식으로 두 모델을 효과적으로 결합함
- 이는 Unified Multi-scale Cross-modal Interaction (UMCI) 모듈을 통해 언어와 시각적 특징 간의 상호작용을 강화하고, Multi-level Mask Refinement (MMR) 모듈을 통해 다양한 수준의 마스크를 통합하여 세분화 성능을 향상시키는 과정을 포함함
- 실험 결과, ClipSAM은 MVTec-AD 및 VisA 데이터셋에서 최적의 분할 성능을 달성하며, 특히 SAM 기반 방법에 비해 각종 성능 지표에서 상당한 향상을 보임
Introduction
- Zero-Shot Anomaly Segmentation, ZSAS는 상용화된 산업 제품과 다양한 이상의 유형으로 인해 훈련 데이터 없이도 이미지 내에서 이상 영역을 정확히 식별하고 세분화하는 중요한 과제임
- 최근 CLIP과 SAM과 같은 기초 모델들이 ZSAS의 성과에 이바지하고 있지만, 각각의 모델은 한계를 지니고 있음
- CLIP은 전반적인 특징 정렬에 강점을 갖고 있지만, 세밀한 이상 세분화에는 부족함이 있으며, SAM은 다양한 프롬프트를 통해 세분화 가능하지만, 자주 불필요한 마스크를 생성하여 후처리가 복잡해짐
- 이러한 문제를 해결하기 위해 연구진은 ClipSAM이라는 새로운 협업 프레임워크를 제안함
- ClipSAM은 CLIP의 이상 감지 및 대략적인 세분화 기능을 활용하여 SAM의 세분화 결과를 정교하게 개선함
- 이를 위해 Unified Multi-scale Cross-modal Interaction(UMCI) 모듈을 도입하여 언어와 비주얼 피처 간의 상호작용을 통해 - 이상 부분의 의미를 학습하고, Multi-level Mask Refinement(MMR) 모듈을 통해 CLIP의 위치 정보를 기반으로 SAM을 유도하여 마스크의 정밀도를 높이는 방식을 취하고 있음
- 이와 같은 접근법은 다양한 데이터셋에서 우수한 성능을 보이며, ZSAS 분야의 새로운 가능성을 열고 있음
Related work
전통적인 이상 탐지 방법
- 첫 번째는 표현 기반 방법으로, 정상 샘플의 특징을 저장하고 이들을 비교하여 이상을 식별하는 방식
예를 들어, PatchCore는 각 카테고리에 대한 정상 샘플의 특징을 저장하고 처리 중에 특징을 비교하여 이상을 분리함 - 두 번째는 재구성 기반 방법으로, 정상 샘플을 재구성한 뒤 재구성된 결과와 입력 간의 차이를 평가하여 이상을 탐지하는 방식
이러한 전통적인 방법들은 훈련된 모델에 의존하므로, 새로운 샘플에 맞춰 재훈련이 필요하다는 단점이 있음
Zero-shot anomaly segmentation
제안된 ZSAS 방법은 CLIP과 SAM 두 가지 주요 모델을 기반으로 발전함
- CLIP 기반 방법은 WinCLIP과 APRIL-GAN과 같은 접근 방식이 있으며, 이미지 패치와 텍스트 특징 간의 유사도를 계산하여 각 패치의 이상 여부를 판단함
- 반면, SAM 기반 방법은 SAA와 같은 접근을 통해 텍스트 프롬프트를 사용하여 후보 마스크를 생성하는데, 이 경우 불확실한 프롬프트로 인해 이상 지역의 정확한 탐지가 어려운 문제가 발생함
- CLIP과 SAM의 협력적 사용을 통해 이러한 한계를 극복하고자 하는 연구도 진행되고 있음
Foundation models
- foundation 모델 부분에서는 CLIP과 SAM이 다양한 후속 작업에서 우수한 성과를 보이면서, ZSAS에서도 이들 모델의 협력이 중요하다는 점을 강조하고 있음
- 최근의 연구들은 기초 모델을 활용한 다양한 시도를 보여주며, 특히 SP-SAM과 SAM-CLIP와 같은 접근 방식을 통해 두 모델 간의 시너지 효과를 극대화하고 있음
Cross-modal interaction
- 교차 모드 상호작용의 중요성이 계속해서 증가하고 있음
- 이는 다양한 도메인에서 이미지와 텍스트 간의 정보를 효과적으로 교환함으로써 더 나은 정보 융합을 통한 이상 지역의 보다 정확한 탐지 가능성을 제시함
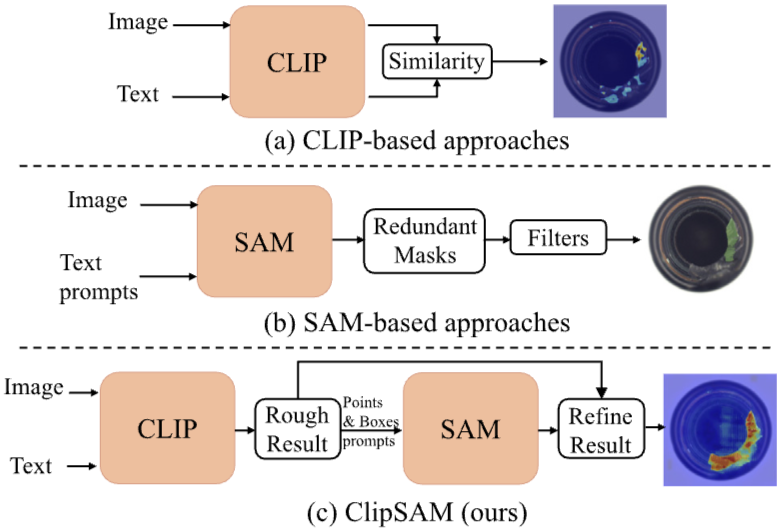
- CLIP 기반 접근, SAM 기반 접근 및 본 논문에서 제안하는 ClipSAM 접근의 구조적 비교를 시각적으로 나타냄
- 이러한 접근 방식 간의 차이를 명확히 하여, ClipSAM이 이들이 갖는 장점을 결합한 점을 잘 나타내고 있음
Methodology
CLIP and SAM collaboration
- CLIP (Contrastive Language-Image Pre-training)와 SAM (Segment Anything Model)의 협업을 통해 제로샷 이상 세분화(Zeros-shot Anomaly Segmentation)에서의 성능을 향상시키는 방식이 소개됨
- 이 두 모델의 결합은 각각의 강점을 활용하여 기존의 한계점을 극복하려는 의미가 있음
- CLIP은 이미지와 텍스트 간의 기능을 결합하여 이상이 있을 것으로 추정되는 영역을 식별하고 대략적으로 세분화하는 데 강점을 가지고 있음
- 반면, SAM은 이 초기 정보를 바탕으로 더욱 정교한 세분화 결과를 생성하는 데 능숙함
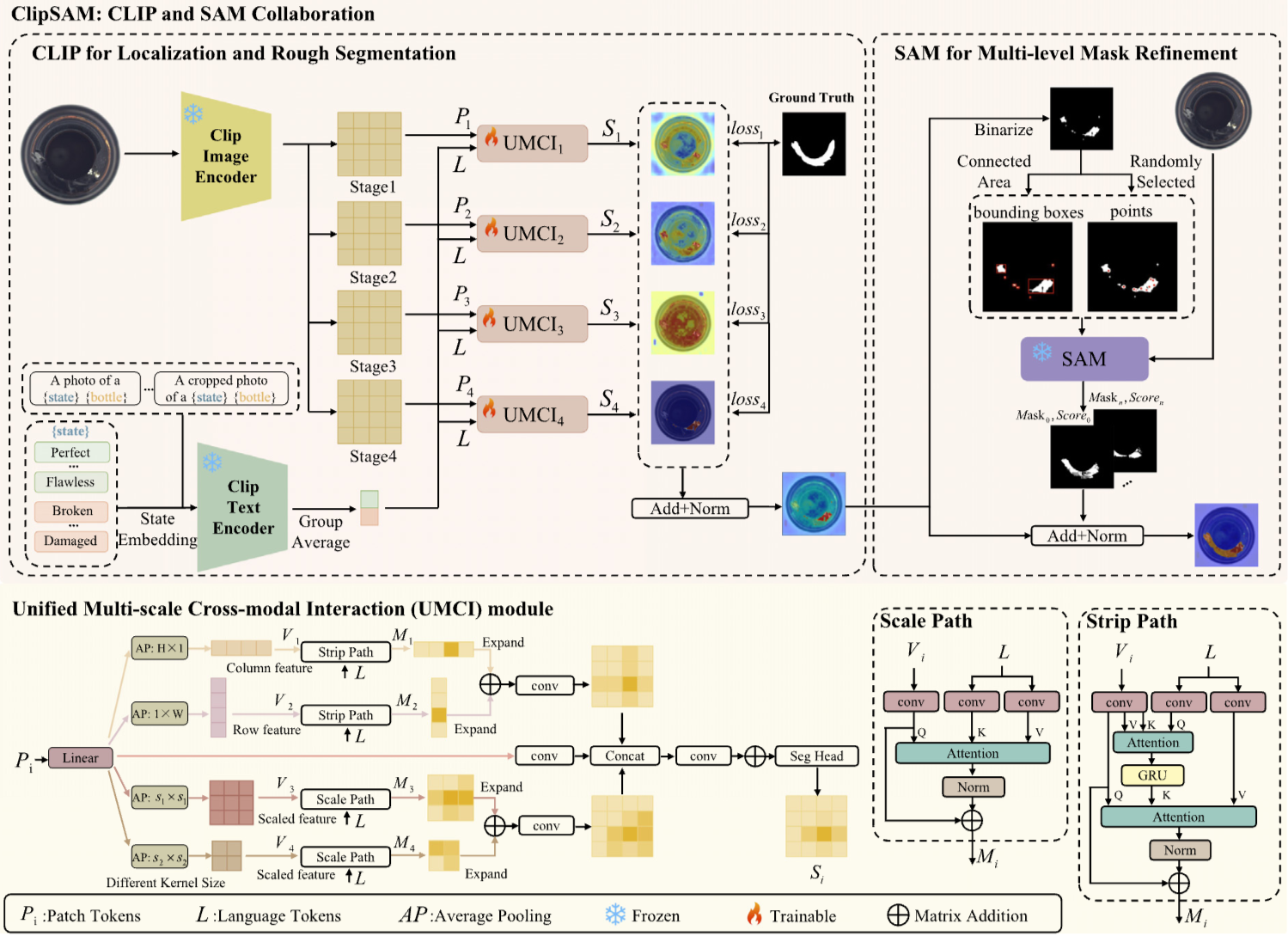
- 제안된 방법론은 두 단계로 구성
- CLIP을 활용하여 이미지에서 이상이 예상되는 영역을 식별하고, 이를 대략적으로 세분화함
- SAM을 사용하여 CLIP이 제공한 위치 정보를 바탕으로 더 세밀하게 세분화하는 과정을 진행함
- 이를 위해 1) Unified Multi-scale Cross-modal Interaction (UMCI) 모듈, 2)Multi-level Mask Refinement (MMR) 모듈 두 가지 주요 모듈이 디자인 됨
- UMCI 모듈은 언어 기능과 시각 기능을 모두 활용하여 이상 부분을 이해하고 세분화하는 과정을 강화함
- 이 모듈은 다양한 방향에서(행-열)와 여러 스케일(다양한 크기)에서 정보의 융합을 촉진하여, 모델이 보다 정교하게 이상을 감지할 수 있도록 지원함
- MMR 모듈은 CLIP의 위치 정보를 기반으로 하여, 다양한 수준의 마스크를 결합하고 조정해 정밀한 출력을 생성하는 데 기여함
- 이러한 협업 방식은 제로샷 이상 세분화의 성능을 효과적으로 향상시키며, 실험 결과에서도 높은 성능을 달성하는 모습을 보여주고 있음
- CLIP과 SAM의 결합은 기존의 한계점을 극복하고 더욱 정교한 세분화 결과를 제공하는 중요한 발전으로 평가될 수 있음
Description text
- ClipSAM 프레임워크에서 제로샷 이상 감지를 위한 프롬프트를 구축하는 방법을 제안함
- 이 프롬프트는 WinCLIP과 같은 이전 연구에서 사용된 것과 유사하게 구성되며, 템플릿, 상태 단어 및 클래스 이름을 조합하여 개체의 특성을 설명하는 문장을 형성함
- 예를 들어, 일반적인 프롬프트는 "A photo of a [상태][클래스]"와 같이 형성될 수 있으며, 여기서 [상태]는 "perfected" 또는 "damaged"와 같은 용어로 채워져 개체가 정상인지 비정상인지 지정
- 이 과정은 이러한 설명 문장을 생성하는 것부터 시작하며, 기술적 템플릿과 적절한 상태 단어를 결합하여 개체의 상태를 전달함
- 문장이 생성된 후, CLIP 모델의 텍스트 인코더를 사용하여 이 설명 텍스트에서 특징을 추출함
- 저자들은 정상 물체와 이상 물체를 각각 설명하는 두 가지 범주의 특징에 집중한다고 언급
- 이러한 특징을 추출한 후, 두 범주에 대해 평균 표현을 별도로 계산하여, 세분화 과정에서 중요한 역할을 하는 통합된 특징 벡터를 생성하게 됨
- 프롬프트 설계는 CLIP 모델이 이미지 내의 비정상 영역을 이해하고 세분화하는 효과성에 직접적인 영향을 미치기 때문에 매우 중요함
- 이러한 전체적인 방법론은 언어 도메인과 시각 도메인 간의 의미 정보를 통합하여 모델의 제로샷 이상 감지 능력을 향상시킴

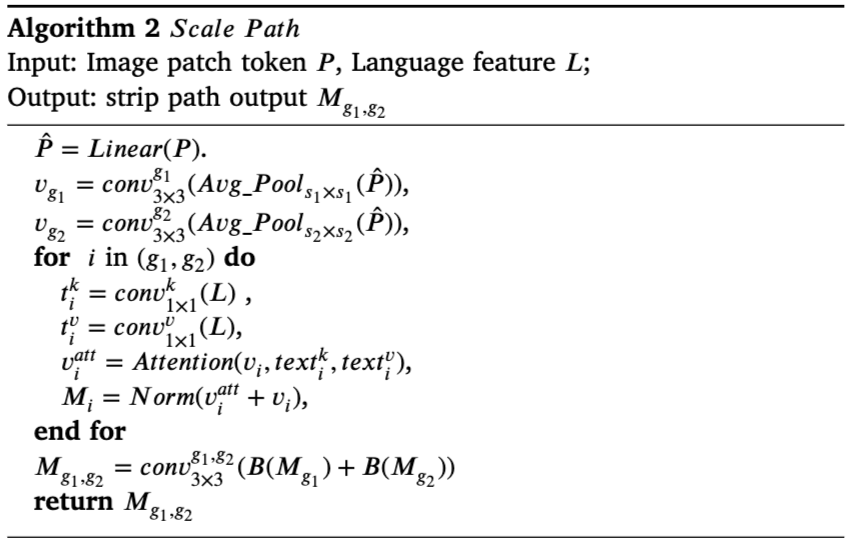
Unified multi-scale cross-modal interaction(UMCI)
- Unified Multi-scale Cross-modal Interaction (UMCI) 모듈은 CLIP와 SAM의 협업 프레임워크에서 중요한 역할을 하며, 두 가지 경로로 구성됨
-
Strip Path
Strip Path는 입력으로 텍스트 특징 벡터 ( L )과 비주얼 패치 토큰 ( P )를 사용하며, 수평 및 수직 방향에서 로우(row)와 컬럼(column) 수준의 특징을 추출하여 정확한 위치를 식별함
이 과정에서 convolutional layers를 통해 텍스트 특징과 시각적 특징 간의 상관관계를 파악함

-
Scale Path
반면, Scale Path는 비주얼 특징을 다양한 규모에서 처리하여 글로벌 특징을 보다 효과적으로 이해할 수 있도록 설계됨
이 경로에서도 여러 스케일에서 평균 풀링을 적용하여 다양한 시각적 정보를 포착하고, 이를 통해 정보 손실을 보완함
- 이 두 경로의 출력은 bilinear interpolation을 통해 원래 이미지의 스케일로 늘여 결합됨
- 이 과정은 위 그림에서 그 구조와 흐름을 보여주며, 최종적으로 UMCI 모듈은 비주얼 패치와 pixel-wise 예측값을 결합하여 rough segmentation을 형성하게 됨
- 이러한 UMCI 모듈은 CLIP 모델이 이미지 내에서 향상된 주의(Attention) 기반의 로컬 및 글로벌 특징을 학습할 수 있도록 помогает, 궁극적으로 ZSAS(Zero-Shot Anomaly Segmentation) 성능을 개선하는 데 기여함
Multi-level mask refinement(MMR)
-
MMR 모듈은 CLIP에서 생성된 대략적인 분할의 포인트와 박스를 이용하여 SAM이 보다 정밀한 마스크를 생성하도록 유도함
-
추가적으로, MASKS와 관련된 신뢰도 점수를 사용하여 최종 결과를 융합하는 과정을 포함함
-
ClipSAM 프레임워크에서 다중 레벨 마스크 정제(MMR) 모듈은 분할 정확도를 높이는 핵심 요소
-
이 모듈은 CLIP 단계에서 생성된 거친 분할 결과 (O)를 이진화하여 이진 마스크 (O_b(x, y))를 생성함
-
이어서 연결된 이상 영역을 식별하여 임의의 포인트 (S_p)와 바운딩 박스 (S_b)를 추출하고, 이 둘을 조합하여 SAM 모듈에 입력할 프롬프트 세트 (S)를 만듦
-
MMR 모듈은 포인트와 박스를 결합하여 SAM의 성능을 최적화하며, 이 두 가지 유형의 프롬프트를 함께 사용할 때 더 나은 분할 결과를 얻음
-
최종적으로, 거친 분할 결과와 정제된 마스크를 융합하여 최종 분할 결과 (O_{final})을 생성함
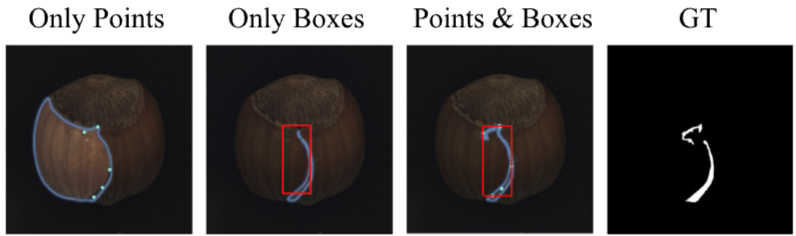
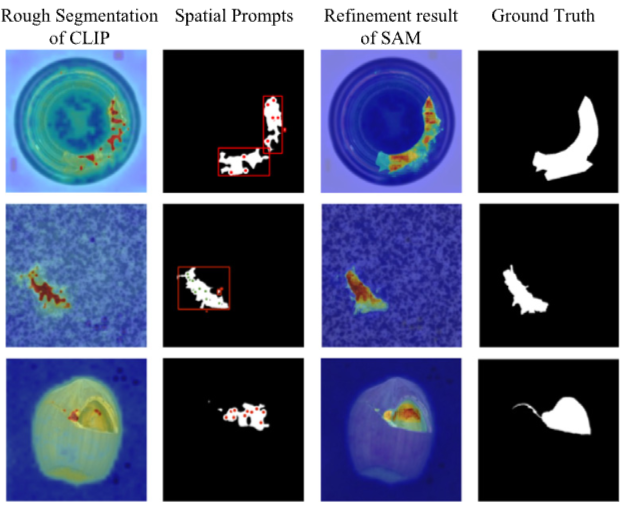
- 다양한 공간 프롬프트를 사용한 SAM의 분할 결과를 시각적으로 보여주며, 조합된 프롬프트 사용이 더욱 정확한 분할 결과를 도출함을 나타냄
- MMR 모듈은 CLIP의 위치 지정 능력을 활용하여 SAM의 정제 과정을 통해 세밀한 분할을 실현하는 데 필수적임
Objective function
- ClipSAM 프레임워크에서 다루는 유일한 학습 부분은 UMCI 모듈
- 이 모듈을 효과적으로 최적화하기 위해 Focal Loss와 Dice Loss를 사용함
- Focal Loss는 클래스의 불균형 문제를 해결하는 데 주로 사용되며, 이 지표는 이상이 전체 객체에서 차지하는 비중이 작은 특성을 고려함
- Dice Loss는 모델 출력과 정답 영역 간의 겹침 정도를 기반으로 하여, 분할 정확도를 높이는 데 유효함
- 최종적으로, 전체 손실은 각 단계에 대해 서로 다른 손실 가중치를 적용하여 계산되며, 이 과정은 모델이 더 효과적으로 학습할 수 있도록 도움
- 이를 통해 ClipSAM은 다양한 이상 탐지 상황에서도 견고한 성능을 발휘할 수 있음
Experiments
Experimental setup
- 본 연구에서는 산업 이상 탐지에 널리 사용되는 두 가지 데이터셋인 MVTec-AD와 VisA를 사용하여 실험을 수행
- MVTec-AD 데이터셋은 15개의 카테고리(5개의 텍스처 및 10개의 객체)로 구성되어 있으며, 총 3466개의 비디오와 1888개의 주석이 달린 이미지로 이루어져 있음
- 이 데이터셋에서는 73종의 이상 유형이 포함되어 있어 다양한 산업 제품의 이상 탐지에 적합함
- 반면에 VisA 데이터셋은 10,821개의 이미지를 포함하며, 9621개의 정상 샘플과 1200개의 이상 샘플로 구성되어 있음
- 이러한 데이터셋은 복잡한 구조를 가진 샘플과 다중 객체를 포함하여 다양한 산업 환경을 고려한 테스트를 가능하게 함
Experiments on MVTec-AD and VisA
Comparison with State-Of-The-Art Approaches
- MVTec-AD 및 VisA 데이터셋에서 제안한 ClipSAM 프레임워크의 성능을 평가
- 사용된 두 데이터셋은 각각 산업의 이상 탐지 작업에 널리 사용되는 표준 데이터셋
- MVTec-AD 데이터셋은 3466개의 비주얼 이미지와 1888개의 주석 이미지로 구성되어 있으며, 15개의 카테고리(5개의 텍스처와 10개의 객체)를 포함하고 73개의 이상 유형을 포함하고 있음
- 반면, VisA 데이터셋은 총 10,821개의 이미지로 이루어져 있으며, 이 중 9,621개는 정상 샘플, 1,200개는 이상 샘플
- ClipSAM의 성능을 평가하기 위해, 이 연구에서는 AUROC, F1-max, AP, PRO와 같은 다양한 평가 지표를 사용함
- AUROC는 클래스 간 구별 능력을 반영하며, F1-max는 정밀도와 재현율의 조화 평균을 나타냄
- AP는 다양한 재현율 수준에서의 모델의 정확성을 측정하고, PRO는 각 연결된 이상 지역의 픽셀 예측 정확도를 평가함
- 이러한 지표들을 통해 ClipSAM이 기존의 최첨단 ZSAS 방법들과 비교했을 때 우수한 성과를 나타내는 것을 확인할 수 있음
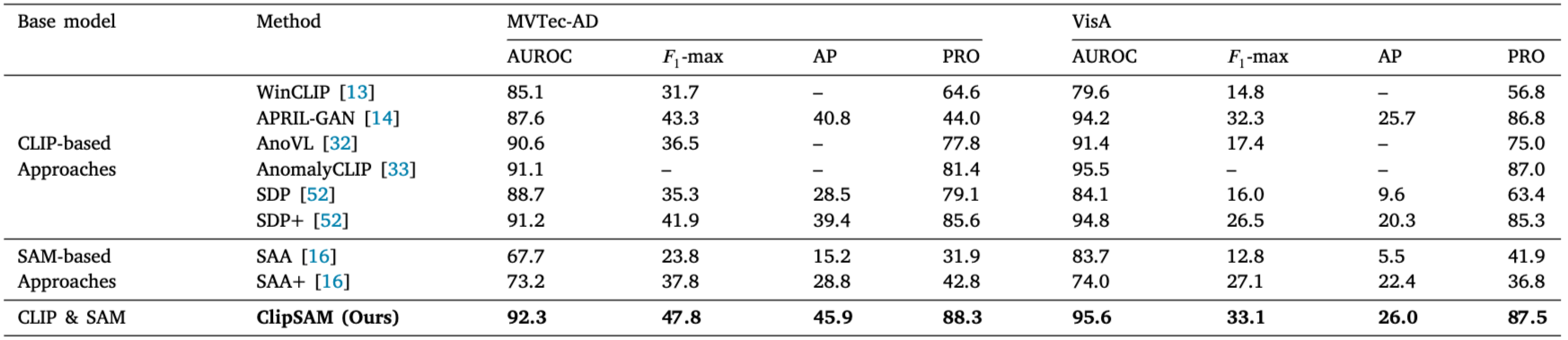
- MVTec-AD와 VisA 데이터셋에서 ClipSAM과 여러 다른 방법들의 성능을 비교한 결과
- ClipSAM은 두 데이터셋 모두에서 AUROC, F1-max, AP, PRO에서 기존 방법들보다 뛰어난 성능을 보임
- 예를 들어, MVTec-AD 데이터셋에서 ClipSAM은 기존 CLIP 기반 방법인 SDP+보다 AUROC에서 1.1%, F1-max에서 5.9%, AP에서 6.5%, PRO에서 2.7% 향상된 결과를 보임
Qualitative Comparisons

- ClipSAM과 APRIL-GAN 및 SAA를 포함한 다른 방법들의 시각적 결과 비교가 제공
- 이 그림을 통해 APRIL-GAN은 대략적으로 이상점을 찾아낼 수 있지만, 세밀한 분할 성능에서는 부족함을 보이는 반면, ClipSAM은 훨씬 더 정확한 위치 및 경계 분할 결과를 나타내는 것을 확인할 수 있음
- 종합적으로 ClipSAM은 MVTec-AD와 VisA 데이터셋에서 모두 기존의 최첨단 방법들보다 더 나은 성능을 보여주었으며, 이는 개발한 프레임워크가 효과적으로 작동함을 입증함
Ablation studies
Effectiveness of Components
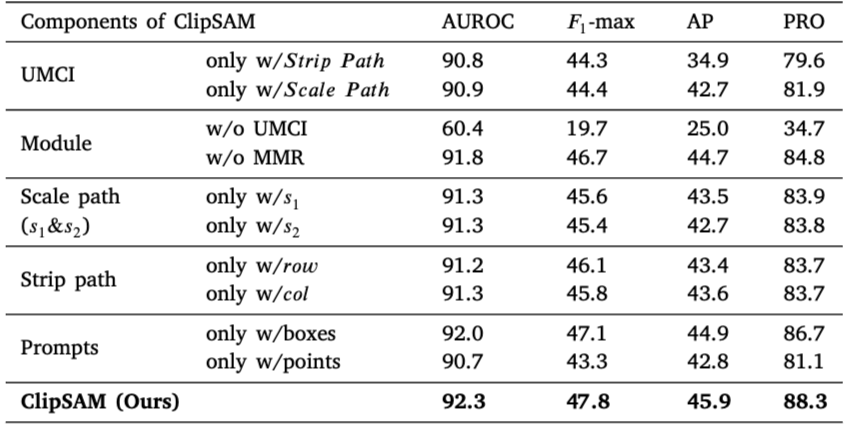
ClipSAM의 ablation 연구에서는 모델의 두 주요 구성 요소인 UMCI(통합 다중 스케일 교차 모드 상호 작용) 모듈과 MMR(다중 수준 마스크 정제) 모듈의 성능 기여도를 분석
-
UMCI 모듈: 𝑆 𝑡𝑟𝑖𝑝 𝑃 𝑎𝑡𝑗 또는 𝑆 𝑐 𝑎𝑙𝑒 𝑃 𝑎𝑡𝑗 중 하나를 제거하면 성능이 저하됨. 특히 𝑆 𝑐 𝑎𝑙𝑒 𝑃 𝑎𝑡𝑗를 제거할 때 성능 감소가 더욱 두드러지며, 이는 두 경로가 상호 보완적으로 작용하여 적절한 이상 위치 파악과 초기 세분화를 가능하게 함을 보여줌
-
MMR 모듈: 이 모듈을 제거할 경우 성능이 소폭 저하됨. MMR은 CLIP의 거친 세분화 결과를 바탕으로 SAM을 통해 보다 정밀한 이상 분할을 수행하는 역할을 하며, 그 부재는 후속 단계의 정확성을 떨어뜨림

Effectiveness of Hyperparameters
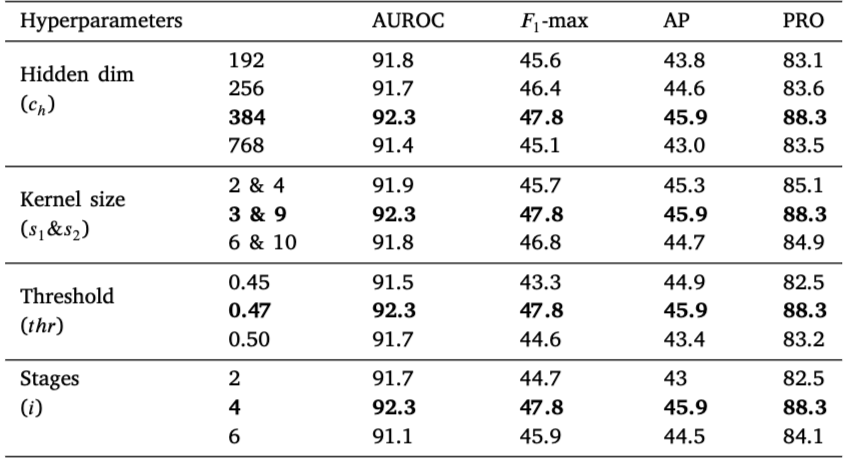
- 숨겨진 차원(hidden dimension), 커널 크기(kernel size), 임계값(threshold) 및 단계 수(stages)와 같은 하이퍼파라미터들이 성능에 중요한 영향을 미친다는 것이 확인
- 예를 들어, 적절한 커널 크기와 임계값의 설정이 모델의 정확도에 긍정적인 영향을 미침
Efficiency of ClipSAM
- ClipSAM 모델의 효율성을 평가하고, 다른 기존 모델들과 비교하여 실행 속도와 연산량에서의 성능을 분석함으로써 실용성을 검토하기 위해 진행됨
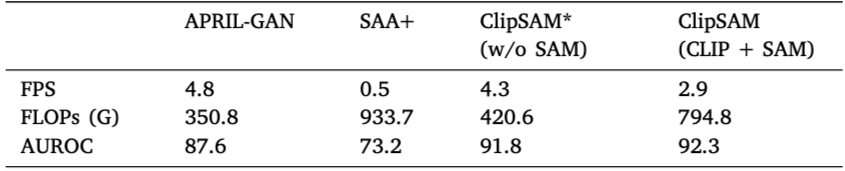
- ClipSAM은 APRIL-GAN 및 SAA+와 비교하여 비슷한 FPS를 유지하면서 높은 정확성을 보임
- ClipSAM* 모델은 효율성의 기준이 되었고, 실행 속도는 우수하지만 성능이 조금 떨어짐
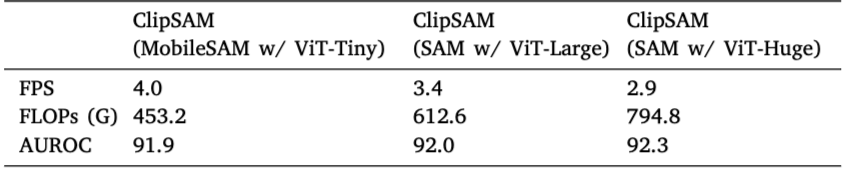
- MobileSAM은 가장 효율적이었지만 성능이 낮았고, 더 큰 SAM 모델일수록 성능이 향상되지만 연산량(FLOPs)도 증가함
-ClipSAM은 실시간 처리를 위해 설계되었으며, Adaptive mask quantity와 통합 전략이 모델 성능을 개선하는 데 기여함
Effectiveness of Extra Strategy
- ClipSAM의 추가 전략이 성능에 미치는 영향을 평가

- ClipSAM의 성능을 개선하기 위한 여러 추가 전략을 검토하여 모델의 견고성을 높이는 방법을 제시함
- Adaptive mask quantity: 이 전략을 통해 높은 신뢰도를 가진 마스크만을 선택하는 것이 성능에 미치는 영향이 최소화되는 것으로 나타남
- 이는 방법이 뛰어난 견고성을 유지한다는 것을 의미
- CLIP 결과 통합: CLIP의 rough segmentation 결과를 SAM의 마스크와 통합하지 않을 경우 성능이 저하된다는 것이 확인됨
- 이는 두 결과를 결합함으로써 최종 출력의 견고성이 향상된다는 것을 나타냄
Experiments on MTD and KSDD2
Comparison with State-Of-The-Art Approaches
- ClipSAM의 성능을 최신 기술들과 비교하여 평가함
- MTD 및 KSDD2 데이터셋에서 ClipSAM의 효과성을 검증하고, 기존의 선진 기술들과의 성능 차이를 분석하기 위한 목적임
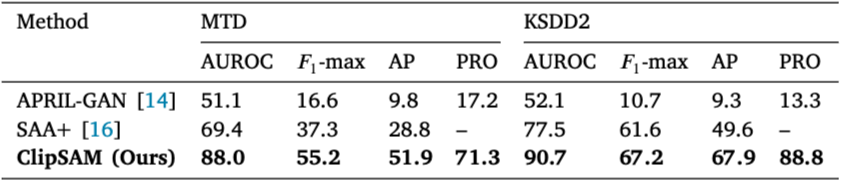
- ClipSAM은 APRIL-GAN 및 SAA+와 비교하여 MTD 및 KSDD2 데이터셋에서 모든 성능 지표에서 유의미한 향상을 보임
- 특히, MTD 데이터셋에서는 APRIL-GAN에 비해 AUROC가 36.9%, 𝐹1-max가 38.6%, AP가 42.1%, PRO가 54.1% 향상됨
- ClipSAM은 MTD와 KSDD2 데이터셋 모두에서 다른 모델들보다 뛰어난 AUROC, 𝐹1-max, AP, PRO 성능을 달성하며, 더 복잡한 이상 탐지 작업에서도 효과적으로 작동함을 보여줌
Qualitative Comparisons
- ClipSAM의 성능을 시각적으로 비교하여 모델의 이상 탐지 능력을 평가
- ClipSAM의 이상 탐지 및 분할 성능을 시각적으로 나타내기 위해 다른 최신 기술들과 비교 분석하여, 모델의 강점을 강조하는 것을 목표로 함
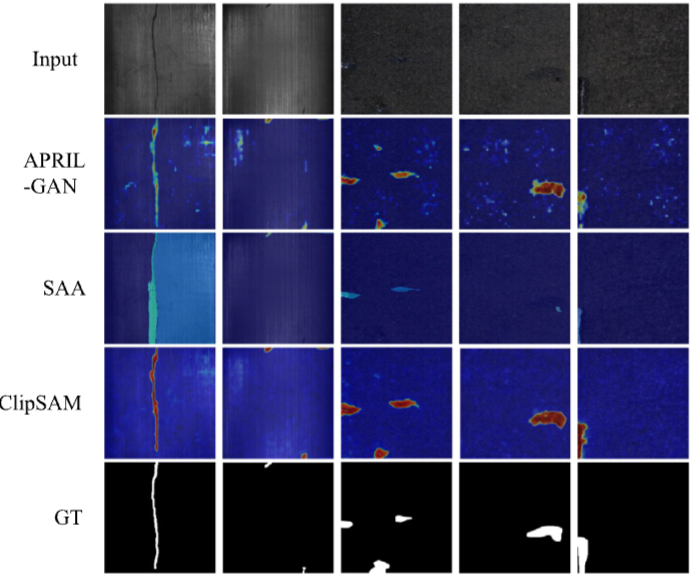
- ClipSAM은 APRIL-GAN과 SAA의 결과와 비교할 때, 이상 부분을 보다 정확하게 식별하고 경계를 명확히 나타내는 능력이 뛰어난 것으로 나타남
- APRIL-GAN은 이상치 예측에서 부정확한 부분이 있었고, SAA는 일부 부위를 간과하거나 잘못된 마스크를 생성함
- 실험 결과, ClipSAM은 복잡한 샘플에서조차 유의미한 이상 탐지를 수행하며, 기존 방법들과의 비교에서 뛰어난 위치 및 경계 탐지 능력을 보여줌
Conclusion
- CLIP(Contrastive Language-Image Pre-training)와 SAM(Segment Anything Model)이라는 두 가지 기본 모델의 협업을 통한 '제로샷 이상치 분할'(Zero-Shot Anomaly Segmentation, ZSAS) 방법론인 ClipSAM을 제안함
- ClipSAM은 두 가지 모듈인 통합 다중 스케일 크로스 모달 상호 작용(UMCI) 모듈과 다중 수준 마스크 정제(MMR) 모듈을 통해 두 모델의 장점을 조화롭게 결합함
- UMCI 모듈은 이상치를 정확하게 위치시키고 초기 분할을 수행
- MMR 모듈은 SAM을 이용해 정밀한 공간 프롬프트로 초기 분할 결과를 정제 - 충분한 실험을 통해 ClipSAM이 ZSAS를 향상시킬 수 있는 새로운 방향을 제공함을 보여주며, 다양한 평가 지표에서 기존 기법보다 향상된 성능을 기록함
- 결과적으로, ClipSAM은 픽셀 수준의 시각적 특징과 언어적 특징 간의 정렬 능력을 더욱 활용하며, 다양한 모델의 협업을 통해 성능을 극대화하는 방법의 가능성을 보여줌
- 연구는 특정 작업을 위해 대형 모델을 효과적으로 활용하는 방법이 앞으로의 중요한 연구 분야임을 제시함
