[Paper Review] SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding
[Paper Review] Seminar
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2025년 논문세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- 본 논문이에서는 SAM(Segment Anything Mode)과 CLIP(Contrastive Language–Image Pretraining) 모델을 통합하여 새로운 모델 SAM-CLIP을 생성함
- CLIP은 의미적 이해에 뛰어나고, SAM은 공간적 이해 및 세분화에서 특화됨
- 통합된 모델은 두 모델의 장점을 결합하여 두 가지 기본 임무를 수행 가능하게 함
- 기존 모델들을 독립적으로 사용하는 것보다 저장공간과 계산 비용을 절감함
- 계산 비용이 적고 데이터의 일부만으로 학습이 가능하여 효율성을 높임
- 다중 작업 학습, 지속적 학습, 지식 증류 기술을 효율적으로 통합하는 방식
- SAM-CLIP이 새롭게 제안한 ‘제로샷 의미론적 세분화’ 작업에서 뛰어난 성과를 보여줌
- Pascal-VOC 및 COCO-Stuff 데이터셋에서 각각 6.8% 및 5.9%의 mIoU(평균 교차 점수) 향상을 기록함
Introduction
Vision Foundation Models(CLIP, SAM)
- CLIP은 의미적 이해와 텍스트 프롬프트 기반의 분류 작업에 뛰어난 성능을 보임
- 반면 SAM은 공간적 이해에 초점을 맞추어 이미지 세분화에 최적화되어 있음
- 본 연구의 주된 목표는 두 모델을 통합하여 SAM-CLIP이라는 새로운 모델을 제안하며, 두 모델의 장점을 결합하고 효율적인 모델을 생성하고자 함
SAM-CLIP
- SAM-CLIP은 다중 작업 학습, 지속적 학습, 그리고 knowledge distillation와 같은 기법들을 활용하여 모델을 통합함
- 해당 과정에서 SAM-CLIP은 기존 모델보다 적은 계산 비용과 데이터 요구량으로 훈련될 수 있으며, 이는 전통적인 다중 작업 훈련 방식보다 훨씬 효율적임
- 또한, SAM-CLIP은 Zeroshot 의미적 세분화 작업에서 새로운 최첨단 결과를 달성하였고, 기존 모델들과 비교했을 때 성능이 향상된 것으로 나타남
- 마지막으로, SAM-CLIP은 엣지 디바이스와 같은 자원이 제한된 환경에서의 활용 가능성이 높아 다양한 비전 작업을 수행할 수 있는 잠재력을 지니고 있음
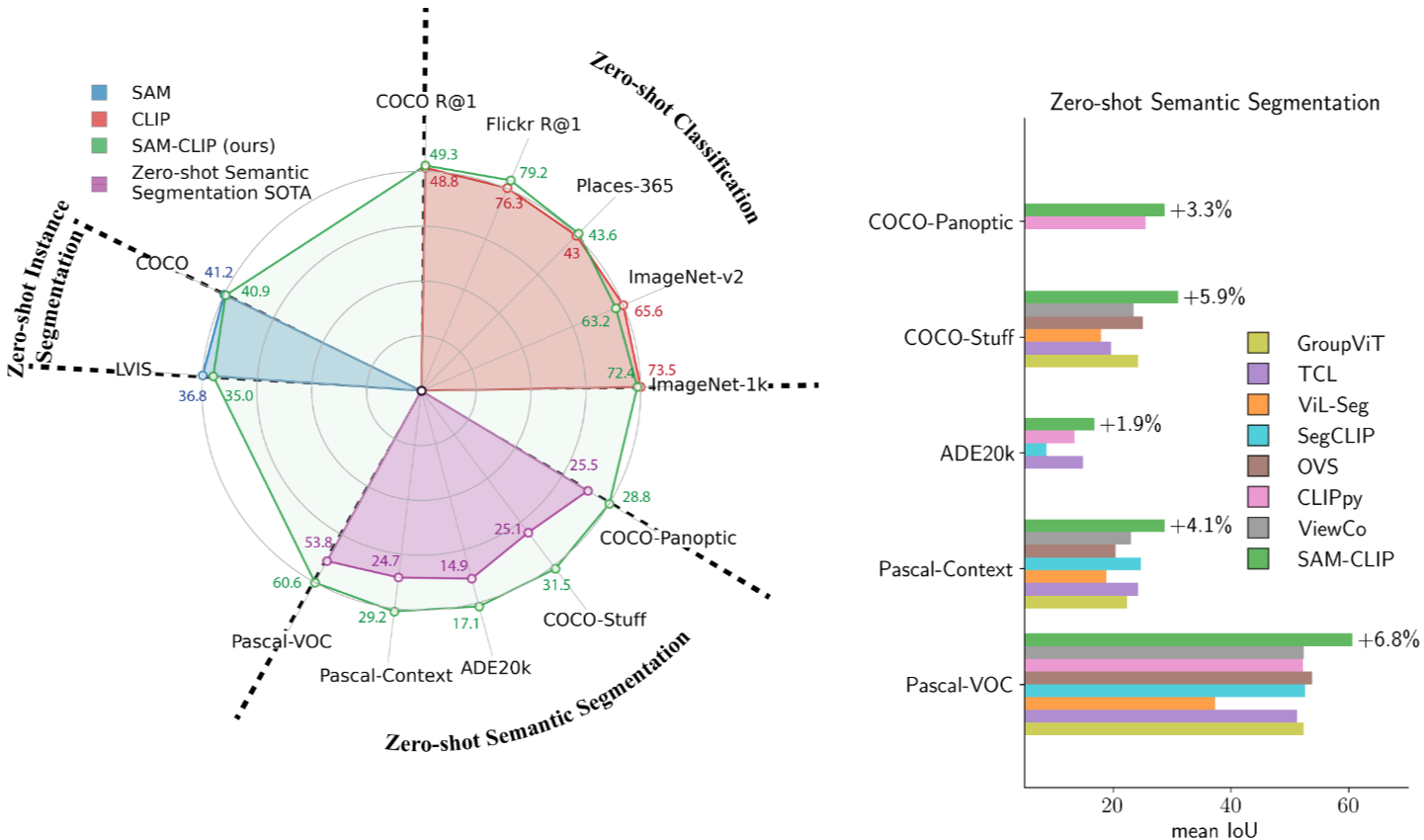
Zero-Shot Capabilities
- SAM-CLIP은 SAM과 CLIP의 능력을 통합하여, 단일 공유 backbone을 통해 두 작업을 수행할 수 있음을 나타냄
- 즉, SAM의 경우 Zero-Shot Instance Segmentation을 수행하고, CLIP의 경우 Zero-Shot Classification 및 이미지-텍스트 검색 기능을 제공함
Emergence of a New Task
- Figure 1의 오른쪽 부분에서는 SAM-CLIP이 Zero-Shot Semantic Segmentation이라는 새로운 작업을 수행할 수 있음을 나타냄
- 이는 SAM과 CLIP이 각각의 기능을 통해 습득한 지식을 결합하여, 의미 기반의 분할 마스크를 생성하는 능력을 갖추게 되었다는 것을 강조함
Background
Vision-Language Models (VLMs)
: CLIP 및 ALIGN과 같은 모델들은 대규모 이미지-텍스트 데이터셋을 기반으로 학습됨
이 모델들은 서로 다른 모달리티를 위한 인코더로 구성되어 이미지와 텍스트 각각의 임베딩을 생성함
Contrastive Objective
: 이미지-텍스트 쌍의 긍정적 관계를 최대화하는 대조적 학습 목표가 적용되며, 이로 인해 무분별한 이미지-텍스트 검색 또는 텍스트 프롬프트를 통한 분류가 가능함
Other VLMs
: ViLT, VLMo, BLIP와 같은 모델들은 이미지와 텍스트 모달리티 간의 혼합 아키텍처를 탐색하여 추가적인 제로샷 능력을 구현함
Segment Anything Model (SAM)
: SAM은 프롬프트를 기반으로 세그멘테이션을 가능하게 하는 대규모 데이터셋, 모델 및 훈련 레시피를 소개함
SAM은 이미지 인코더와 프롬프트 인코더, 마스크 디코더로 구성되며, 고해상도 세그멘테이션 마스크를 생성할 수 있음
Knowledge Distillation (KD)
: 지식 증류는 대형 모델(Teacher)이 축적한 지식을 기반으로 압축된 분류기(Student)를 훈련하는 방법
최근 VLM에 대한 증류 방법들이 전개되고 있으며, 이는 서로 다른 제로샷 능력을 단일 모델로 전달하는데 집중함
Continual Learning (CL)
: 새로운 작업을 배우면서 이미 학습한 지식을 잃지 않도록 하는 계속적 학습 접근 방식이 사용됨
Zero-shot Semantic Segmentation
: 사전 지식 없이 주어진 텍스트 프롬프트에 따라 밀접한 세그멘테이션 마스크를 예측하는 작업으로, 열린 형식의 작업을 요구함
최신 접근 방법은 이미지-텍스트 쌍 데이터셋과 사전 훈련된 VLM을 활용하여 세그멘테이션 마스크를 생성함
Proposed Approach
두 개의 VFMs인 SAM과 CLIP를 효율적으로 통합하여 성능을 극대화하는 방법을 제시함
이 접근방식은 SAM을 기초 모델로 설정하고, CLIP의 지식을 이를 통해 통합하는 과정으로 이루어짐
두 모델은 각각 고유한 능력을 가지며, SAM은 고해상도 이미지에서 뛰어난 세그멘테이션 성능을 보여주고, CLIP은 의미적 이해에 강점을 가지고 있음
이러한 상호 보완적인 특성을 활용하여, SAM-CLIP이라는 단일 모델을 개발함
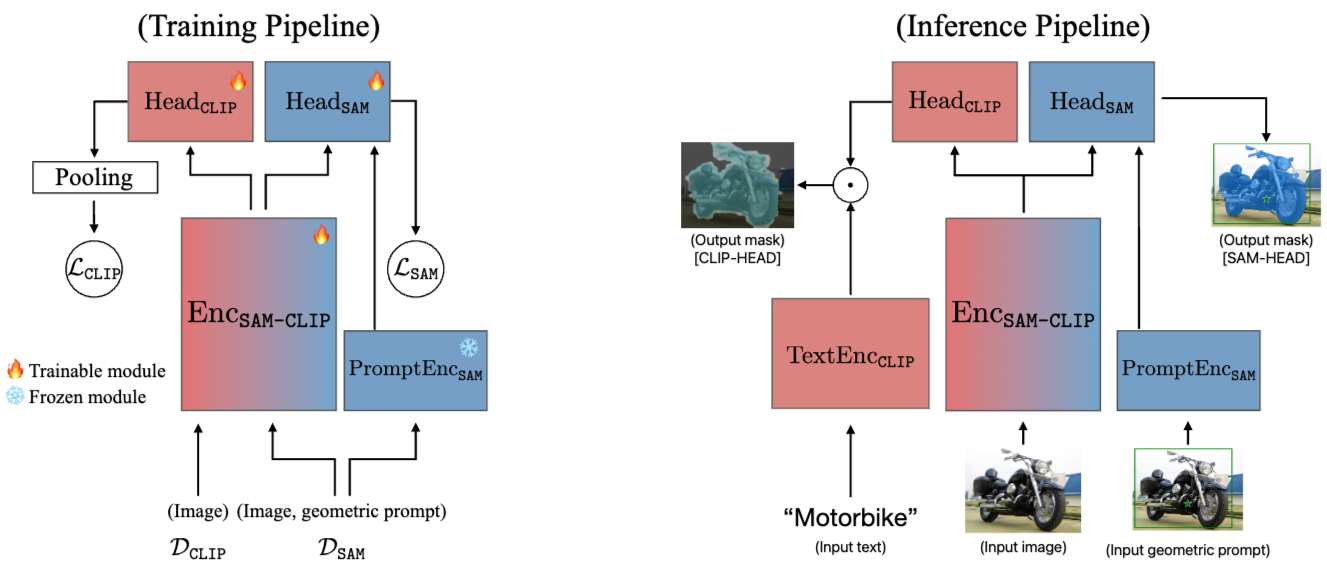
Base and Auxiliary Models
Base Model: SAM (Segment Anything Model)
이미지 인코더 (EncSAM), 프롬프트 인코더 (PromptEncSAM), 마스크 디코더 (MaskDecSAM) 구성
Auxiliary Model: CLIP
EncCLIP 및 TextEncCLIP 로 구성
Knowledge Integration Method
SAM의 샘플에서 추출한 지식과 CLIP의 샘플에서 추출한 지식을 통합하여 새로운 모델 EncSAM-CLIP을 생성합니다.
전이 손실: CLIP의 세미틱 기능을 SAM에 통합하면서, 다음과 같은 손실 함수를 사용하여 지식 전이를 수행합니다:
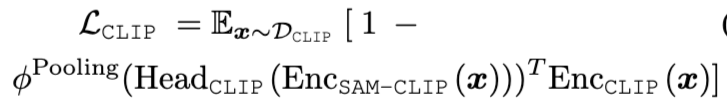
이 수식은 CLIP로부터 학습한 세미틱 특성을 통해 SAM의 성능을 높이는 것을 목표로 합니다.
Multi-task Learning
학습 과정은 두 단계로 구성됨
- Head probing
: 기본 모델의 백본인 EncSAM-CLIP를 고정하고, HeadCLIP만 훈련하여 기본적인 세미틱 기능을 학습 - Multi-task distillation
: 모든 헤드와 이미지 인코더를 학습 가능하게 하여 학습
손실 함수는 아래 수식으로 정의됨
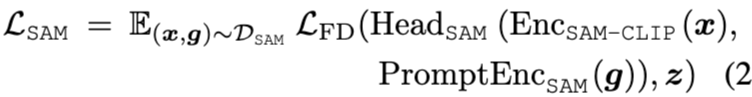
Experiments
Implementation Details
-
Model Architecture
SAM-CLIP은 Segment Anything Model(SAM)을 기반으로 하며, ViT-B/16 아키텍처로 구성됨
SAM은 12개의 변환기 레이어를 포함함
CLIP의 능력을 통합하기 위해, SAM 백본에 CLIP 헤드를 추가
이 CLIP 헤드는 간단한 구조로 3개의 변환기 레이어로 구성됨
이미지에서 추출된 패치 토큰은 통합 풀링 계층을 통해 이미지 수준의 임베딩으로 변환
이 풀링 계층은 샘플 이미지에 대해 더 나은 제로-샷 분류 및 세분화 성능을 이끌어내는 데 기여함 -
Dataset Preparation
CLIP의 지식 증류를 위해 여러 데이터셋을 병합하여 을 생성
포함된 데이터셋은 CC3M, CC12M, YFCC-15M, 및 ImageNet-21k로 총합 40.6M개의 비표시 이미지로 구성됨
SAM의 자기 증류를 위해 SA-1B 데이터셋에서 5.7%의 하위 집합을 샘플링하여 DSAM을 생성함
SAM 데이터셋은 처음에 11M 개의 이미지와 1.1B 개의 마스크로 이루어져 있음 -
Training
Head Probing: 이 단계에서는 이미지 백본(EncSAM-CLIP)은 고정하고, HeadCLIP만 학습함
이는 HeadCLIP의 파라미터에 타당한 값을 먼저 학습하게 하여 Forgetting을 방지하는 데 도움을 줌
Multi-task Distillation: 이 단계에서는 모든 헤드와 이미지 인코더가 학습 가능하도록 하여, 과 을 결합한 손실을 최적화함
이 과정에서 과 에서 샘플을 사용하여 다중 작업 훈련을 진행함 -
Resolution Adaption
SAM-CLIP은 다양한 해상도를 지원하도록 설계됨
CLIP 작업은 낮은 해상도에서 수행되고, SAM 작업은 1024px 해상도에서 수행됨
두 헤드를 동시에 사용할 경우 효율성을 높이기 위해 CLIP 헤드를 1024px 해상도로 조정하는 추가 단계를 포함함 -
More Details
구현 및 훈련에 대한 세부사항은 부록 A에 제시됨
Zero-Shot Evaluations
-
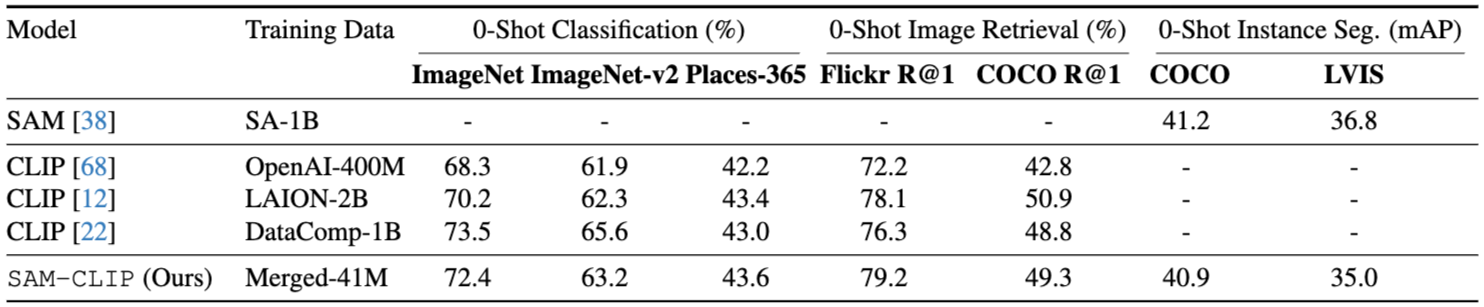
CLIP Tasks: Zero-Shot Image Classification & Text-to-Image Retrieval
제로샷 이미지 분류
:SAM-CLIP은 제로샷 이미지 분류를 위해 미리 정의된 텍스트 템플릿을 사용하여 이미지들을 분류
입력 변수로는 ImageNet, ImageNet-v2, Places365와 같은 데이터셋이 사용
SAM-CLIP은 72.4%의 정확도로 ImageNet에서 제로샷 분류를 수행하였으며, 기존 CLIP 모델들과 비교했을 때 경쟁력 있는 성능을 보임
특히 CLIP 모델들은 일반적으로 224px 해상도에서 훈련되었으나 SAM-CLIP은 336px 해상도로 작동하여 이에 대한 성능 향상이 있음을 보여줌
제로샷 텍스트-이미지 검색:
: SAM-CLIP은 Flickr30K 및 COCO 데이터셋에서 텍스트-이미지 검색 성능을 평가함
여기서는 이미지와 텍스트 임베딩 간의 코사인 유사도를 계산하여 순위를 매김
SAM-CLIP은 79.2%의 Recall@1 성능을 달성하여 기존 모델보다 높은 검색 성능을 기록함
이에 따라 제로샷 평가에서 뛰어난 성능을 발휘 -
SAM Task: Zero-Shot Instance Segmentation
: SAM-CLIP은 객체 탐지 결과로 생성된 경계 상자를 기반으로 개별 객체 인스턴스에 대한 마스크를 예측함
COCO와 LVIS 데이터를 사용해 성능을 평가함
SAM-CLIP은 COCO와 LVIS 데이터셋에서 원본 SAM 모델과 비슷한 성능을 보여주어, 기존 SAM의 능력이 효과적으로 유지되었음을 입증함
이 성능은 제로샷 인스턴스 분할에서 SAM-CLIP의 우수성을 나타냄 -
Zero-Shot Transfer to Semantic Segmentation

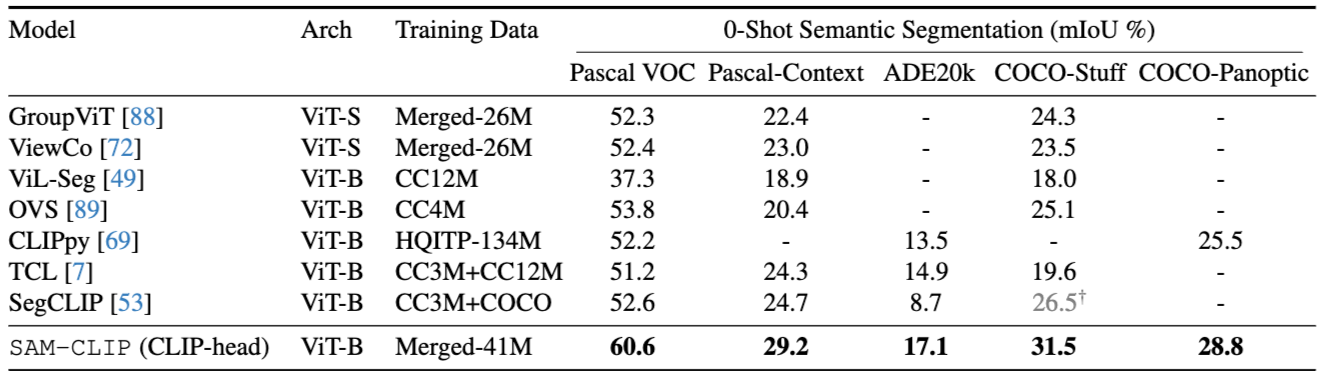
: SAM-CLIP은 Pascal VOC, Pascal Context, ADE20k 등의 데이터셋에서 제로샷 의미론적 분할의 성능을 평가함
여기서는 CLIP-헤드를 통해 입력된 이미지를 텍스트 클래스와 일치시키고 마스크 예측을 수행함
SAM-CLIP은 60.6%의 mean IoU(mIoU)를 기록하여 각 데이터셋에서 이전 아키텍처들보다 훨씬 더 나은 성능을 달성함
특히, 모든 데이터셋에서 SOTA를 큼직한 차이로 이룸
Head-Probing Evaluations on Learned Representations

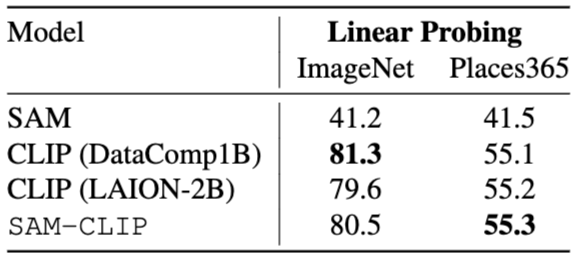
- SAM-CLIP 모델이 두 개의 기초 모델인 SAM과 CLIP에서 표현을 상속받는 능력을 평가
- 이 연구에서는 세 가지 헤드 구조(선형 헤드, DeepLab-v3, PSP-Net)를 사용하여 Pascal VOC와 ADE20k 두 개의 데이터셋에 대해 평가를 수행
- SAM의 표현은 CLIP과 비교할 때 의미적 이해가 필요한 작업에서 성능이 저조한 반면, SAM-CLIP은 다양한 헤드 구조에서 모두 더 나은 성능을 보임
- 이러한 결과는 SAM-CLIP 모델이 두 부모 모델의 강점을 융합하여 광범위한 다운스트림 비전 작업에 더 적합한 표현 능력을 제공할 수 있음을 보여줌
Composing Both CLIP and SAM Heads for Better Segmentation
- SAM-CLIP 모델의 CLIP 헤드와 SAM 헤드를 결합하여 더 나은 성능을 도출하는 방법을 설명함
- 먼저, 입력 이미지를 1024px로 크기를 조정한 후, SAM-CLIP의 인코더를 통해 처리함
- 이후 CLIP 헤드를 사용하여 낮은 해상도(32x32)에서 마스크 예측을 수행하며, 이때 텍스트 프롬프트를 활용
- CLIP 헤드에서 생성된 마스크 예측의 신뢰도를 바탕으로 포인트 프롬프트를 생성함
- 그런 다음, 이 포인트 프롬프트와 CLIP 헤드에서 나온 마스크 예측을 SAM의 프롬프트 인코더에 입력하여 고해상도(256x256) 마스크를 예측
- 마지막으로, SAM 헤드는 두 가지 입력을 활용하여 더욱 정밀하고 세분화된 마스크 예측을 생성함
- 1024px 해상도로 EncSAM-CLIP을 단 한 번의 전방 패스에서 실행하도록 설계되어 있어 효율성을 확보
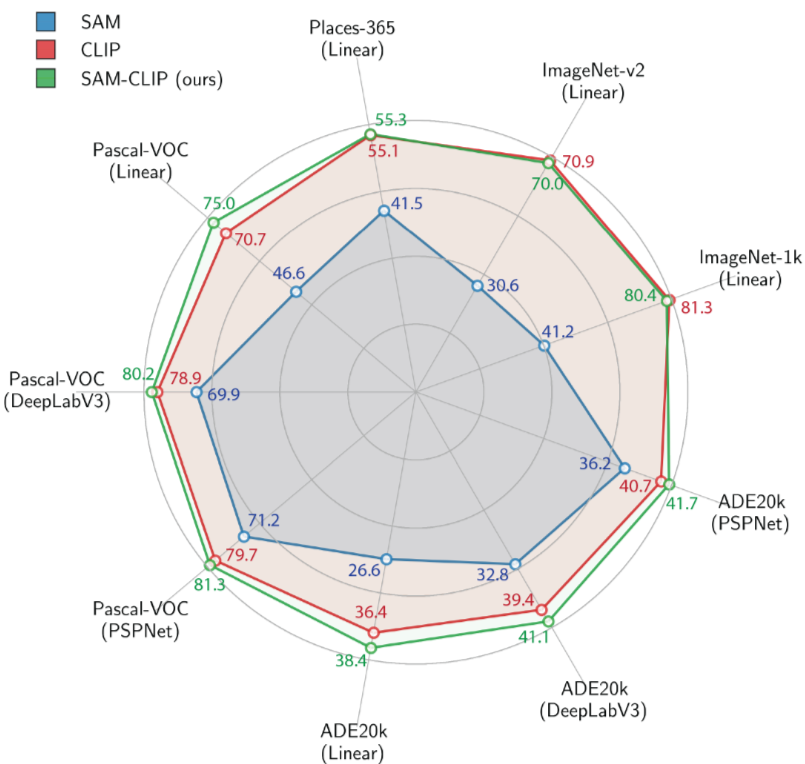

- CLIP 헤드만 사용할 때보다 성능이 개선되며, 이 새로운 접근 방식은 제로샷 세그먼테이션에서 remarkable improvement를 나타냄
- 따라서 이 방식은 서로 다른 기능을 가진 CLIP과 SAM 헤드를 결합함으로써, 각 모델의 강점을 살린 정밀한 세분화 성능을 제공함
Conclusion
본 논문에서는 공공에서 사용 가능한 시각 기반 모델인 Segment Anything Model (SAM)과 Contrastive Language-Image Pretraining (CLIP)을 통합하여 단일 아키텍처로 만드는 방법을 제안함
이 방법은 multi-task distillation와 memory rehearsal을 기반으로 하여, SAM과 CLIP의 서로 보완적인 시각적 능력을 결합하는 것을 목표로 함
SAM은 spatial understanding에 뛰어난 반면, CLIP은 이미지의 semantic understanding에 강점을 가짐
SAM-CLIP의 장점
- 원본 모델의 zero-shot 능력을 최대한 보존하면서 단일 비전 백본을 확보하여 edge device에 적합하게 설계됨
- SAM-CLIP은 원본 모델에 비해 보다 다양한 하위 작업에 활용할 수 있는 더 풍부한 표현을 생성함
- 두 모델의 능력을 결합하여 새로운 제로샷 기능이 향상됨
본 연구에서는 SAM-CLIP이 CLIP의 의미적 이해와 SAM의 localization knowledge를 결합하여 zero-shot semantic segmentation에서 SOTA를 달성했음을 보여줌
