
복잡성은 죽음이다. 개발자에게 생기를 앗아가며, 제품을 계획하고 제작하고 테스트하기 어렵게 만든다. - 레이 오지, 마이크로소프트 최고 기술 책임자(CTO)
도시를 세운다면?
도시가 돌아가는 이유는, 각 분야를 담당하는 팀이 있기 때문이다. 그리고 적절한 추상화와 모듈화 때문이다.
소프트웨어 팀도 도시처럼 구성한다. 하지만, 막상 팀이 제작하는 시스템은 비슷한 수준으로 관심사를 분리하거나 추상화를 이뤄내지 못한다. 이번 장에서는 시스템 수준에서도 높은 추상화 수준을 통해 깨끗함을 유지하는 방법을 살펴본다.
시스템 제작과 시스템 사용을 분리하라
설정 논리는 일반 실행 논리와 분리해야 모듈성이 높아진다.
제작과 사용은 아주 다르다. 건물을 지을 때와, 실제 사용할 때 환경과 사람들이 달라지는 것을 생각해보자. 마찬가지로 소프트웨어 시스템도 애플리케이션 객체를 제작하고, 의존성을 연결하는 준비과정과 런타임 로직을 분리해야 한다.
/* Code 1-1 */
public Service getService() {
if (service == null)
service = new MyServiceImpl(...); // 모든 상황에 적합한 객체인가..?
return service;
}시작 단계는 모든 애플리케이션이 풀어야 할 관심사이다. 이런 관심사로 표현되는 경우 이를 분리하는 것이 좋다. 위의 코드를 이를 분리하지 않은 예시이다. 이는 Lazy Initialization, Lazy Evaluation 이라는 기법이다. 다음의 장점을 가진다.
- 실제로 필요할 떄까지 객체를 생성하지 않으므로 불필요한 부하가 걸리지 않는다.
- 따라서 그만큼 애플리케이션 시작 시간이 짧아진다.
- 어떤 경우에도 null을 반환하지 않는다.
하지만, 다음의 단점을 갖는다.
getService메서드가 해당 객체의 사용여부에 관계없이MyServiceImpl생성자 인수에 명시적으로 의존한다.MyServiceImpl이 무거운 객체라면 단위테스트가 어려워진다.- 테스트 전용 객체(Test Double, mock object)로
service변수에 할당해야 한다. - service가 null일 때와 그렇지 않을 때도 테스트해야 한다. 이는 생성 로직과 사용 로직이 혼재되어 있기 때문에 발생한다.
- 결과적으로 작게나마 SRP을 준수하지 못하고 있다.
- 테스트 전용 객체(Test Double, mock object)로
- 가장 중요한 문제는 생성시
MyServiceImpl이 모든 상황에 적합한 객체인가하는 점이다.
초기화 지연을 한 번 정도 사용한다면 별로 심각한 문제가 아니다. 하지만 이런 설정 기법을 사용한다면, 애플리케이션에 설정 로직이 곧곧에 흩어져 있을 것이다. 모듈성은 저조하며 중복이 심하다. 설정 논리는 일반 실행 논리와 분리해야 모듈성이 높아진다.
Main 분리
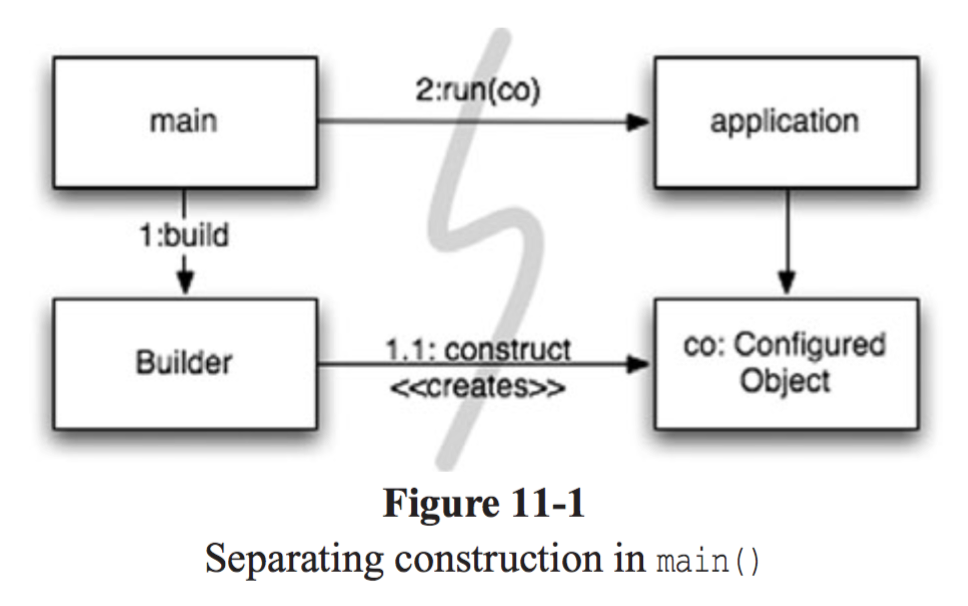
- main이 builder에게 객체 생성을 요청한다.
- application은 builder가 만든 객체를 사용한다.
이런 방식을 통해 application이 객체가 생성되는 과정을 전혀 모르면서도 사용할 수 있게 할 수 있다. application은 모든 객체가 생성되었다고 가정한다.
팩토리
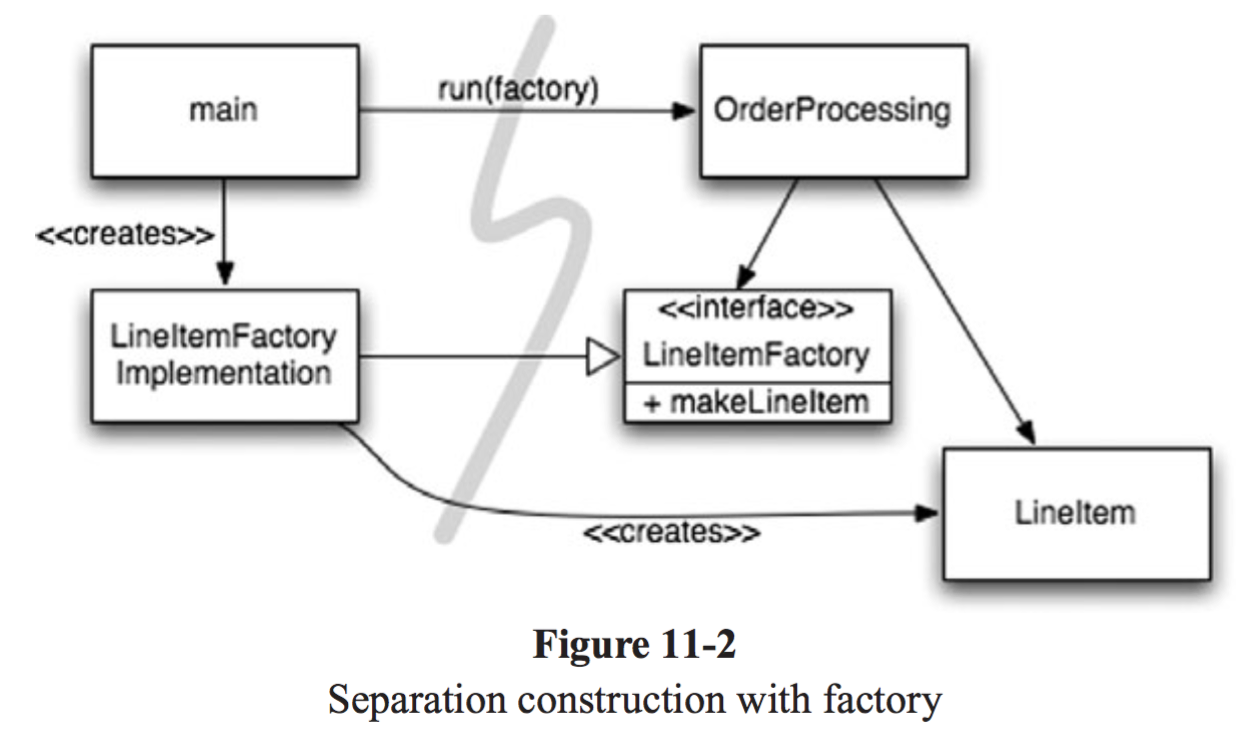
main 분리 처럼 아예 시스템 초기 생성 시점에 처리하는 방법도 있겠지만, 때떄로 application이 객체가 생성되는 시점을 결정할 필요도 있다. 예를 들어, 주문 처리 시스템에서 application이 LineItem 인스턴스를 생성하여 Order에 추가하는 것이 있겠다.
이런 경우 Abstract Factory 패턴을 사용한다. 그림을 보면, OrderProcessing은 LineItemFactory Interface에 요청한다. 실제 구현체는 main이 만든 LineItemFactoryImplementation이고, 이녀석이 LineItem을 생성한다.
의존성 주입
사용과 제작을 분리하는 강력한 매커니즘 하나가 의존성 주입(Dependency Injection)이다. DI는 제어 역전(Inversion of Control: IoC) 기법을 의존성 관리에 적용한 메커니즘이다.
제어 역전에서는 한 객체가 맡은 보조 책임을 새로운 객체에게 전적으로 떠넘긴다. 새로운 객체는 넘겨받은 책임만 맡기 때문에, SRP를 준수할 수 있게 된다. 이런 의존성 관리를 하는데 있어, 객체는 의존성 자체를 인스턴스로 만드는 책임은 지지 않는다. 즉, 의존성을 해결하는 전담 객체가 따로 있어야 한다는 말이다. 이런 초기 설정을 주입하는 과정은 시스템 전체에서 필요하기 때문에, main 루틴이나 특수 container(DI Container)를 사용한다.
/* Code 1-3 */
MyService myService = (MyService)(jndiContext.lookup(“NameOfMyService”));위 코드를 호출하는 쪽에서는 실제로 lookup 메서드가 무엇을(어떤 구현체를) 리턴하는지에 대해 관여하지 않으면서 의존성을 해결할 수 있다.
진정한 의존성 주입은 여기에서 한 단계 더 나아가 완전히 수동적인 형태를 지닌다. 의존성을 필요로 하는 객체가 직접 의존성을 해결(생성, 연결)하는 대신 생성자/setter 등을 통해 DI 컨테이너가 해당 의존성을 해결하도록 도와준다. (보통 우리가 많이 사용하는 방법)
확장
처음부터 미래의 요구사항까지 고려하여 시스템을 만든다는 믿음은 미신이다.
우리는 오늘 주어진 사용자 스토리에 맞춰 시스템을 구현해야 한다. 내일은 내일의 스토리에 맞춰 시스템을 조정하고 확장한다. 이것이 반복적이고 점진적인 Agile 방식이다. TDD, Refactoring으로 이어지는 깨긋한 코드는 코드 수준에서 시스템을 조정하고 확장하기 쉽게 만든다.
시스템 수준에서는 어떨까? 어떤식으로 관리하는 것이 시스템 전반에서 이를 관리하기 좋게 할 수 있을까? 답부터 말하자면, 관심사를 기준으로 나누어야 한다.
먼저, 스케일링을 고려하지 않은 구조에 대해 EJB1/EJB2를 예시로 알아보자.
- EJB에 대한 자세한 내용은 본 챕터와 관계가 없으므로 생략한다. (EJB에 대한 자세한 개요는 각주로 추가 바람)
- 우선 entity bean이란 관계 데이터(DB 테이블의 행)의 메모리상의 표현이라는 것만 알고 가자. (An entity bean is an in-memory representation of relational data, in other words, a table row.)
/* Code 2-1(Listing 11-1): An EJB2 local interface for a Bank EJB */
package com.example.banking;
import java.util.Collections;
import javax.ejb.*;
public interface BankLocal extends java.ejb.EJBLocalObject {
String getStreetAddr1() throws EJBException;
String getStreetAddr2() throws EJBException;
String getCity() throws EJBException;
String getState() throws EJBException;
String getZipCode() throws EJBException;
void setStreetAddr1(String street1) throws EJBException;
void setStreetAddr2(String street2) throws EJBException;
void setCity(String city) throws EJBException;
void setState(String state) throws EJBException;
void setZipCode(String zip) throws EJBException;
Collection getAccounts() throws EJBException;
void setAccounts(Collection accounts) throws EJBException;
void addAccount(AccountDTO accountDTO) throws EJBException;
}/* Code 2-2(Listing 11-2): The corresponding EJB2 Entity Bean Implementation */
package com.example.banking;
import java.util.Collections;
import javax.ejb.*;
public abstract class Bank implements javax.ejb.EntityBean {
// Business logic...
public abstract String getStreetAddr1();
public abstract String getStreetAddr2();
public abstract String getCity();
public abstract String getState();
public abstract String getZipCode();
public abstract void setStreetAddr1(String street1);
public abstract void setStreetAddr2(String street2);
public abstract void setCity(String city);
public abstract void setState(String state);
public abstract void setZipCode(String zip);
public abstract Collection getAccounts();
public abstract void setAccounts(Collection accounts);
public void addAccount(AccountDTO accountDTO) {
InitialContext context = new InitialContext();
AccountHomeLocal accountHome = context.lookup("AccountHomeLocal");
AccountLocal account = accountHome.create(accountDTO);
Collection accounts = getAccounts();
accounts.add(account);
}
// EJB 컨테이너 논리
public abstract void setId(Integer id);
public abstract Integer getId();
public Integer ejbCreate(Integer id) { ... }
public void ejbPostCreate(Integer id) { ... }
// 나머지도 구현해야 하지만 일반적으로 비어있다.
public void setEntityContext(EntityContext ctx) {}
public void unsetEntityContext() {}
public void ejbActivate() {}
public void ejbPassivate() {}
public void ejbLoad() {}
public void ejbStore() {}
public void ejbRemove() {}
}위 코드와 같은 전형적인 EJB2 객체 구조는 아래와 같은 문제점을 가지고 있다.
- 비지니스 로직이 EJB2 컨테이너에 타이트하게 연결되어 있다. Entity를 만들기 위해 컨테이너 타입을 subclass하고 필요한 lifecycle 메서드를 구현해야 한다.
- 실제로 사용되지 않을 테스트 객체의 작성을 위해 mock 객체를 만드는 데에도 무의미한 노력이 많이 든다. EJB2 구조가 아닌 다른 구조에서 재사용할 수 없는 컴포넌트를 작성해야 한다.
- OOP 또한 등한시되고 있다. 상속도 불가능하며 쓸데없는 DTO(Data Transfer Object)를 작성하게 만든다.
(이 부분 잘 이해하지 못했다..)
횡단(cross-cutting) 관심사
이론적으로는 독립된 형태로 구분될 수 있지만 실제로는 코드에 산재하기 쉬운 부분들
트랜잭션, 보안, 영속성, 로깅, 로그인 모듈 등은 application의 객체 경계를 넘나드는 경향이 있다. 모든 객체가 전반적으로 동일한 방식을 이용하게 만들어야 한다. 그렇지 않는다면 같은 동작을 수행하는 코드가 여기저기 흩어지게 된다. 이는 Aspect-Oriented Programming(AOP)과 같은 맥락이라 볼 수 있다.
자바 프록시
간단한 경우라면 자바 프록시가 적절한 솔루션일 것이다. 아래는 자바 프록시를 사용해 객체의 변경이 자동으로 persistant framework에 저장되는 구조에 대한 예시이다.
/* Code 3-1(Listing 11-3): JDK Proxy Example */
// Bank.java (suppressing package names...)
import java.utils.*;
// The abstraction of a bank.
public interface Bank {
Collection<Account> getAccounts();
void setAccounts(Collection<Account> accounts);
}
// BankImpl.java
import java.utils.*;
// The “Plain Old Java Object” (POJO) implementing the abstraction.
public class BankImpl implements Bank {
private List<Account> accounts;
public Collection<Account> getAccounts() {
return accounts;
}
public void setAccounts(Collection<Account> accounts) {
this.accounts = new ArrayList<Account>();
for (Account account: accounts) {
this.accounts.add(account);
}
}
}
// BankProxyHandler.java
import java.lang.reflect.*;
import java.util.*;
// “InvocationHandler” required by the proxy API.
public class BankProxyHandler implements InvocationHandler {
private Bank bank;
public BankHandler (Bank bank) {
this.bank = bank;
}
// Method defined in InvocationHandler
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if (methodName.equals("getAccounts")) {
bank.setAccounts(getAccountsFromDatabase());
return bank.getAccounts();
} else if (methodName.equals("setAccounts")) {
bank.setAccounts((Collection<Account>) args[0]);
setAccountsToDatabase(bank.getAccounts());
return null;
} else {
...
}
}
// Lots of details here:
protected Collection<Account> getAccountsFromDatabase() { ... }
protected void setAccountsToDatabase(Collection<Account> accounts) { ... }
}
// Somewhere else...
Bank bank = (Bank) Proxy.newProxyInstance(
Bank.class.getClassLoader(),
new Class[] { Bank.class },
new BankProxyHandler(new BankImpl())
);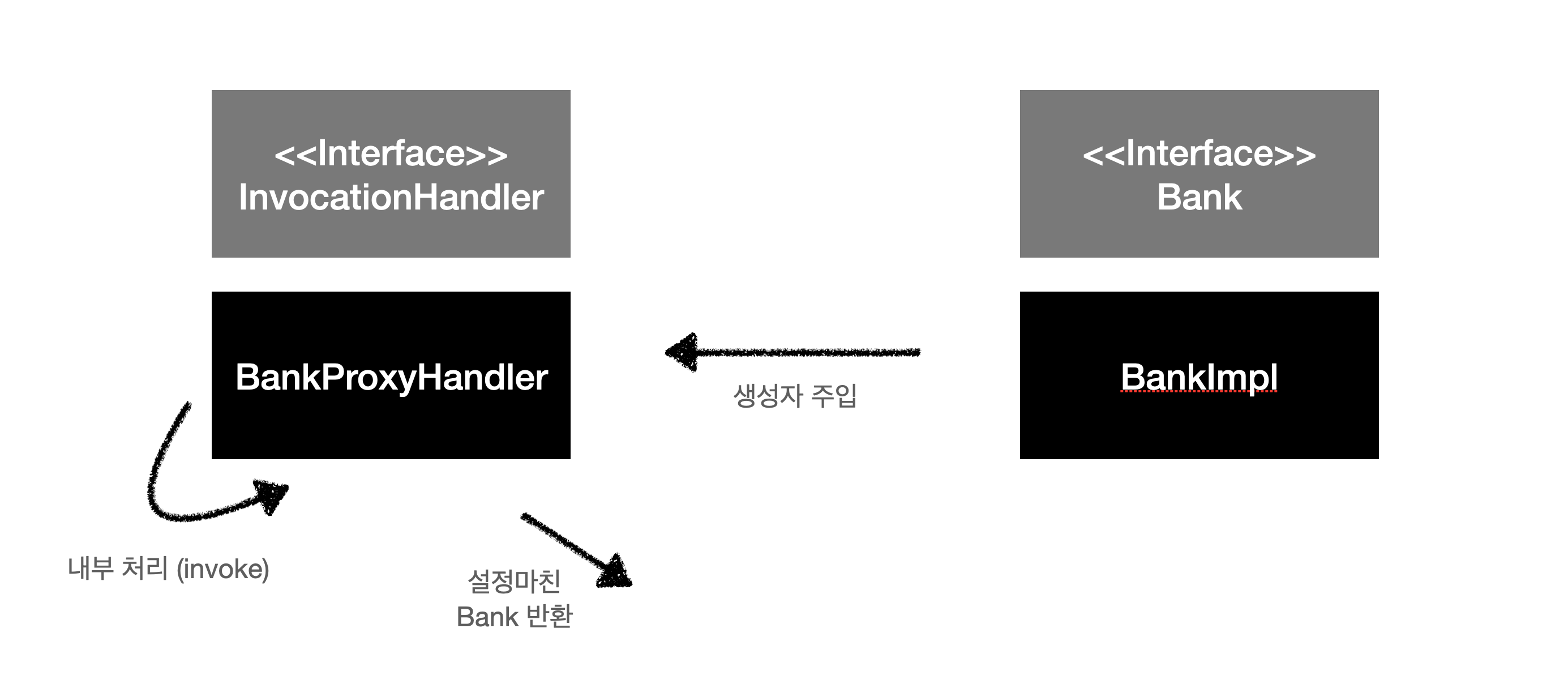
위 코드에 대한 간략한 설명은 아래와 같다.
- Java Proxy API를 위한 Bank 인터페이스를 작성한다.
- 위에서 작성한 Bank 인터페이스를 사용한 BankImpl(POJO aka Plane Old Java Object)를 구현한다. 여기에는 순수한 데이터만 들어가며 비지니스 로직은 포함되지 않는다.(모델과 로직의 분리)
- InvocationHandler를 구현하는 BankProxyHandler를 작성한다. 이 핸들러는 Java Reflection API를 이용해 Bank 인터페이스를 구현하는 객체들의 메서드콜을 가로챌 수 있으며 추가적인 로직을 삽입할 수 있다. 본 예제에서 비지니스 로직(persistant stack logic)은 이 곳에 들어간다.
- 마지막으로 코드의 마지막 블럭과 같이 BankImpl 객체를 BankProxyHandler에 할당, Bank 인터페이스를 사용해 프록시된 인터페이스를 사용해 모델과 로직이 분리된 코드를 작성할 수 있다. 이로써 모델과 로직의 분리를 이뤄낸 코드를 작성할 수 있게 되었다.
하지만 위와 같은 상대적으로 간단한 경우임에도 불구하고 결과적으로 추가적인 복잡한 코드가 생겼다. 또 시스템 단위로 실행 "지점"을 명시하는 메커니즘도 제공하지 않는다.
순수 자바 AOP 프레임워크
위 Java Proxy API의 단점들은 Spring, JBoss와 같은 순수 자바 AOP 프레임워크를 통해 해결할 수 있다. 예를 들어 Spring에서는 비지니스 로직을 POJO로 작성해 자신이 속한 도메인에 집중하게 한다. 결과적으로 의존성은 줄어들고 테스트 작성에 필요한 고민도 줄어든다. 이러한 심플함은 user story의 구현과 유지보수, 확장 또한 간편하게 만들어 준다.
예시를 통해 Spring 프레임워크의 동작 방식에 대해 확인해 보자.
/* Code 3-2(Listing 11-4): Spring 2.X configuration file */
<beans>
...
<bean id="appDataSource"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close"
p:driverClassName="com.mysql.jdbc.Driver"
p:url="jdbc:mysql://localhost:3306/mydb"
p:username="me"/>
<bean id="bankDataAccessObject"
class="com.example.banking.persistence.BankDataAccessObject"
p:dataSource-ref="appDataSource"/>
<bean id="bank"
class="com.example.banking.model.Bank"
p:dataAccessObject-ref="bankDataAccessObject"/>
...
</beans>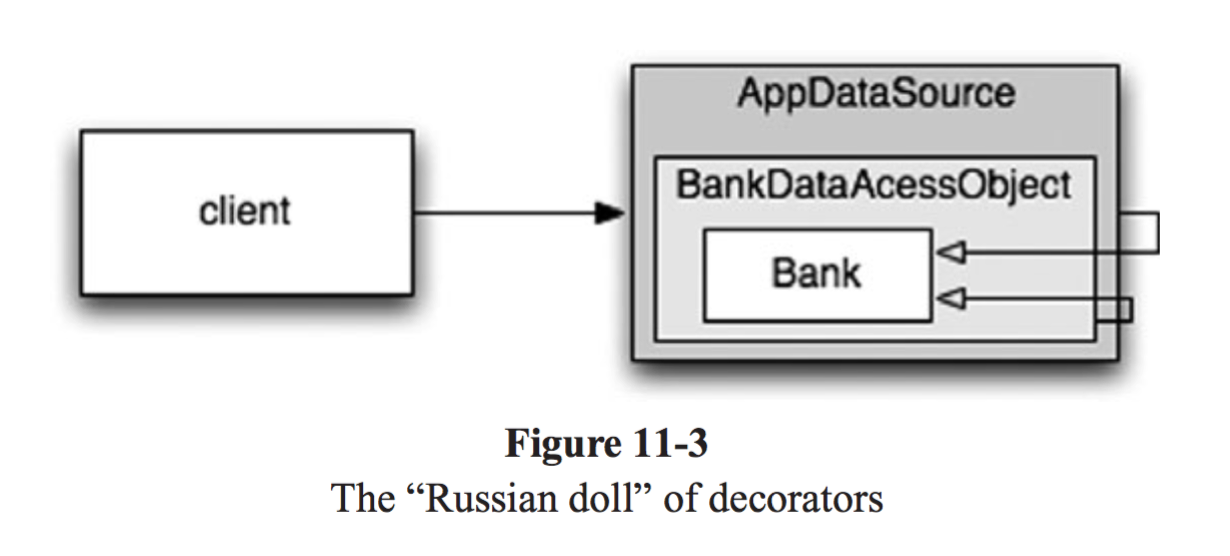
Bank객체는 BankDataAccessObject가, BankDataAccessObject는 BankDataSource가 감싸 프록시하는 구조로 되어 각각의 bean들이 "러시안 인형"의 한 부분처럼 구성되었다. 클라이언트는 Bank에 접근하고 있다고 생각하지만 사실은 가장 바깥의 BankDataSource에 접근하고 있는 것이다.
/* Code 3-3: Code 3-2의 활용법 */
XmlBeanFactory bf = new XmlBeanFactory(new ClassPathResource("app.xml", getClass()));
Bank bank = (Bank) bf.getBean("bank");위와 같이 최소한의 Spring-specific한 코드만 작성하면 되므로 프레임워크와 "거의" decouple된 어플리케이션을 작성할 수 있다.
구조 정의를 위한 xml은 다소 장황하고 읽기 힘들 수는 있지만 Java Proxy보다는 훨씬 간결하다. 이 개념은 아래에 설명할 EJB3의 구조 개편에 큰 영향을 미쳤다. EJB3은 xml와 Java annotation을 사용해 cross-cutting concerns를 정의하고 서포트하게 되었다.
/* Code 3-4(Listing 11-5): An EBJ3 Bank EJB */
package com.example.banking.model;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.Collection;
@Entity
@Table(name = "BANKS")
public class Bank implements java.io.Serializable {
@Id @GeneratedValue(strategy=GenerationType.AUTO)
private int id;
@Embeddable // An object “inlined” in Bank’s DB row
public class Address {
protected String streetAddr1;
protected String streetAddr2;
protected String city;
protected String state;
protected String zipCode;
}
@Embedded
private Address address;
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER, mappedBy="bank")
private Collection<Account> accounts = new ArrayList<Account>();
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public void addAccount(Account account) {
account.setBank(this);
accounts.add(account);
}
public Collection<Account> getAccounts() {
return accounts;
}
public void setAccounts(Collection<Account> accounts) {
this.accounts = accounts;
}
}위와 같이 EJB3은 EJB2 보다 훨씬 간결한 코드로 작성할 수 있게 되었다. 몇몇 세부 속성들은 annotation으로 클래스 내에 정의되어 있지만 annotation을 벗어나진 않기 때문에 이전보다 더 깨끗하고 명료한 코드를 산출하며 그로 인해 유지보수, 테스트하기 편한 장점을 갖게 되었다.
AspectJ 관점
AspectJ는 AOP를 실현하기 위한 full-featured tool이라 일컬어진다. 8~90%의 경우에는 Spring AOP와 JBoss AOP로도 충분하지만 AspectJ는 훨씬 강력한 수준의 AOP를 지원한다. 다만 이를 사용하기 위해 새로운 툴, 언어 구조, 관습적인 코드를 익혀야 한다는 단점도 존재한다.(최근 소개된 "annotation-form AspectJ"로 인해 적용에 필요한 노력은 많이 줄어들었다고 한다.)
AOP에 대한 더 자세한 내용은 [AspectJ], [Colyer], [Spring]를 참조하기 바란다.
테스트 주도 시스템 아키텍처 구축
BDUF(Big Design Up Front: 앞으로 벌어질 모든 사항을 설계하는 기법)은 해롭다. 처음에 쏟아 부은 노력을 버리지 않으려는 심리적 저항, 그리고 처음 선택한 아키텍처가 향후 사고 방식에 미치는 영향으로 변경을 쉽사리 수용하지 못하게 된다.
관점, 혹은 관심사를 기반으로 분리하는 방식은 단순한 아키텍처에서 복잡한 아키텍처로 키워갈 수 있는 시작점이 될 수 있다. 프로젝트의 질반적인 범위, 목표, 일정, 일반적인 구조에 대해 생각하되, 변하는 황경에 대처해 진로를 변경할 능력도 반드시 유지해야 한다. 즉, 너무 많은 미래를 바라보고 과도하게 넣은 API는 오히려 관심사를 분리하지 못하고, 사용자 스토리에 집중하지 못하는 결과를 초래할 수 있다는 말이다.
이상적인 시스템 아키텍쳐는 각각 POJO로 만들어진 모듈화된 관심 분야 영역(modularized domains of concern)으로 이루어져야 한다. 다른 영역끼리는 Aspect의 개념을 사용해 최소한의 간섭으로 통합되어야 한다. 이러한 아키텍쳐는 코드와 마찬가지로 test-driven될 수 있다.
의사 결정을 최적화하라
모듈을 나누고 관심사를 분리하면 지엽적인 관리와 결정이 가능해진다. 때때로 가능한 마지막 순간까지 결정을 미루는 방법이 최선이라는 것을 잊지 말자.
모듈화된 관심 분야로 이루어진 POJO 시스템의 (변화에 대한)민첩함은 가장 최신의 정보를 가지고 적시에 최적의 선택을 할 수 있게 도와준다. 결정에 필요한 복잡도 또한 경감된다.
명백한 가치가 있을 때 표준을 현명하게 사용하라
많은 소프트웨어 팀들은 훨씬 가볍고 직관적인 디자인이 가능했음에도 불구하고 그저 표준이라는 이유만으로 EJB2 구조를 사용했다. 표준에 심취해 "고객을 위한 가치 창출"이라는 목표를 잃어 버렸기 때문이다.
표준은 아이디어와 컴포넌트의 재사용, 관련 전문가 채용, 좋은 아이디어의 캡슐화, 컴포넌트들의 연결을 쉽게 도와 준다. 하지만 종종 표준을 만드는 데에 드는 시간은 납품 기한을 맞추기 어렵게 만들고, 혹은 최초에 제공하려던 기능과 동떨어지게 되기도 한다.
시스템은 도메인 특화 언어가 필요하다
좋은 DSL은 도메인 영역의 개념과 실제 구현될 코드 사이의 "소통의 간극"을 줄여 도메인 영역을 코드 구현으로 번역하는 데에 오역을 줄여준다. DSL을 효율적으로 사용하면 코드 덩어리와 디자인 패턴의 추상도를 높여 주며 그에 따라 코드의 의도를 적절한 추상화 레벨에서 표현할 수 있게 해준다.
DSL은 "모든 단계에서의 추상화"와 "모든 도메인의 POJO화"를 고차원적 규칙과 저차원적 디테일 전반에 걸쳐 도와 준다.
결론
시스템 역시 깨끗해야 한다.
침략적인(invasive) 아키텍쳐는 도메인 로직에 피해를 주고 신속성에도 영향을 준다. 도메인 로직이 모호해지면 버그는 숨기 쉬워지고 기능 구현은 어려워 진다. 신속성이 침해되면 생산성이 저해되고 TDD로 인한 이득 또한 얻을 수 없다.
의도는 모든 레벨의 추상화에서 명확해야 한다. 이는 각각의 concern들을 POJO로 작성된 코드와 aspect-like 메커니즘을 통해 구성할 때 비로소 실현될 수 있다.
당신이 시스템을 디자인하든 독자적인 모듈을 디자인하든, 동작하는 범위에서 가장 간단한 것을 사용하는 것을 잊어서는 안된다.
Reference
