🎯 오늘의 목표
- SQLite 데이터베이스에서 SQL을 사용하여 데이터를 전처리하고
- Python을 활용해 필요한 데이터를 시각화하기!
👩🏻💻 오늘 배운 것
✅ SQLite 활용법
✅ 파이썬에서 SQL연결, 테이블 생성하기
✅ 시각화 스킬업(plt.grid(True), plt.tight_layout())
✅pd.to_datetime으로 날짜타입으로 바꿔 그래프 정리해주기
✅ 변동성 분석(절대값으로!)
✅ `LAG(윈도우함수, 이전행을 가져옴)
✅ 자기상관성 분석(np 이용해 자기상관계수 구하기, 그래프 그리기)
SQLite란?
장점
- 별도의 서버 프로세스 없이 SQL 데이터베이스 엔진을 제공
- 모바일 애플리케이션, 소규모 프로젝트에 적합
- 접근이 용이하고 관리가 간편함
단점
- 대용량 데이터베이스나 고성능을 요구하는 애플리케이션에서는 부적합
- 동시성 처리가 제한적
MySQL과 비교
- MySQL은 서버 기반의 DBMS로, 대규모 데이터베이스와 고성능을 요구하는 애플리케이션에 적합
- 고급 기능과 보안, 복잡한 트랜잭션 처리 제공
- 단, 설치와 관리가 복잡하며 리소스 사용량이 더 높음
✅ 규모로 따지면, Oracle > MySQL > SQLite
1. 라이브러리 임포트
import pandas as pd
import sqlite3. #SQLite를 사용하기 위한 파이썬 내장 라이브러리
import matplotlib.pyplot as plt2. 데이터 로드 및 SQLite 데이터베이스로 변환
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-min-temperatures.csv'
data = pd.read_csv(url)
conn = sqlite3.connect('daily_temperatures.db')
data.to_sql('temperatures', conn, if_exists = 'replace', index = False)✅ sql 연결, 테이블 생성
conn = sqlite3.connect('daily_temperatures.db')
- sqlite에 있는 daily_temperatures.db에 연결
- 해당 파일이 없다면 새로 생성하고, 존재하는 경우 파일에 연결
.to_sql
- 'temperatures'라는 이름의 테이블로 데이터를 SQLite에 저장
if_exists = replace
- 해당 테이블이 이미 존재하는 경우, 기존 테이블을 대체
index = False
- dataframe의 인덱스를 테이블에 저장하지 않겠다
3. SQL 쿼리실행: 연도별 최대 기온
yearly_max_temp_query = """
SELECT strftime('%Y', Date) as Year,
max(Temp) as MaxTemp
FROM temperatures
GROUP BY Year
ORDER BY Year ;
"""
yearly_max_temp = pd.read_sql_query(yearly_max_temp_quaery)✅ 파이썬에서 """사이에 SQL 쿼리문을 작성하여 전처리 가능
4. 데이터 시각화 : 연도별 최대 기온
plt.figure(figsize = (12, 6))
plt.plot(yearly_max_temp['Year'], yearly_max_temp['MaxTemp'], marker = 'o', color = 'darkblue', linestyle = '--')
plt.title('Yearly Maximum Temperature')
plt.xlabel('Year')
plt.ylabel('Max Temperature (°C)')
plt.xticks(rotation=45)
plt.grid(True)
plt.tight_layout()
plt.show()✅ 시각화 스킬 업
plt.grid(True) : 그리드를 표시해 포인트 위치를 잘 식별
plt.tight_layout(): 그래프 레이아웃 자동 조정, 이쁘게
5. SQL 쿼리 실행 : 월별 평균 기온
monthly_avg_temp_query = """
select strftime('%Y-%m', Date) as YearMonth,
avg(Temp) as AvgTemp
from temperatures
group by YearMonth
order by YearMonth ;
"""
monthly_avg_temp = pd.read_sql_query(monthly_avg_temp_query, conn)6. 데이터 시각화 : 월별 평균 기온
plt.figure(figsize=(15, 7))
plt.plot(monthly_avg_temp['YearMonth'], monthly_avg_temp['AvgTemp'], marker='o', linestyle='-', color='coral')
plt.title('Monthly Average Temperature')
plt.xlabel('Year-Month')
plt.ylabel('Average Temperature (°C)')
plt.xticks(rotation=45)
plt.grid(True)
plt.tight_layout()
plt.show()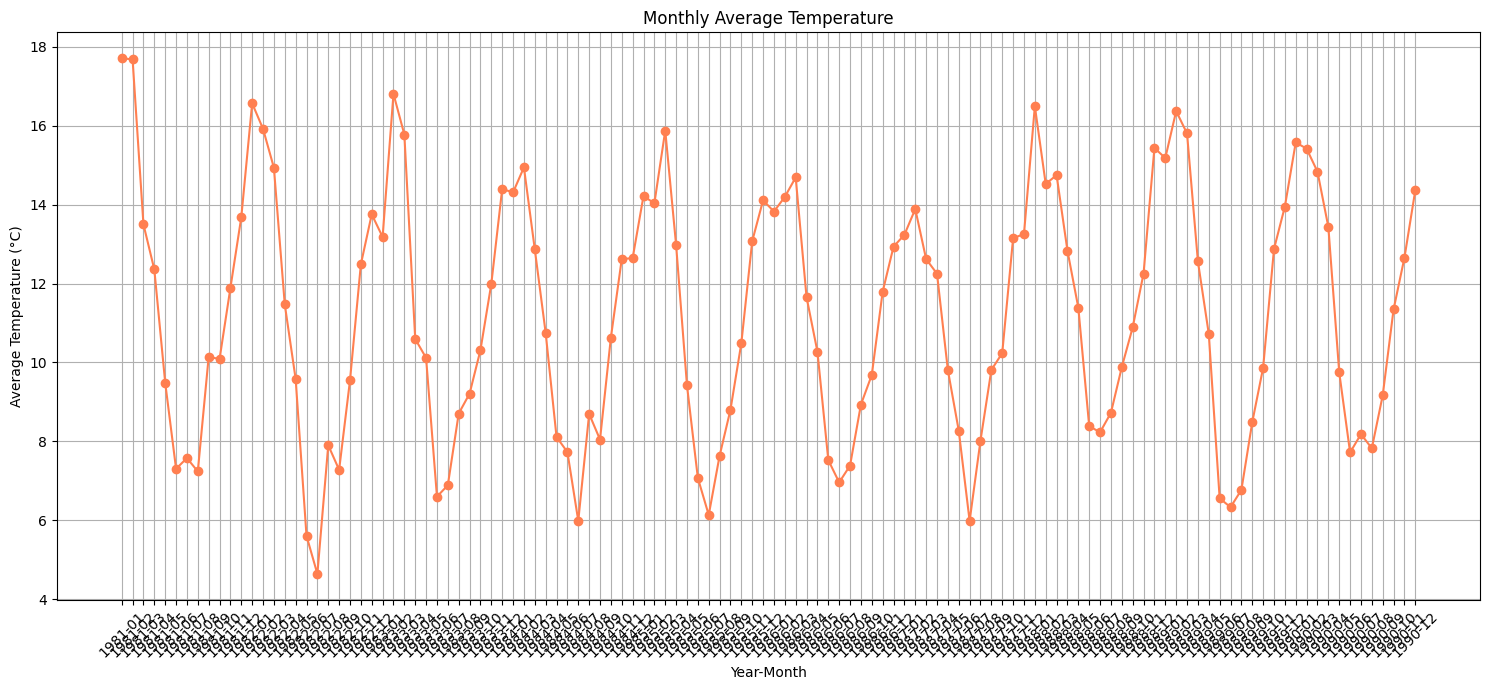
이러면 x축 눈금이 너무 많아 보기 안좋다.
pd.to_datetime으로 시각화 수정하기
plt.figure(figsize=(15, 7))
plt.plot(pd.to_datetime(monthly_avg_temp['YearMonth']), monthly_avg_temp['AvgTemp'], marker='o', linestyle='-', color='coral')
plt.title('Monthly Average Temperature')
plt.xlabel('Year-Month')
plt.ylabel('Average Temperature (°C)')
plt.xticks(rotation=45)
plt.grid(True)
plt.tight_layout()
plt.show()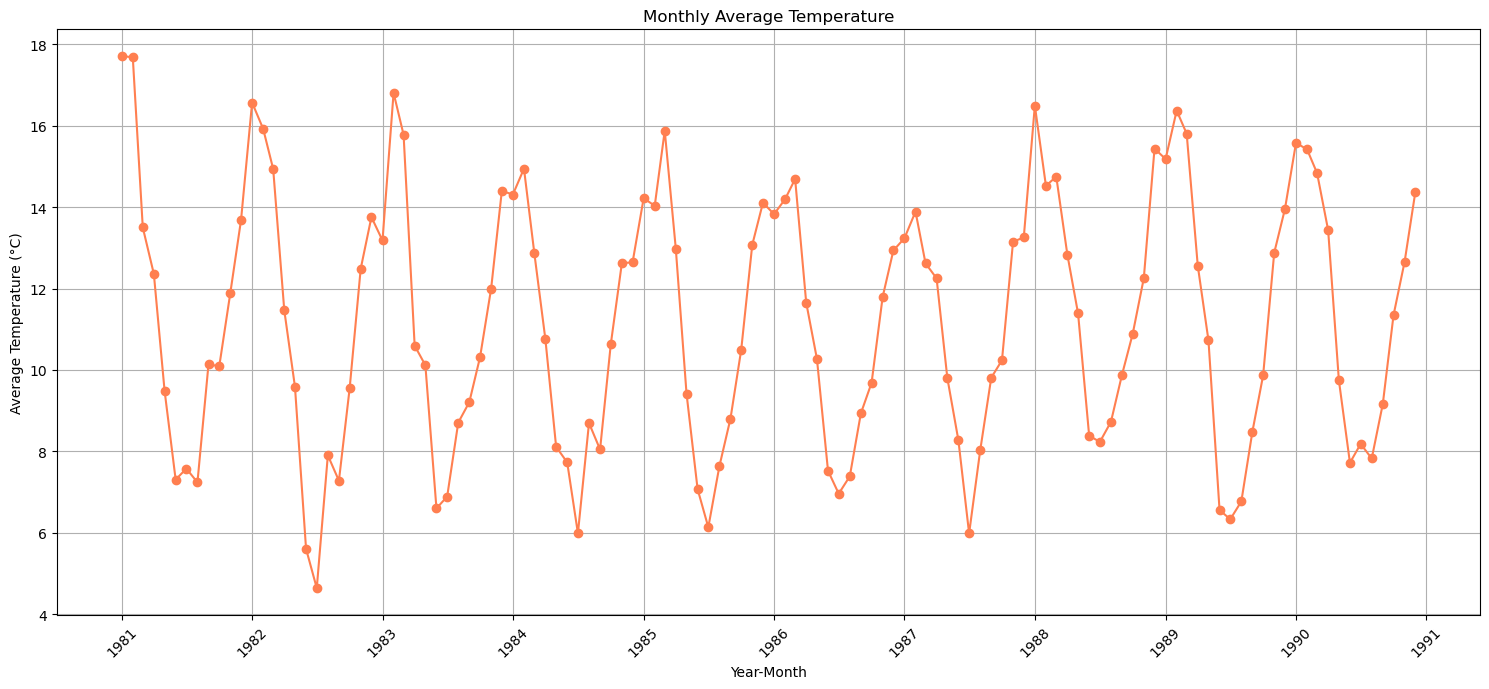
7. 변동성 분석
- 변동성 분석은 기온데이터의 일일변동폭을 측정하여 기온이 얼마나 변동성이 큰지 파악하는 분석
- 특정기간 동안 기온 변화의 안정성을 평가할 수 있다.
query = """
select Date,
ABS(Temp - LAG(Temp,1) over (order by Date)) as DailyChange
from temperatures
"""
daily_change = pd.read_sql_query(query, conn)# 일별 기온 변동성 시각화
plt.figure(figsize=(14, 7))
plt.plot(pd.DataFrame(daily_change['Date']), daily_change['DailyChange'], color='blue', alpha=0.5)
plt.title('Daily Temperature Change')
plt.xlabel('Date')
plt.ylabel('Temperature Change (°C)')
plt.show()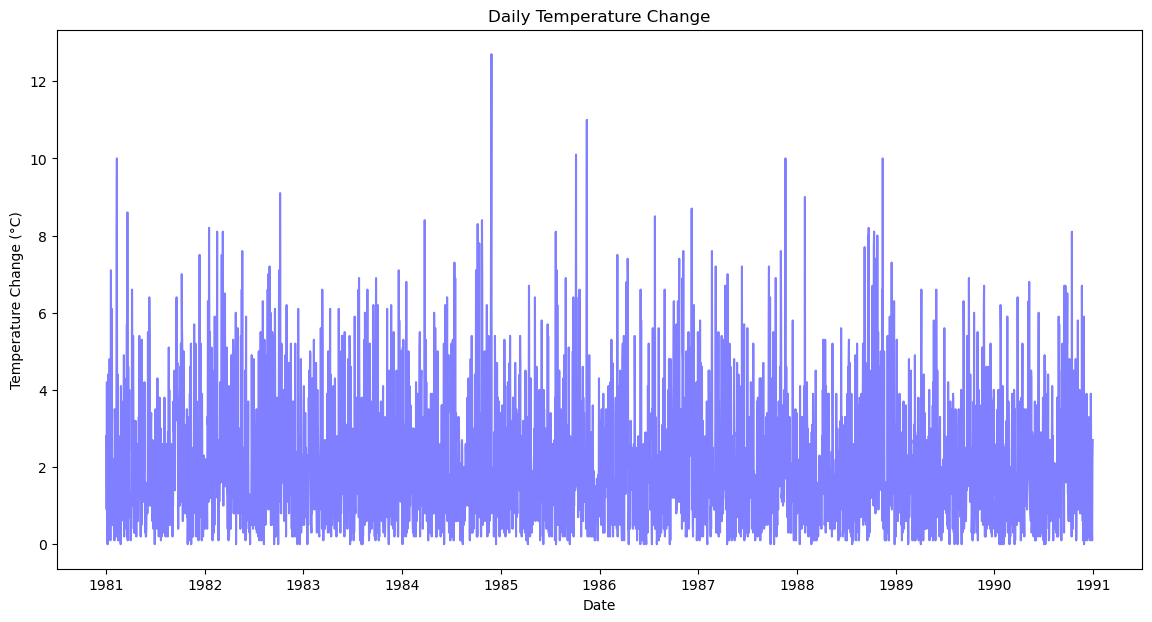
✅ 변동성 분석 : 얼마나 변동성이 큰지 파악(절대값 사용)
✅ LAG: 이전의 행을 가져옴
오늘의 킥! - 자기상관성 분석
- 자기상관성 분석?
시계열 데이터에서 한 시점의 데이터가 이전 시점의 데이터와 어떤 관계를 가지는지 분석하는 방법. 시간의 흐름에 따른 데이터의 패턴 파악하는데 유용함.
import numpy as np
query = """
select Date,
Temp,
LAG(Temp, 1) over (order by Date)as PrevDayTemp
from temperatures
order by Date
"""
temp_data = pd.to_sql_query(query, conn)
temp_data.dropna(inplace = True)
temp_data['TempChange'] = temp_data['Temperature'] - temp_data['PrevDayTemp']
temp_data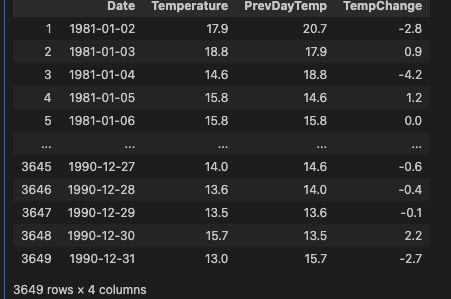
자기상관성 분석 그래프
correlation = np.corrcoef(temp_data['TempChange'][1:], temp_data['TempChange'][:-1])[0, 1]
print(f'1일차 기온 변화의 자기상관계수 {correlation : 2.f}')
pd.plotting.autocorrelation_plot(temp_data['Temperature'])
plt.title['Autocorrelation of Daily Temperature']
plt.show()
1일 시차 기온 변화의 자기상관 계수: -0.18
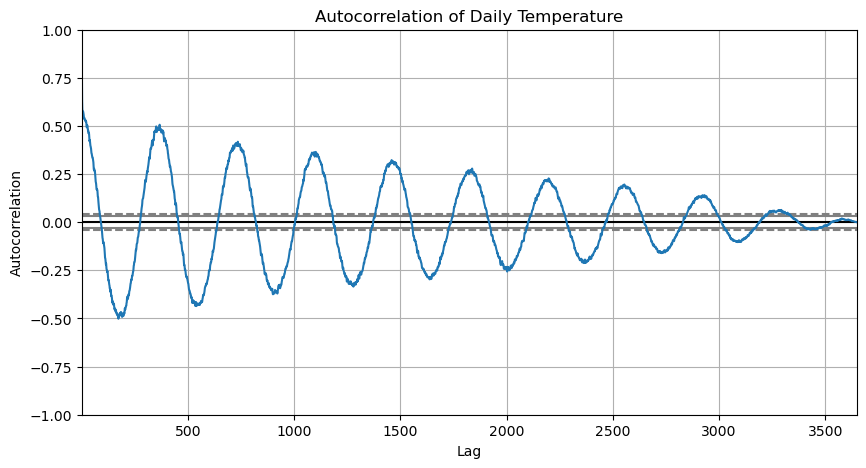
✅ 자기상관성 계수는 -1에서 1 사이
✅ 자기상관성 계수 그래프 : pd.plotting.autocorrelation_plot
✅ 첫번째와 마지막 요소 제외(인덱싱) 이유 : 이전값과 현재값의 쌍을 맞춰 데이터 포인트의 불균형을 줄이고 신뢰성을 높일 수 있음
✅[0, 1]은 상관 계수행렬의 인덱싱. 상관계수 행렬의 [i, j]위치의 값은 i번째 배열과 j번째 배열의 상관관계를 나타냄. [0,1]은 상관계수 행렬에 인덱싱하여 두 배열간의 상관계수를 추출함.
