꾸역꾸역 머신러닝 열심히 배웠는데
튜터링에서 기가막힌 라이브러리를 알게 되었다.
저코드로 수십개의 머신러닝 모델을 돌릴 수 있는 pycaret
👩🏻💻 Pycaret 메소드
setup(): 데이터 전처리compare_models(): 여러 회귀모델을 훈련하여 비교tune_model(): 오토튜닝, 자동으로 모델 최적화plot_model(): pycaret 시각화(잔차, 오차)predict_model(): 모델의 예측성능 평가
pycaret?
Python에서 사용할 수 있는 저코드 머신러닝 라이브러리
데이터 전저리, 모델선택, 최적화 및 배포까지 한번에 해주는 치트키pycaret 용도
- 베이스라인 모델을 정할때 활용
- 머신러닝의 통상 과정들을 한번에 스킵할 수 있다.
- 데이터 클리닝: 결측치 처리, 이상치 감지 및 제거
- 특성 공학: 새로운 특성 생성 및 변환, 비선형 관계를 갖는 변수 변환
- 데이터 분할: 훈련 데이터와 테스트 데이터로 분할
- 정규화/표준화: 데이터의 스케일 조정
- 인코딩: 범주형 변수를 수치형 변수로 변환
- 다중 공선성 확인: 변수 간의 고도의 상관관계 분석 및 처리
- 특성 선택: 중요한 특성 선택 및 불필요한 특성 제거
# pycaret 설치
! pip install pycaret full
# 데이터 불러오기
from pycaret.dataset import get_data
boston_df = get_data('boston')
# pycaret 회귀분석 라이브러리 불러오기
from pycaret.regression import *
# pycaret 한번에 전처리하기
s = setup(data = boston_df,
target = 'medv', #예측 대상변수
session_id = 123, #실험의 재현성과 관리를 위위함
normalize = True, #정규화
transformation = True, #데이터변환(정규분포를 더 정규분포와 유사하게)
remove_outliers = True, #이상치제거
remove_multicollinearity = True, #다중공선성제거
multicollinearity_threshold = 0.9, #다중공선성제거 임계치
feature_selection = True) #특성선택(불필요한 특성 제거)
전처리된 결과를 한번에 확인할 수 있다.
데이터분리, 결측치 제거, 이상치제거, 정규화 등 어떻게 처리되었는지 확인
#전처리된 trian data 확인
s.train_transformed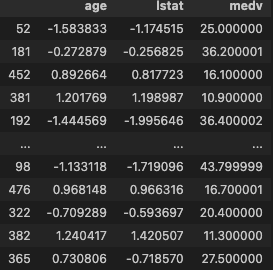
선택된 변수는 age, lstat
# 머신러닝 모델 비교
best_model = compare_models()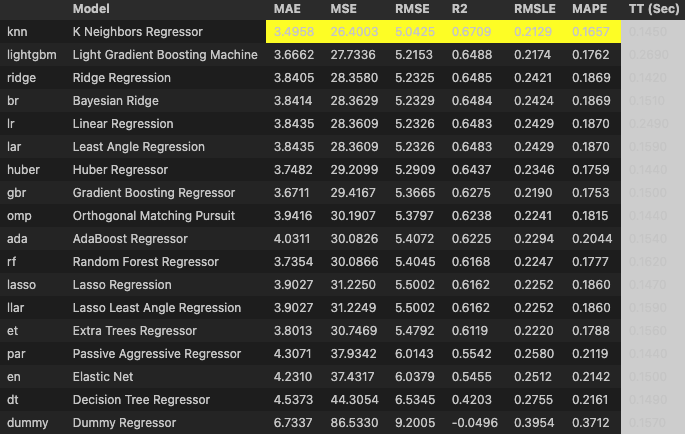
정말 신세계라 할 수 있다. 위 모델을 전부 비교해주고 가장 베스트 알아서 골라준다.
베스트 모델은 knn
여기서 끝이 아니다. 설명력을 더 높일 수 있게 모델을 tune할 수 있다.
#자동 하이퍼파라미터 튜닝(오토튜닝)
tuned_model = tune_model(best_model, optimize = 'R2')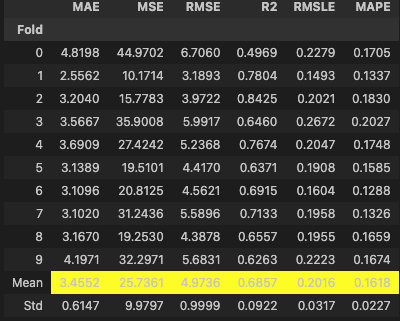
R2 : 0.6709 -> 0.6857
모델 성능 최적화도 쉽게 할 수 있다.
#모델 분석 시각화
import matplotlib.pyplot as plt
#원본 histogram
plt.hist(boston_df['medv'], bins = 100)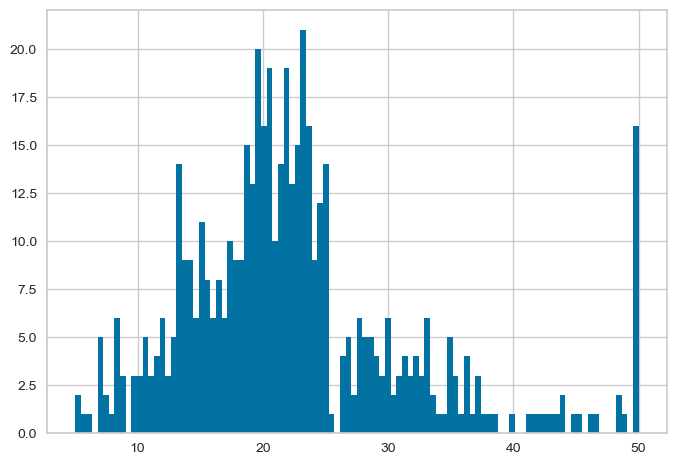
plot_model(tuned_model, plot = 'residuals')
plt.show()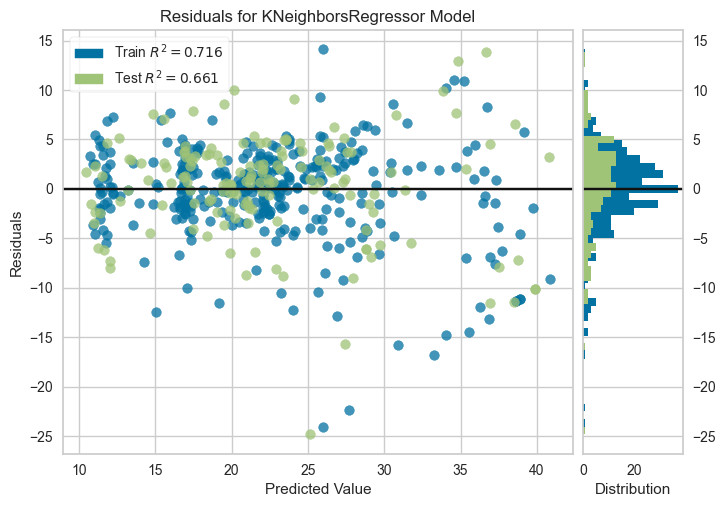
잔차그래프는 예측값과 실제값의 차이를 보여준다.
잔차가 무작위로 분포하고 특정 패턴이 없어야 모델이 잘 학습했다고 할 수 있다.
# 오차그래프
plot_model(tuned_model, plot = 'error')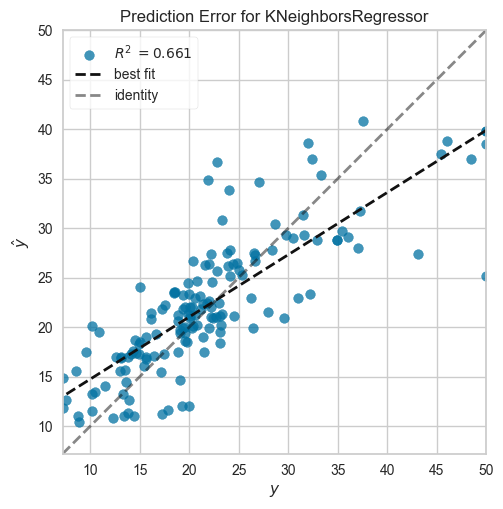
오차그래프는 모델의 예측 오차를 시각화 한다.
일반적으로 예측값 대비 실제값의 오차를 보여주고, 잔차 분포의 특성을 파악하는데 도움된다.
#모델 최종평가
new_boston_df = boston_df
final_prediction = predict_model(tuned_model, data = new_boston_df)
knn접근법으로 설명력이 0.7039까지 상승했다.
다만, pycaret 모델을 바로 사용하는게 아니라 참고하여 모델을 선정하고 설명력의 기준을 잡으면 되겠다.

잘 하고 있는겨?