01. 대량 데이터에 따른 성능
1. 테이블 분할 개요
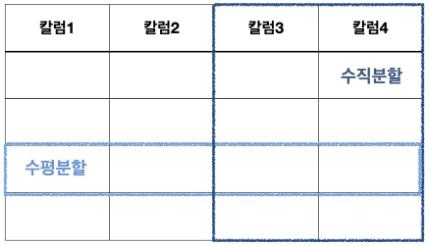
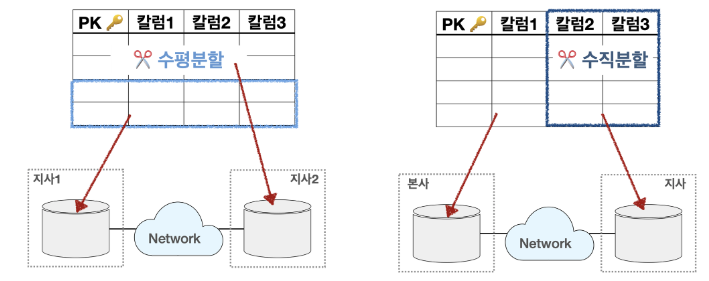
많은 트랜잭션 때문에 저하되는 테이블 구조는 수평/푸직 분할 설계를 통해 예방할 수 있다.수평분할
- 행 단위로 요소를 분할하여 디스크의 입/출력 비용을 감소시키는 방법
- 1년치의 데이터가 대용량인 경우, 월별로 분할하여 저장
수직분할
- 컬럼 단위로 요소를 분할하여 디스크의 입/출력 비용을 감소시키는 방법
- 고객의 생년월일, 주소 등의 개인정보와 취미, 특기 등의 기타 정보를 별도로 저장
성능저하현상
수평/수직 분할을 통해 성능 저하를 예방한다 해도 대용량 데이터를 다루는 과정에서 성능 저하는 일어날 수 있다.
- 로우 체이닝
- 행 데이터가 너무 길어서 데이터 블록 하나에 데이터가 모두 저장되지 않고 2개 이상의 블록에 걸쳐서 하나의 행이 저장되는 형태
- 하나의 행을 읽을 때 2개 이상의 데이터 블록을 일게 되는데, 절대적으로 읽어야 하는 데이터가 증거하기 때무네 성능 저하에 직접적인 영향을 준다.
- 로우 마이그레이션
- 수정이 발생하면 수정된 데이터를 해당 데이터 블록에 저장하지 못하고, 다른 블록의 빈 공간을 찾아내서 저장하는 방식으로 처리됨
- 마찬가지로 절대적으로 읽어야 하는 데이터 블록의 수가 늘어나 성능 저하에 영향을 줌
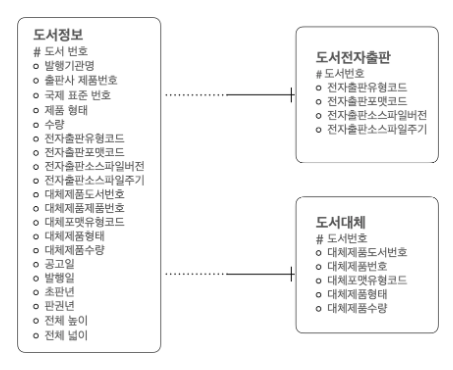
2. 테이블 수직 분할
- 컬럼의 수가 매우 많을 때, 특정한 컬럼만 자주 불러오는지만 쿼리문을 실행할 때마다 모든 컬럼을 읽게 된다. -> 불필요한 입/출력이 많아짐 -> 컬럼을 나눔
- 대체도서에 대한 정보를 조회하고 싶으면 도서대체 테이블에서 조회하고, 전자출판 정보를 조회하고 싶으면 전자출판 테이블을 조회하면 됨
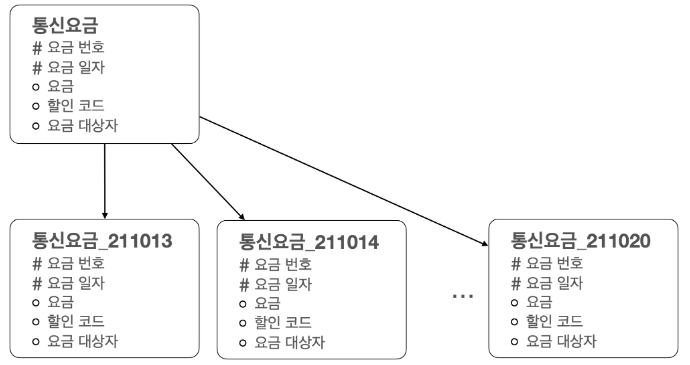
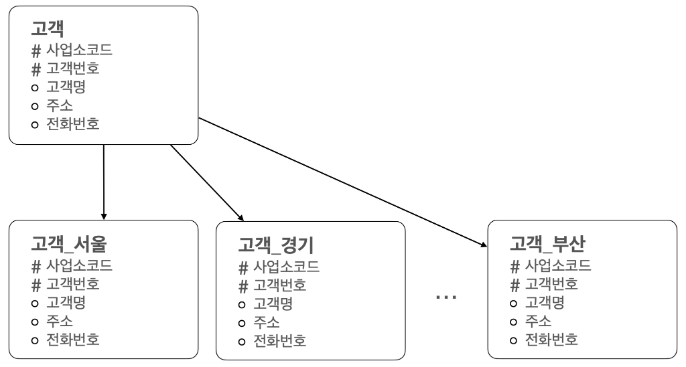
3. 테이블 수평분할(범위/목록)
범위분할(Range Partition)
- 특정 기간을 중심으로 분할하는 것을 범위 파티셔닝이라고 한다.
- 데이터 보관 주기에 따라 테이블의 데이터를 쉽게 지울 수 있어 보관 주기에 따른 테이블 관리가 용이하다.
목록분할(List Partition)
- 경기권 고객만을 대상으로 데이터를 조회할 경우 '고객_경기' 테이블의 파티션만 조회하면
해시분할(Hash Partition)
- 지정된 HASH 조건에 따라 해싱 알고리즘을 적용하여 테이블을 분리
- 데이터의 관리보다는 성능 향상에 목적이 있음
- 장점
- 알고리즘에 의해 데이터가 분리되어 입력되기 때문에 기존 1개의 테이블에만 데이터를 입력하는 방식보다 부하가 줄어든다
- 특정 파티션에 데이터가 집중될 가능성이 있는 범위 분할의 단점을 보완할 수 있음
- 데이터 처리가 많아지는 경우 경합을 막을 수 있음
- 단점
- 데이터 보관 주기에 따라 쉽게 삭제하는 기능을 제공하기 어렵다.
- 특정 데이터가 어떤 파티션에 저장되는지 정확하게 예측하기 어렵다.
합성분할(Composite Patition)
위의 3개의 분할 방식을 섞는 방법을 의미하는데, 범위 분할로 분할 이후 다시 해시 함수를 적용해 분할하는 방식 등을 말한다.
4. 테이블 수평/수직 분할 절차
- 데이터베이스 모델링 진행
- 데이터베이스 테이블 용량 산정
- 데이터 처리 과정에서의 트랜잭션 패턴 분석
- 데이터 처리 과정이 컬럼과 로우 중 어디에 집중되는지 분석하고 집중된 부분의 테이블 파티셔닝
02. 데이터베이스의 구조와 성능
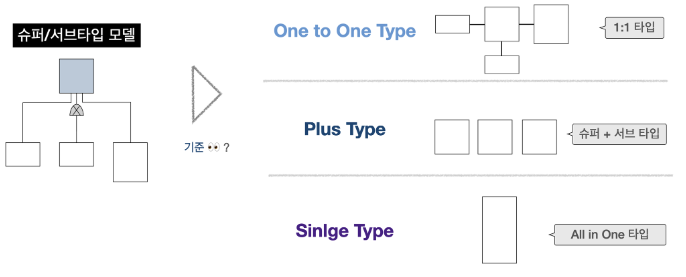
1. 슈퍼타입/서브타입
슈퍼타입/서브타입이란?
- 업무를 구성하는 데이터의 특징을 공통점과 차이점으로 나누어 표현한 직관적 모델링
- 슈퍼타입 : 공통적인 속성
- 서브타입 : 자신만의 속성
슈퍼타입/서브타입 모델 변환 방법
- 슈퍼타입(Single/All in One)
- 슈퍼/서브 타입 모델을 하나의 테이블로 변환
- 고객 테이블을 싱글 테이블로 구성
- 서브타입(Plus/Super+Sub)
- 슈퍼타입과 서브타입 테이블로 변환
- 슈퍼 엔터티에 있던 컬럼을 공통적으로 가짐
- 개별타입(OneToOne + 1:1)
- 슈퍼/서브 타입을 슈퍼타입과 서브타입 각 개별 테이블로 변환
- 슈퍼/서브 테이블 모두를 생성함
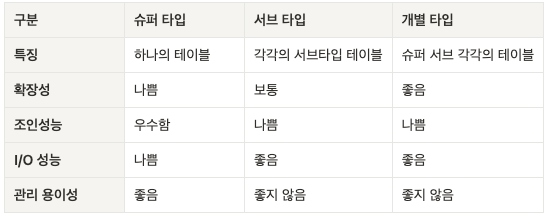
슈퍼타입/서브타입 데이터 모델 변환 타입 비교
슈퍼타입/서브타입 모델 변환의 중요성
- 트랜잭션은 항상 일괄적으로 처리된다.
- 트랜잭션은 항상 서브타입을 개별로 처리한다.
- 트랜잭션은 항상 슈퍼타입과 서브타입을 공통적으로 처리된다.
2. 인덱스 특성을 고려한 PK/FK 데이터베이스 성능향상
PK 순서와 성능 사이의 관계
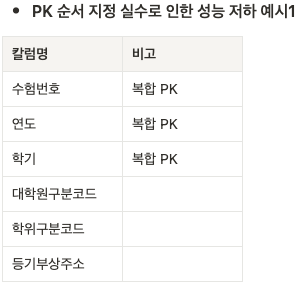
- PK 순서 지정 실수로 인한 성능 저하 예시 1
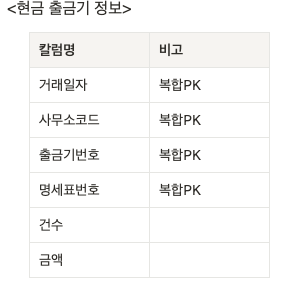
-> 연도, 학기를 자주 불러온다면 컬럼 순서를 연도, 학기, 수험번호 순으로 지정하는 것이 성능에 효과적이다.- PK 순서 지정 실수로 인한 성능 저하 예시 2
-> 거래일자의 범위가 많기 때문에 사무실코드부터 순서를 지정해 사무소코드, 거래일자, 출금기번호, 명세표번호 순으로 지정하는것이 성능 향상에 효과적!FK와 테이블 인덱스 구성 사이의 관계
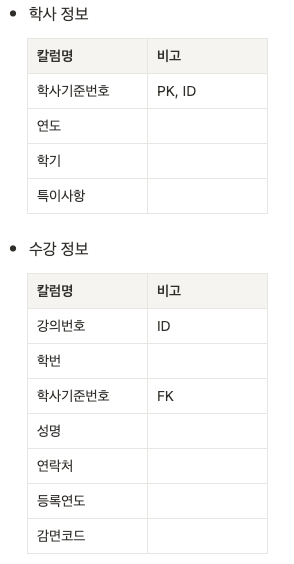
- 수강정보는 기본적으로 학사정보 테이블의 데이터와 연결되는 부분이 많기 때문에 테이블 조인이 많이 발생함
- 수강정보 테이블의 학사기준번호 컬럼으로 하는 인덱스를 미리 만들어 놓아 성능 저하를 막는다.


03. 분산 데이터베이스와 성능
1. 분산 데이터베이스의 개요
분산 데이터베이스란?
- 여러 곳으로 분산되어 있는 데이터베이스를 하나의 가상 시스템으로 사용
- 논리적으로 동일한 시스템에 속하지만 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터를 모음
- 물리적으로는 분산되어 있지만 논리적으로는 하나의 데이터베이스를 다룸
분산 데이터베이스의 투명성
투명성이란 데이터베이스를 사용하는 사용자가 데티어베이스 시스템이 논리적으로 분산되어 있음을 인식하지 못하고 나만의 데이터베이스 시스템을 사용하는 것처럼 느끼게 되는 것
분산 데이터베이스 적용방법
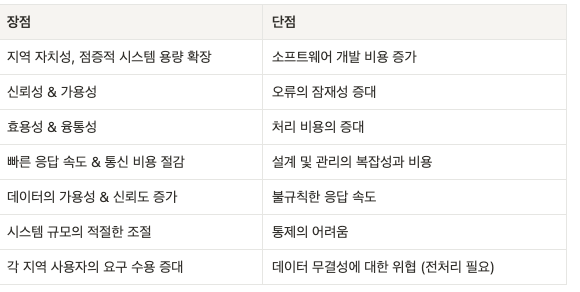
개발비용 및 처리 비용이 증가하고 응답 속도 등이 개선되지 않을 수 있다.
따라서 업무 구성에 따른 아키텍처가 어떤 형태로 구성되어 있는지 등을 고려해야한다.분산 데이터베이스의 장단점

2. 분산 데이터베이스의 활용 방향성 및 적용방법
분산 데이터베이스의 활용 방향성
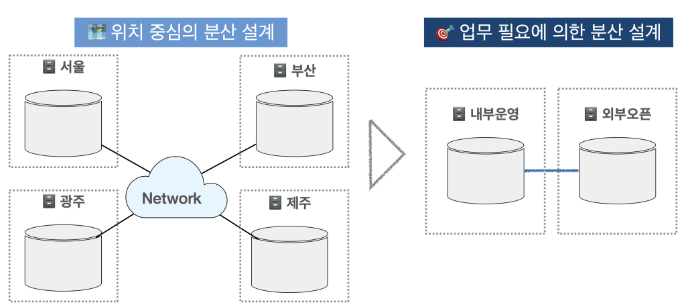
- 과거 분산 데이터베이스는 '위치' 중심 설계였으나
- 최근에는 업무 특성에 맞게 내부 및 외부 데이터베이스를 나눠 설계함.
- 통합된 데이터베이스 환경보다 훨씬 더 빠르지만, 네트워크 트래픽 혹은 트랜잭션 집중으로 성능 저하가 발생할 수 있다.
분산 데이터베이스의 적용 방법
- 테이블 위치(Location) 분산
설계된 테이블의 위치를 다르게 위치시킨다.
- 테이블 분할(Fragmentation) 분산
각 테이블을 쪼개서 분산하는 방법
- 수평분할 : 행으로 분리, 모든 데이터는 분리되어 있는 형태로 구성됨
- 수직분할 : 컬럼으로 분리, 모든 데이터는 분리되어 있는 형태로 구성됨
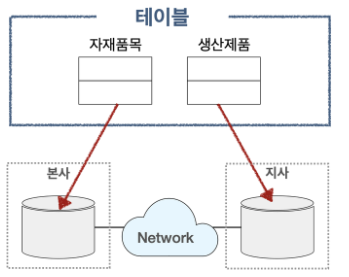
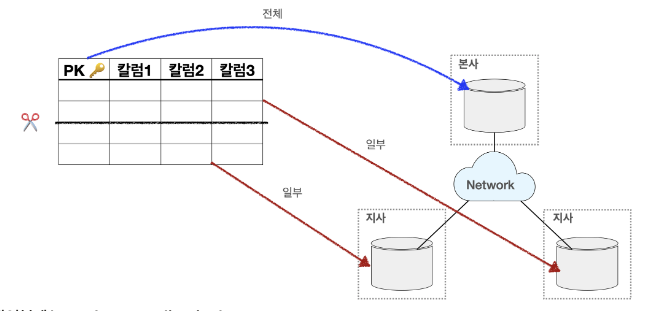
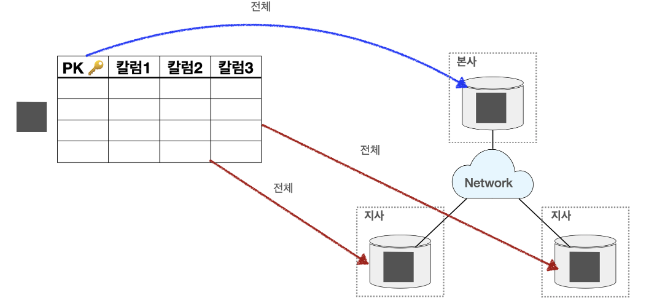
테이블 복제 분산
- 부분 복제(Segment Replication)
통합된 테이블을 마스터 데이터베이스에 가지고 있으면서 각 지사별로는 지사에 해당하는 행을 가지고 있는 형태
- 광역 복제(Broadcast Replication)
통합된 테이블을 마스터 데이터베이스에 가지고 있으면서 각 지사별로는 마스터 데이터베이스와 동일한 데이터를 가지고 있는 형태
테이블 요약 분산
- 분석요약
- 동일한 테이블 구조를 가지고 있으면서 분산되어있는 동일한 내용의 데이터를 이용한 통합된 데이터를 산출
- 새벽(유저가 잘 활동하지 않는) 에 작업
- 통합요약
- 분산되어 있는 다른 내용의 데이터를 이용해 통합된 데이터를 산출하는 방식
- 중앙으로 모아서 다시 산출해주는 방식

잘 하고 있는겨?