1. 성능 데이터 모델링과 정규화
1. 데이터 모델 성능
- 성능 데이터 모델링이란?
- 성능 향상을 목적으로 하는 작업
- 처음부터 성능 향상을 목적으로 진행하는 작업
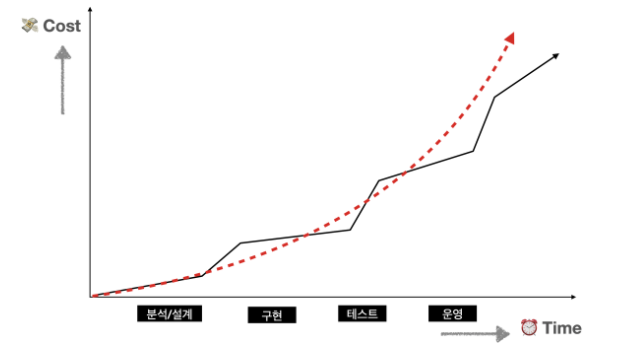
- 성능 데이터 모델링 수행 시점
- 사전에 철저하게 설계된 상태로 모델링에 도입할 수록 비용이 적게든다.
- 분석 및 설계 단계에서 수행해야 재업무 비용을 최소화 할 수 있다.
- 성능 데이터 모델링의 고려사항
- 정규화를 정확하게 수행
- 데이터를 주요 관심사별로 분산시킬 수 있어 성능 향상의 효과가 있다.
- 중복된 데이터가 쌓이는 것을 막을 수 있다.
- 데이터베이스 용량 산정 수행
- 어떤 엔터티에 데이터가 집중되는지 파악할 수 있다.
- 테이블 분리와 조인을 통한 데이터 수집이 필요하다.
- 데이터베이스에서 발생되는 트랜잭션의 유형 파악
- CRUD 매트릭스 혹은 시퀀스 다이어그램을 보면 파악하기에 용이하다.
- 데이터 조회에 필요한 조인 관계 등을 파악할 수 있다.
- 데이터베이스의 용량과 트랜잭션 유형에 따라 반정규화 수행
- 테이블, 속성, 관계 등에 대해서 포괄적인 반정규화를 통해 성능을 조정해야 한다.
- 이력모델, PK/FK, 슈퍼타입/서브타입의 조정
- 성능이 우수한 순서대로 칼럼의 순서를 조정해야 한다.
- 성능 관점에서 데이터 모델 검증
- 항상 성능 최적화를 위해서 데이터 모델을 검증한다.
- 데이터 모델이 괜찮은 형태로 구조화 되었다 하더라도 성능 최적화를 위한 선택을 위해 끊임없이이 고민한다.
2. 정규화를 통한 성능 향상 전략
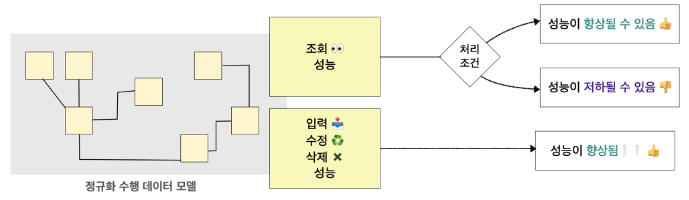
그래서 정규화란?
-> 정규화를 하여도 성능이 좋아질 수도, 저하될 수도 있음.
데이터의 일관성을 유지하고 데이터의 중복을 방지하며 데이터의 유연성을 유지하기 위해 데이터를 분해하는 과정3. 정규화 용어 및 이점
- 정규화 용어
- 정규화(Normalization) : DBMS 테이블의 삽입, 삭제, 수정 과정에서의 이상 현상의 발생을 최소화 하기 위해 작은 단위의 테이블로 나눠가는 과정
- 정규형(NF : Normal Form) : 정규화된 결과물에 의해 도출된 데이터 모델이 갖춰야 할 특성을 만족하는 '정규화된 결과물'을 의미함
- 함수정 종속성(FD : Functional Dependency) : 칼럼 A를 알고 있으면 다른 칼럼 B를 알 수 있다고 가정할 때, B는 A에 함수적 종속성을 가진다고 한다.
- 결정자(Determinant) : 위의 함수적 종속성에서 A에 해당함.
- 다치종속 : 결정자 A에 의해 B의 값을 다수 알 수 있을 때, B는 A에 다치종속 되었다고 표현한다.
- 정규화의 이점
- 데이터의 유연성
- 높은 응집도와 낮은 결합도 원칙에 충실해짐
- 응집도 : 요소들이 서로 관련되어 있는 정도
- 결합도 : 요서들 간의 상호 의존하는 정도
- 데이터의 재활용성
- 데이터의 개념이 조금 더 세분화될 수 있고 개념에 대한 재활용 가능성이 증가한다.
- 데이터의 중복 최소화
- 식별자가 아닌 속성이 한 번만 포함되기 때문에 데이터의 중복이 최소화된다.
2. 정규화 이론
1. 제 1 정규화
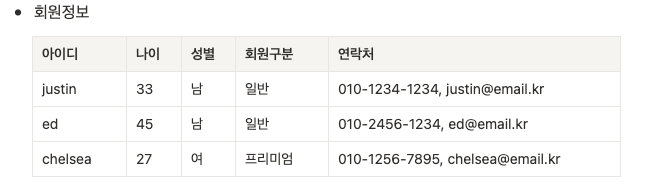
한 속성에 여러 개의 속성이 포함되어 있거나 같은 유형의 속성이 여러 개로 나눠져있는 경우 해당 속성을 분리한다.
- 제 1 정규형 위반
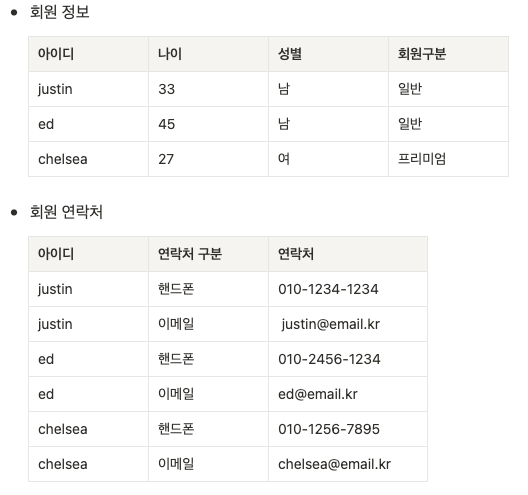
- 제 1정규화한 테이블
2. 제 2 정규화
제 1 정규화를 만족시키고 PK가 아닌 모든 칼럼은 PK 전체에 종속된다.
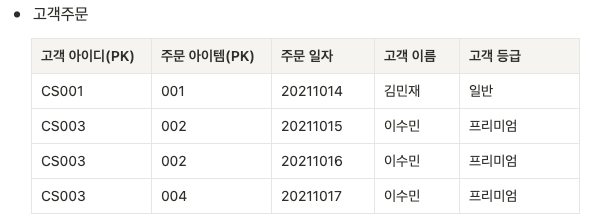
- 제 2 정규화 위반
모든 컬럼은 PK 전체에 종속되어야 하나, 고객등급은 주문아이템(PK)에 종속되지 않음
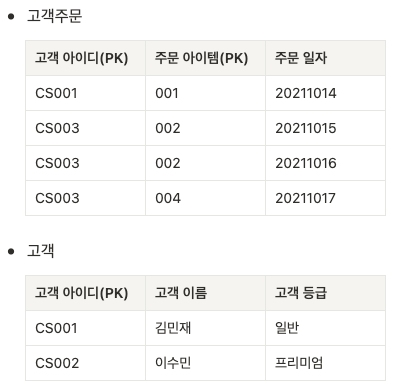
- 제 2정규화한 테이블
테이블을 분리하여 고객 정보를 위한 식별자를 추가함. 복합 식별자의 일부 컬럼에만 종속되는 문제를 해결
3. 제 3 정규화
제 2 정규화를 만족시키고 일반 속성 간에도 함수 종속 관계가 존재하지 않아야 함
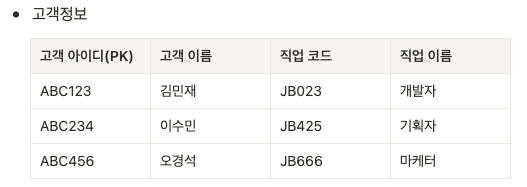
- 제 3정규화 위반
PK에 해당하는 고객아이디를 제외하면 다른 속성 간에는 종속관계가 발생하면 안된다. 직업코드와 직업 이름이 종속관계에 있다.
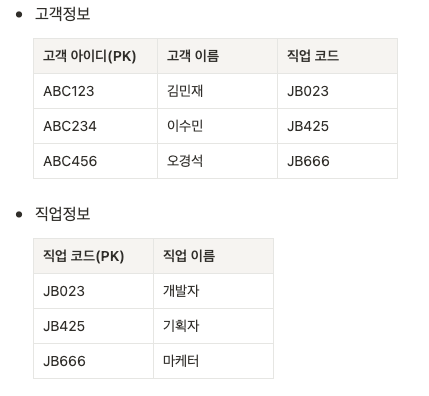
- 제 3정규화한 테이블
기존 '고객정보'라는 하나의 테이블에서 일반 속성 간의 종속성이 발생하는 부분을 분리하여 '직업정보'라는 다른 테이블 구성.
4. 정규화 유형
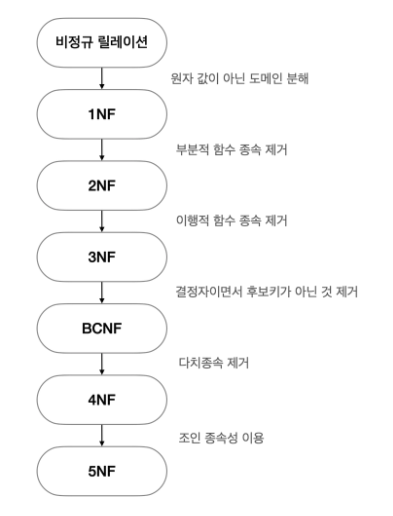
SQLD에서는 제 3 정규화까지 다룸
- 제 1 정규화(1NF)
- 모든 속성은 반드시 하나의 값을 가져야 한다.
- 속성의 원자성 확보 : 한 속성에 여러 속성값을 부여하거나 같은 유형의 속성이 여러개인 경우 해당 속성을 분리한다.
- 제 2 정규화(2NF)
- 부분적 함수 종속 제거 : 주식별자(PK)에게 완전하게 함수 종속되지 않은 속성을 분리하여 종속 관계를 구성한다.
- 제 3 정규화(3NF)
- 이행적 함수 종속 제거 : 일반 속성간의 함수 종속성이 발생하지 않도록 분리한다.
- 보이스-코드정규화(BCNF) : 결정자 안에 함수 종속을 가진 주식별자 속성을 분리한다.
- 제 4 정규화 : 다치종속성을 제거한다.
- 제 5 정규화 : 조인 속성을 제거한다.
3. 반정규화 개념과 설명
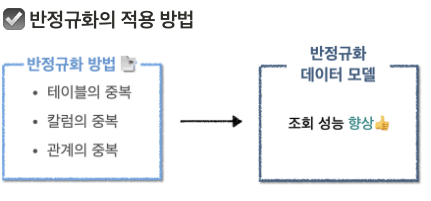
1. 반정규화의 정의
- 반정규화는 성능 향상에 목적이 있다.
- 정규화와 반대로, 중복을 통해 목적을 달성한다.
- 반정규화를 하는 상황
- 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하되는 경우가 많다.
- 테이블간 경로가 너무 멀어 조인으로 인한 성능 저하가 예상된다.
- 칼럼을 계산하여 읽을 때 성능이 저하될 것이라고 예상된다.
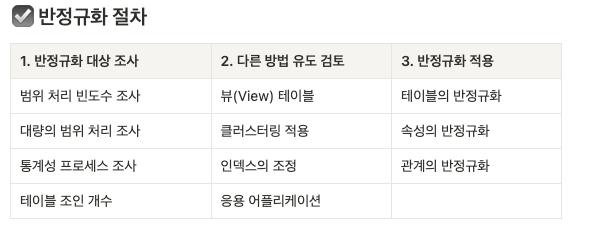
-> 반정규화는 무조건 실행하는 것이 아님. 대상을 먼저 조사하고 다른 방법이 있는지 찾아보고 적용해야 함!
2. 반정규화의 기법
- 테이블 반정규화
- 테이블 병합
- 여러 개의 테이블을 하나로 합침
- 병합하면 테이블을 중복 저장하게 되지만 조회 과정의 성능이 향상될 수 있음
- 테이블 분할
- 특정 테이블을 여러 개의 테이블로 나눔
- 테이블 추가
- 특정 테이블을 추가함
- 데이터 중복 저장의 비효율이 발생하더라도 조회의 성능을 높이기 위해 사용



- 컬럼 반정규화
컬럼의 반정규화는 특정 컬럼을 추가하여 데이터 모델 내에서 중복으로 데이터가 저장됨에도 성능을 향상시킬 수 있는 방법이다.
- 중복 컬럼을 추가하여 연산 제거,
- 추가 컬럼을 만들어 연산 감소,
- 이력테이블에 특정 컬럼을 추가해 조회성능 향상,
- PK컬럼 내에 특정한 규칙에 의해 데이터가 저장되어 있지만 일반 컬럼으로 만드는 방법,
- 응용 시스템의 오작동을 위해 컬럼을 추가시키는 방법

- 관계 반정규화
- 중복 관계 추가
여러 경로에 걸쳐 테이블을 조인하는 경우, 조인 연산 자체를 줄여 조회 성능을 향상시킴.
A->B->C 형태로 조인이 발생한다면, A->C로 줄이는 것.
데이터 무결성을 위반하더라도 데이터 처리를 할 때 성능을 향상시키기 위해 사용한다.

잘 하고 있는겨?