데이터베이스 생성, 테이블 생성, 데이터 삽입
CREATE DATABASE IF NOT EXISTS SampleDB;
-- 데이터베이스 생성
USE SampleDB;
-- 데이터베이스 사용선언
CREATE TABLE IF NOT EXISTS Employees (
ID INT PRIMARY KEY,
Name VARCHAR(50),
Position VARCHAR(50),
Salary DECIMAL(10, 2)
); -- 테이블 생성
INSERT INTO Employees (ID, Name, Position, Salary)
VALUES (1, 'Alice', 'Developer', 60000.00),
(2, 'Bob', 'Designer', 55000.00);
SELECT * FROM Employees;
-- 데이터 삽입 및 조회데이터베이스 목록 조회
SHOW DATABASES ; 특정 데이터베이스의 테이블 목록 조회
USE DBsample ;
SHOW TABLES ; 테이블 생성, 구조변경, 삭제(DDL)
--테이블 생성
CREATE TABLE Employee (
EmployeeID INT PRIMARY KEY,
Name VARCHAR(50),
Postion VARCHAR(50),
Salary DECIMAL(10,2)
);
-- 데이터 삽입
INSERT INTO Employees (EmployeeID, Name, Postion, Salary)
VALUES (1, 'Alice', 'Developer', 60000.00)
-- 테이블 구조 변경(컬럼추가)
ALTER TABLE Employees ADD Name VARCHAR(10) ;
-- 테이블 삭제
DROP TABLE Employees ; 데이터 삽입, 조회, 업데이트(DCL)
-- 데이터 삽입
INSERT INTO Employees (EmployeeID, Name, Postion, Salary)
VALUES (1, 'Alice Smith', 'Developer', 70000.00) ;
-- 데이터 조회
SELECT *
FROM Employees
-- 데이터 업데이트
UPDATE Employees
SET Salary = 70000.70
WHERE EmployeeID = 1 ;
-- 데이터 삭제
DELETE FROM Employees
WHERE EmployeeID = 1 ; 필터링 쿼리(ORDER BY, GROUP BY, HAVING)
-- 각 부서별 평균 급여를 계산하고, 평균 급여가 60000 이상인 부서만 필터링합니다.
SELECT
Department,
avg(Salary) as AVG_Sal
FROM Employees
GROUP BY Department
HAVING avg(Salary) >= 60000 문자열 함수(CONCAT, SUBSTRING, TRIM, LOWER, UPPER)
SELECT CONCAT(Name, ' - ', Department) AS Concatenated
FROM Employees;
--> Alice-Marketing
SELECT SUBSTRING(Name, 1, 3) AS Substring
FROM Employees;
--> Ali
SELECT TRIM(Name) AS TrimmedName
FROM Employees;
--> Alice(양쪽 공백이 사라짐)
SELECT LOWER(Department) AS Lowercase
FROM Employees;
--> marketing
SELECT UPPER(Department) AS Uppercase
FROM Employees;
--> MARKETING수치함수(ROUND, ABS, SUM, AVG, COUNT)
SELECT ROUND(Salary, -3) AS RoundedSalary
FROM Employees;
SELECT ABS(Salary - 60000) AS SalaryDifference
FROM Employees;
SELECT SUM(Salary)
FROM Employees;
SELECT AVG(Salary)
FROM Employees;
SELECT COUNT(*)
FROM Employees;연산자(AND, OR, NOT, IN, LIKE)
SELECT *
FROM Employees
WHERE Salary > 50000 AND Department = 'IT';
SELECT *
FROM Employees
WHERE Salary BETWEEN 40000 AND 80000;
SELECT *
FROM Employees
WHERE Department IN ('Engineering', 'IT');
SELECT *
FROM Employees
WHERE Name LIKE '@%';
SELECT *
FROM Employees
WHERE Salary <> 60000;JOIN(INNER, LEFT, RIGHT, FULL, CROSS)
--INNER JOIN
SELECT
Table1.id,
Table1.value,
Table2.description
FROM
Table1
INNER JOIN
Table2
ON
Table1.id = Table2.id;
-- LEFT(RIGHT) OUTER JOIN
SELECT
Table1.id,
Table1.value,
Table2.description
FROM
Table1
LEFT(RIGHT) OUTER JOIN
Table2
ON
Table1.id = Table2.id;
-- FULL OUTER JOIN
SELECT
Table1.id,
Table1.value,
Table2.description
FROM
Table1
FULL OUTER JOIN
Table2
ON
Table1.id = Table2.id;
-- CROSS JOIN
-- CROSS JOIN은 두 테이블 간 가능한 모든 조합을 생성하는 SQL 조인 유형입니다. 이 조인은 두 테이블의 모든 행을 조합하여 크로스 프로덕트를 생성하는 데 사용됩니다.
-- 모든 조합 생성: CROSS JOIN은 한 테이블의 각 행과 다른 테이블의 모든 행을 결합합니다.
-- 크로스 프로덕트: 결과는 두 테이블의 행 수를 곱한 만큼의 조합을 포함합니다.
SELECT
Table1.id,
Table1.value,
Table2.description
FROM
Table1
CROSS JOIN
Table2;서브쿼리
- 정의: 서브쿼리는 메인 쿼리 안에 포함되어 있는 또 다른 쿼리입니다.
- 타입: 단일 행 반환 서브쿼리와 다중 행 반환 서브쿼리가 있습니다.
- 위치: SELECT, FROM, WHERE 절 등에서 사용됩니다.
- 용도: 데이터 필터링, 복잡한 집계, 데이터 조인 등에 활용됩니다.
-- 부서별 최대 급여 계산
SELECT
Department,
(SELECT MAX(Salary)
FROM Employees
WHERE Department = Departments.Department) AS Max_Sal
FROM Department ; 조건문(CASE WHEN, IF)
-- 직원의 급여에 따라 급여 등급을 분류하는 쿼리입니다.
SELECT
EmployeeID,
Name,
Salary,
CASE
WHEN Salary >= 60000 THEN 'High'
WHEN Salary BETWEEN 40000 AND 59999 THEN 'Medium'
ELSE 'Low'
END AS SalaryGrade
FROM
Employees;집합연산(UNION, INTERSECT, EXCEPT)
- UNION: 두 개 이상의 쿼리 결과를 결합하여 중복을 제거한 단일 결과 집합을 생성합니다.
- INTERSECT: 두 쿼리 결과에서 공통되는 요소만을 선택하여 새로운 결과 집합을 생성합니다.
- EXCEPT: 첫 번째 쿼리 결과에서 두 번째 쿼리 결과를 제외한 요소들로 구성된 결과 집합을 생성합니다.
-- IT 부서와 Sales 부서 직원의 목록 (UNION)
SELECT Name
FROM Employees
WHERE Department = 'IT'
UNION
SELECT Name
FROM Employees
WHERE Department = 'Sales' ;
-- IT 부서에만 있는 직원의 목록 (EXCEPT)
SELECT Name
FROM Employees
WHERE Department = 'IT'
EXCEPT
SELECT Name
FROM Employees
WHERE Department = 'Sales' ; 윈도우함수(OVER, PARTITION BY, ROW_NUMBER, RANK, DENSE_RANK)
- OVER
-- over절을 활용한 이동평균
SELECT
EmployeeID,
SaleDate,
AVG(SaleAmount) OVER (ORDER BY SaleDate ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) As MovingAVG
FROM Sales ;
-- 예시
EmployeeID | SaleDate | SaleAmount
-----------|------------|-----------
1 | 2024-01-01 | 100
1 | 2024-01-02 | 200
1 | 2024-01-03 | 300
2 | 2024-01-01 | 150
2 | 2024-01-02 | 250
2 | 2024-01-03 | 350
-- 1. EmployeeID 1, SaleDate 2024-01-01, SaleAmount 100
- 이동 평균은 2024-01-01 (100), 2024-01-02 (200)의 평균입니다 (이전 날짜가 없으므로 두 날짜만 고려).
- MovingAvg = (100 + 200) / 2 = 150
-- 2. EmployeeID 1, SaleDate 2024-01-02, SaleAmount 200
- 이동 평균은 2024-01-01 (100), 2024-01-02 (200), 2024-01-03 (300)의 평균입니다.
- MovingAvg = (100 + 200 + 300) / 3 = 200
-- 3. EmployeeID 1, SaleDate 2024-01-03, SaleAmount 300
- 이동 평균은 2024-01-02 (200), 2024-01-03 (300)의 평균입니다 (다음 날짜가 없으므로 두 날짜만 고려).
- MovingAvg = (200 + 300) / 2 = 250- PARTITION BY
--partion by 로 부서별 총 매출액 SaleAmount 큰순으로 정렬
SELECT
EmployeeID,
Department,
SaleAmount,
SUM(SaleAmount) OVER (PARTITION BY Department ORDER BY SaleAmount DESC) AS TotalSalesByDept
FROM
Sales ; - ROW_NUMBER, RANK, DENSE_RANK
ROW_NUMBER(): 각 파티션 내에서 고유한 순서를 할당합니다.RANK(): 동일한 값을 가진 항목에 동일 순위를 부여하고, 다음 순위는 건너뜁니다.DENSE_RANK(): 동일한 값을 가진 항목에 동일 순위를 부여하지만, 순위를 건너뛰지 않습니다.
SELECT
EmployeeID,
Department,
SaleAmount,
ROW_NUMBER() OVER (PARTITION BY Department ORDER BY SaleAmount DESC) AS RowNum,
RANK() OVER (PARTITION BY Department ORDER BY SaleAmount DESC) AS Rank,
DENSE_RANK() OVER (PARTITION BY Department ORDER BY SaleAmount DESC) AS DenseRank
FROM
Sales;- LEAD, LAG
LEAD(): 현재 행으로부터 지정된 수만큼 이후의 행을 참조합니다.LAG(): 현재 행으로부터 지정된 수만큼 이전의 행을 참조합니다.
SELECT
EmployeeID,
Department,
SaleAmount,
LEAD(SaleAmount, 1) OVER (PARTITION BY Department ORDER BY SaleDate) AS NextSale,
LAG(SaleAmount, 1) OVER (PARTITION BY Department ORDER BY SaleDate) AS PrevSale
FROM
Sales;
-- 예시
EmployeeID | Department | SaleDate | SaleAmount
-----------|------------|------------|-----------
1 | A | 2024-01-01 | 100
1 | A | 2024-01-03 | 200
2 | A | 2024-01-02 | 150
2 | A | 2024-01-04 | 250
1. EmployeeID 1, Department A, SaleDate 2024-01-01, SaleAmount 100
- `NextSale`: 다음 날짜(2024-01-02)의 판매액은 150입니다 (`LEAD`).
- `PrevSale`: 이전 판매 기록이 없으므로 `NULL`입니다 (`LAG`).
2. EmployeeID 1, Department A, SaleDate 2024-01-03, SaleAmount 200
- `NextSale`: 다음 날짜(2024-01-04)의 판매액은 250입니다 (`LEAD`).
- `PrevSale`: 이전 날짜(2024-01-02)의 판매액은 150입니다 (`LAG`).
3. EmployeeID 2, Department A, SaleDate 2024-01-02, SaleAmount 150
- `NextSale`: 다음 날짜(2024-01-03)의 판매액은 200입니다 (`LEAD`).
- `PrevSale`: 이전 날짜(2024-01-01)의 판매액은 100입니다 (`LAG`).
4. EmployeeID 2, Department A, SaleDate 2024-01-04, SaleAmount 250
- `NextSale`: 이후의 판매 기록이 없으므로 `NULL`입니다 (`LEAD`).
- `PrevSale`: 이전 날짜(2024-01-03)의 판매액은 200입니다 (`LAG`).트랜잭션 관리
- 트랜잭션 관리란 ?
트랜잭션 관리는 데이터베이스에서 데이터의 일관성과 정확성을 유지하는 중요한 역할을 합니다. 트랜잭션은 데이터베이스 작업의 완전성을 보장하기 위해 사용되며, 오류가 발생하면 원래 상태로 롤백됩니다. - 트랜잭션 핵심 구성요소
- BEGIN TRANSACTION: 트랜잭션의 시작을 알립니다.
- COMMIT: 트랜잭션 내의 모든 변경 사항을 데이터베이스에 영구적으로 적용합니다.
- ROLLBACK: 트랜잭션 내의 모든 변경 사항을 취소하고, 데이터를 트랜잭션 시작 전의 상태로 되돌립니다.
- TRANSACTION ISOLATION LEVEL: 다른 트랜잭션과의 격리 수준을 설정합니다.
-- 트랜잭션 시작
BEGIN TRANSACTION;
-- 첫 번째 계정의 잔액을 100만큼 감소시킵니다.
UPDATE Accounts SET balance = balance - 100 WHERE account_id = 1;
-- 두 번째 계정의 잔액을 100만큼 증가시킵니다.
UPDATE Accounts SET balance = balance + 100 WHERE account_id = 2;
-- 변경 사항을 데이터베이스에 반영합니다.
COMMIT;
-- 문제가 발생한 경우, 변경 사항을 취소하고 원래 상태로 되돌립니다.
ROLLBACK;
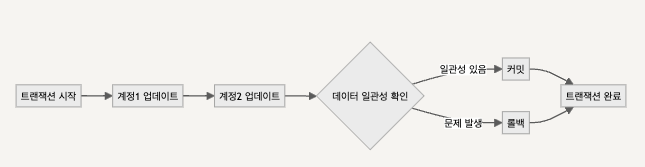트랜잭션 쿼리 진행도(Mermaid)
VIEW
- 뷰(view)란?
뷰는 데이터베이스에서 하나 이상의 테이블로부터 파생된 가상 테이블입니다. 뷰를 사용하면 데이터를 효율적으로 관리하고, 복잡한 쿼리를 단순화할 수 있습니다. - 가상 테이블: 뷰는 실제 데이터를 저장하지 않는 가상 테이블입니다.
- 재사용 가능: 뷰를 통해 정의한 쿼리는 여러 번 재사용할 수 있습니다.
- 보안: 뷰를 사용하여 특정 데이터만을 사용자에게 노출시킬 수 있습니다.
- 단순화: 복잡한 쿼리를 뷰로 정의하여 간단하게 만들 수 있습니다.
-- 뷰 생성하기
CREATE VIEW SalesSummary AS
SELECT
Department,
SUM(SaleAmount) AS TotalSales
FROM Sales
GROUP BY Department ;
-- 뷰 보기
SELECT *
FROM SalesSummary ; INDEXING
- 인덱스란 ?
인덱스는 데이터베이스에서 데이터 검색 속도를 향상시키는 중요한 기능입니다. 적절한 인덱싱은 데이터 검색 및 처리 성능을 대폭 개선할 수 있습니다. - 데이터 접근 속도 향상: 인덱스를 사용하면 특정 조건에 맞는 데이터를 빠르게 찾을 수 있습니다.
- 검색 및 정렬 최적화: 특정 컬럼에 대한 검색 및 정렬 연산이 더 효율적으로 수행됩니다.
- 성능상의 비용: 인덱스는 저장 공간을 차지하며, 데이터 삽입이나 수정 시 추가적인 연산이 필요합니다.
-- index 생성
-- 'Sales' 테이블의 'Department' 컬럼에 인덱스를 생성합니다.
CREATE INDEX idx_department ON Sales(Department) ;
-- index 사용
-- 생성된 인덱스를 활용하여 'Sales' 부서에 해당하는 데이터를 빠르게 검색합니다.
SELECT *
FROM Sales
WHERE Department = 'Sales' ; SQL 최적화
- 쿼리 최적화: 쿼리의 성능을 개선하여 더 빠른 응답 시간과 효율적인 리소스 사용을 달성합니다.
- 인덱스 사용: 적절한 인덱스를 사용하여 데이터 검색 속도를 향상시킵니다.
- 성능 분석 도구:
EXPLAIN등의 도구를 사용하여 쿼리 실행 계획을 분석하고 성능을 평가합니다.
-- 느린쿼리(index 없음)
SELECT EmployeeID, Product, SUM(SaleAmount)
FROM LargeSales
WHERE SaleDate BETWEEN '2023-01-01' AND '2023-12-31'
AND SaleAmount > 500
GROUP BY EmployeeID, Product;
-- 인덱스 추가
CREATE INDEX idx_SaleAmount_SaleDate ON LargeSales(SaleAmount, SaleDate) ;
-- 빠른쿼리(인덱스 있음)
SELECT EmployeeID, Product, SUM(SaleAmount)
FROM LargeSales
WHERE SaleDate BETWEEN '2023-01-01' AND '2023-12-31'
AND SaleAmount > 500
GROUP BY EmployeeID, Product;
-- 쿼리 진행순서
1. 느린 쿼리 실행: 복잡한 조건을 가진 느린 쿼리를 실행합니다.
2. 성능 문제 파악: 쿼리 실행 속도가 느린 원인을 분석합니다.
3. 인덱스 생성: 성능 개선을 위해 적절한 인덱스를 생성합니다.
4. 빠른 쿼리 실행: 인덱스를 활용하여 빠른 쿼리를 실행합니다.SQL 쿼리 프로같이 적는 법
- 명확하고 간결한 쿼리 구성: 불필요한 데이터를 검색하지 않도록 하고, 쿼리의 목적에 맞게 필요한 데이터만 선택합니다.
- 적절한 명명 규칙 사용: 테이블과 컬럼에 명확한 이름을 사용하여 쿼리의 이해를 돕습니다.
- 주석 사용: 쿼리의 목적과 구조를 설명하여 다른 사용자가 쿼리를 이해하고 수정하기 쉽게 합니다.
- 복잡한 쿼리의 단계적 구성: 큰 쿼리를 여러 단계로 나누어 작성하여 복잡성을 줄이고 가독성을 높입니다.
-- 간결하고 명확한 SELECT 쿼리
- 나쁜 예
SELECT * FROM Employees;
- 좋은 예
SELECT EmployeeID, Name, DepartmentID FROM Employees;
-- 조인 사용시 명확한 테이블 별칭 사용
- 나쁜 예
SELECT e.Name, d.DepartmentName FROM Employees e, Departments d WHERE e.DepartmentID = d.DepartmentID;
- 좋은 예:
SELECT emp.Name, dept.DepartmentName FROM Employees emp JOIN Departments dept ON emp.DepartmentID = dept.DepartmentID;
-- 복잡한 쿼리를 단계적으로 나누어 작성
- 나쁜 예:
SELECT EmployeeID,
COUNT(*)
FROM Sales
WHERE SaleAmount > 500
GROUP BY EmployeeID
HAVING COUNT(*) > 5;
- 좋은 예
- 단계 1: 판매량이 500 이상인 판매 기록 필터링
WITH FilteredSales AS (SELECT * FROM Sales WHERE SaleAmount > 500)
- 단계 2: 직원별 판매 건수 계산 및 조건에 따라 필터링
SELECT EmployeeID, COUNT(*)
FROM FilteredSales
GROUP BY EmployeeID
HAVING COUNT(*) > 5;
-- 쿼리 주석 사용
--각 부서의 직원 수를 계산합니다
SELECT dept.DepartmentName, COUNT(emp.EmployeeID) AS NumberOfEmployees
FROM Employees emp
JOIN Departments dept
ON emp.DepartmentID = dept.DepartmentID
GROUP BY dept.DepartmentName;
잘 하고 있는겨?