데이터를 분할하기 & ML 기초 용어
-
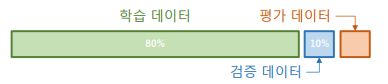
학습 데이터(train data) : 순수하게 학습 과정에서 사용하는 데이터. 보통 전체 데이터의 8할정도로 사용한다.
-
검증 데이터 (validation data) : 학습을 진행하는 중간 과정에서 모델의 학습 상태를 주기적으로 확인하는 데이터. 보통 전체 데이터의 1할정도로 사용한다.
-
평가 데이터 (test data) : 학습을 완료한 후 모델의 최종 성능을 평가하기 위한 데이터. 보통 전체 데이터의 1할 정도로 사용한다.
-
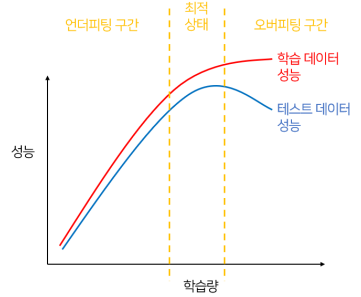
Underfitting : 학습이 부족한 구간을 의미한다
-
Overfitting : 특정 훈련 데이터에 지나치게 학습되어 새로운 데이터나 테스트 데이터에서 성능이 나오지 않는 문제 (=일반화 능력이 떨어진다)
- 해결 방법
- 데이터 양을 늘리기
- 모델의 복잡도를 줄이기
- 정규화 기법 사용하기
- etc
- 해결 방법
-
손실 함수 (Loss Function) : ML 모델의 예측값과 실제 정답 사이의 차이를 측정하는 지표. 일반적으로 손실(Loss)이 작을수록 모델의 성능이 좋다고 볼 수 있다.
- 따라서, ML 모델 학습과정인 Loss를 줄이는 과정으로 진행된다
-
Loss Function은 Task의 종류에 따라 달라진다
- Regression : 평균 제곱 오차 (MSE)
- Classification : 교차 엔트로피 (Cross Entropy)
- Binary Classification : 로그 손실 (Log Loss)
- etc
-
Parameter : ML 모델이 내부적으로 갖고 있는 변수. 모델이 데이터로부터 학습하는 패턴 관계를 표현하며, 모델의 성능에 직접적인 영향을 미친다. Parameter의 구조와 조합은 모델마다 다르다. 학습하는 과정은 Parameter의 값을 찾는 과정이라고 볼 수 있다.
-
최적화 : Parameter를 조절해가며 최적의 값(Loss값이 최소가 되는 값)을 찾아내는 과정이다.
Task에 따른 지도학습의 분류
-
회귀 문제 (Regression problem) : 주어진 입력 데이터에 대해 연속적인 숫자값을 예측하는 문제 (서술형 문제와 비슷)
- ex) 내일 서울의 온도는 ?
-
분류 문제 (Classification problem) : 주어진 입력 데이터가 어떤 Class에 속하는지를 판별하는 문제 (이지/오지선다와 비슷)
- 이진 분류 문제 : Class의 범주가 2개인 경우. ex) 고양이 vs 강아지
- 다중 클래스 문제 : Class의 범주가 여러개인 경우 ex) 선풍기, 고양이, 개구리, ...
분류 문제의 종류
-
로지스틱 회귀 (Logistic Regression) : Binary Classification에 적합. 확률을 직접 예측하는 확률 추정 접근으로 결과를 예측.
-
결정 트리 분류기 (Decision Tree Classifier) : 데이터를 잘 분할하는 결정 트리를 사용하여 분류를 수행
-
랜덤 포레스트 (Random Forest) : 여러 결정 트리를 결합(앙상블 모델)하여 사용. 높은 정확도를 보이며, 과적합 문제를 방지해준다.
-
SVM (Support Vector Machine) : 데이터를 최적으로 분리하는 결정 경계를 찾는 알고리즘
회귀 문제의 종류
-
선형 회귀 (Linear Regression) : 독립 변수와 종속 변수 간의 선형 관계를 모델링
-
라쏘 / 릿지 회귀 (Lasso / Ridge Regression) : 규제 기법을 이용해 과적합을 방지하고, 일반화 성능이 향상된 선형 모델
-
결정 트리 회귀 (Decision Tree Regression) : 결정 트리를 이용해 회귀 문제에 적용
-
SVR (Support Vector Regression) : SVM을 회귀에 적용
-
KNN Regression (K-Nearest Neighbors Regression) : 주어진 데이터 포인트에서 가장 가까운 K개의 이웃 데이터의 평균으로 예측값을 결정
