Data Science Devcourse
1.[DevCourse] Day 1 - 데이터와 데이터 팀

데이터란?
2.[DevCourse] Day 2 - 데이터 기반 의사 결정
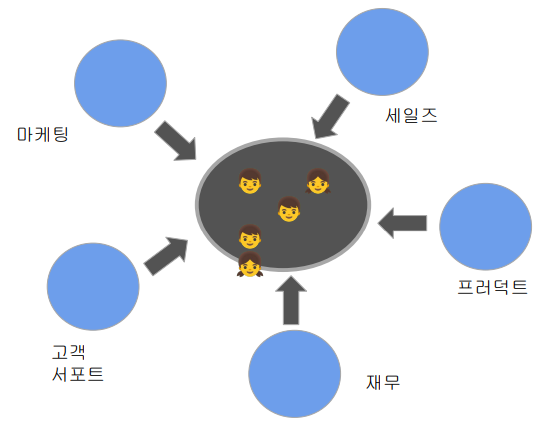
데이터 기반 의사 결정
3.[DevCourse] Day 3 - 데이터 기반 제품 개선
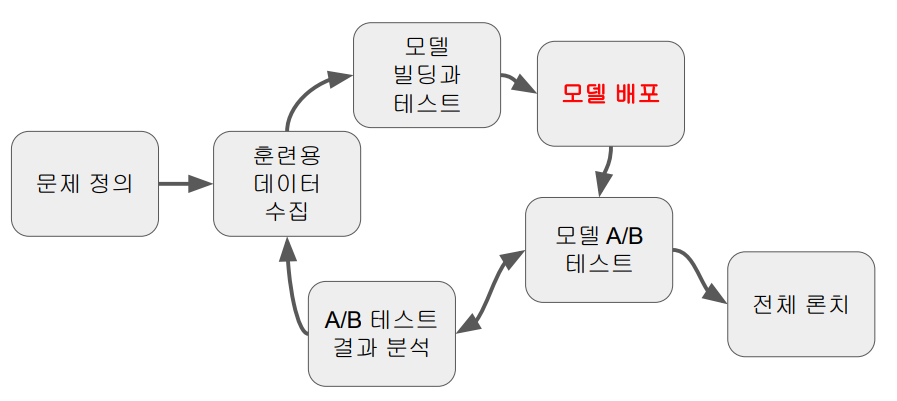
데이터 과학자의 역할 중 하나는 데이터를 기반으로 제품을 개선하는 것이다
4.[DevCourse] Day 4 - Gen AI

존 매카시의 정의 (WHAT IS ARTIFICIAL INTELLIGENCE?) : "지능형 기계, 특히 지능형 컴퓨터 프로그램을 만드는 과학 및 공학이다.
5.[DevCourse] Day 5 - 데이터 활용시 고려할 점
데이터 소스와 양의 폭발적인 증가로 인해 데이터베이스의 형태가 Data Warehouse에서 Data Lake로 변화
6.[DevCourse] Day 6 - Excel을 활용한 데이터 분석 실습(1)
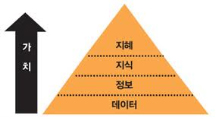
데이터의 사전적 정의 : 이론을 세우는데 기초가 되는 사실, 또는 바탕이 되는 자료휴대폰 번호, 영화의 목록, 게임 아이템 등 여러가지의 데이터가 있다
7.[DevCourse] Day 7 - Excel을 활용한 데이터 분석 실습(2)
ChatGPT를 사용한 업무 보조 AI를 만드는 것은 어디까지나 "보조"임을 인지해야 한다.업무 보조 AI를 만드는 과정은 다음과 같다.
8.[DevCourse] Day 8 - Excel을 활용한 데이터 분석 실습(3)
논리 데이터True(1), False(0)로 표현되며 참이나 거짓을 표시하는 데이터논리 함수에 주로 사용됨논리 함수주어진 조건에 따라 참 또는 거짓을 반환함IF, AND, OR, NOT 함수 등이 포함수식 데이터=1+2+3, =SUM(A1, A2) 와 같이 함수 혹은
9.[DevCourse] Day 9 - Excel을 활용한 데이터 분석 실습(4)
특강 : 간단한 엑셀 함수로 Kaggle 해보기 Kaggle이란? : 2017년 Google에서 인수한 데이터 분석 플랫폼이며 데이터 과학 및 머신러닝 경진대회를 주최하는 온라인 커뮤니티. 전 세계 데이터 분석가/과학자들이 모여있는 플랫폼이며 다양한 문제, 상금, 좋
10.[DevCourse] Day 10 - Excel을 활용한 데이터 분석 실습(5)
결측치(Missing Value) : 유효하지 않거나, 아무것도 존재하지 않는 값.
11.[DevCourse] Day 11 - SQL 기초(1)
SQL (Structured Query Language) : 관계형 데이터베이스를 사용하기 위한 표준 언어
12.[DevCourse] Day 13 - SQL 기초(3)
BIT(M) : 이진법 숫자를 표현, M을 사용하여 몇 비트를 사용할지 결정M의 범위는 1~64TINYINT : 매우 작은 정수를 표현, 8bit(1byte) 사용BOOL, BOOLEAN : TRUE, FALSESMALLINT : 작은 정수를 표현, 16b
13.[DevCourse] Day 12 - SQL 기초(2)
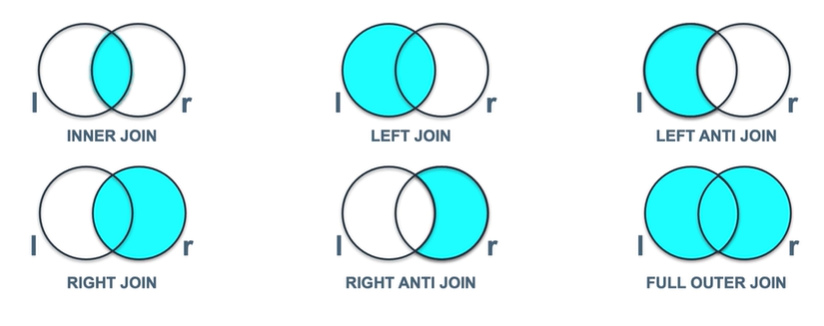
JOIN : 두개 이상의 테이블을 특정 key를 기준으로 결합하는 것집합의 개념으로 어떤 JOIN을 사용할지 생각해보면 괜찮을 것 같다INNER JOIN : 두 테이블의 key의 값이 서로 같을 경우에만 JOIN 실행가장 가벼운 JOIN이다LEFT JOIN : 왼쪽 테
14.[DevCourse] Day 14 - SQL 기초(4)
효율적인 쿼리를 작성하기 위해서는 (비용, 연산량, 수행시간, ...)를 고려해야 한다테이블을 집합으로 생각하기row를 제한테이블을 조회할때는 항상 LIMIT을 걸고 조회해라 (얼마나 큰 테이블인지 모른다)파티션이 있는 테이블인지 확인하고, 파티션을 필터 조건으로 걸고
15.[DevCourse] 10-1 데이터 웨어하우스 소개
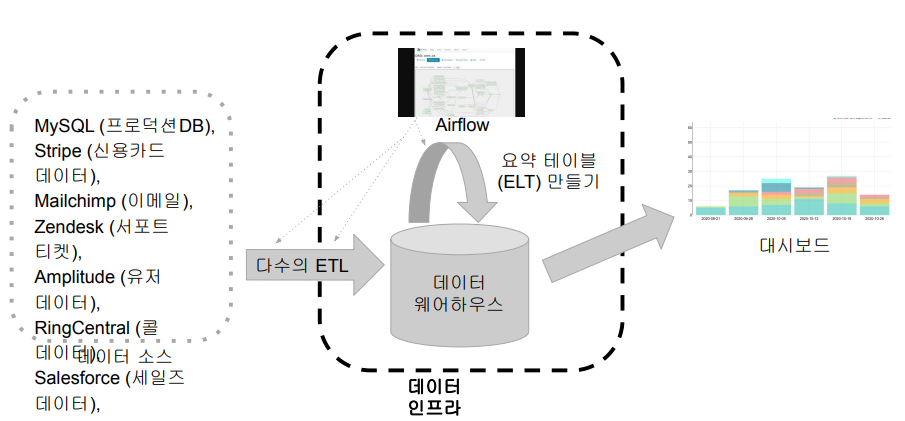
데이터 웨어하우스는 기본적으로 구조화된 데이터를 처리 할 때 유리하고, 데이터 레이크보다는 비용이 비싼편이다고정비용 : 매 달 정해진 비용을 내고 사용 ex) AWS Redshift가변비용 : 사용한 만큼 비용을 낸다 ex) BigQuery, Snowflake보통 가변
16.[DevCourse] 10-2 Snowflake 운영과 관리
클라우드 기반 데이터웨어하우스글로벌 클라우드(AWS, GCP, Azure)위에서 모두 동작하는 멀티클라우드데이터 판매를 통해 매출을 가능하게 해주는 Data Sharing / Marketplace 기능을 제공스토리지와 컴퓨팅 인프라가 별도로 설정되는 가변 비용 모델SQ
17.[DevCourse] 10-3 좋은 지표란?
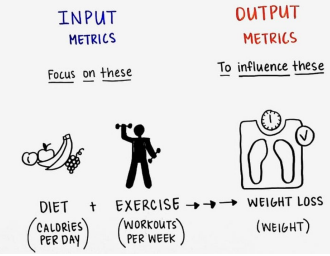
KPI는 적게 설정하는 것이 좋다 (정말로 가치가 있는 값으로 설정해야 한다)여러번 측정 가능한 지표가 좋다 (ex. Monthly Recurring Revenue)후행지표이다 (=결과론적으로 나오는 지표이다)feedback이 가능한 지표여야 한다3AAccessible
18.[DevCourse] 10-4 Superset 배워보기
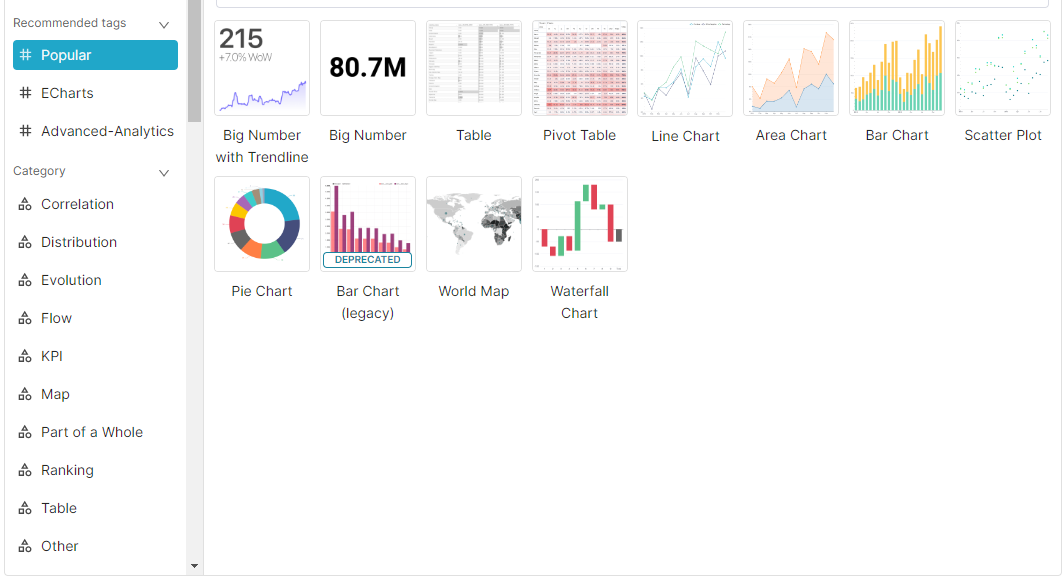
다양한 시각화 툴 소개 대시보드, 혹은 BI(Business Intelligence) 툴이라고 부르기도 한다 중요한 데이터 포인트들(KPI, 각종 지표)를 계산/분석/시각화 해주는 도구 Excel, Google Spreadsheet : 가장 많이 사용되며 가장 쉬운
19.[DevCourse] 10-5 Tableau 배워보기
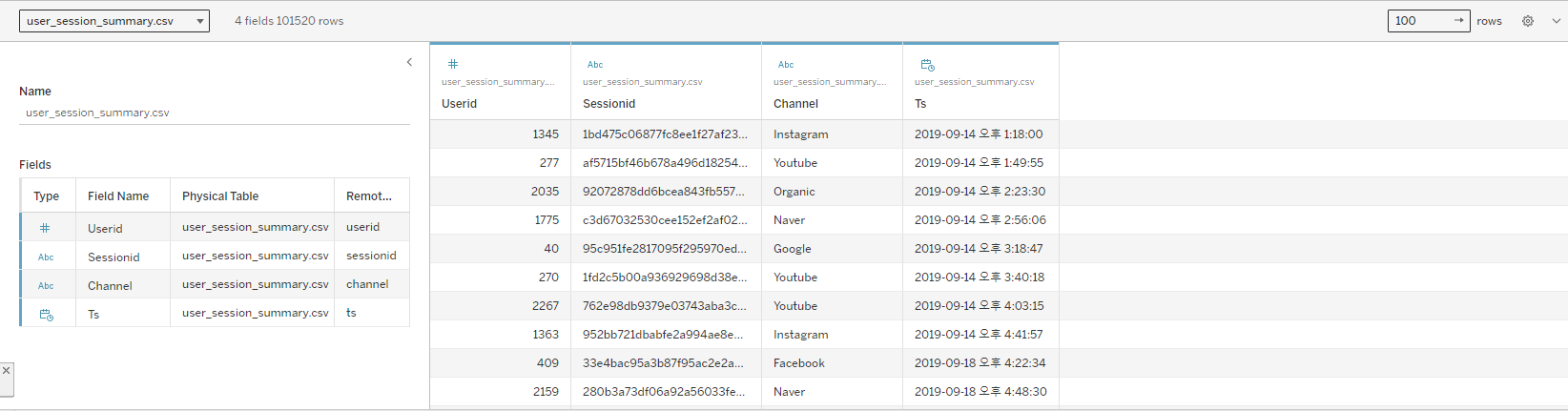
학습을 위한 public 버젼(무료)이 있다. 해당 버젼을 기준으로 소개를 진행한다CSV 파일만 지원한다. 즉, 데이터에 대한 라이브 연결은 지원하지 않는다자신이 만든 대시보드는 기본적으로 모든 사람들에게 공개된다 -> 포트폴리오로 사용 가능하다Tableau의 용어 설
20.[DevCourse] 11-2 지도학습 기초
dd
21.[DevCourse] 11-1 머신러닝 기초와 배경

머신러닝이란? 머신 스스로가 데이터에서 지식을 추출하는(데이터의 특징과 패턴을 찾아내는) 작업 Tom Mitchell의 학습에 대한 정의 어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상돼었다면, 이 컴퓨터 프로그램은
22.[DevCourse] 11-3 선형 회귀

선형 모델의 개념 과자(1,500원)와 우유(1,200원)를 사기위해 마트에서 장을 본다고 가정하자. total cost = n(과자) * 1500 + n(우유) * 1200 조건(과자의 가격과 우유의 가격은 서로 독립) 이처럼, 독립 변수 (n(과자, 우유)
23.[DevCourse] 11-4 SVM 이론

빨간 선, 파란 선 모두 삼각형과 원을 정확하게 분류하였다파란 선의 경우 각 클래스의 데이터 샘플로부터 가장 멀리 위치해있다 -> 일반화 성능이 빨간 선보다 좋다샘플로부터 분류 선까지의 거리를 마진(Margin)이라고 하며, 마진을 구성하는 데이터 샘플을 서포트 벡터(
24.[DevCourse] 11-5 비지도학습

정답 레이블이 지정되지 않은 데이터로부터 패턴을 찾아내는 학습 방법론주어진 데이터의 구조나 패턴을 자동으로 탐색하는 목적을 가지고 있다군집화 (Clustering) : 데이터를 유사한 특성을 공유하는 군집으로 분할하는 과정차원 축소 (Dimensionality Redu
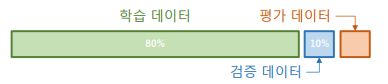
25.[DevCourse] 11-6 성능평가

검증 : 모델의 학습이 잘 진행되었는지, 즉 일반화 능력이 좋은지를 판단하는 평가 과정검증 데이터를 선택 할 때 아래와 같은 문제가 발생 가능쉬운 데이터로의 편향전체적인 데이터 양의 부족교차 검증 (Cross Validation) : 전체 데이터를 여러 개의 하위 데이