1661. Average Time of Process per Machine
- 작성한 쿼리 (187ms)
- 각 기계의 프로세스 별로 시작 시각과 종료 시각을 따로 유지하여 기계별 평균 처리 속도를 계산하였다.
- JOIN을 사용하지 않고 문제를 해결해 보기 위해 이러한 접근을 해 보았지만, WHERE 절에서 실질적으로 JOIN과 유사한 연산을 수행해야 한다.
- CTE를 사용하여 임시 테이블을 생성하기 때문에 (데이터의 크기에 따라) 메모리 사용, 디스크 I/O와 관련된 오버헤드가 있을 수 있고, 쿼리 최적화에 불리하다.
WITH startCTE as (
SELECT machine_id, process_id, timestamp
FROM Activity
WHERE activity_type = "start"
),
endCTE as (
SELECT machine_id, process_id, timestamp
FROM Activity
WHERE activity_type = "end"
)
SELECT S.machine_id, ROUND(AVG(E.timestamp - S.timestamp), 3) as processing_time
FROM startCTE as S, endCTE as E
WHERE S.machine_id = E.machine_id and S.process_id = E.process_id
GROUP BY 1- 상위 성능 쿼리 (180ms)
select a1.machine_id, ROUND(AVG(a2.timestamp - a1.timestamp), 3) as processing_time
from Activity a1
join Activity a2
on a1.machine_id=a2.machine_id and a1.process_id=a2.process_id
and a1.activity_type='start' and a2.activity_type='end'
GROUP BY 1- EXPLAIN 결과 (작성한 쿼리)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | Activity | null | ALL | null | null | null | null | 12 | 50 | Using where; Using temporary |
| 1 | SIMPLE | Activity | null | ALL | null | null | null | null | 12 | 8.33 | Using where; Using join buffer (hash join) |
- EXPLAIN 결과 (상위 성능 쿼리)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | a1 | null | ALL | null | null | null | null | 12 | 50 | Using where; Using temporary |
| 1 | SIMPLE | a2 | null | ALL | null | null | null | null | 12 | 8.33 | Using where; Using join buffer (hash join) |
- 두 쿼리의 EXPLAIN의 결과는 같지만, 메모리 오버헤드를 생각한다면 작성한 쿼리에서는 성능 문제가 발생할 수 있다.
USING VS ON
-
USING
- 두 테이블 간의 공통 컬럼(이름이 같은 컬럼)을 기반으로 조인을 수행한다
- 중복된 컬럼을 제거하고, 하나의 컬럼만 포함한다
- 동일한 이름을 가진 컬럼 기준 단순 조인을 할 때 사용한다
-
ON
- 다양한 조건을 지정할 수 있고, 컬럼 이름이 달라도 조인이 가능하다
SubQuery VS CTE
- SubQuery : 메인 쿼리 내에 중첩된 쿼리
- 가독성 : 복잡한 쿼리일 경우 가독성이 떨어질 수 있다
- 재사용성 : 동일한 서브쿼리를 여러 번 사용하려면 반복 작성해야 한다
- 실행 : 메인 쿼리가 실행되기 전에 실행된다. 메인 쿼리는 서브쿼리의 결과를 사용하여 필터링, 집계 등의 작업을 수행한다
- 한계점
- 보통 최적화가 어려우며, 특히 중첩된 서브쿼리의 경우 성능이 떨어질 수 있다
- 동일한 서브쿼리를 여러 번 사용할 경우 반복해서 작성해야 하며, 성능에 영향을 줄 수 있다
SELECT employee_id, first_name, last_name
FROM employees
WHERE department_id = (SELECT department_id FROM departments WHERE department_name = 'Sales');- CTE (Common Table Expression) : WITH 절을 사용하여 쿼리 시작 부분에 정의되며, 일시적으로 쿼리 내에서 사용할 수 있는 테이블과 같은 역할을 한다.
- 가독성 : 복잡한 쿼리를 분할하여 가독성이 높다
- 재사용성 : 동일한 CTE를 여러 번 참조 가능하다
- 실행 : 정의된 쿼리가 실행될 때 일시적인 테이블로 생성되며, 메인 쿼리는 이를 참조하여 작업을 수행한다.
- 재귀성 : 재귀적인 데이터 처리가 가능하다
- 한계점
- 큰 데이터 세트를 처리할 때 메모리와 디스크 사용량이 증가할 수 있다
WITH SalesDepartment AS (
SELECT department_id
FROM departments
WHERE department_name = 'Sales'
)
SELECT employee_id, first_name, last_name
FROM employees
WHERE department_id IN (SELECT department_id FROM SalesDepartment);
재귀적 CTE
-
자기 자신을 참고하여 반복적으로 데이터를 생성하는 CTE. 계층적인 데이터를 처리하거나, 재귀적인 계산을 수행하는 데 유용하다.
-
예시 데이터 (employees)
WITH RECURSIVE EmployeeHierarchy AS (
-- Anchor member: 최상위 관리자 선택
SELECT employee_id, manager_id, first_name, last_name, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- Recursive member: 하위 직원 선택
SELECT e.employee_id, e.manager_id, e.first_name, e.last_name, eh.level + 1
FROM employees e
INNER JOIN EmployeeHierarchy eh ON e.manager_id = eh.employee_id
)
SELECT employee_id, manager_id, first_name, last_name, level
FROM EmployeeHierarchy;
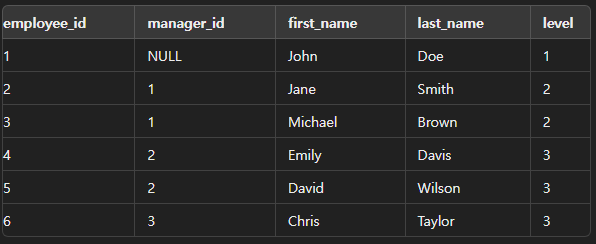
- 수행 결과

개인 공부용 블로그입니다