로컬 해석력(Local Interpretability) VS 글로벌 해석력(Global Interpretability)
- 특정 미적분 문제 풀이 방법 VS 미적분 문제 전체 풀이 전략법
| 구분 | Local | Global |
|---|---|---|
| 대상 | 개별(혹은 국소 영역) 샘플 | 전체 데이터 |
| 질문 | 왜 이 결과 도출? | 모델이 어떤 방식으로 작동? |
| 목적 | 설명 / 디버깅 / 고객 대응 | 모델 이해 / 정책 설계 |
-
현대 모델은 복잡한 비선형 구조 → 전체 해석은 제한적 (black box)
-
하지만 국소 영역에서는 단순한 모델(예: 선형)로 근사 가능 → 이를 기반으로 Local 해석 수행
-
설명용 데이터 출처 : 신용 등급(Credit_Score)을 세가지 분류로 나누는 데이터
- GOOD, STANDARD, BAD
Global Interpretability
- MDI(Mean Decrease in Impurity)
- PI
- SHAP
- PDP
- ICE
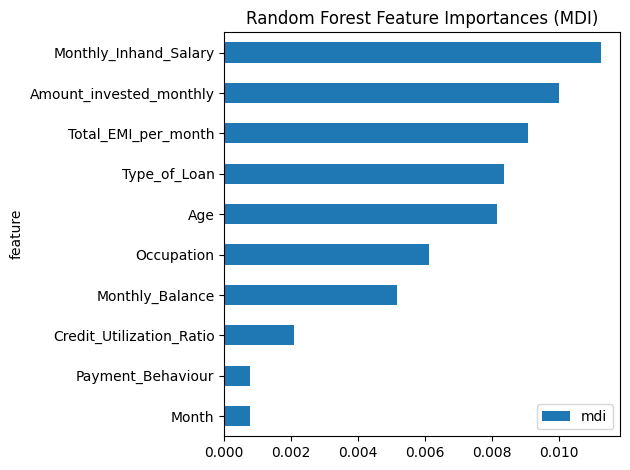
MDI (Mean Decrease in Impurity)
-
트리 모델에서 각 변수가 split에 사용될 때 감소시킨 impurity(Gini, MSE 등)를 기준으로 중요도를 계산
-
많이 쓰일수록, 그리고 크게 impurity를 줄일수록 중요도가 높아짐
Permutation Importance(순열 중요도)
- 특정 변수(F)를 의도적으로 망가뜨려 모형의 F 의존도를 측정
과정 요약
- 1단계 : baseline 성능 측정 ()
- 2단계 : 특정 변수에 대한 permutation 수행 후 성능 측정 ()
- 3단계 : 반복 수행 후 평균 성능 감소량 계산
-
RandomForestRegressor의 baseline 성능 : 0.9921
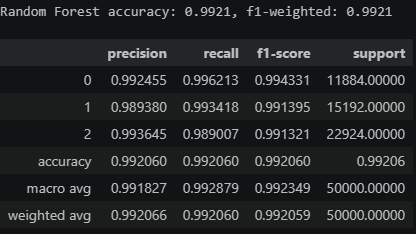
-
순열 n(n=5)번 생성 후 각 반복에서 성능 감소량 () 계산
| Feature | Iter 1 | Iter 2 | Iter 3 | Iter 4 | Iter 5 |
|---|---|---|---|---|---|
| Interest_Rate | 0.26266 | 0.25826 | 0.26274 | 0.25870 | 0.26094 |
| Payment_of_Min_Amount | 0.15952 | 0.16074 | 0.16108 | 0.15980 | 0.16022 |
| Num_Bank_Accounts | 0.11460 | 0.11348 | 0.11512 | 0.11374 | 0.11266 |
| Num_of_Delayed_Payment | 0.07610 | 0.07588 | 0.07668 | 0.07734 | 0.07500 |
| Month | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 |
| Credit_Utilization_Ratio | 0.00000 | 0.00008 | -0.00002 | 0.00010 | 0.00002 |
| Payment_Behaviour | 0.00002 | -0.00002 | 0.00010 | -0.00006 | 0.00004 |
| Monthly_Balance | 0.00016 | 0.00016 | 0.00016 | 0.00018 | 0.00030 |
-
평균 성능 감소량(PI) 계산

-
PI 상위 5위 (망가진 값이 들어오면 성능 변화 큼)
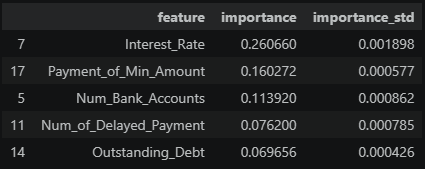
-
PI 하위 5위 (망가진 값이 들어와도 성능 변화 없음)
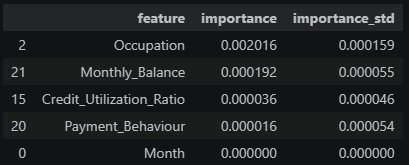
-
해석
- 성능 감소량이 클수록 해당 변수에 대한 모델 의존도가 높음
- 일부 변수는 음수 값이 발생할 수 있으며, 이는 permutation 후 오히려 성능이 약간 개선된 경우로, 변수의 영향이 거의 없거나 노이즈 수준임을 의미
MDI VS PI
- 완전히 랜덤 노이즈 컬럼 하나를 추가했을 때,
해당 컬럼의 중요도는 각자 어떻게 나오는가?- 타이타닉 데이터셋에 무작위 수치형 변수(random_num)와 무작위 범주형 변수(random_cat)를 추가하여 실험
MDI
- 아무런 정보가 없는 random_num 변수가 매우 높은 중요도를 가진 것으로 나타남. 이는 모델이 수치형 변수의 미세한 차이를 이용해 학습 데이터에 과적합되었기 때문
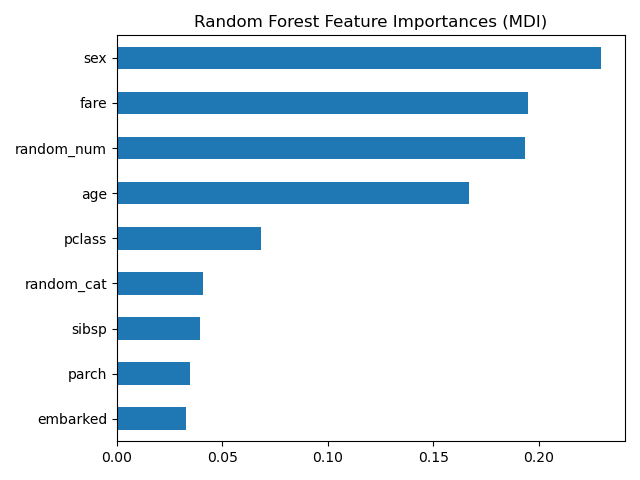
순열 중요도 (Permutation Importance)
- 테스트 데이터에서 측정했을 때, 무작위 변수들의 중요도는 거의 0에 가깝게 낮게 측정.
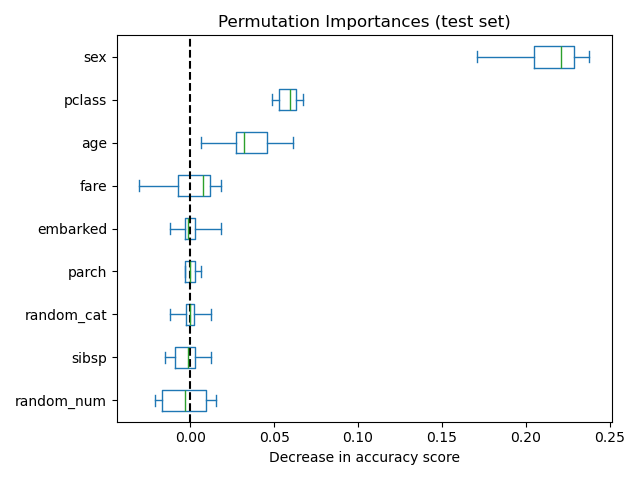
위 결과를 기반으로 보는 MDI의 단점
-
고유값(cardinality)이 높은 변수(ie. random_num)에 대해 중요도를 과대평가하는 경향이 있음 -> 실제 예측에는 도움이 되지 않는 변수를 중요하다고 판단할 수 있음
-
MDI는 학습 데이터만 사용하여 계산하기 때문에, 테스트 데이터에 동일 법칙이 적용되지 않을 수 있음 (과적합)
협력게임
- 여러 플레이어가 함께 어떤 결과 를 만들었을 때, 그것을 어떻게 나눌 것인가?
-
플레이어 집합 :
-
협력체(Coalition) S는 N의 부분집합
-
가치함수 :
협력 게임의 난제
-
핵심 문제는, v에 대한 기여도를 직접적으로 정의할 수 없다는 점이다. 예를들어,
일 때
일 때
일 때- 와 같이 교호작용이 있을 경우 시너지 가치를 단순히 1이나 2의 기여도라고 정의 할 수 없는 문제가 있다.
-
그래서 나온 개념이 한계 기여도(marginal contribution)이다
- 이미 어떤 집합 S가 있을 때, i가 추가되면서 증가한 가치 :
-
즉, 새로 들어온 플레이어가 협력체의 가치가 얼마나 '점프'했나를 잣대로 삼는 방법이다.
-
하지만 marginal contribution 방식의 치명적인 문제가 있다면, 플레이어가 들어오는 순서에 따라 각자의 기여도에 차이가 생긴다.
합류 순서 1 한계 기여도 2 한계 기여도 1 11 10 2 -
따라서 특정 순서에 편향되지 않도록, 가능한 모든 순서의 기여도를 평균 내는 방식이 필요하다
Shapley Value
- 플레이어가 여러 명 있고, 누가 먼저 들어오냐에 따라 기여도가 달라진다
- 이때 공정하게 기여도를 계산하는 방법은?
-
해결 방법 : 모든 순서를 다 고려해서 평균 내자
-
-
: 가능한 모든 순서 (Permutation)
-
: 그 순서에서 보다 먼저 들어온 플레이어의 집합
-
: i가 들어오면서 증가한 가치 (marginal contribution of i)
-
결국 Shapely Value는 모든 순서에서의 marginal contribution 평균
-
- 이때, Shaply Value는 [효율성, 위장 플레이어, 대칭성, 가산성]을 모두 만족하는 공정한 분배의 성질을 가진다.
출처 : Shapely Value와 SHAP에 대해서 알아보자 with Python
효율성 (Efficiency)
- 총상금은 게임에 참여한 모든 플레이어에게 남김없이 나눠줘야 한다
대칭성 (Symmetry)
- 두 플레이어의 기여도가 같다면, 가져가는 상금도 같다
위장 플레이어 (Dummy Player)
- 기여도가 없는 플레이어에게 상금을 주지 않는다
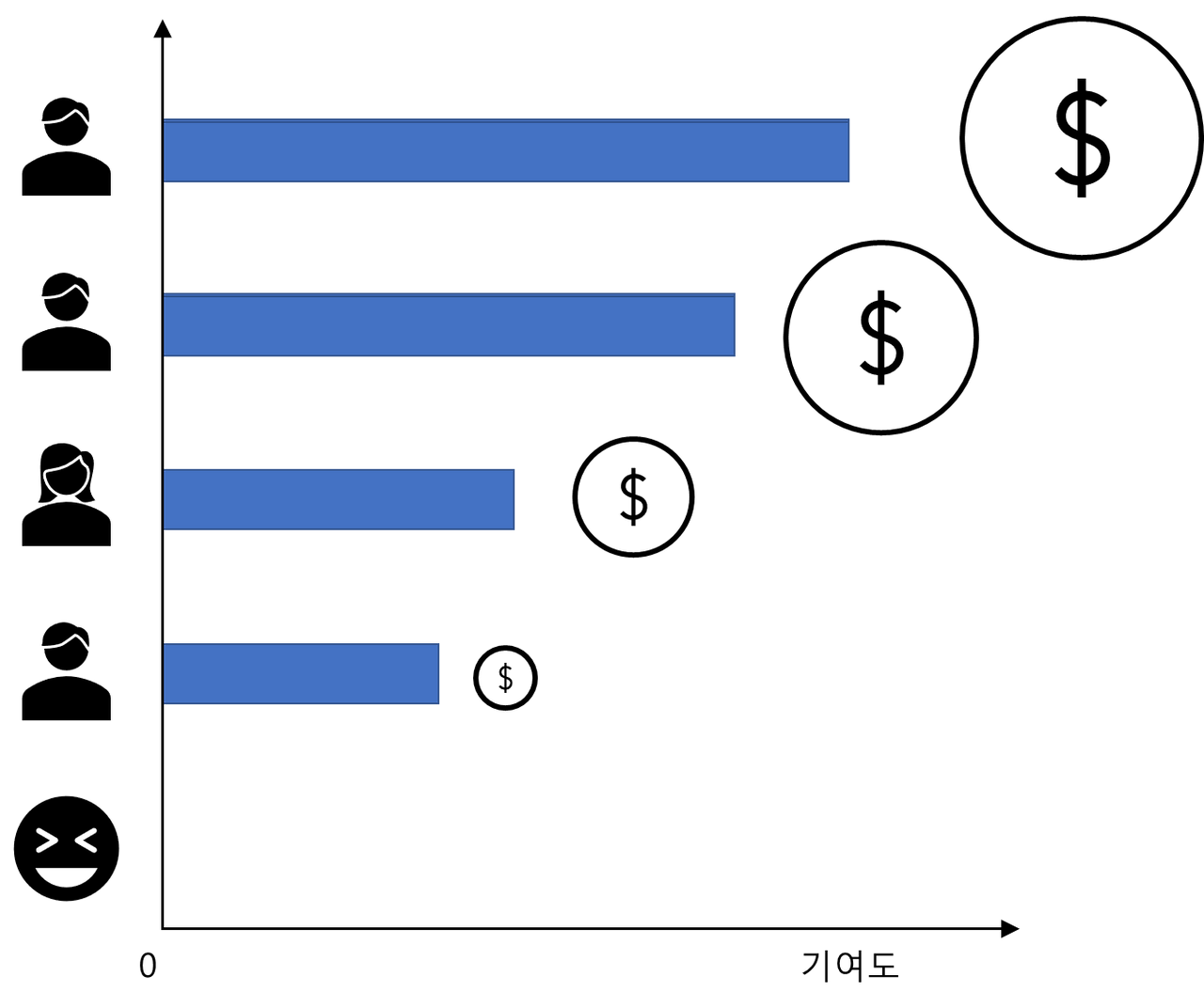
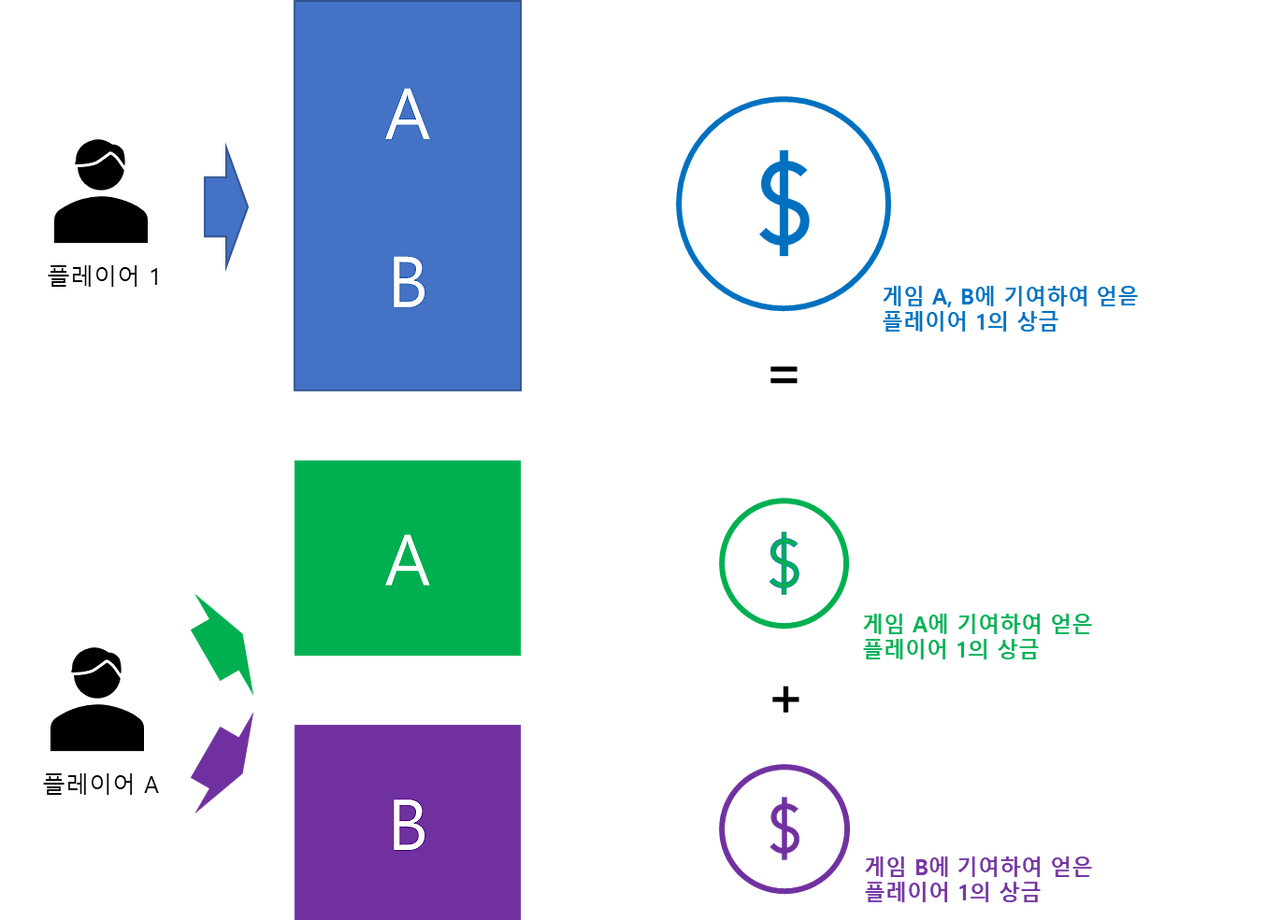
가산성 (Additivity)
- 한 플레이어가 k개의 게임에서 얻은 상금의 합은, 각 게임에서 얻은 상금의 합과 일치해야 한다
SHAP (SHapley Additive exPlanations)
- Shapely Value에서 플레이어를 변수, 가치함수를 모델 예측값으로 치환한 것이 SHAP의 기본 원리이다
-
baseline : 아무 변수도 없을 때의 평균 예측값
-
subset : 일부 변수(S)만 있을 때 기대되는 예측값
-
marginal contribution : 변수 가 추가되었을 때 예측값 변화량
-
SHAP value() : 변수 가 subset S에 추가될 때의 예측값 변화량(marginal contribution)을 모든 가능한 S에 대해 평균낸 값이다
SHAP summary (Mean |SHAP|)
- 각 변수의 SHAP value 절대값을 평균낸 값으로, 모델 예측에 대해 해당 변수가 얼마나 큰 영향을 미치는지 나타냄 (MDI, PI와 유사)
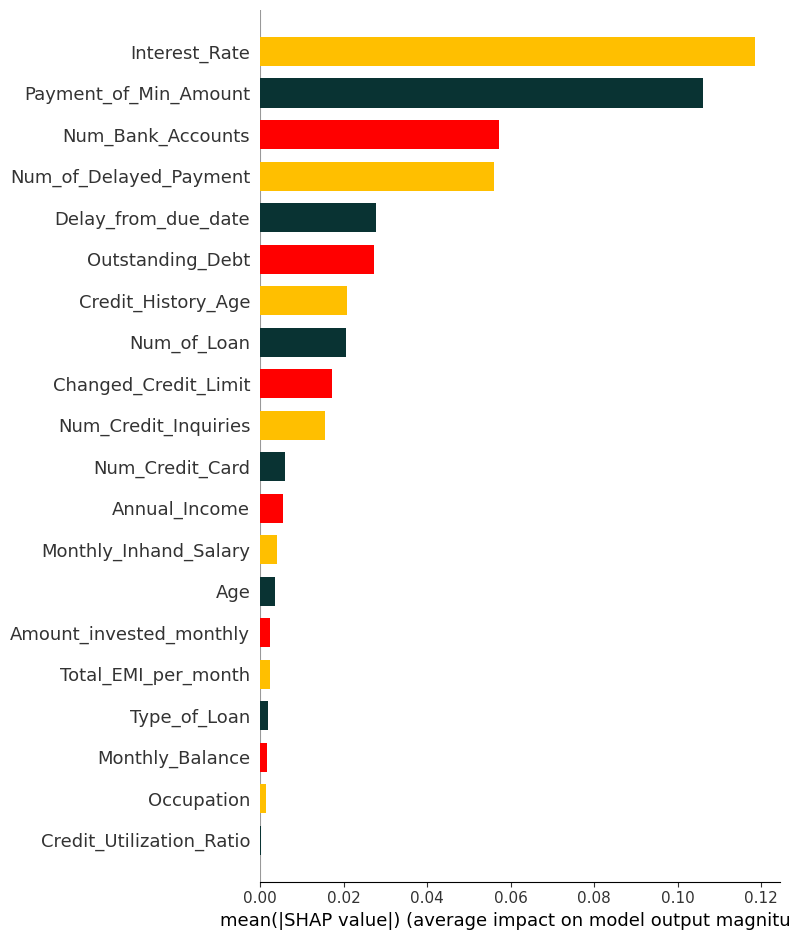
Mean |SHAP| VS PI
-
PI는 변수 하나를 고립시켜 성능 저하를 보지만, 많은 데이터에서는 변수들이 서로 독립적이지 않으며, 동일하거나 유사한 정보를 가진 변수들이 존재할 수 있다.
-
극단적인 예시로,
Interest_Rate에 -1을 곱해neg_Interest_Rate를 추가하고, PI와 mean |SHAP|를 비교해보자
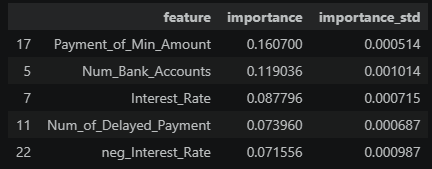
-
기존에 하나만 있을 때 0.26이었던 중요도가, 똑같은 정보(부호만 반대)를 가진 변수가 추가되자 0.08과 0.07 수준으로 급격히 분산되며, 그 합이 작아진다.
-
Interest_Rate를 섞어도, 상관관계가 큰 neg_Interest_Rate를 통해 여전히 정보를 파악할 수 있기 때문에, 성능 하락폭이 작게 측정되어, 중요도가 낮게 평가된다.
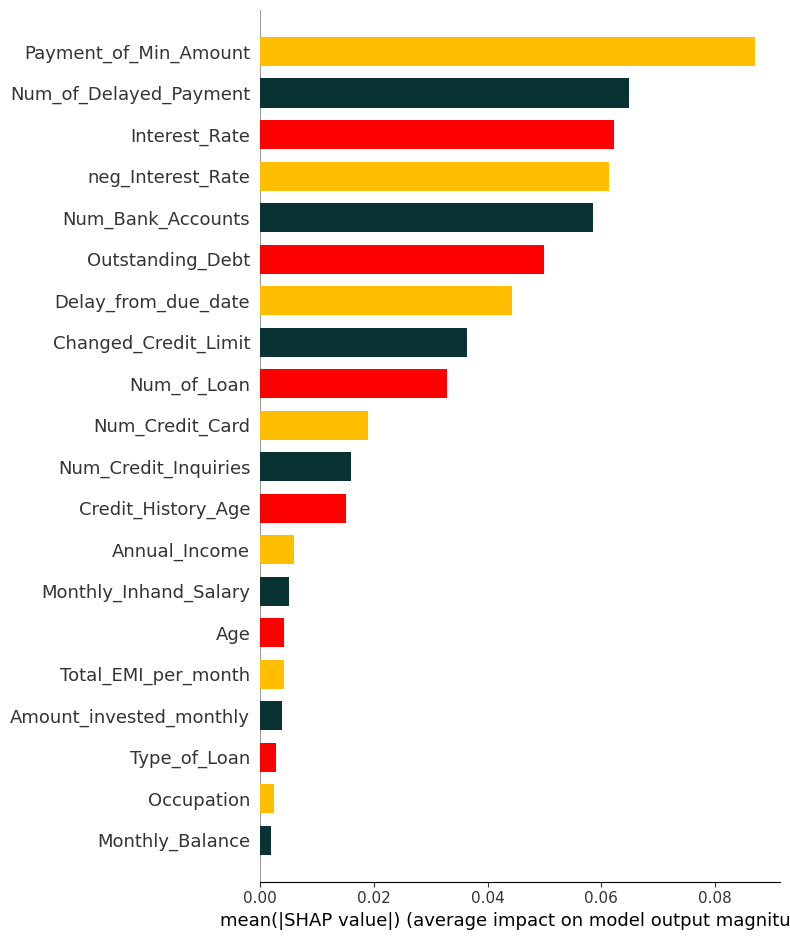
-
SHAP은 기여도를 분해하는 방식이기 때문에, 동일한 정보를 가진 변수들 사이에서 기여도를 나누어 갖는다.
-
그 결과 개별 변수의 mean(|SHAP|) 값은 감소하지만, 두 변수의 중요도를 합산하면 원래 변수의 영향력과 유사한 수준을 유지하는 경향이 있다.
-
SHAP은 기여도를 공정하게 나눠줄 뿐, 중복된 정보의 진짜 원인을 구분해주지는 않기 때문에, Feature Grouping이나 Conditional SHAP와 같은 추가적인 기법이 필요하다.
SHAP summary (Beeswarm)
- 개별 샘플의 SHAP value를 그대로 보여주되, 겹치지 않게 퍼뜨려서 분포, 방향 변수값까지 동시에 보여주는 plot
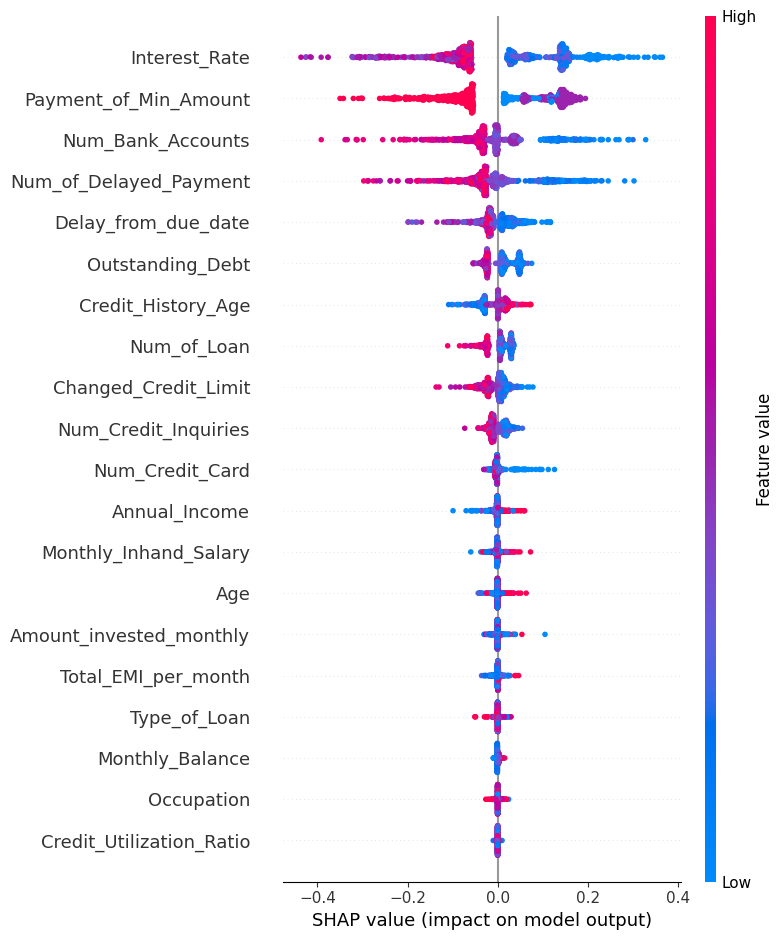
-
전반적으로 변수 값이 클수록(red), 작을수록(blue) SHAP value의 방향이 잘 구분되는 모습을 보인다.
-
그러나 일부 구간에서는 동일한 feature value에 대해 SHAP value가 서로 다른 방향으로 나타나는 경우가 존재하며,
이는 해당 변수의 효과가 다른 변수에 의해 영향을 받는, 즉 상호작용이 존재할 가능성을 시사한다.
SHAP Dependence Plot
- 특정 변수 하나를 선택해,
그 변수의 SHAP value를 feature 값 기준으로 펼쳐서 2D로 표현하고,
색을 통해 다른 변수와의 상호작용 가능성을 드러낸 plot
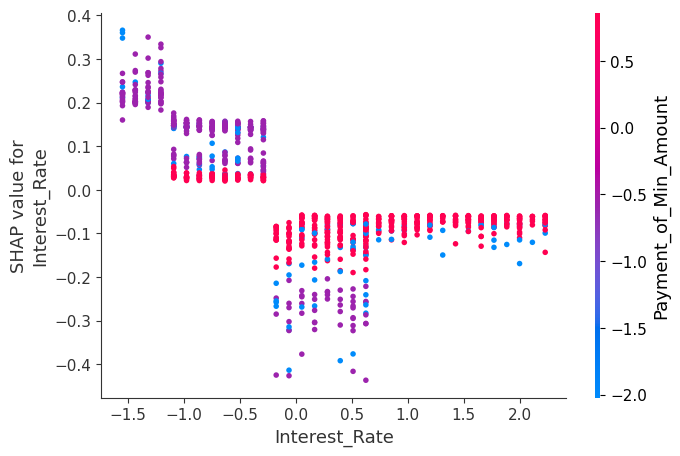
Interest_Rate주효과
- Interest_Rate가 낮을수록 GOOD에 기여하고, 높을수록 GOOD을 감소시킨다.
- Interest_Rate가 약 -1.0 ~ -0.8 부근, -0.2 ~ 0.2 부근에서 기여도가 크게 바뀐다.
Payment_of_Min_Amount과 상호작용
-
Payment_of_Min_Amount가 빨간색(Yes)인 경우-
Interest_Rate에 관계 없이 SHAP value가 비교적 좁은 범위에 분포 -
Interest_Rate에 따른 영향이 일정하게 유지되는 경향을 보임
-
-
Payment_of_Min_Amount가 보라색(기록되지 않음)인 경우-
Interest_Rate의 임계치에 따라 SHAP value가 크게 바뀌며, 크게 두가지 그룹(왼쪽 위, 가운데 아래)을 형성함 -
이는 금리와 상환 여부 간의 상호작용 및 비선형 관계가 존재함을 시사한다.
-
-
Payment_of_Min_Amount가 파란색(No)인 경우-
동일한
Interest_Rate에서도 SHAP value의 분산이 크게 나타남 -
Interest_Rate의 효과가 다른 변수들의 영향을 많이 받는 것으로 해석할 수 있다.
-
SHAP Interaction Plot
- : 모형 최종 예측값
- : baseline, 아무 변수도 없을 때의 평균 예측값
- : 변수 의 SHAP 값
- : 변수 의 주효과 (에 가 없는 상태에서 를 넣었을 때의 기여도 변화)
- : 변수 와 의 상호작용효과 (에 가 있는 상태에서 를 넣었을 때 기여도 변화)
- SHAP value 중, 주효과를 차감한 순수 상호작용 효과를 확인
-
예를 들어, 변수가 세 가지만 있는 단순한 환경을 가정하면 다음과 같다 :
-
① 가 없는 상황에서의 투입 (주효과)
일 때:
일 때:
의미: 이 값들의 평균은 가 아예 세상에 없다고 가정했을 때 가 내는 순수 영향도 -
② 가 있는 상황에서의 투입 (상호작용 효과)
일 때:
일 때:
의미: 라는 파트너가 옆에 있을 때 가 내는 상호작용 영향도 -
③ 최종 도출
= (②의 평균) - (①의 평균)
-
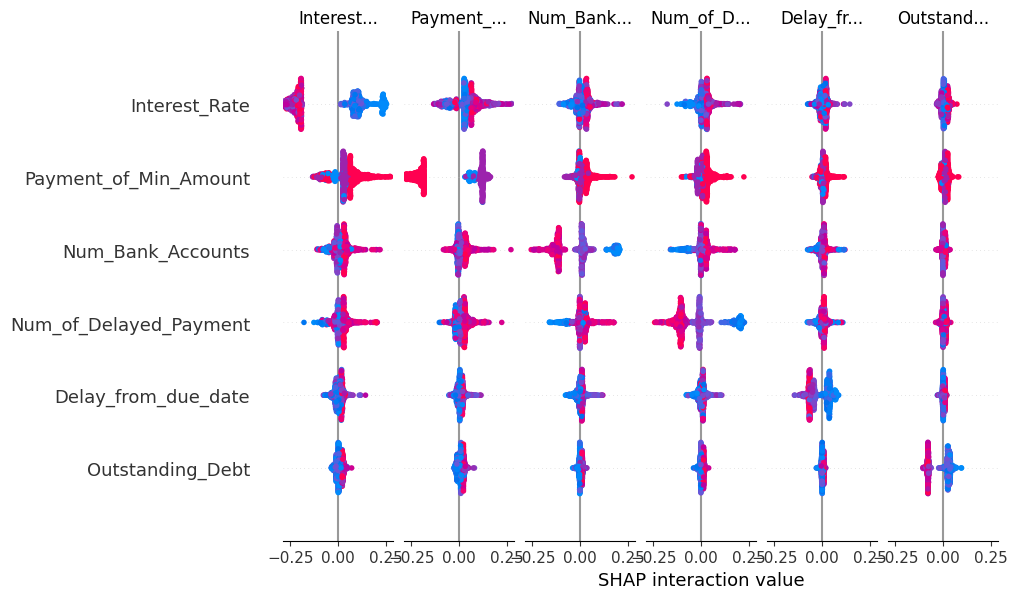
- 대각선 (i,i) → main effect
- 대각선 밖 → interaction : 두 변수가 함께 있을 때 모델 출력에 얼마나 영향을 주는가
- 퍼짐(폭)이 클수록 모델 출력에 영향력이 큰 상호작용
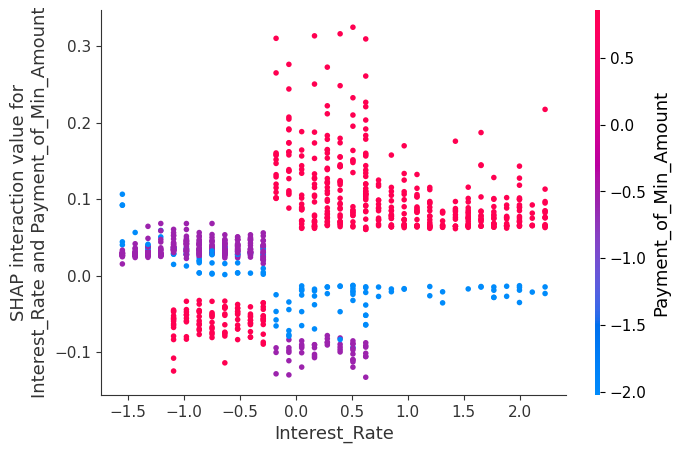
- 빨강 (
Payment_of_Min_Amount= Yes)
x > 0 구간 → interaction 양수 (위쪽)
→ 두 변수가 함께 있을 때 Good 방향으로 추가 기여
x < 0 구간 → interaction 음수 (아래쪽)
→ 두 변수가 함께 있을 때 Good 방향 기여를 감소
- 보라 (
Payment_of_Min_Amount= 기록 없음)
x > 0 구간 → interaction 음수 (아래쪽)
x < 0 구간 → interaction 양수 (위쪽)
→ 빨강과 반대로 작용하는 상호작용 효과를 보이며, 상호작용의 강도가 낮은 편 - 파랑 (
Payment_of_Min_Amount= No)
대부분 interaction이 0 근처 or 음수
→ interaction이 거의 없고,Interest_Rate효과가 단독으로 작용
PDP (Partial Dependence Plots)
- 특정 변수 값이 변할 때, 평균적으로 예측이 어떻게 변하는가
과정 요약
- 1단계 : 특정 변수의 값을 하나 고정
- 2단계 : 모든 샘플에 대해 그 값으로 바꿈
- 3단계 : 예측값 평균 계산
- 4단계 : 고정값을 변경하며 반복
- 1단계 : (sklearn
PartialDependenceDisplay기준) percentile 기반으로 고정값()을 선정
percentile = [0.01, 0.02, ..., 0.99]-
2단계 : 모든 샘플에 대해 해당 값을 로 설정
-
3단계 : 예측값 평균 계산
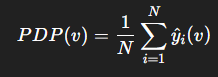
ICE (Individual Conditional Expectation) Plot
- 각 샘플마다, 그 변수 변화에 따라 예측이 어떻게 변하는가
과정 요약
- PDP와 동일한 과정을 거치지만, 평균을 내지 않고 각 샘플별로 따로 그림
예시 (위 PDP plot과 같이 보기)
Interest_Rate에 대한 PDP & ICE Plot (PD = GOOD 확률)
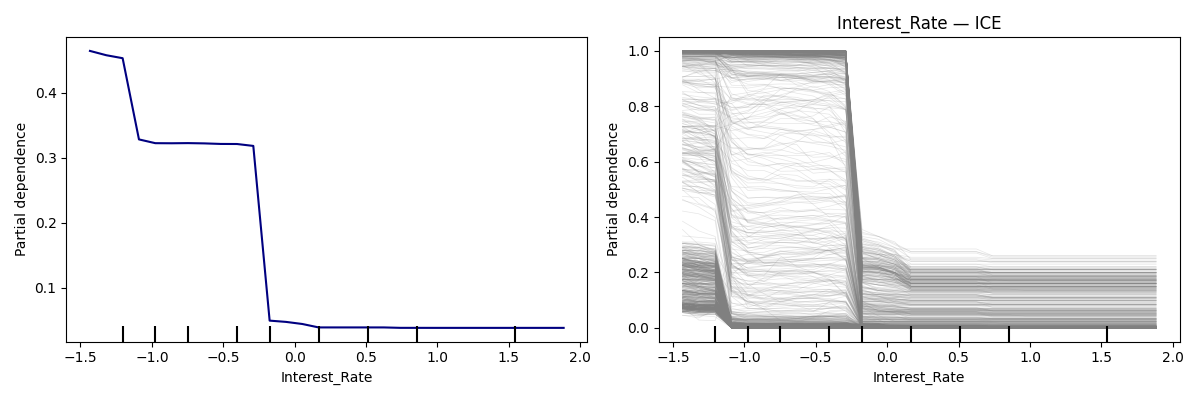
- -1.2 부근과 -0.2 부근에서 두 번의 큰 계단식 하락
- (첫 번째 하락): 금리가 아주 낮은 수준(-1.2 부근)에서 이미 GOOD 확률이 꺾이기 시작하는 집단
- (두 번째 하락): 금리가 0에 가까워질 때까지 높은 GOOD 확률(1.0 부근)을 유지하다가, -0.2 지점에서 벼랑 끝처럼 추락하는 집단
→ 가설 : 다른 지표들은 우량(Good)하지만, 금리가 특정 임계치를 넘는 순간 모델이 더 이상 Good으로 볼 수 없다고 판단한다
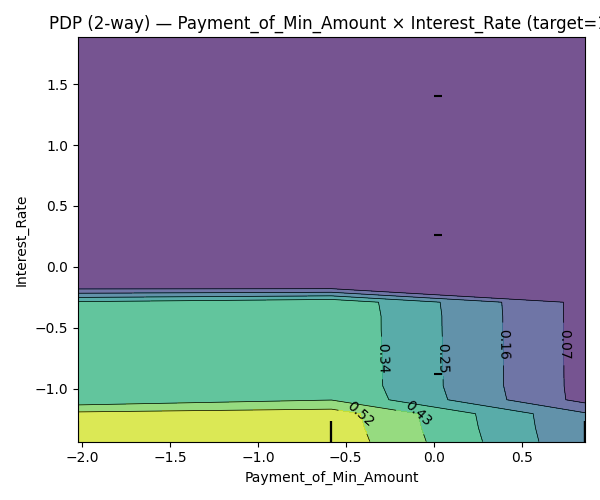
n-way PDP
- 두 변수의 상호작용 확인
Interest_Rate&Payment_of_Min_Amount에 대한 2-way PDP Plot (PD = GOOD 확률)
ALE (Accumulated Local Effects)
- 실제 존재하는 변수 조합만 고려하여
PDP의 약점 (비현실적인 변수 조합):
-
'침실 수'와 '평수' 데이터가 있다고 해보자
- PDP의 행동: 10평짜리 원룸 데이터 샘플을 가져와서, 침실 수만 '20개'로 바꿔버리고 모델에 넣어 예측값을 구한다
- 결과: 모델은 "10평에 방이 20개인 집"을 본 적이 없으므로 엉뚱한 값을 내뱉고, PDP는 이 왜곡된 값을 평균 내어 그래프를 그리게 됨
ALE의 접근 : 변수를 직접 바꾸는 대신, 아주 좁은 구간(Local) 내에서 변수가 살짝 변할 때 예측값이 얼마나 변하는지(차분)를 계산한 뒤, 이를 누적(Accumulate)한다
알고리즘
1) 구간 나누기 (Conditional Distribution) : 데이터를 (기준 feature로) 여러 개의 작은 구간으로 나눈다
2) 구간별 로컬 변화 측정 (Local Effects): 각 구간 안 데이터를 시작점과 끝점으로 바꿔본 뒤, 예측값이 얼마나 변했는지(차이)를 구해서 그 구간의 평균 변화량을 계산한다
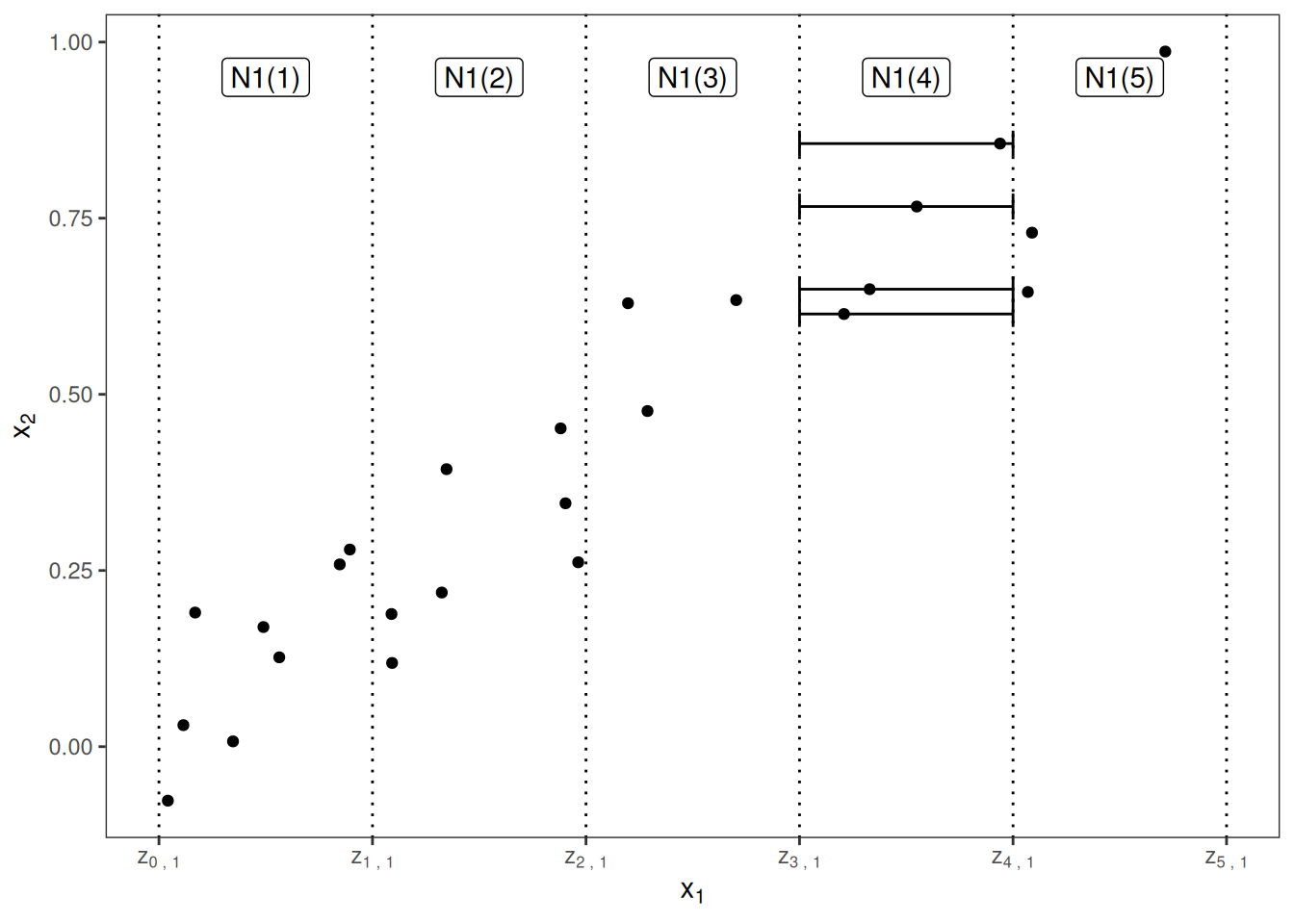
3) 누적 및 센터링 (Accumulation & Centering) : 이 작은 구간들의 변화량을 첫 구간부터 차례대로 쌓아 올린 후(적분), 전체 평균이 0이 되도록 이동 시킨다
- ALE는 절대적인 예측값이 아니라, 변화량을 측정한다
- 좁은 구간 안에서의 순수한 변화량을 누적하여 전체 범위에 따른 순수 효과 곡선을 만드는 거다
-
ALE는 특정 구간에 있는 샘플들만 사용하기 때문에, "기준 변수 수준에서 실제로 나타날 수 있는 다른 변수들의 조합"을 자연스럽게 유지한다.
- 즉, 모델에게 "비현실적인 데이터"를 물어보지 않고, "현실적인 범위 내에서, 연봉이 조금 오르면 어떻게 되니?"라고 묻는 것과 같다
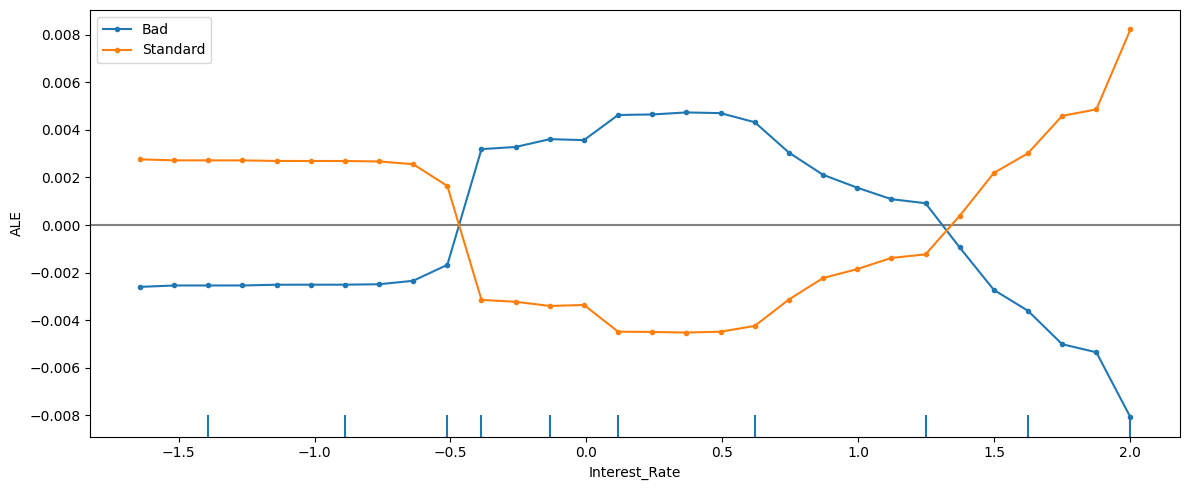
💡 ALE 그래프는 PDP와 비슷해 보이지만, y축의 의미가 결정적으로 다르다
-
y축 (ALE Value): 해당 변수가 평균적일 때와 비교하여 예측값을 얼마나 변화시키는지를 나타낸다
-
y = 0 지점: 해당 변수 값이 전체 평균 수준일 때
-
y > 0: 평균적인 상황보다 해당 클래스(Bad 또는 Standard)로 판정할 확률을 이만큼 더 높인다
- (-0.5 ~ 0.5 구간)
Interest_Rate중간 구간에서는 평균적인 상황보다 'Bad'로 예측할 확률이 약 0.4%p 정도 높아진다
- (-0.5 ~ 0.5 구간)
-
y < 0: 평균적인 상황보다 해당 클래스(Bad 또는 Standard)로 판정할 확률을 이만큼 더 낮춘다
- (-1.5 ~ -0.5 구간)
Interest_Rate가 낮을 때는 평균적인 상황보다 'Bad'로 예측할 확률이 약 0.2%p 정도 낮아진다
- (-1.5 ~ -0.5 구간)
-
-
x축 밑의 바(Rug Plot): 실제 데이터가 어디에 분포해 있는지를 보여주는 bar
-
이 선들이 빽빽한 곳은 실제 데이터가 많이 모여 있는 곳이라 그래프의 선을 믿을 수 있음
-
선들이 드문드문한 곳은 데이터가 거의 없어서 모델이 "추측"을 하고 있을 확률이 높음
-
