스터디
1.linear regression
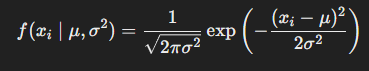
Machine Learning 아서 사무엘의 정의 : 기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야 머신러닝의 목표는 관측된 데이터를 기반으로 현실을 가장 잘 설명할 수 있는(일반화 성능이 좋은
2.Liner Regression 2

회귀분석의 전제 조건 선형성 (Linearity) : 종속 변수 Y와 독립변수 X 사이에 관계가 선형적이어야 한다 확인 방법 : 잔차와 독립 변수 간의 산점도를 통해 선형성을 시각적으로 확인 가능하다 독립성 (Independence) : 각 관측값은 서로 독립적
3.Linear Regression 3
Bias-variance decomposition Bias-variance decomposition(편향-분산 분해)를 사용하여 실제값과 예측값의 차이(예측 오차)를 구성하는 세 가지 요소를 찾아보자 사용할 표기법을 정리하면 아래와 같다 |표기|설명| |:
4.선형회귀분석 프로젝트
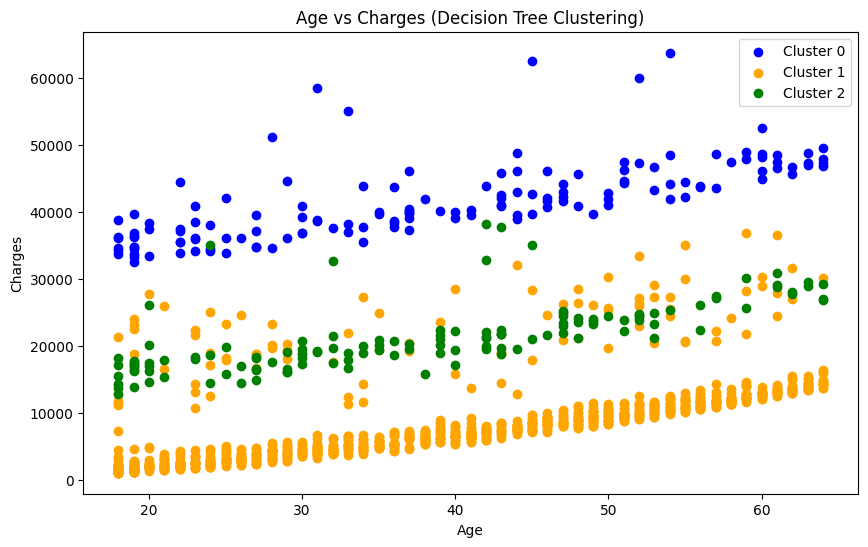
선형회귀분석 프로젝트 24.08.26 ~ 24.09.16(총 2주)까지 스터디에서 진행한 프로젝트에 대한 회고록이다. 사용 데이터는 kaggle의 Medical Cost Personal Datasets이다. 자세한 코드 및 발표자료는 github에 정리되어 있다.
5.Perceptron
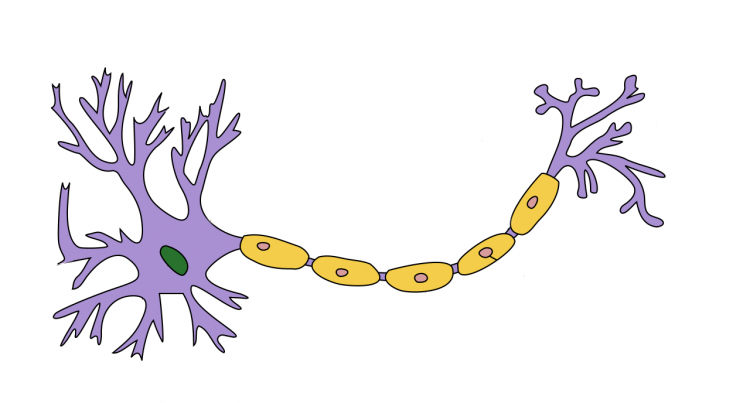
뉴런은 신경계의 기본 단위로, 우리 뇌와 신경 시스템의 정보 처리와 전달을 담당한다.뉴런의 구조수상돌기 : 다른 뉴런이나 외부로부터 전기적 신호를 받아들이는 부분이다. 수상돌기는 여러 신호를 받아들이며, 이를 뉴런의 세포체로 전달한다세포체 : 수상돌기를 통해 받아들인
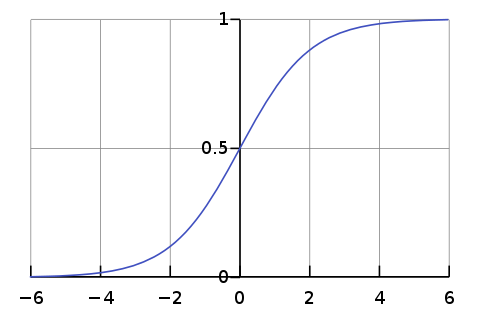
6.Logistic Regression
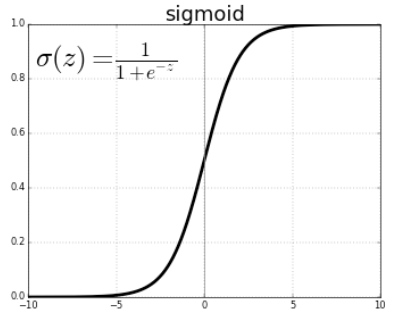
Perceptron은 계단 함수를 사용하여 이진 분류를 진행한다. 즉, 예측값 $$\\hat y$$이 0보다 크면 1, 0보다 작으면 0의 값으로 분류한다.이렇듯 Perceptron의 분류 결과는 명목변수(norminal variable)이다. 명목변수는 단순한 구분기
7.ANN
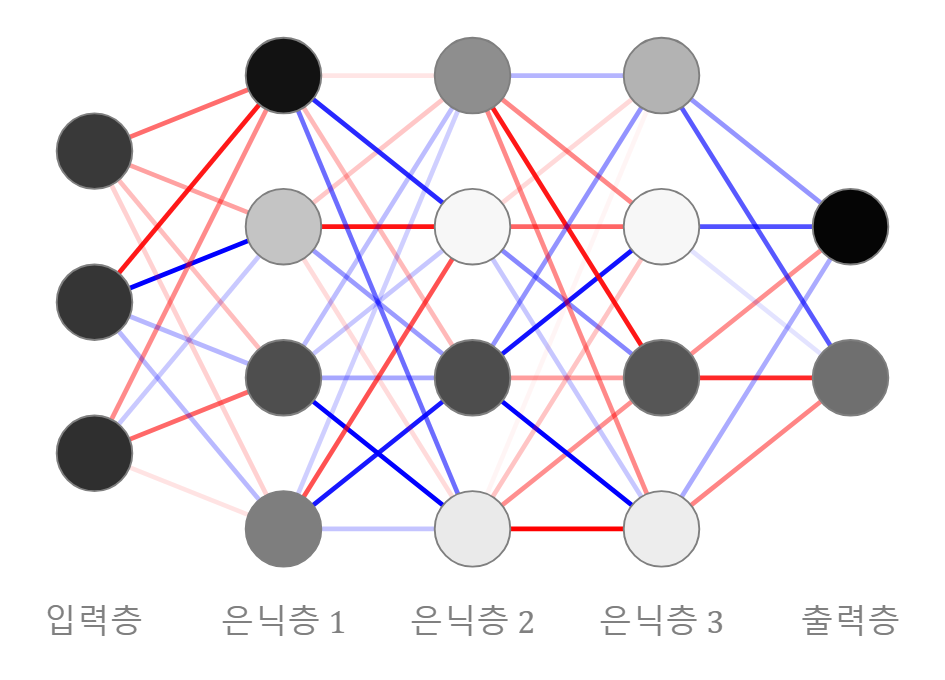
Perceptron은 단일 뉴런으로 구성된 모델로, 입력 데이터에 가중치를 곱한 선형 결합 값에 활성화 함수(계단 함수)를 적용하여 이진 분류를 수행한다. 위 그림에서 표시된 하나의 원이 하나의 Perceptron과 동일한 의미를 갖는다.ANN(Artificial Ne
8.CNN
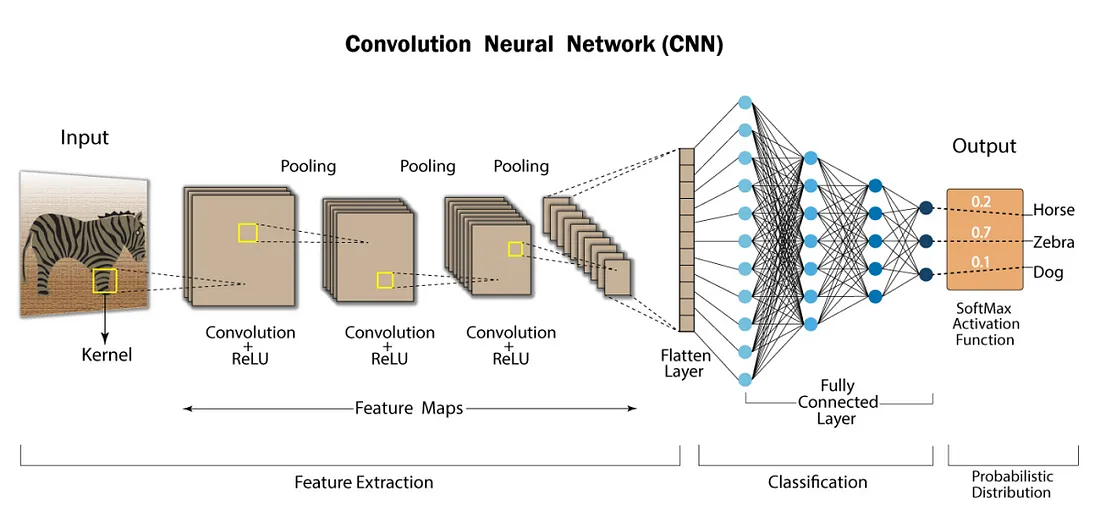
입력 데이터의 공간적 구조를 파악하여 이미지, 객체 인식 분야에서 자주 사용하는 딥러닝 모델.CNN의 구성 요소는 크게 네가지로 나눌 수 있다.합성곱 계층 (Convolution Layer) : 입력 이미지에 복수의 필터(Kernel)를 적용하여 특징 맵(Feature
9.기본 활성화 함수
기본 활성화 함수 정리 | 활성화 함수 | 주요 활용처 | 함수 원형 | 계산 비용 | Vanishing Gradient | Explodi
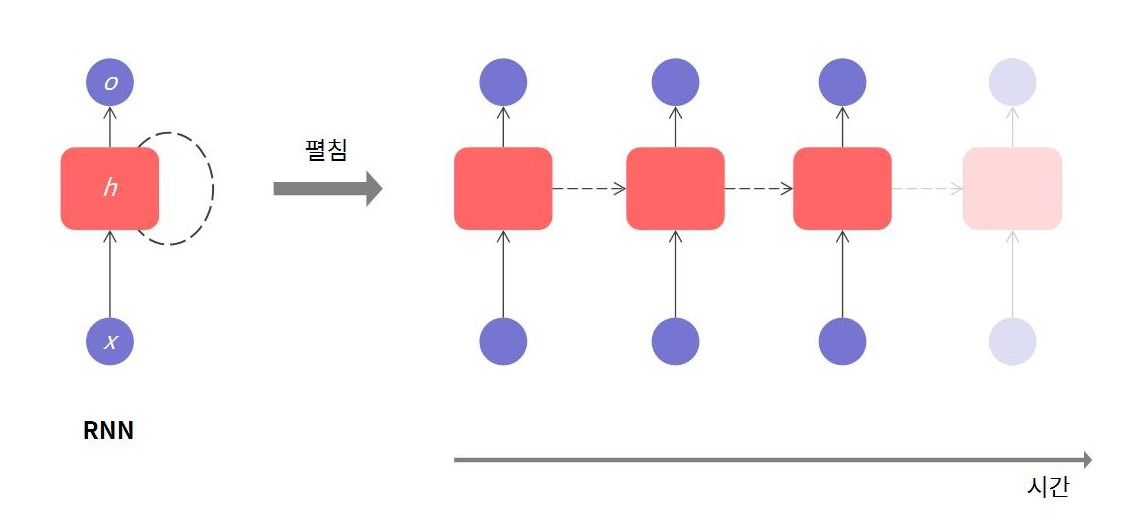
10.RNN

RNN (Recurrent Neural Network) 시계열 데이터나 순차적 데이터를 처리하는 데 특화된 딥러닝 모델 현재 단계의 예측이 단순히 현재 입력에만 의존하지 않고, 이전 입력도 고려한다 고정 크기의 데이터가 아닌 가변적인 시퀀스의 입력 또는 출력
11.LSTM
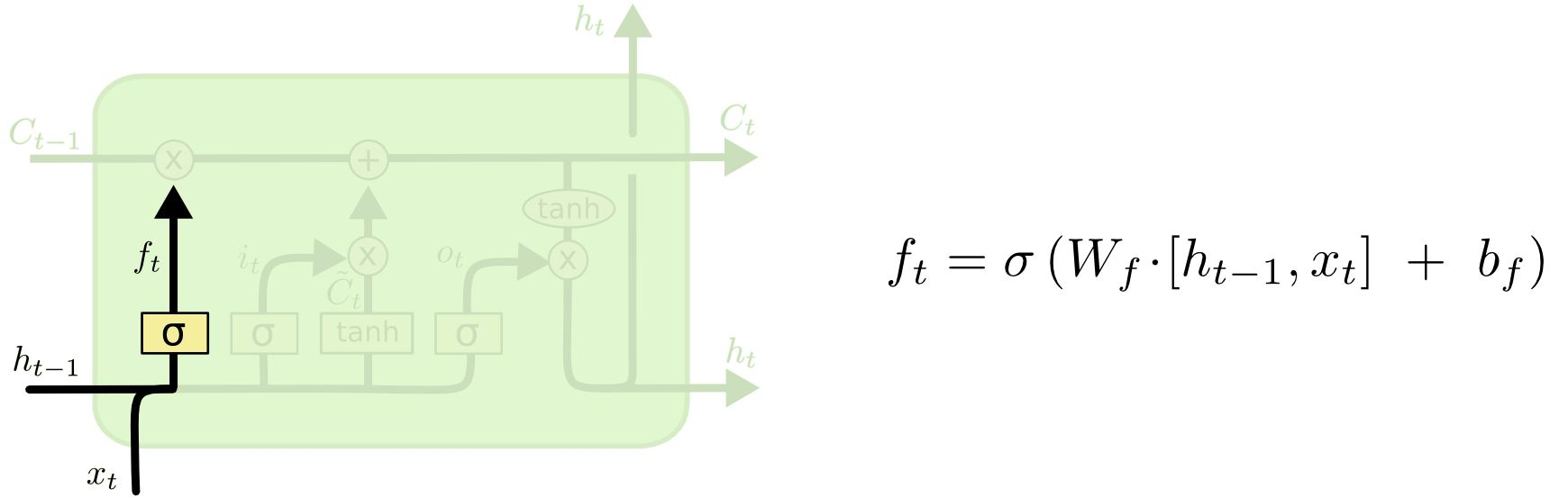
LSTM LSTM(Long Short-Term Memory) : 순환 신경망(RNN)의 구조를 기반으로 발전된 신경망으로, 셀 상태와 입력 게이트, 출력 게이트, 망각 게이트를 통해 기존 RNN이 가진 기울기 소멸 문제(vanishing gradient)를 완화하고,
12.워드 임베딩
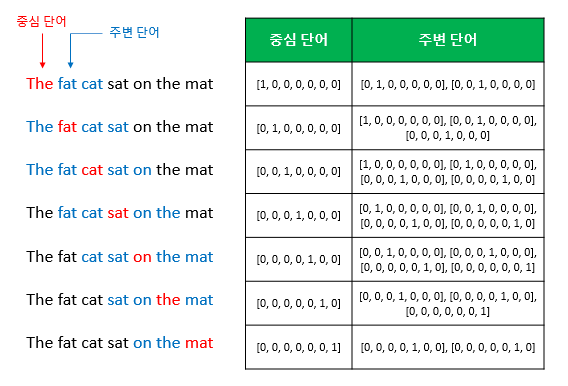
텍스트 데이터를 수치형 데이터로 변환하는 기법으로, 자연어 처리(NLP) 모델에서 핵심적으로 사용된다.워드 임베딩은 어휘의 단어나 구문을 고정 크기의 실수 벡터로 매핑하며, 이를 위해 언어 모델링 및 특징 학습 기술을 활용한다.단어와 구문을 임베딩 형태로 표현하면 구문
13.Basic Attention Mechanism
비동기/동기를 기준으로 나누어 특징을 살펴보자시퀀스의 입력, 출력 길이가 다른 경우 비동기적 Seq2Seq(Encoder-Decoder) 모델을 사용한다.source : RNN 개념과 Encoder-Decoder 구조비동기적 Seq2Seq의 기본 구조는 다음과 같다 (
14.GAN
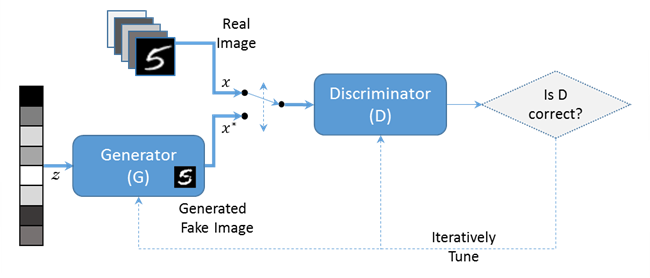
source : IT 위키GAN(Generative Adversarial Network)은 생성 모델 중 하나로, "Generator"와 "Discriminator"라는 두 개의 신경망이 서로 경쟁하며 학습하는 방식으로 동작한다.데이터를 "잘" 생성한다는 것은, 단순히
15.베이지안
빈도주의 확률 VS 베이지안 확률 🎲 빈도주의(Frequentist) 확률 : 반복 가능한 실험 : 어떤 사건이 무한히 반복되었을 때의 비율로 해석하며, 객관적인 수치이다.
16.Bayesian Linear Regression
베이지안 추정 모수에 대해 사전적으로 가지고 있던 믿음(Prior)과, 관측된 데이터를 반영한 정보(Likelihood)를 바탕으로 모수의 사후 분포(Posterior)를 추정하는 과정이다. 이때, 모수는 고정된 값이 아니라 확률 변수로 간주되며, 추정의 결과는 하나의
17.Naive Bayesian Classifier
Naive Bayesian Classifier(NBC) 순진함 + 베이즈 정리 => 분류 Naive (simple or idiot) "입력 변수 [$$x1, x2, ... x_n$$]은 주어진 클라스 $$y$$에 대해 서로 조건부 독립이다" 라는 매우 강한
18.ResNet
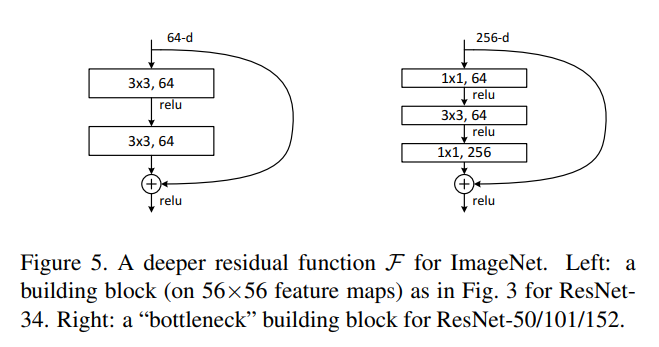
깊은 네트워크와 ResNet Deep Residual Learning for Image Recognition > 성능 저하 (Degradation Problem) 불필요한 학습은 개선이 아니라 왜곡이다 자신의 정체성(Identity)를 잊지 않는 것이 중요하다 일반
19.Transformer
Transformer 모델의 등장 배경 > #### Seq2Seq 모델의 한계점 장기 의존성 문제 : 시퀀스의 길이가 길어질수록 초반부의 중요한 정보가 후반부까지 잘 전달되지 않고, 정보가 소실되거나 변질되기 쉬운 현상 LSTM, GRU와 같은 게이트 기
20.Multi-Task Learning
MTL 같이 학습하는 과제들에 대한 시너지를 기대 둘 이상의 과제를 동시에 학습하는 머신러닝 기법 비유 : 관점 1) 사람의 학습을 모방. 새롭게 배우는 task A에 대해, 이미 알고 있는 유사한 task A'의 지식을 통해 학습 난이도를 완화
21.GMM(Gaussian Mixture Model)
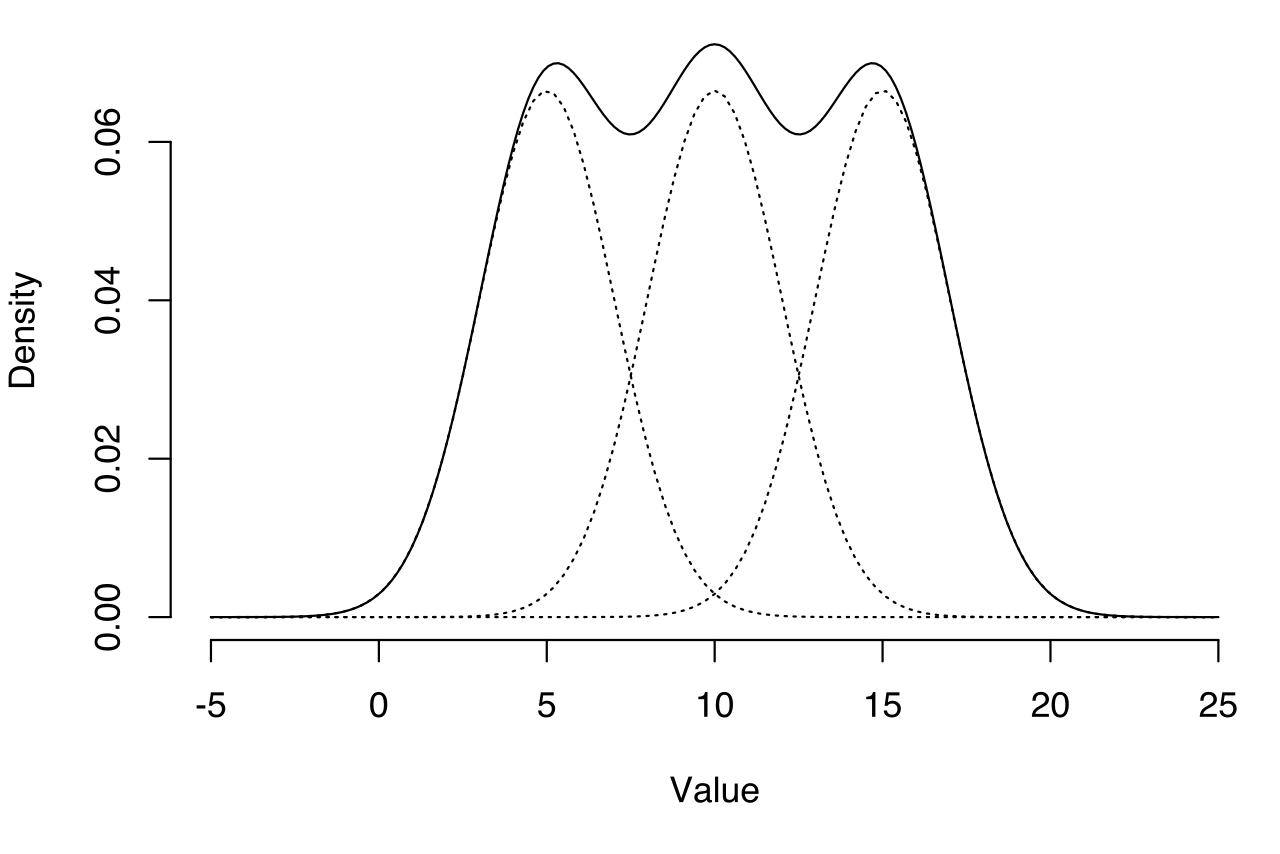
복잡한 데이터는 우리가 알고 있는 하나의 분포 모양으로 설명할 수 없다데이터는 단일한 분포 하나로는 설명되지 않는 경우가 많다. 예를 들어, 사람들의 키 분포에서 남성과 여성 집단이 섞여 있다면 전체 분포는 두 개의 정규분포가 합쳐진 모양을 보일 것이다.이처럼 하나의
22.GCN (Graph Convolution Network)
그래프 자료구조를 다루기 위해 설계된 신경망 구조source : Tistory기존 DNN(CNN, RNN 등)은 격자(Grid) 자료 구조를 전제로 하며, 보통 하나의 샘플(row, sequence)을 입력받아 그 샘플 자체에 대한 예측값을 출력한다그러나, 이러한 DN
23.XAI - Global Interpretation
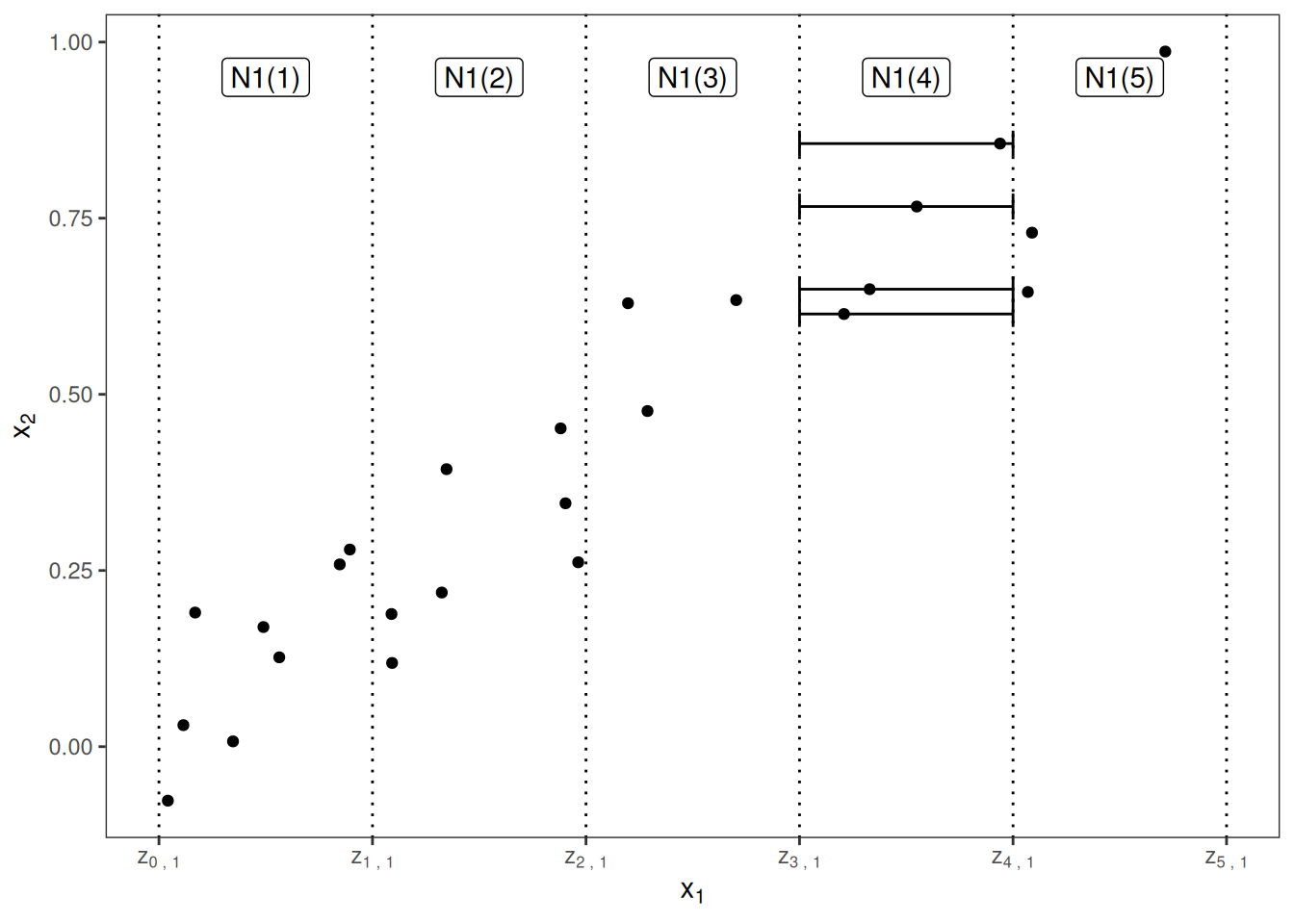
로컬 해석력(Local Interpretability) VS 글로벌 해석력(Global Interpretability) 특정 미적분 문제 풀이 방법 VS 미적분 문제 전체 풀이 전략법 | 구분 | Local | Global | | ---