1. 딥러닝
1.1. 인공 신경망
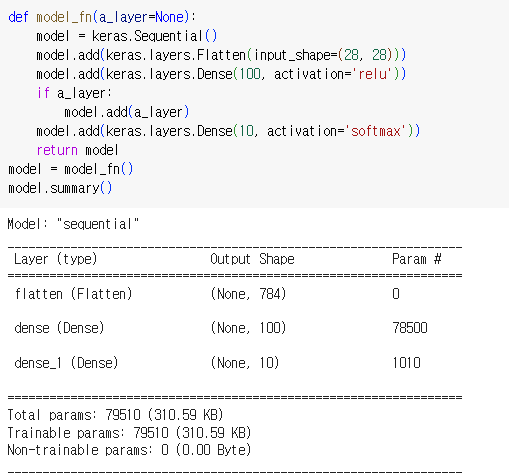
1.1.1. 패션 아이템 자동 분류 인공 신경망 모델 생성
1.1.1.1. 데이터 확인
-
패션 아이템을 자동으로 분류하는 인공 신경망 모델 생성
-
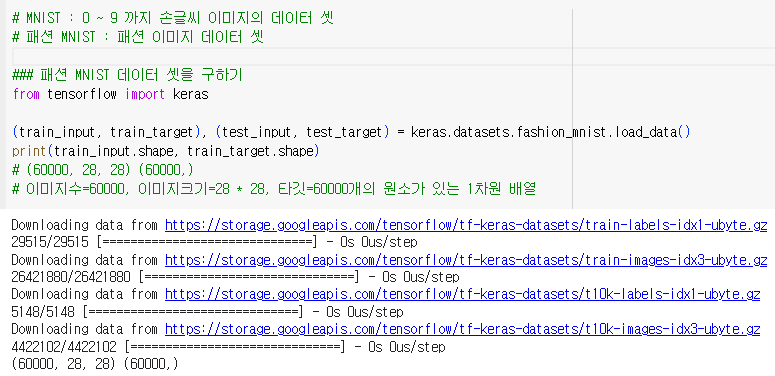
MNIST : 0 ~ 9 까지 손글씨 이미지의 데이터 셋
-
패션 MNIST : 패션 이미지 데이터 셋
-
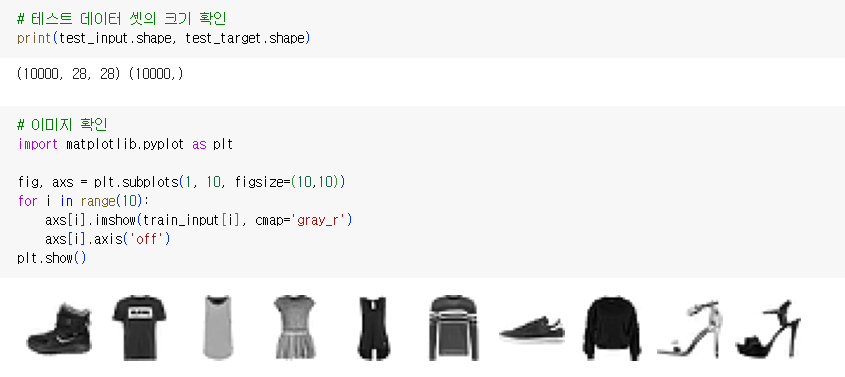
테스트 데이터 셋의 크기 확인 및 이미지 확인
-
패션 아이템 별로 레이블이 정해져 있다.


-
로지스틱 회귀 모델로 패션 아이템 분류
-
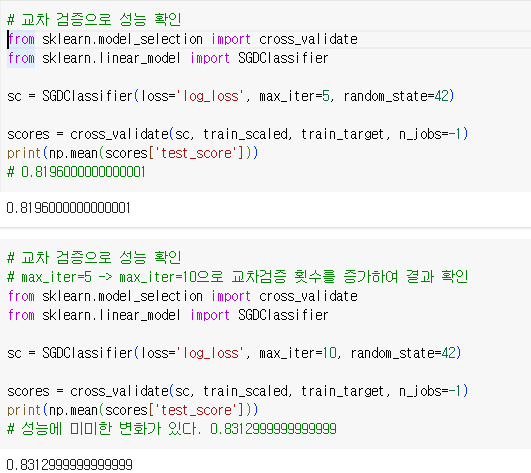
전체 샘플의 수가 60000개를 이루어 한번에 학습하는 건 효율이 떨어짐
-
따라서 확률적 경사 하강법을 적용하여 학습 실시
-
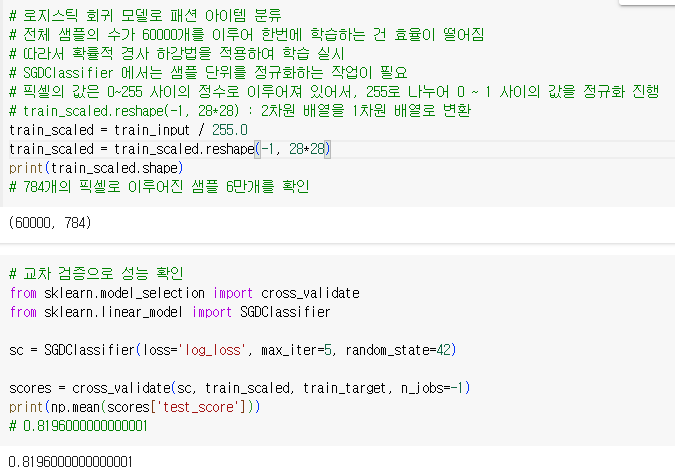
SGDClassifier 에서는 샘플 단위를 정규화하는 작업이 필요
-
픽셀의 값은 0~255 사이의 정수로 이루어져 있어서, 255로 나누어 0 ~ 1 사이의 값을 정규화 진행
-
train_scaled.reshape(-1, 28*28) : 2차원 배열을 1차원 배열로 변환
-
784개의 픽셀로 이루어진 샘플 6만개를 확인
-
교차 검증 횟수를 늘리며 테스트 세트의 정확도를 확인
1.1.1.2. 로지스틱 회귀 모델을 활용한 인공 신경망
-
로지스틱 회귀의 공식
- z = aw1 + bw2 + cw3 + dw4 + ... + f
- z1 = aw11 + bw21 + cw31 + dw41 + ... + f
- z2 = aw12 + bw22 + cw32 + dw42 + ... + f
- 티셔츠 = w1픽셀1 + w2픽셀2 + w3픽셀3 + ... + w784픽셀784 + b
- 원피스 = w1'픽셀1 + w2'픽셀2 + w3'픽셀3 + ... + w784'픽셀784 + b
-
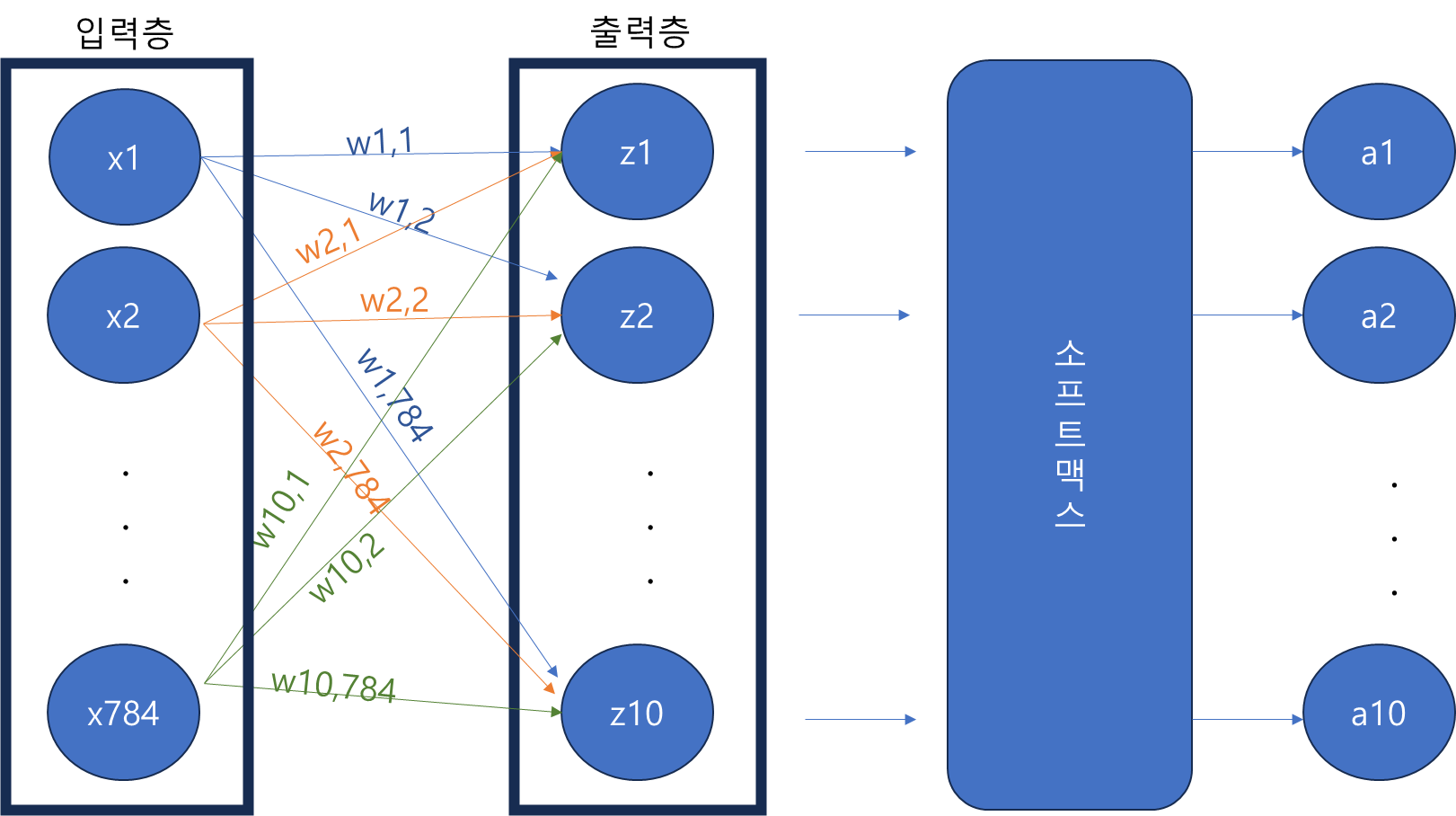
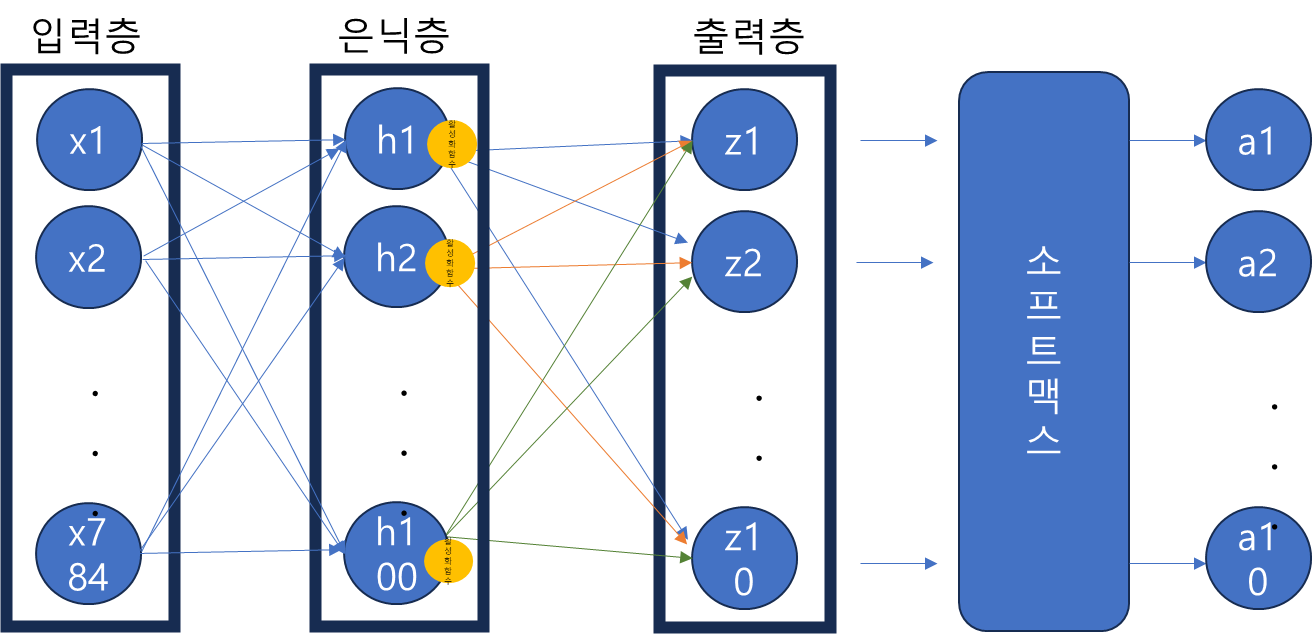
인공 신경망
- 출력층(z) : 각 클래스(예시에선 패션 아이템) 별로 로지스틱 회귀 공식으로 계산된 값
- 뉴런(=유닛) : z 값을 계산하는 단위
- 입력층(x1, x2 ...) : 변수의 값 (예시에서는 픽셀 값)
- 가중치(w11, w12) : 각 픽셀에 곱해지는 값
-
텐서플로와 케라스
- 케라스 : 텐서플로의 고수준 API, 직접 GPU 연산을 하진 않음
- 멀티 백앤드 케라스 : GPU를 사용하는 다른 라이브러리를 백엔드로 사용
- 딥러닝 라이브러리 : 벡터와 행렬 연산에 최적화되어 있는 GPU를 사용
-
인공 신경망 모델 생성
- 훈련 세트의 20%를 검증 세트로 사용
- 인공 신경망에서 교차 검증을 사용하지 않는 이유 : 딥러닝 분야의 충분한 데이터, 교차 검증을 수행하기에 필요한 시간

-
밀집층 생성
- 밀집층 : 각 클래스와 변수 별로 적용되는 계수가 모두 모여 있는 층
- 예시에서는 10개의 클래스 * 784개의 변수 = 7840개의 선(가중치)가 밀집해 있다.
- 완전 연결층 : 밀집층을 양쪽 뉴런이 모두 연결하고 있을 때
- keras.layers.Dense(10 -> 뉴런 개수, activation='softmax' -> 뉴런의 출력에 적용할 함수, input_shape=(784,) -> 입력의 크기)
- 이진 분류 일 때 activation='sigmoid'로 설정
- 활성화 함수 : 소프트맥스 처럼 뉴런의 선형 방정식 계산 결과에 적용되는 함수
- 활성화 함수는 뉴런의 출력에 바로 적용되기 때문에 보통 청의 일부로 나타냅니다.
- keras.Sequential(dense) : 케라스에 층을 생성, 추가할 층이 1개 이상일 경우 파이썬 리스트로 전달

-
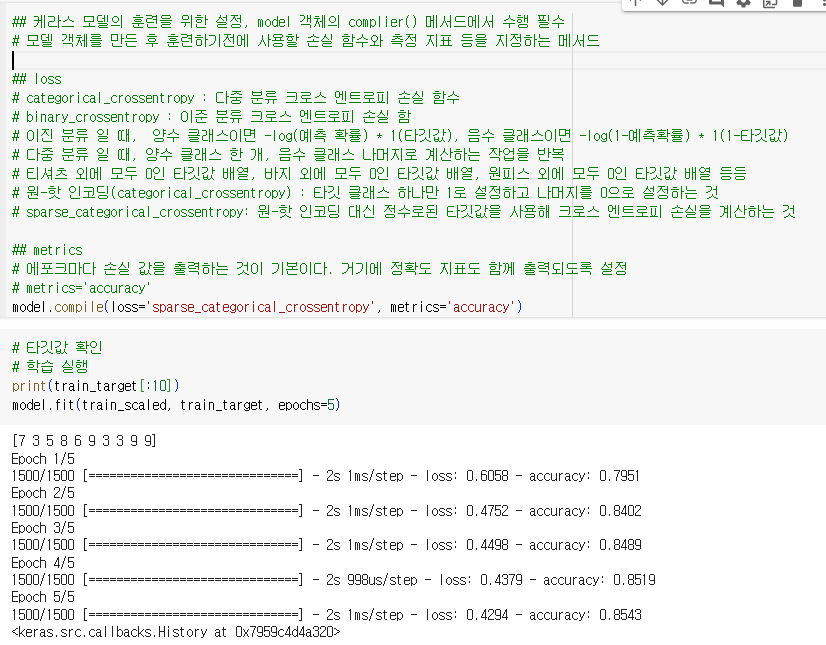
케라스 모델의 훈련을 위한 설정, model 객체의 complier() 메서드에서 수행 필수
- 모델 객체를 만든 후 훈련하기전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드
-
케라스 모델의 훈련을 위한 설정, model 객체의 complier() 메서드에서 수행 필수
- 모델 객체를 만든 후 훈련하기전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드
-
loss
- categorical_crossentropy : 다중 분류 크로스 엔트로피 손실 함수
- binary_crossentropy : 이준 분류 크로스 엔트로피 손실 함
- 이진 분류 일 때, 양수 클래스이면 -log(예측 확률) 1(타깃값), 음수 클래스이면 -log(1-예측확률) 1(1-타깃값)
- 다중 분류 일 때, 양수 클래스 한 개, 음수 클래스 나머지로 계산하는 작업을 반복
ㅍ 티셔츠 외에 모두 0인 타깃값 배열, 바지 외에 모두 0인 타깃값 배열, 원피스 외에 모두 0인 타깃값 배열 등등 - 원-핫 인코딩(categorical_crossentropy) : 타깃 클래스 하나만 1로 설정하고 나머지를 0으로 설정하는 것
- sparse_categorical_crossentropy: 원-핫 인코딩 대신 정수로된 타깃값을 사용해 크로스 엔트로피 손실을 계산하는 것
-
metrics
- 에포크마다 손실 값을 출력하는 것이 기본이다. 거기에 정확도 지표도 함께 출력되도록 설정
- metrics='accuracy'
-
테스트 세트로 검증

1.1.2. 확인 문제
1.1.2.1. 어떤 인공 신경망의 입력 특성이 100개이고 밀집층에 있는 뉴런의 개수가 10개일 때 필요한 모델 파라미터의 개수는 몇 개인가요?
- 인공 신경망의 입력 특성 = 100, 뉴런의 개수 = 10 일 때, 필요한 모델 파라미터의 개수
100(인공 신경망의 입력 특성) * 10(뉴런의 개수) = 1000
1.1.2.2. 케라스의 Dense 클래스를 사용해 신경망의 출력층을 만들려고 합니다. 이 신경망이 이진 분류 모델이라면 activation 매개변수에 어떤 활성화 함수를 지정해야 하나요?
- sigmoid
- 출력층에 적용할 수 있는 손실 함수는 sigmoid, softmax이다. 다중 분류는 softmax, 이진 분류는 sigmoid
1.1.2.3. 케라스 모델에서 손실 함수와 측정 지표 등을 지정하는 메서드는 무엇인가요?
- compile() : 모델 객체를 만든 후 훈련하기 전에 사용할 손실 함수와 측정 지표등 을 지정하는 메서드텍스트
- fit() : 모델 훈련 메서드
1.1.2.4. 정수 레이블을 타깃으로 가지는 다중 분류 문제일 때 케라스 모델의 compile() 메서드에 지정할 손실 함수로 적절한 것은 무엇인가요?
- sparse_categorical_crossentropy : 원-핫 인코딩 대신 정수로된 타깃값을 사용해 크로스 엔트로피 손실을 계산하는 것
1.2. 심층 신경망
1.2.1. 심층 신경망 모델 생성
1.2.1.1. 데이터 확인
1.2.1.2. 은닉층 생성
-
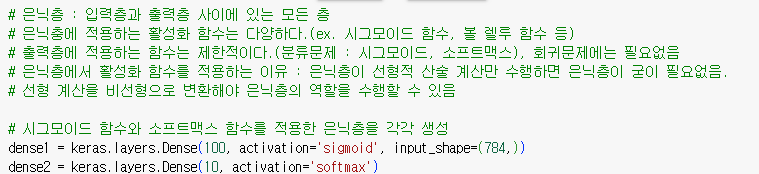
은닉층 : 입력층과 출력층 사이에 있는 모든 층
-
은닉충에 적용하는 활성화 함수는 다양하다.(ex. 시그모이드 함수, 볼 렐루 함수 등)
-
출력층에 적용하는 함수는 제한적이다.(분류문제 : 시그모이드, 소프트맥스), 회귀문제에는 필요없음
-
은닉층에서 활성화 함수를 적용하는 이유 : 은닉층이 선형적 산술 계산만 수행하면 은닉층이 굳이 필요없음.
-
선형 계산을 비선형으로 변환해야 은닉층의 역할을 수행할 수 있음
-
시그모이드 함수와 소프트맥스 함수를 적용한 은닉층을 각각 생성
-
1.2.1.3. 심층 신경망 생성
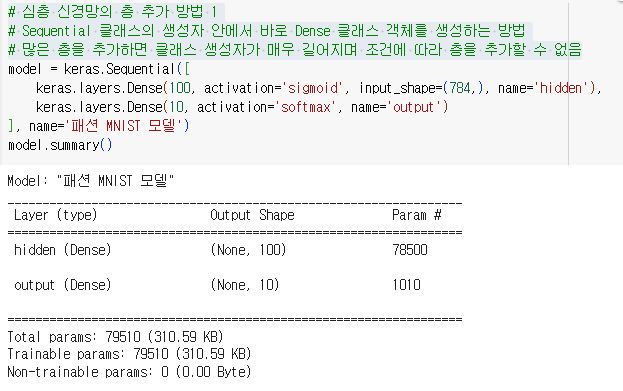
- 은닉층을 추가하여 심층 신경망 생성
- dense1 : 해당 클래스가 아니면 모두 0으로 예측하는 시그모이드 함수를 적용한 은닉층
- dense2 : 각 클래스 별로 결과를 출력하는 소프트 맥스 함수의 출력층
- keras.Sequential 클래스에 입력할 객체의 마지막은 항상 출력층
- 미니배치 경사하강법을 사용하기 때문에 샘플전부를 사용하지 않고 여러 번에 걸쳐 경사 하강법 단계를 수행
- dense 레이어에 100개의 뉴런과 샘플마다 784개의 픽셀값이 은닉층을 통과하여100개의 특성으로 압축
- 은닉층에서 784*100의 가중치 + 100의 절편 = 78500 개의 파라미터 생성
- 출력층에서 10개의 뉴런 * 은닉층에서 전달받은 100개의 뉴런 = 가중치의 개수
- 출력층의 가중치 10100 + 출력층 뉴런 마다 절편 10 = 1000 + 10 = 1010

1.2.1.4. 은닉층 추가 방법 1
- Sequential 클래스의 생성자 안에서 바로 Dense 클래스 객체를 생성하는 방법
- 많은 층을 추가하면 클래스 생성자가 매우 길어지며 조건에 따라 층을 추가할 수 없음
- 많은 층을 추가하면 클래스 생성자가 매우 길어지며 조건에 따라 층을 추가할 수 없음
1.2.1.5. 은닉층 추가 방법 2
-
add() 메서드 전달
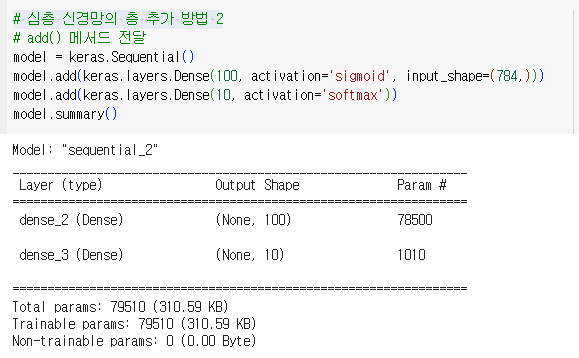
-
모델 학습 실시

1.2.2. 렐루 활성화 함수
- 시그모이드 함수는 좌우측 끝으로 갈수록 그래프가 누워있기 때문에 올바른 출력을 만드는데 신속하게 대응하지 못함
- 층이 많아질수록 단점의 커져 학습의 지장을 줌
- 렐루 함수 : 입력이 양수이면 활성화함수가 없는 것처럼 입력을 통과시키고 음수일 경우엔 0으로 만듦
- 이미지 학습에 특히 좋은 효과
- reshape 메서드로 1차원 배열로 변환하는 대신 Flatten 메서드 사용
1.2.2.1. 렐루 활성화 함수를 적용한 모델 생성
-
Flatten메서드는 입력층과 은닉층 사이에 층처럼 존재하지만 데이터 배열에만 관여할 뿐
-
분석 결과에 영향을 주지 않기 때문에 층으로 간주하지 않는다.

-
전처리 중에 배열변환을 제외
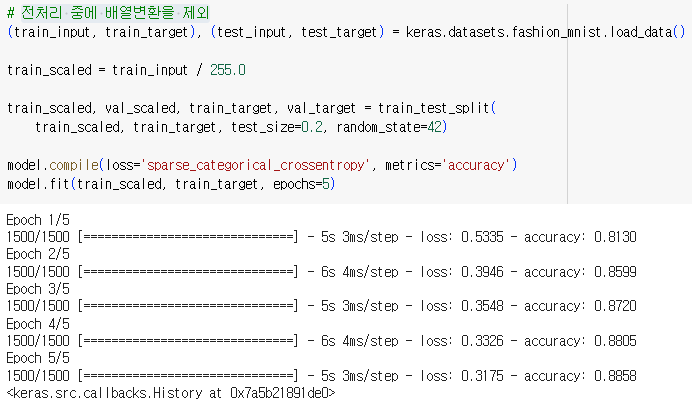

1.2.3. 옵티마이저
- 하이퍼파라미터(epoch, batch_size 등)의 최적값을 찾아준다
- 케라스의 미니배치 경사 하강법의 기본 개수=32. 하이퍼파라미터로써 조정할 필요가 생기기도 한다
- 기본적으로 확률적 경사 하강법인 SGD 알고리즘을 사용한다.
1.2.3.1. 하이퍼파라미터를 적용한 최적의 모델 생성
-
optimizer='sgd'와 optimizer=sgd의 차이
-
'sgd'라 지정하면 자동으로 SGD 클래스 객체를 생성

-
네스테로프 모멘텀 최적화, 모멘텀 값은 0.9이상으로 지정한다.
-
네스테로프 모멘텀은 모멘텀 최적화를 2번 반복하여 구현하여 대부분 기본 확률적 경사 하강법 보다 나은 성능을 제공

-
적응적 학습률 : 모델이 최적점에 가까이 갈수록 학습률을 낮출 수 있는데 이를 통해 안정적인 최적점에 수렴할 가능성이 높다.
-
Adagrad 옵티마이저 사용

-
RMSprop 옵티마이저 사용

-
adam : RMSprop과 모멘텀 최적화의 장점을 결합
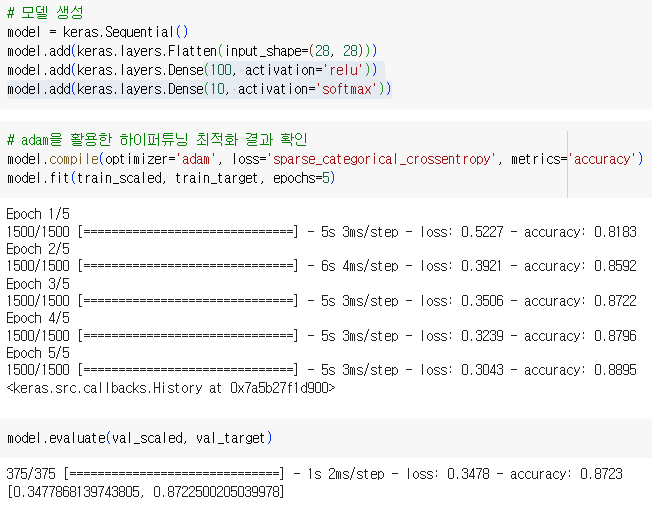
1.2.4. 확인 문제
1.2.4.1. 모델의 add() 메서드 사용법이 올바른 것
- model.add(keras.layers.Dense(10, activation='relu'))
1.2.4.2. 크기가 300 * 300인 입력을 케라스층으로 펼치려고 합니다. 어떤 층을 사용해야 하나요?
- Flatten
1.2.4.3. 이미지 분류를 위한 심층 신경망에 널리 사용되는 케라스의 활성화 함수는?
- relu
1.2.4.4. 적응적 학습률을 사용하지 않는 옵티마이저는?
- SGD
1.3. 신경망 모델 훈련
- 머신러닝 알고리즘과 딥러닝의 차이
- 머신러닝 알고리즘 : 모델의 구조가 어느정도 고정되어 있고 학습 성능향상을 위해 매개변수를 조정하는 과정이 동반됨
- 딥러닝 : 모델의 구조를 직접 만든 것에 가까움
1.3.1. 손실 곡선
- 데이터 재수집
- 모델 학습 결과
- history 변수에 학습 모델에 대한 정보를 기록
- verbose : 훈련 과정의 시각화 정도를 지정, 0에 가까울수록 훈련 과정의 시각화를 최소화
- history 딕셔너리에 들어있는 값을 확인
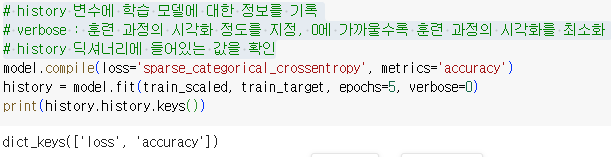
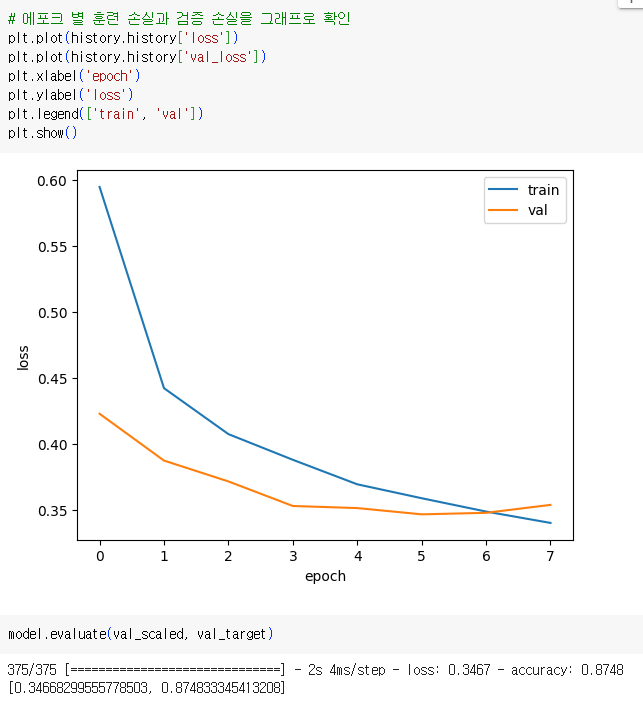
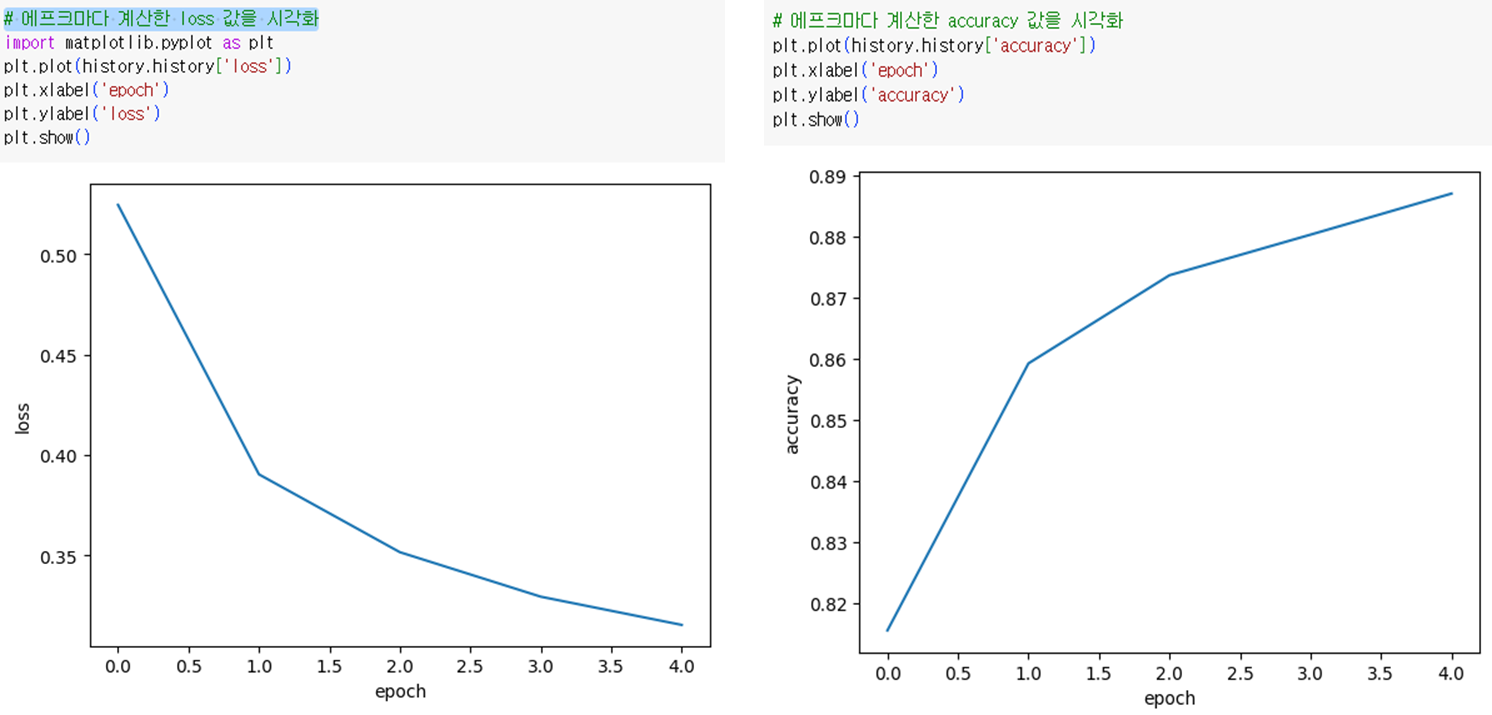
- 에포크 별 loss 및 정확성을 그래프로 확인
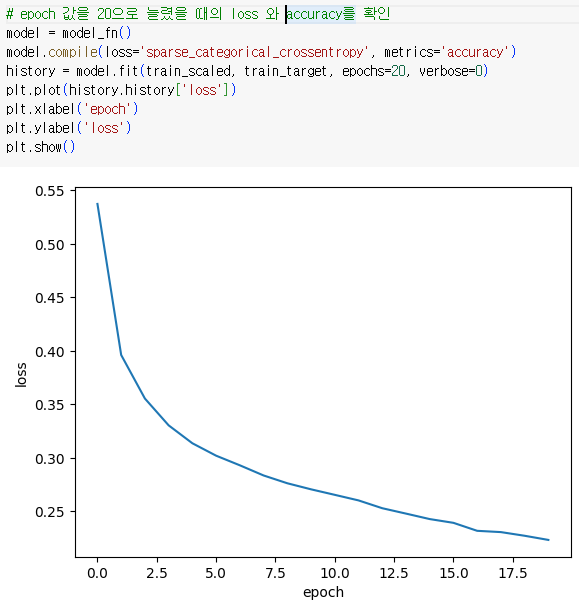
- epoch 값을 20으로 늘렸을 때의 loss 와 accuracy를 확인
1.3.2. 검증 손실
-
과대/과소 적합 여부를 확인
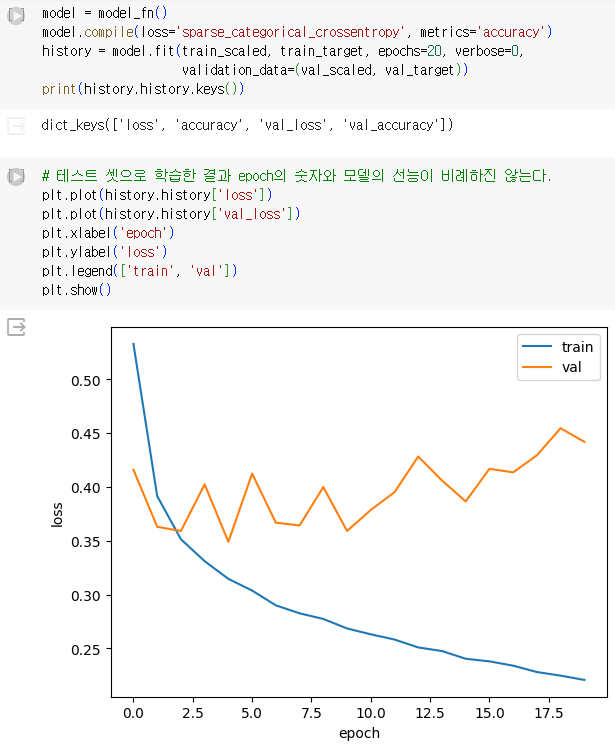
-
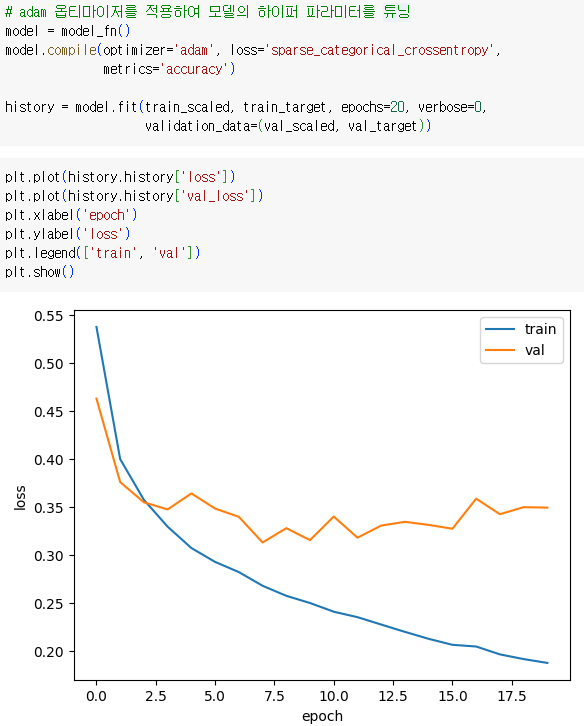
adam 옵티마이저를 적용하여 모델의 하이퍼 파라미터를 튜닝
1.3.3. 드롭 아웃
- 은닉층에 존재하는 랜덤하게 일부 뉴런의 출력을 0으로 만들어서 과대적합을 막는 방법
- 드롭할 뉴런을 정하는 하이퍼파라미터
- 특정 뉴런에 과대하게 의존하는 것을 방지하며 모든 입력에 대해 주의를 기울인다.
- 일부 뉴런의 출력이 실제로 없을 수 있다는 가정도 확인할 수 있음
1.3.3.1. 주의사항
- 은닉층 뒤에 추가되는 드롭아웃 층은 훈련되는 모델 파라미터가 없어 입력과 출력의 크기가 같다
- keras.layers.Dropout(0.3) : 전체 특성에 30%를 랜덤하게 끈다
- 훈련이 끝난 뒤 평가나 예측을 수행할 땐, 드롭아웃을 적용하지 않는다
- 훈련된 모든 뉴런을 사용해야 올바른 예측이 가능하다
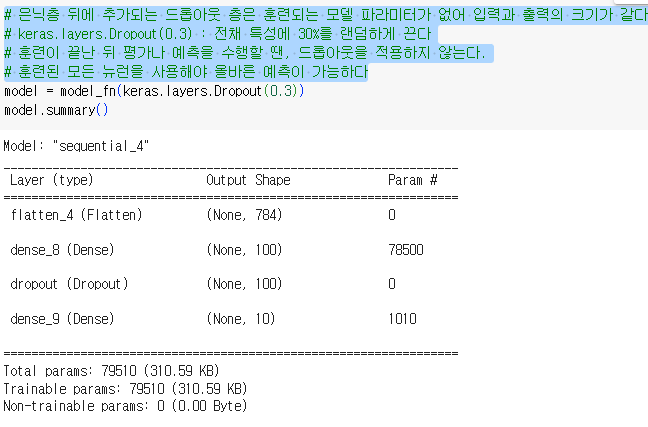
- 텐서플로와 케라스는 모델을 평가와 예측에 사용할 때는 드롭아웃을 적용하지 않는다.
- epoch 10 즈음에서 테스트 세트의 결과에 향상이 없고, 훈련 세트에서 과대적합이 발생한다.
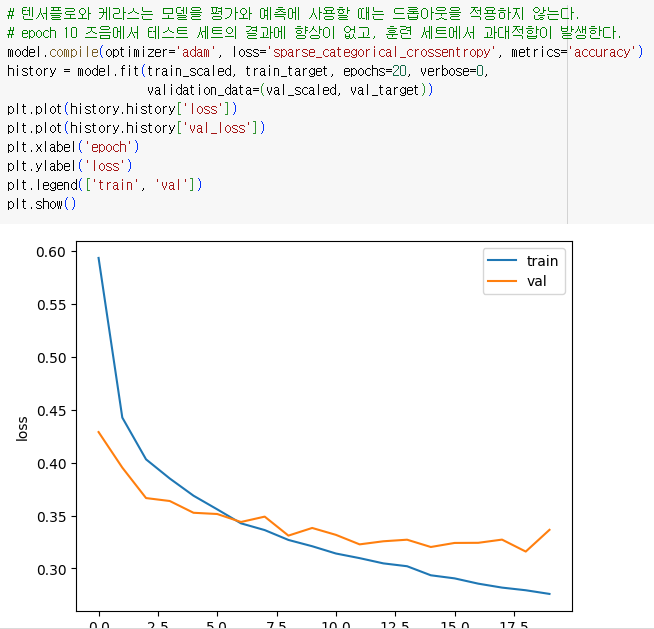
- 에포크 횟수를 10회로 조정하여 훈련 시작 및 모델 저장
- save_weights() : 훈련된 모델의 파라미터를 저장
- save() : 모델의 구조와 파라미터를 함께 저장, .h5 확장자 일 경우, HDF5 포맷으로 저장

- 모델이 기록된 파일 조회
- 훈련하지 않은 새로운 모델에 model-weights.h5 파일에서 훈련된 모델 파라미터를 적용
- model-whole.h5 파일에서 새로운 모델을 만들어서 바로 사용

1.3.4. 콜백
- 훈련 과정 중간에 어떤 작업을 수행할 수 있게하는 객체
- ModelCheckpoint : 에포크마다 모델을 저장
- save_best_only : 가장 낮은 검증 점수를 만드는 모델을 저장
- 전체 모델의 30%의 특성 랜덤하게 0으로 만들고 최적의 하이퍼파라미터를 탐색한다.
- 학습하면서 최적의 모델을 'best-model.h5'에 저장

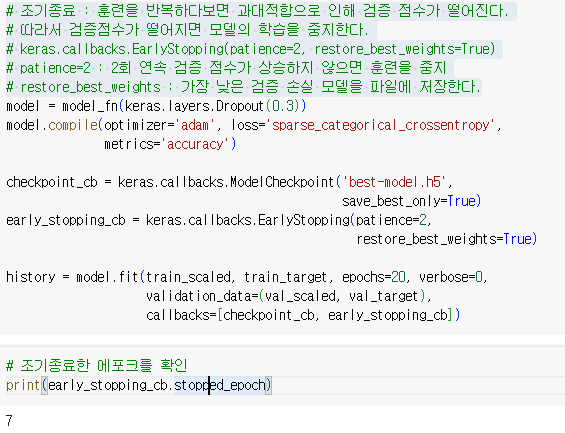
- 조기종료 : 훈련을 반복하다보면 과대적합으로 인해 검증 점수가 떨어진다.
- 따라서 검증점수가 떨어지면 모델의 학습을 중지한다.
- keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
- patience=2 : 2회 연속 검증 점수가 상승하지 않으면 훈련을 중지
- restore_best_weights : 가장 낮은 검증 손실 모델을 파일에 저장한다.