OpenIntro statistics를 바탕으로 작성했습니다.
한스 로슬링의 저서 팩트풀니스에 소개된 질문이다.
세계의 1살 어린이 중 몇 %가 백신을 접종할까?
a. 20%
b. 50%
c. 80%
대학 교육을 받은 성인들 중 정답을 맞춘 비율은 얼마나 될까?
Hypothesis testing framework
결과를 아래와 같이 두 가지로 추측해 볼 수 있다.
사람들은 이런 상식은 없다. 찍는 것과 다를바가 없을 것이다.
적어도 오답은 피하지 않겠나. 찍는 것보다는 나을 것이다.
이런 것들을 가설이라고 부른다. 은("H-nought"이라고 발음하며) 귀무가설(null hypothesis)이라고 하고 는 대립가설(alternative hypothesis)이라고 한다.
는 회의론적 시각이다. "다를거 없다"는 태도이다. 는 새로운 시각이다.
이런 도구를 처음 보는 사람들도 있겠지만, 대부분 사람들은 자연스레 이 프레임워크를 사용하고 있다. 어떤 사람이 허황된 주장을 했다고 해보자. 근거가 없다면 쉽게 믿지 않을 것이다. 하지만 뭔가 '강력한 근거'를 제시한다면 얘기가 달라진다.
비슷한 일이 법정에서도 일어난다. 판사는 무죄추정의 원칙에 따라 판결한다. 피고는 일단 무죄인데 혹시 범죄 혐의를 입증할 강력한 증거가 있으면 유죄로 판결한다는 것이다. 여기서 귀무가설은 무죄이고 대립가설은 유죄이다.
'죄가 없다' 것이 원칙이라면 죄가 있어도 유죄 판결을 받지 않을 수도 있지 않을까? 지은 죄에 비해 가벼운 형량을 선고 받을 가능성도 있지 않을까? 물론 그렇다. 그래서 보통은 판결문에 "죄가 없다" 같은 단정적인 표현보다는 "혐의를 입증할 수 없다" 정도의 애매한 표현이 많이 보이는 것이다. 귀무가설에 대해서도 "귀무가설을 기각할 수 없다"는 애매한 표현을 쓰는 것과 같은 맥락이다.
다시 로스링의 문제로 돌아가서 귀무가설과 대립가설을 세워보자. 보기가 3개 있는 문제이니까 사람들이 대충 찍었다면 정답을 맞출 확률은 0.333일 것이다. 대충 찍지 않았다면 0.333이 아닐 것이다. 수식으로 쓰면 아래와 같다.
실제로 조사했는데 정답자 비율이 정확히 0.333이 아니라면 우리는 귀무가설을 기각해야 할까?
당연히 아니다. 위에서 언급했듯 '강력한' 근거가 필요하다.
Testing hypothesis using confidence intervals
글 처음에 제시한 문제의 정답은 'c.80%' 이다. 대학 교육을 받은 성인 50명에게 위 질문을 했더니 24%만이 정답을 맞췄다고 한다. 배운 사람들 수준이 이 정도라니..(사실 나도 못 맞췄다.) 숫자만 보면 사람들 상식이 찍는 것만도 못하다는 결론을 내려야 한다는 생각이 든다. 그런데, 이 결과가 그런 판단을 할 '강력한' 근거인가?
표본수, 비율이 주어졌으니 여기서 신뢰구간을 구해볼 수 있다. 먼저 sucess-failure condition을 만족하는지 본다. 여기서 50명은 완전 무작위로 선발했다고 가정하자. 이고 이라 둘 다 10을 넘겼다. 조건을 만족한다.
이고 95% 신뢰구간을 만들면
이 된다. null value인 0.333이 신뢰구간에 포함됐다. 그러므로 우리는 귀무가설을 기각하지 못한다. 다시 말해, 사람들이 찍지 않았다고 볼 수 없다.
위 문제 정답을 못맞춰서 창피했다면 다음 문제는 잘 맞춰보자.
현재 세계에 0-15세 어린이는 20억이다. 미국에 2100년 어린이 수는 몇 명이 될까?
a. 40억
b. 30억
c. 20억
귀무가설, 대립가설은 달라지지 않았다.
정답은? a.20억명이다. 이번에도 228명의 대학 교육을 받은 성인들에게 위 질문을 던졌다. 34명(14.9%)만이 정답을 맞췄다. 위에서 한 것을 그대로 따라해보자. 먼저 sucess-failure condition 만족 여부. 여기서 이고 이기 때문에 통과했다.
신뢰구간을 구해보자.
95% 신뢰구간을 만들어보자.
이번엔 신뢰구간에 0.333이 포함되지 않았다. 이번엔 사람들이 상식이 부족하다는 결론을 내릴 수 있을 것 같다. 이것을 통계 언어로는 "95% 신뢰구간에서 귀무가설을 기각한다."고 이야기 한다.
여기서 95%는 어디서 나온 기준인가하는 의문이 든다. 세상에 95%도 좋지만 99%나 99.9%는 되어야 진짜 확신할 수 있는 것 아니냐고!
Decision error
다시 법정으로 돌아가보자. 판사들은 법정에서 오류가 없는 판결을 내린다고 할 수 있을까? 당연히 아니다. 실제로 죄가 있는데 법정에서 유유히 걸어나가는 경우도 있을 것이고, 죄가 없는데 유죄 판결을 내리는 경우도 있다. 이 중 어떤 오류가 더 위험할까?
무죄추정의 원칙이 어떤 태도에서 기인했을지 생각하면 답이 나온다. 죄가 없는데 유죄 판결을 받는 경우가 더 위험하다. 만약 법정 구속을 하는 등 신체적 자유까지 박탈했다면 이야기는 더 심각해진다.
법정에서 귀무가설은 '무죄'이고 대립가설은 '유죄'이다. 죄가 없는데 유죄 판결을 내리는 오류는 귀무가설을 기각한 경우에 범하게 된다. 이것을 제1종 오류라고 부른다. 반면 죄가 있는데 무죄 판결을 내리는 오류는 귀무가설을 기각하지 못한 경우에 범하게 된다. 이것을 제2종 오류라고 부른다. 판결을 내릴 때와 마찬가지로 제1종 오류를 범하는 경우가 일반적으로 더 위험하다.
정리하면 제1종 오류는 귀무가설이 참인데 기각하는 경우고 제2종 오류는 대립가설이 참인데 귀무가설을 기각하지 않는 경우이다. 아래에 정리된 표를 첨부했다.

죄가 없는데 유죄 판결을 내리는 제1종 오류를 줄이려면 어떻게 해야 할까? 최대한 보수적으로 판결을 내리면 된다. 그럼 반대로 죄가 있는데 무죄 판결을 받는 경우(제2종 오류)가 많아지지 않을까? 죄가 조금만 입증 돼도 유죄 판결을 내리면 어떨까? 억울한 사람들이 늘어날 것이다. 눈치 챘겠지만 두 오류는 trade-off 관계에 있다.
앞서 우리는 95% 신뢰구간을 설정했다. 옳은 판단을 할 확률을 95%라고 생각하자. 반대로 오류를 범할 확률을 5%라고 이야기 할 수 있을 것이다. 제1종 오류를 5%보다 더 범하고 싶지 않다는 의미이고 이것을 신뢰수준(significant level)이라고 한다. 신뢰 수준은 보통 로 표기한다. 5% 신뢰수준이면 와 같이 쓴다. 신뢰수준은 보통 0.1, 0.05, 0.01 세가지를 사용하는데 0.05를 가장 많이 사용한다.
Formal testing using p-values
p값을 이용하는 방법도 많이 쓰인다. 위에서 사용한 기법과는 어떤 차이가 있는지 잘 정리해두자.
Pew Research(리얼미터나 한국갤럽 같은 여론조사 전문 기관인 것 같다.)는 미국 성인 1000명에게 석탄 에너지 사용을 늘리는 것에 대한 찬반을 물었다. 이때 귀무가설과 대립가설은 아래와 같다.
위 조사 결과 37% 사람들이 석탄 에너지 사용을 지지했다. p값 방법으로 가설을 검정해보자. 신뢰구간을 계산하기 전에 먼저 success-failure condition을 점검해보자.
이고 로 통과했다. 여기서 인 0.37을 사용하지 않고 null value인 0.5를 사용한 것에 주목하자. SE도 마찬가지로 null value를 이용해 계산한다.
결론적으로, 만약 귀무가설이 참이라면 표본 비율은 평균 0.5 표준오차 0.016인 정규분포를 따라야 한다고 이야기 할 수 있다. 그림으로 그리면 아래와 같다.
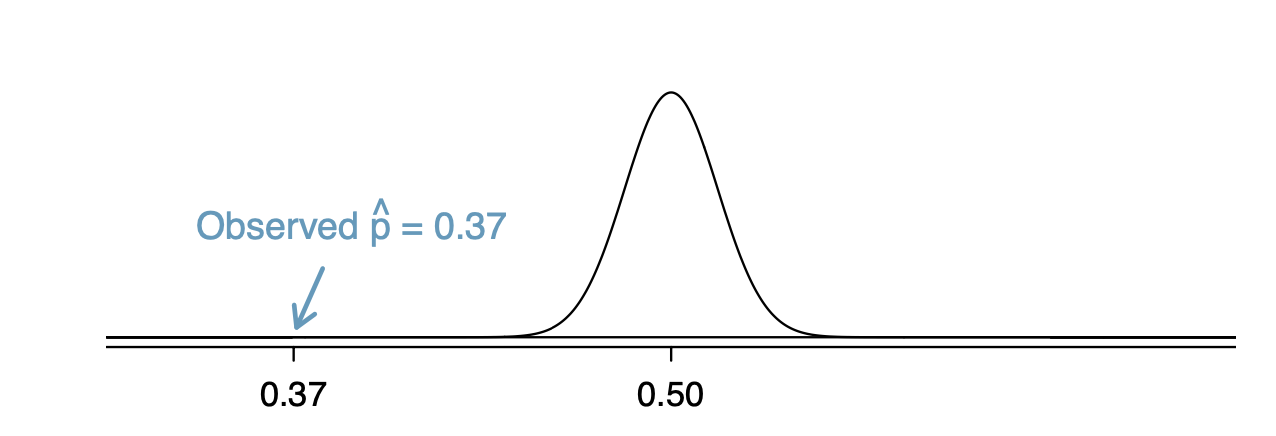
이것을 null distribution(널 분포?)라고 부른다. p값은 이 분포에서 가 관측될 확률 혹은 얼마나 극단적인지를 수치화 한 것이다.
여론조사 결과인 은 위 분포 어디쯤에 있을까? 정규 분포니까 정규화하면 확률을 구할 수 있다.
정규 분포의 왼쪽 꼬리 어디쯤인데 계산할 수 없을 정도로 작다. 대충 그냥 0이라고 해도 괜찮을 정도다. 다시 말해서 null distribution에서 이 값을 관측할 확률은 거의 없다는 것이다.
p값과 유의수준 를 많이 비교하곤 한다. p값이 보다 작으면 귀무가설을 기각한다.
