One-sample mean with the t-distribution
OpenIntro Statistics 4th Edition
Chater 7. Inference for numerical data를 바탕으로 작성했습니다.
묶음 글
1. One-sample mean with the t-distribution(현재 글)
2. Paired data
와 같이 도 몇 가지 조건만 충족되면 정규 분포로 모델링 할 수 있다.
표본 평균에 더 적합한 t-분포를 알아보고 신뢰구간을 만드는 법, 가설검정 하는 법 등을 소개한다.
The sampling distribution of
표본평균에 대한 중심극한 이론은 아래와 같다.
에서 추출한 충분히 많은 n개의 표본분포 는 평균 , 표준오차(SE)=의 정규 분포로 거의 근사된다.
- 모델링을 위해선 몇 가지 조건을 만족하는지 확인해야 하는데 보다는 조금 더 까다로운 편이다.
- 를 모르기 때문에 추정해야 하는데 완벽하지 않기 때문에 t-분포를 사용하게 된다.
Evaluating the two conditions required for modeling
표분평균에 중심극한 이론을 적용하기 위해 필요한 두가지 조건
- Independence. 표본은 반드시 독립적으로 추출해야 한다.(임의 추출)
- Normality. 표본이 많을 수록 정규성을 높아진다. 많으면 많을 수록 좋다. 얼마나 많아야 하는지 애매하지만 기준을 제시해 볼 순 있다.
Rules of thumb
- : 표본 크기가 30보다 작다면 데이터에 명확한(clear) outlier가 없어야 한다.
- : 표본 크기가 30보다 크거나 작다면 극단적인(particularly extreme) outlier가 없어야 한다.
정성적이고 사람에 따라 다르게 볼만한 기준으로 보인다. 그래서 '경험 법칙'이라고 부르는 것 같다.
Introducing the t-distribution
는 모르기 때문에 표본평균 s로 아래와 같이 표준오차를 근사할 수 있다. 표본이 작을 수록 모표준편차와의 오차는 커진다.
정규분포를 사용하기 힘들고 이럴때 t-분포를 사용하게 된다.
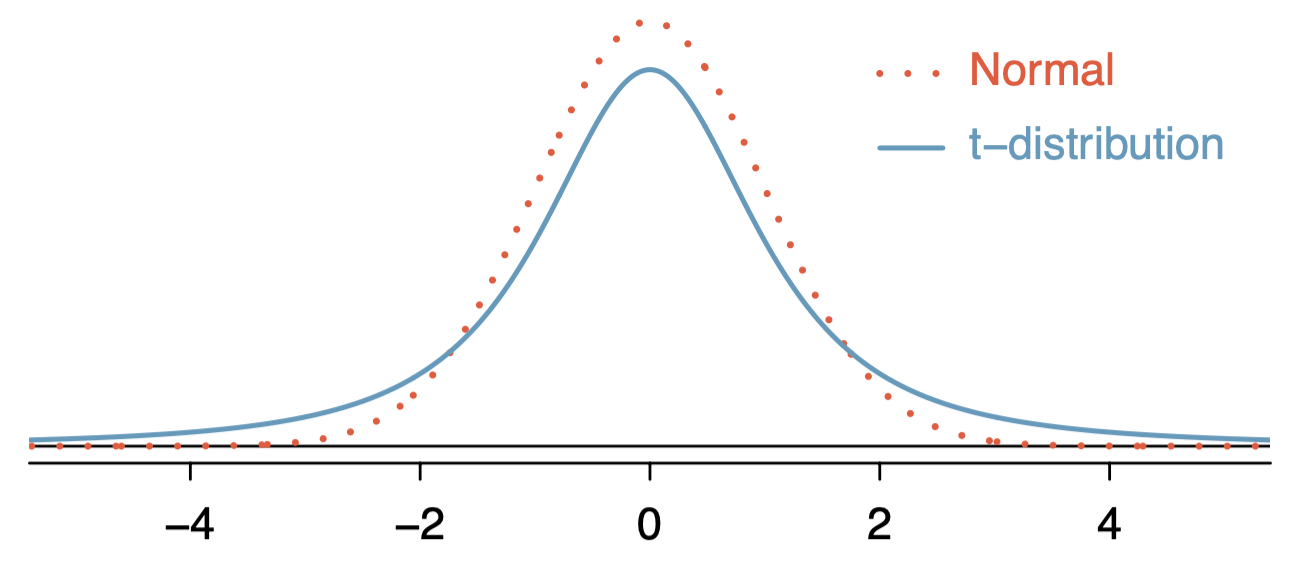
t-분포는 위 그림과 같이 정규분포와 유사하게 생겼지만 키는 작고 꼬리가 두텁다. 샘플 크기 인 자유도(df)라는 파라미터를 사용한다.
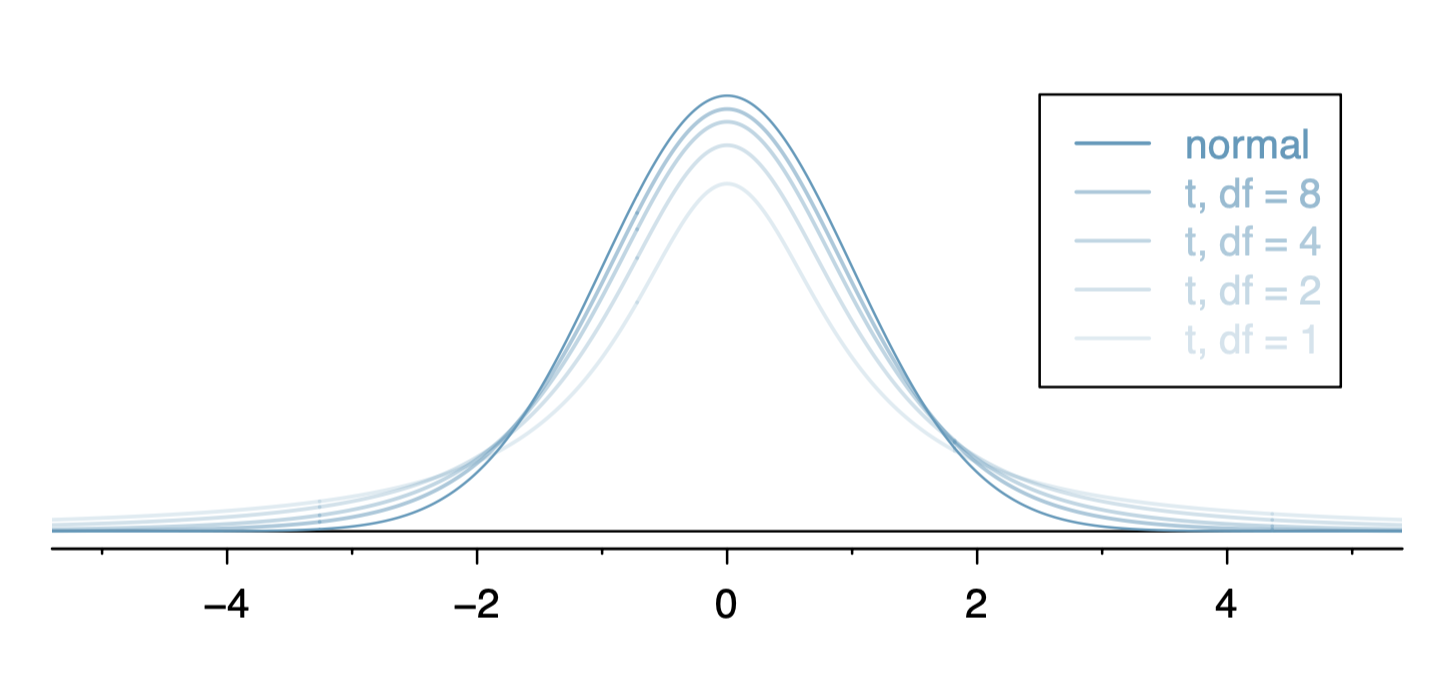
자유도가 커지면(샘플 크기가 커지면) 키가 점점 커지고 꼬리가 얇아지다 30을 넘으면서 정규 분포와 거의 구분할 수 없게 된다.
One sample t-confidence intervals
지금까지 정리한 내용을 토대로 95% 신뢰구간을 구해본다. 돌고래의 수은 함량 데이터를 보자. 19마리의 돌고래를 조사해서 아래와 같은 데이터를 얻었다.

독립성, 정규성 검증은 한것으로 하고 생략.
이 데이터의 95% 신뢰구간을 구해보자.
아래 수식을 이용할 수 있다.
SE는 위에서 제시한대로 표본표준편차 를 이용해 근사 한다.
아래 순서로 구하면 된다.
- 신뢰구간 정하기(95%, 90%. 99% 등)
- 표본표준편차를 이용해 SE 구하기
- df를 이용해 t값 역으로 구하기
- 위 결괏값들을 이용해 신뢰구간 산출
t값을 역으로 구하는 방법은 여러가지가 있으나 난 구글 스프레드시트를 선호하는 편이다. TINV 함수를 쓰면 된다. 엑셀에도 아마 같거나 비슷한 함수가 있을 것.
이고, 하면 18이 된다.
- 신뢰구간은 95%로 정해져 있음
- t값은 구글 스프레드시트 TINV 함수를 이용해 구했다. 확률, df를 차례로 넣어주면 된다. 2-tailed로 꼬리부분 확률이다. 95% 신뢰구간이면 0.05다. 약 2.1이라고 알려준다.
TINV(0.05, 18)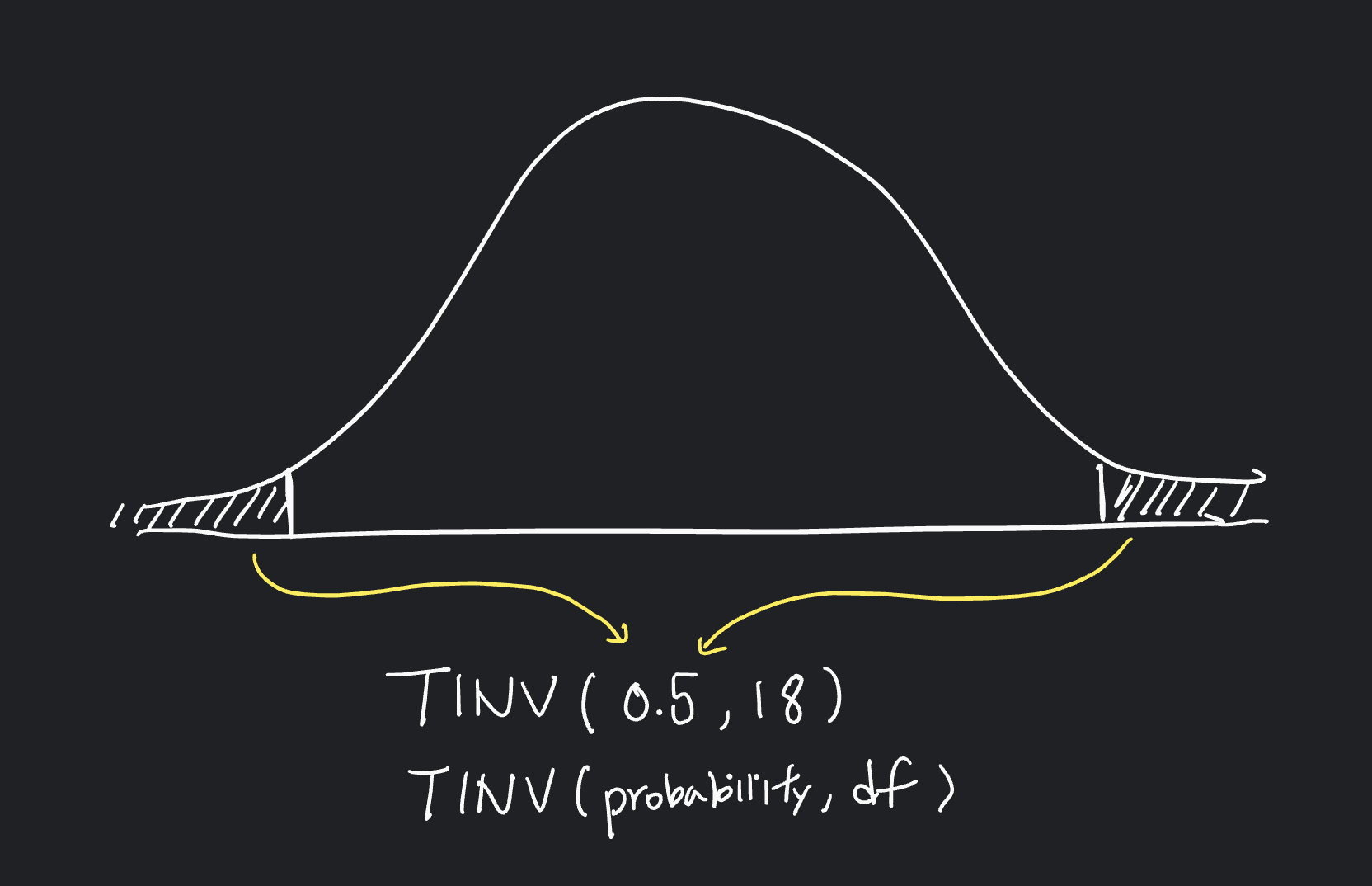
- 결과를 합쳐 구한다.
책에서는 준비, 확인, 계산, 결론 단계를 거치라고 조언하고 있다. 이 중 특히 우리가 유의해야 하는 단계는 어떤 분포나 프레임워크를 사용할 수 있는지 확인하는 단계이다.
독립성의 경우 표본을 임의 추출 했다고 생각했는데 생각지 못한 편향(bias)이 나타날 수 있다. 정규성의 경우에서 증명했듯 정성적 평가를 해야 할 때도 있다.
나머지는 그냥 조립하면 된다.
One sample t-test
마지막으로 t-검정을 해보자.
Cherry Blossom Race는 매년 봄에 열리는 10마일을 달리는 대회다. 2006년 기록과 2017년 기록을 비교해 미국의 러너들이 빨라졌는지 느려졌는지 확인해보자. 2006년 참가자 전체 평균 기록은 93.29분이었다.(약 93분 17초 정도)
귀무가설은 '기록이 달라지지 않았다'이고 대립가설은 '기록이 달라졌다'이며 수식으로 나타내면 아래와 같다.
2017년 참가자 100명의 표본평균, 표본표준편차는 97.32, 16.98이었다. 이를 토대로 null 분포를 구해보자.
평균 93.29, 표준오차 1.698, 자유도 99인 t-분포를 따른다고 요약할 수 있다. 이제 표본평균으로 p-value를 구해보자.
이제 구글 스프레드시트의 TDIST 함수를 이용해 p값을 구해보자.
TDIST(x, degrees_freedom, tails)2꼬리로 하면 한번에 되고 1꼬리로 하면 결과에 2를 곱해줘야 한다.
TDIST(2.37, 99, 2)p값은 약 0.02이기 때문에 유의수준 0.05에서 귀무가설을 기각한다.
