본 포스팅은 David Silver 교수님의 강화학습 강의와 그 강의를 정리한 깃북, 팡요랩 강의를 바탕으로 정리한 것입니다.
1. What is Reinforcement Learning
1.1 Definition of RL (in WikiPedia)
강화 학습(Reinforcement learning)은 기계학습이 다루는 문제 중에서 다음과 같이 기술 되는 것을 다룬다. 어떤 환경을 탐색하는 에이전트가 현재의 상태를 인식하여 어떤 행동을 취한다. 그러면 그 에이전트는 환경으로부터 포상을 얻게 된다. 포상은 양수와 음수 둘 다 가능하다. 강화 학습의 알고리즘은 그 에이전트가 앞으로 누적될 포상을 최대화하는 일련의 행동으로 정의되는 정책을 찾는 방법이다.
- 학습 : 환경과의 상호작용을 통한 습득과정
- 기계학습 : 학습 과정을 “computational”한 방법으로 접근하는 것 기계학습의 범주
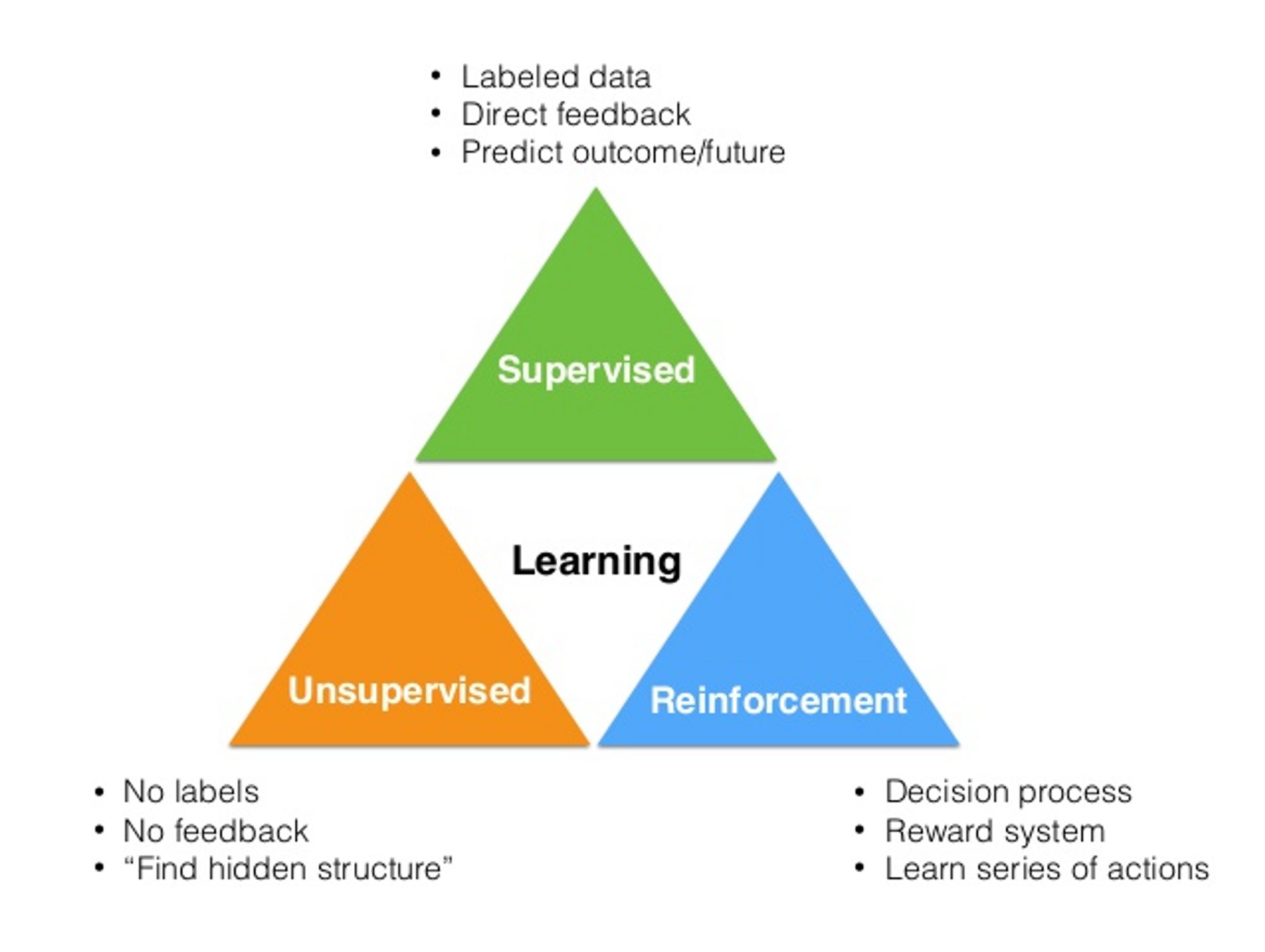
- 강화학습 : 올바른 action이 무엇인지 알지 못하지만, 환경과의 상호작용을 통하여 점차 학습해 나가는 기계학습의 한 학습 방법
Example) 사람이 처음 자전거를 탈 때
1.2 Problem of RL
강화학습은 해결하고자하는 문제가 강화학습 문제; Problem인지를 기준으로 정의된다.
-> 대부분의 기계학습 방법들은 “어떻게 학습하는가”를 기준으로 정의된다. (학습하는 방식)
-
강화학습 문제의 예
- Fly stunt manoeuvres in a helicopter
- Defeat the world champion at Backgammon (→ AlpaGo)
- Manage an investment portfolio : 이윤을 maximize
- Control a power station
- Make a humanoid robot walk
- Play many different Atari games better than humans
-
강화학습의 특징
-
no supervisor, only a reward signal
- supervisor가 존재한다면 기계가 아무리 학습을 잘 하더라도 supervisor를 넘어설 수 없다.
- 스스로 optimal 한 해를 찾아간다.
↔ supervisor는 아무리 잘 하더라도 suboptimal일 가능성이 높다…! - Example) 바둑에서 이기는 것을 목적이라고 할 때, supervised learning은 어떻게 돌을 둬야 좋은지 직접 일일이 훈수하는 것이라면, RL은 게임에서 이기는게 좋은 reward를 줄 뿐 어떻게 해야 게임에서 이길지를 알려주지 않는다.
-
Agent’s actions affect the subsequent data it receives
- 수행한 행동에 따라서 그 다음에 주어지는 데이터가 달라진다.
↔ 일반적인 기계학습 모델은 train set이 정해져있다. (ex. image classification…)
- 수행한 행동에 따라서 그 다음에 주어지는 데이터가 달라진다.
-
Delayed Reward
- 강화학습은 “시간에 따른 순서”가 있는 문제를 해결하기에 지금 수행한 행동에 대한 반응이 뒤늦게 전달될 수도 있다. (즉각적으로 전달되지 않는다.) → sequential, non i.i.d data
- 지연된 그 시간동안 수행한 여러가지 다른 행동들중에서 어떤 것이 좋은 행동이었는지를 판단하기 어렵게 만드는 주요한 문제가 된다.
- 강화학습은 “시간에 따른 순서”가 있는 문제를 해결하기에 지금 수행한 행동에 대한 반응이 뒤늦게 전달될 수도 있다. (즉각적으로 전달되지 않는다.) → sequential, non i.i.d data
-
Trial and Error
- Predict이 아니라, 실제로 Trial; 수행해보면서 모델을 조정해나간다.
- good action을 수행하면 enviroment로부터 good reward가 전달된다.
- 어떻게 상을 더 많이 받을 것인지를 알아내는게 강화학습의 주요 쟁점 중 하나이다.
-
1.2 History of RL
- Trial and Error
- 동물 행동에 대한 심리학 연구에서 출발했다.
- 심리학에서 “강화”
동물이나 인간이 행동에 대한 결과에 따라, 다음의 행동을 변화시키고 발전시킨다는 이론(스키너 상자실험)
- Delayed Reward
- optimal control : 어떤 비용함수의 비용을 최소화하도록 controler를 디자인하는것
- Bellman equation : optimal control 문제의 해결방법 [Dynamic Programming]
- MDP : Bellman이 고안한 순차 결정 문제에 대한 수학적 모델
이 2가지의 기초적인 토대로부터 강화학습이 탄생하였으며, 이후 Temporal difference Learning, Q-Learning으로 발전하다가 최근 Deep RL으로 발전하게 되었다.
*Deep Reinforcement Learning
- 처음에 강화학습을 배우기 시작할 때는 Grid world같이 작은 환경에서 예시 문제를 풀어볼 것이다.
- 그러나 실제로 게임을 학습하거나 해결하고싶은 복잡한 문제를 풀 때는 데이터의 숫자가 너무 많기 때문에 고전적인 RL을 이용해서는 제대로 학습이 되지 않는다.
- 따라서 데이터의 숫자를 다 일일이 Table로 저장해서 행동하는 것이 아니라 함수의 형태로 만들어서 정확하지는 않더라도 효율적으로 학습을 할 수 있게 하는 방법을 사용한다. [Approximation]
1.3 Example of RL
-
Playing atari with deep reinforcement learning
- 강화학습 + 딥러닝을 이용하여 Atari라는 고전게임을 학습
- Breakout 게임의 학습과정
- 랜덤하게 Agent가 움직이다가 우연히 공을 쳐서 게임의 점수가 올라가는 것을 확인한다면, “이 행동이 나에게 보상을 주는구나!”를 학습하게되어 보상을 받은 행동을 계속 수행하게된다.
- 이때 Agent는 단순히 즉각적인 점수만을 높이려는 것이 아니라 하나의 episode 동안 받는 점수를 최대화시키려고 한다. ⇒ 따라서 Agent는 최대한 높은 점수를 얻게 해주는 일련의 연속된 행동; 정책(Policy)을 찾아나선다.
- 어떤 행동이 좋은 행동이고, 어떤 행동들의 조합이 좋은 정책이 되는지는 Trail and Error로 여러번 시도하보면서 학습된다.
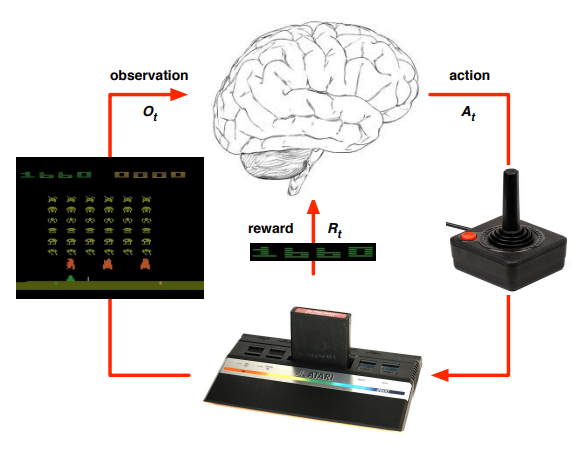
- 논문에서 주목할 점
- input data로 raw pixel를 받아온 점 → CNN과의 연결
- 같은 agent로 여러 개의 게임에 적용되어서 학습이 된다는 점
- Deep neural network를 function approximator로 사용
- Experience Replay
- Target networks
2. The RL Problem
2.1 Reward
-
Definition of Reward
All goals can be described by the maximisation of expected cumulative reward
-
with Reward Hypothesis
모든 목적이 누적된 reward를 최대화하는 것으로 표현할 수 있다는 가정
-
scalar feedback signal (with is time step)
-
Indicates how well agent is doing at
🛠 Agent’s job is to maximise cumulative;누적 reward
-
-
Example
- Fly stunt manoeuvres in a helicopter
- +ve reward for following desired trajectory
- −ve reward for crashing
- Defeat the world champion at Backgammon
- +/−ve reward for winning/losing a game
- Manage an investment portfolio
- +ve reward for each $ in bank
- Control a power station
- +ve reward for producing power
- −ve reward for exceeding safety thresholds
- Make a humanoid robot walk
- +ve reward for forward motion
- −ve reward for falling over
- Play many different Atari games better than humans
- +/−ve reward for increasing/decreasing score
- Fly stunt manoeuvres in a helicopter
-
Sequential Decision Making
-
Goal : select Actions to maximise total future reward
-
Problem 특징
- Action에 대한 결과는 long term이후에 나타날 수도 있다.
- Reward가 Delay될 수 있다.
-
가끔은 즉각적인 Reward는 포기하는 대신 long-term reward를 더 maximise하기 위한 Action을 수행할 수도 있다.
→ 늘 greedy 하게 local oprima만 선택하지는 않는다.
-
Example
- A financial investment (may take months to mature)
- Refuelling a helicopter (might prevent a crash in several hours)
- Blocking opponent moves (might help winning chances many moves from now)
-
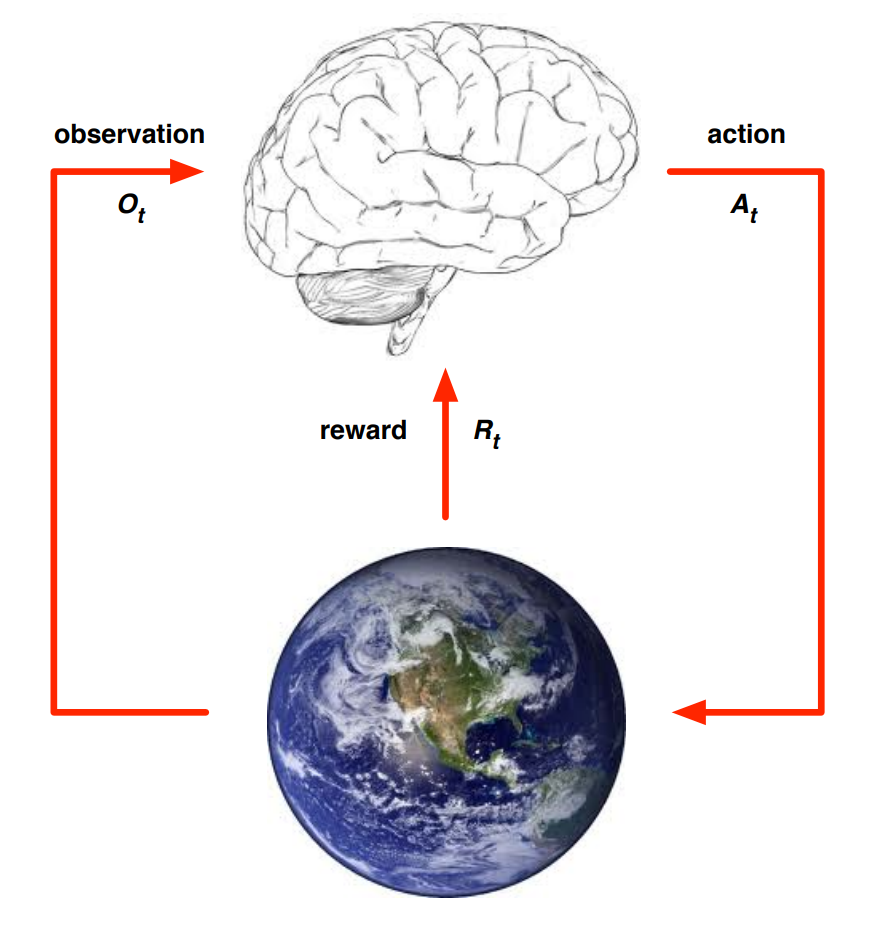
2.2 Agent and Environment
At each step ,
-
The Agent’s aspect
-
env로부터 Observation 를 받는다.
이때 Observation은 Agent의 action으로 인하여 변화된 환경을 나타낸다. -
env로부터 scalar reward 를 받는다.
⬇
-
Action 를 수행한다.
-
-
The Environment’s aspect
-
agent로부터 Action 를 받는다.
⬇
-
observation 를 준다.
-
scalar reward 를 준다.
→ 는 environment의 step에 따라 증가한다.
-
2.3 State
-
History
-
는 그 시간 까지 있었던 모든 각각의 timestep마다 Agent가 수행한 action과 그때의 observation, reward를 순차적으로 기록한 것
-
history가 결정하는 것
- Agent는 Action을 결정한다.
- Environment는 observation과 reward를 결정한다.
-
-
State
-
State is the information used to determine what happens Next
-
history에 대한 함수; History가 가지고 있는 정보들을 가공하여 State를 만든다.
-
-
관점에 따른 State
- Environment State
-
env가 Next observation과 reward를 계산하기 위해 사용한 모든 information (숫자들)
Example) Atari game에서 Agent가 select한 Action에 따라 표기되는 다음 화면(=observation)을 계산하기 위해 참고하는 정보들
→ 공의 위치, 현재 박스의 개수 및 구조…*
-
env의 state는 agent에게는 보이지 않는다. (보이더라도 너무 복잡한 정보라 활용x)
Example) 우리가 게임을 플레이할 때는 컴퓨터 내부적으로 어떻게 계산되는지는 알 필요가 없다 !
-
- Agent State
-
Agent가 Next Action을 select하기 위해 참고하는 정보들 (내가 정하는 것)
-
실제로 통용되는 State와 동일하다.
-
- Environment State
-
Information state : Markov state
-
Definition
A state is Markov *if and only if*
-
The future is independent of the past given the present
- 과거와 미래는 독립적이다!
- 미래를 결정할 때, 예전의 state들은 필요없이 바로 이전의 state만을 참고하여 결정한다.
-
즉, 이런식으로 state를 Markov하게 표현할 수 있다면, 문제를 훨씬 더 간단하게 표현할 수 있다!
-
Example : Rat
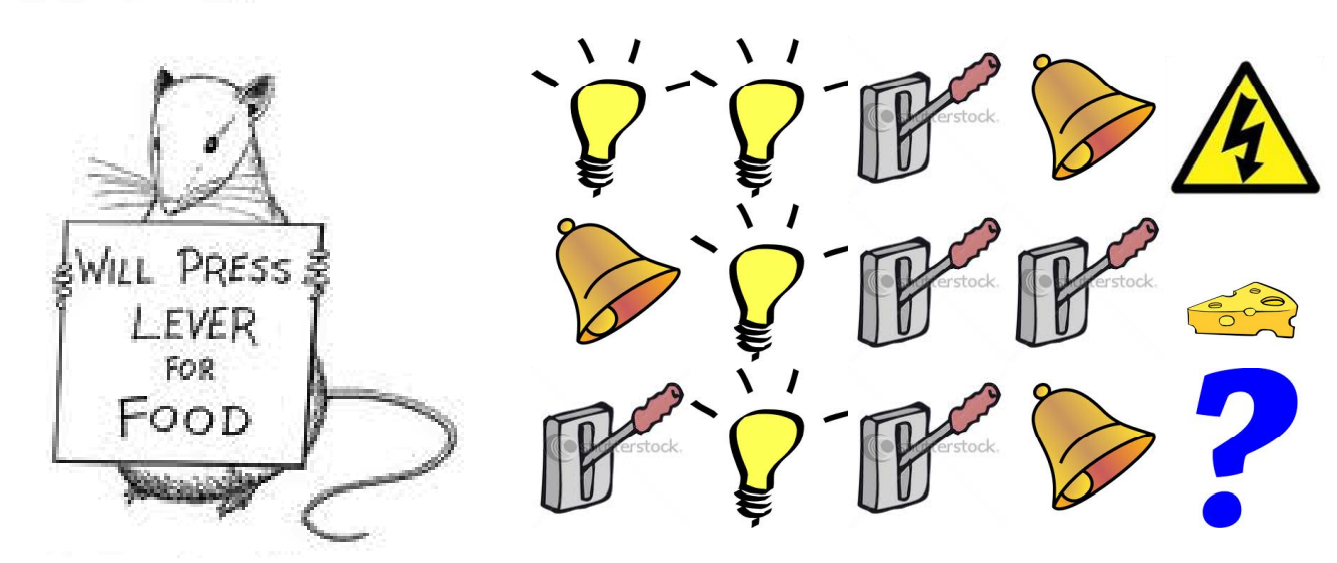
-
최근 3가지의 signal을 state로 정의한다면, → 감전
-
전체 history에서 각 signal이 등장한 횟수를 state로 정의한다면, → 치즈
⇒ 즉, 어떻게 History에 대한 function을 정의하여 State를 표현하는지에 따라서 같은 데이터라 하더라도 다르게 예측할 수 있다.
-
-
-
Observe에 따른 State
-
Fully Observability
-
Markov decision process : MDP
-
env의 state를 agent가 볼 수 있는 상황
-
Agent state = environment state = Information state
-
-
Partially Observability
- partially observable Markov decision process : POMDP
- Agent state ≠ environment state
⇒ 따라서 Agent는 반드시 자신의 State를 표현하기 위한 방법을 구축해야한다.
- Agent의 State 표현법 예시들…
- Complete history :
- Beliefs of environment state :
- Recurrent Neural network :
- Example
- 로봇이 길을 걸을 때 카메라는, 로봇의 정확한 위치정보를 제공하지 않는다.
- 포커를 할 때, 상대방이 가지고 있는 패와 내가 뽑게될 패에 대한 정보를 모르더라도 Action을 결정해야한다.
-
3. The RL Agent
대표적인 RL Agent의 구성요소
- Policy : Agent’s behaviour function
- Value Function : how good is each state and/or action
- Model : Agent’s representation of the environment → Agent는 3가지의 구성요소를 모두 가지고 있을수도 있고, 하나만 가지고 있을수도 있다!
3.1 Policy
- A policy is the Agent’s behaviour
- Agent의 행동을 규정한다.
- state를 입력으로 전달하면, action을 반환한다. → state와 action을 mapping
- Policy의 종류
- deterministic policy : state에 대하여 하나의 action을 정확하게 결정해서 반환한다.
- stochastic policy : state에 대하여 여러가지 action이 가능한데, 이때 각각의 action에 대한 확률을 반환한다.
- deterministic policy : state에 대하여 하나의 action을 정확하게 결정해서 반환한다.
3.2 Value Function
-
Value function is a prediction of future reward
- 현재의 state가 얼마나 좋은지를 “평가”한다.
- 현재로부터 미래까지 받을 수있는 모든 Reward들의 합산의 기댓값으로 표현할 수 있다.
-
Formal 표현
- : 현재 state를 의미
- : value fuction을 의미 → 이때 아래첨자 는 Agent가 어떤 policy 를 따라서 진행한다는 것을 나타낸다.
- : 여러가지 가능한 모든 episode가 존재하기 때문에, 기댓값을 이용하여 나타낸다.
- : 미래의 Reward에 대한 가중치를 줄여서 나타내기 위한 상수값
3.3 Model
- Model predicts what the environment will do next
- Environment가 어떻게 변화할지를 예측하는 요소
- Environment의 역할(=state의 변화, reward 전달)을 Agent가 Model을 이용하여 예측해서 표현
- Model의 종류
- predicts the next state = state의 transition을 예측
- predicts the next (immediate) reward
3.4 Category of RL Agent
- Policy와 Value에 따른 분류
- Value Based
- No Policy
- Value Function
- Policy Based
- Policy
- No Value Function
- Actor Critic
- Policy
- Value Function
- Value Based
- Model에 따른 분류
- Model Free
- Policy and/or Value Function
- No Model
- Model Based
- Policy and/or Value Function
- Model
- Model Free
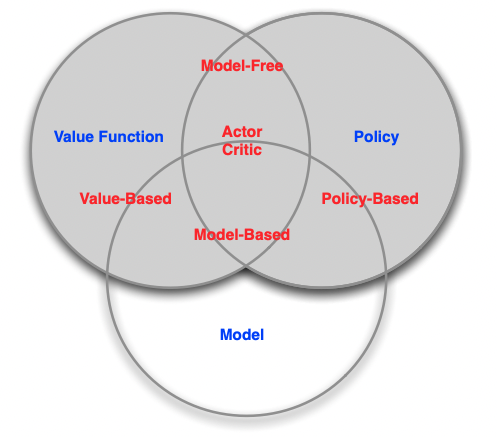
4. Problems within RL
4.1 Learning & Planning
[1]
강화학습 문제의 종류
- (Reinforcement) Learning
- Environment는 initially unknown이다.
- Agent는 environment와 상호작용한다.
- Agent는 자신의 policy를 향상시키려고한다.
- Example with Atari
실제로 게임의 동작과정이나 규칙을 모르는 상태에서, 실제로 Agent가 게임을 플레이하는 과정을 통하여 env와 상호작용하면서 policy가 향상되는 방향으로 학습해나간다.
- Planning
*(a.k.a) delibertation, reasoning, introspection, pondering, thought, search- Environment의 Model은 known이다. (즉, Reward와 Transition을 알고있다.)
- Agent는 model을 이용하여 computation한다.
→ 실제로 environment와 상호작용하지 않고도 simulation할 수 있다.
- Agent는 자신의 policy를 향상시키려고한다.
- Example with Atari
게임의 규칙을 알고 있어서 어떤 query emulator가 존재한다. emulator에 query를 전달하면, 그 Action에 대한 state의 transition, reward등에 대한 질문에 대답할 수 있다.
4.2 Exploitation & Exploration
-
Exploration finds more information about the environment
env로부터 정보를 얻는 과정
-
Exploitation exploits known information to maximise reward
지금까지 얻은 정보를 바탕으로 reward를 maximise할 수 있는 선택을 수행하는 과정
⇒ It is usually important to explore as well as exploit -
Example
- Restaurant Selection
- Exploitation Go to your favourite restaurant
- Exploration Try a new restaurant
- Online Banner Advertisements
- Exploitation Show the most successful advert
- Exploration Show a different advert
- Oil Drilling
- Exploitation Drill at the best known location
- Exploration Drill at a new location
- Game Playing
- Exploitation Play the move you believe is best
- Exploration Play an experimental move
- Restaurant Selection
4.3 Prediction & Control
-
Prediction
- evaluate the future, Given a policy
- policy가 주어졌을 때, 미래를 평가하는 문제 ⇒ value function을 잘 학습시키는 것이 문제의 목적이다.
-
Control
- optimise the future, Find the best policy
- 미래를 최적화하는 문제 ⇒ best policy를 찾는 것이 문제의 목적이다.
-
Gridworld Example
-
Prediction : uniform random policy로 agent가 움직일 때, 각 칸의 value는 얼마가 될 것인가?
-
(a)가 주어진 reward일 때, (b)가 prediction 문제를 푼 결과이다.
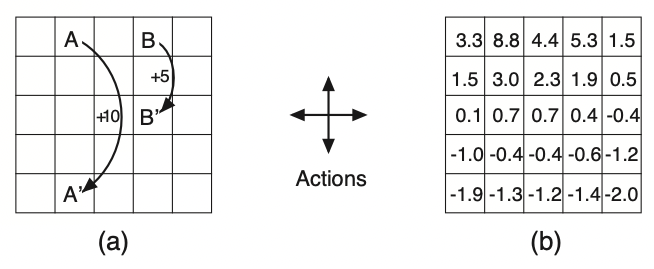
-
Control : 최적 policy는 무엇이고, 최적 policy를 따르는 value function을 이용한 value는 얼마가 될 것인가?
-
(a)가 주어진 reward일 때, (b)와 (c)가 control 문제를 푼 결과이다.
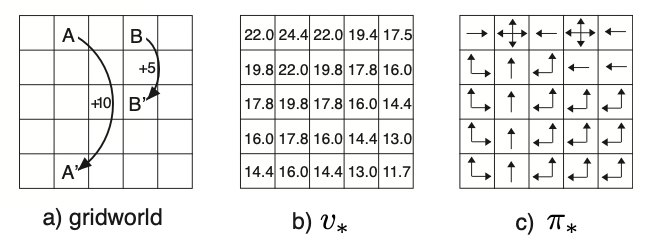
-
Reference
