본 포스팅은 David Silver 교수님의 강화학습 강의와 그 강의를 정리한 팡요랩 강의를 바탕으로 정리한 것입니다.
환경을 알지 못하는 상황에서 던져진 Agent를 이용하여 어떻게 최적의 policy를 찾을 것인가? <Control 문제>
1. Model-free control
1.1 model-free control의 문제점
⚠️ model-free환경에서 control문제를 해결할때는 MDP를 모르기 때문에 발생하는 여러 문제점이 존재한다.
(=를 알지못한다)
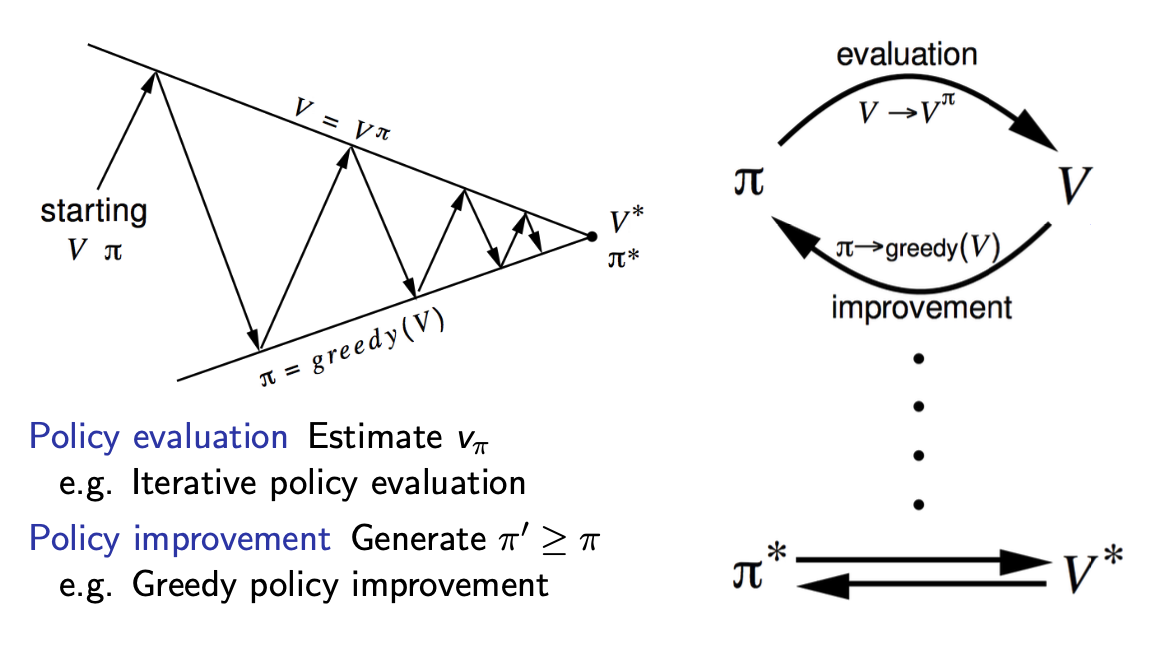
- policy iteration의 원리
-
기본적으로 control문제를 풀기 위해서는 policy evaluation과 policy improvement를 반복해서 수행하면서 점차 개선된 policty를 찾아나가는 과정을 필요로한다.
-
이때, policy evaluation과 improvement 각 단계에서는 어떤 method를 적용하여도 된다.
e.g. (model-based에서는) iterative, greedy
-
- MDP를 모를 때 발생하는 문제점
-
Iterative policy evaluation을 적용할 수 없다.
Iterative policy evaluation은 Bellman Expectation Equation을 기반으로 value를 계산해나가는 과정이다.
그런데 Bellman Expectation Equation에는 MDP를 알아야만 알 수 있는 요소들이 존재하기 때문에 MDP를 알 수 없는 model-free환경에서는 이 식을 그대로 적용할 수 없다.
- state 에서 action 를 했을 때 받는 reward는 실제로 Agent가 경험해봐야만 알 수 있다.
- state 에서 action 을 했을 때 어떤 state 에 도달하게 되는지는 실제로 Agent가 경험해봐야만 알 수 있으며, 경험을 하더라도 구체적인 확률 분포를 정의하지는 못한다.
-
를 기반으로는 Greedy policy를 만들 수 없다.
greedy policy는 state-value function을 기반으로 가장 value가 높은 next-state에 도달하게 하는 action을 선택하는 방법으로 만들어진다.
그런데 model-free환경에서는 어떤 action 을 수행했을 때 어떤 state 에 도달하게 되는지는 실제로 Agent가 경험해봐야만 알 수 있으며, 경험을 하더라도 구체적인 확률 분포를 정의하지는 못한다.
따라서 어떤 action을 했을 때 최종적으로 더 높은 value를 갖는 state에 도달할 확률이 더 높은 action을 선택하는 greedy policy를 정의할 수 없다.
- problem : 2개의 문이 존재하고 각각의 문을 선택할 때마다 reward를 받게 되며, 문을 선택한 뒤에는 그 방으로 들어간다. (model-free)
- action : 왼쪽 문을 연다, 오른쪽 문을 연다
- state : left, right
- episode
-
왼쪽 문을 열고 reward 0을 받은 뒤 왼쪽 방에 들어갔다. →
-
오른쪽 문을 열고 reward 1을 받은 뒤 오른쪽 방에 들어갔다. →
-
더 value가 높은 state인 right에 도달하기 위해 오른쪽 문을 열고 reward 3을 받은 뒤 오른쪽 방에 들어갔다. →
-
더 value가 높은 state인 right에 도달하기 위해 오른쪽 문을 열고 reward 2을 받은 뒤 오른쪽 방에 들어갔다. →
-
- . 오른쪽 문을 여는 행동을 선택하는 것이 과연 최적의 행동이라고 확신할 수 있는가?
. 왼쪽 문을 여는 행동을 딱 한번 수행하는 것으로는 완전히 파악할 수가 없다. (e.g. 왼쪽 문을 다시 열었더니 reward 이 주어질수도 있음)
-
1.2 model-free에서 Policy improvement
MDP를 모를 때 발생하는 문제점의 해결방안
- policy evaluation 단계
즉 prediction 문제는 model-free prediction문제를 해결하는 방법론인 MC, TD를 적용하여 평가할 수 있다.
- policy improvement 단계
- 더 나은 action을 평가하는 기준으로 state-value 대신에 action-value 를 이용한다.
- exploration을 고려하기 위하여 -greedy 방법을 이용한다.
- Greedy policy improvement
-
MDP를 알아야, 에 대하여 greedy policy improvement를 할 수 있다.
model-free일 때는 할 수 없다!
-
model-free일 때는 에 대하여 greedy하게 action을 선택하는 방법으로서 greedy policy improvement를 수행할 수 있다.
-
- -greedy Exploration
-
Exploration이 고려되어야하는 이유
model-based와 달리 model-free환경에서는 실제로 Agent가 action을 선택하고 state사이를 이동하면서 환경에 대한 정보를 배우게 된다. 그런데 학습의 초기 단계에서부터 greedy action만을 선택한다면 Agent가 다양한 state를 방문하지 못하고 이미 방문한 state만 계속 방문하게 될 수 있다.
-
각 action이 non-zero probability를 가질 때, ()
-
의 probability만큼 greedy action을 선택한다. → policy가 계속 emprovement함을 보장한다.
-
의 probability만큼 random action을 선택한다. → agent가 모든 state를 방문할 수 있음을 보장한다.
-
-
(Theorem) -greedy policy improvement
For any -greedy policy , the -greedy policy with respect to is an improvement
-
state 에서의 action은 을 따라 선택하고 이후에는 를 따라 시행했을 때의 action-value 를 bellman equation으로 표현한 것
-
를 epsilon-greedy형태로 표현한 것
가능한 모든 action에 대하여 greedy action에 대해서는 을 곱해주고 그렇지 않은 경우 그냥 만을 곱해주었다. *(probability value)
-
geedy action에 대한 value는 다른 어떤 action-value보다도 큰 값이기 때문에 다른 action들에 대한 weighted-sum보다도 큰 값을 가진다.
*weight는 4번째 식으로 정리하기 위해 곱해준 임의의 값
-
해당 수식은 로 표현된다. (action-value간의 관계)
→ 1-step에 대해서 더 좋음을 보이면 결국 policy improvement theorem에 의해 임을 보일 수 있다.
-
-
1.3 on-policy와 off-policy
- On-policy Learning
- Learn on the job
- 학습시키려는 policy와 실제 environment에서 Agent가 경험을 쌓을 때 따르는 policy가 동일한 경우
- Off-policy Learning
- Look over someone’s shoulder
- 학습시키려는 policy와 실제 environment에서 Agent가 경험을 쌓을 때 따르는 policy가 다른경우
2. On-Policy Monte-Carlo Control
2.1 Monte-Carlo Control
for Every episode :
- Policy evaluation : Monte-Carlo policy evaluation,
- Policy improvement : -greedy policy improvement
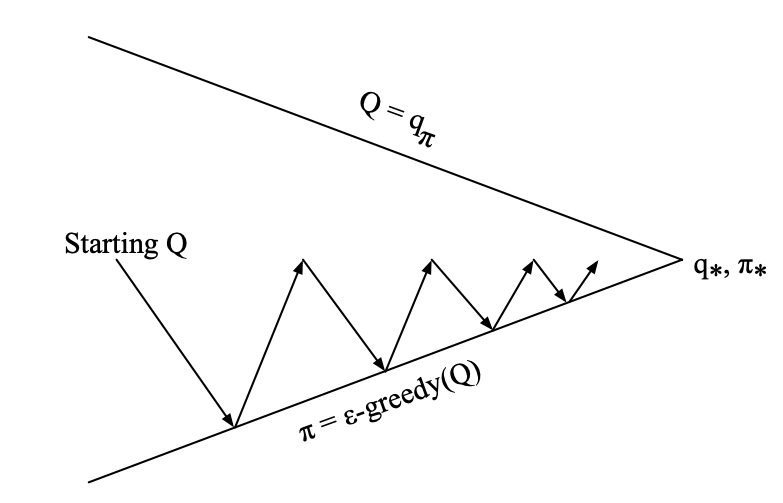
*효율적인 갱신방법 : policy evaluation을 수행할 때, 에 수렴할 때까지 진행하지 않고 early-stop한다.
→ Agnet가 경험한 하나의 episode에 대한 정보를 가지고 바로 더 나은 pocliy로 갱신
2.2 GLIE property
- Definition of Greedy in the Limit with Infinite Exploration : GLIE
⇒ GLIE와 -greedy : 예를 들어, 이 점차 으로 수렴한다면() GLIE의 조건을 만족시킬 수 있다.Greedy in the Limit with Infinite Exploration under the following conditions :
-
All state-action pairs are explored infinitely many times,
-
The policy converges on a greedy policy,
-greedy를 이용한다면 optimal Q-value를 가지고 있더라도 이라는 확률만큼은 최적이 아닌 랜덤한 action을 수행하기 때문에, 결국 최적의 policy를 찾기 위해서는 최종적으로 greedy policy에 수렴해야한다.
-
- GLIE Monte-Carol Control 를 따라 수행한 번째 episode에서,
- For each state and action in the episode, (in Evaluation)
* : 수행 횟수 - Improve policy based on new action-value function (in Emplovement)
- For each state and action in the episode, (in Evaluation)
- (Theorem) GLIE Monte-Carol Control의 수렴성
GLIE Monte-Carlo control converges to the optimal action-value function,
2.3 MC vs. TD Control
-
TD의 장점
- MC에 비하여 Lower variance
- Online Update
- Incomplete sequence에도 적용가능하다.
-
TD를 MC대신에 control loop에 적용하자!
- apply TD to
- -greedy policy improvement
- Update every time-step
3. On-Policy Temporal-Difference Learning
3.1 SARSA
-
SARSA: state 에서 action 를 수행하여 reward 을 받고 next state 에 도달한 뒤, 다시 action 를 수행하는 과정
-
SARSA를 이용한 Action-Value function Update
- TD Target :
- TD error :
-
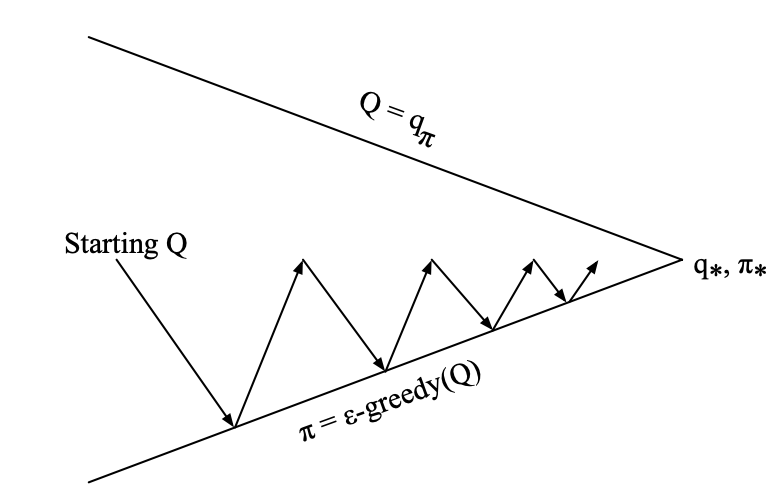
for Every time-step :
-
Policy evaluation : SARSA,
-
Policy improvement : -greedy policy improvement
-
3.2 SARSA Algorithm
- SARSA 알고리즘 설명
-
초기에는 랜덤한 값들로 Q-table을 초기화한다.
-
에 대한 -greedy방법을 이용하여 state 에서의 action 를 고른다.
-
action 를 Agent가 시행하고, 그 결과로 받게되는 reward 과 도달한 next-state 에 대한 정보를 받는다.
-
에 대한 -greedy방법을 이용하여 이동한 state 에서의 action 를 선택한다.
-
next state-action pair에 대한 Q-value를 이용하여 current Q-value를 TD방법으로 업데이트한다.
-
current state, action에 , 를 대입한다.
-

3.3 Convergence of SARSA
- (Theorem) SARSA의 수렴성
SARSA converges to the optimal action-value function , under the following conditions :
- GLIE sequence of policies
- Robbins-Monro sequence of step-sizes : step size는 충분히 커야하지만, 수렴할 정도로 작아야한다.
3.4 n-step SARSA(𝝺)
-
n-step SARSA()
-
일 때의 Q-return
만큼의 실제 reward와, 번째 step에서의 추정 value function의 합으로 표현한다.
- : [SARSA]
- :
- : [MC]
-
n-step Q-return의 define
-
n-step SARSA learning
-
n-step TD target :
-
n-step TD error : ; target과 이전 예측 값의 차이
-
-
-
Forward View SARSA()
- -return : SARSA부터 MC까지 진행했을 때의 모든 return의 평균
-
각 n-step return 에 대하여 weight를 적용하여 계산한다.
-
이 커질수록 가 계속해서 곱해지게 되므로 더 작은 가중치를 가지게 된다.
-
- Forward-view SARSA() Update
- -return : SARSA부터 MC까지 진행했을 때의 모든 return의 평균
- Backward View SARSA()
-
아이디어
- TD()에서 사용한 것처럼 SARSA도 eligibility traces를 적용할 수 있다.
- 단, SARSA는 Q-function에 대해 TD를 적용하므로 각각의 state-action pair에 대해 대응되는 하나의 eligibility trace를 가진다.
-
eligibility trace
- init :
- time-step 에서 어떤 state 에서 어떤 action 를 수행하면, 을 더해주고 방문하지 않았을 때는 에서의 값에다가 를 곱해줘서 값을 감소시킨다.
-
Backward-view SARSA() Update
-
- SARSA()의 효율성 (Gridworld Example)
- one-step SARSA에서는 reward를 받는 순간, 그 state에만 갱신이 된다.
- 그러나 SARSA() *는 reward를 받는 순간, 그 state까지 오기까지 거쳤던 모든 state, action에 대해 약간이나마 그 reward가 전파된다!
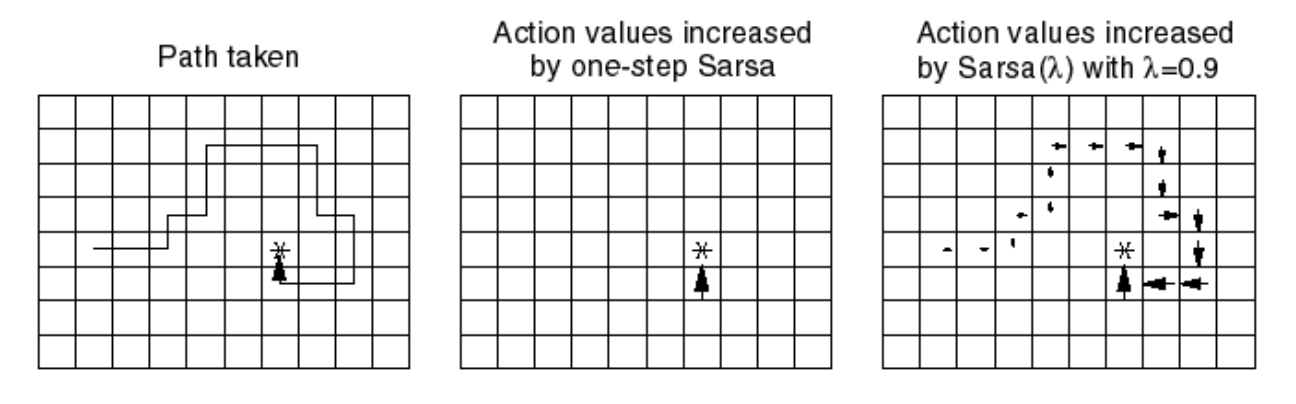
3.5 SARSA(𝝺) Algorithm
- SARSA() 알고리즘 설명
-
초기에는 랜덤한 값들로 Q-table을 초기화한다.
-
에 대한 -greedy방법을 이용하여 state 에서의 action 를 고른다.
-
action 를 Agent가 시행하고, 그 결과로 받게되는 reward 과 도달한 next-state 에 대한 정보를 받는다.
-
에 대한 -greedy방법을 이용하여 이동한 state 에서의 action 를 선택한다.
-
next state-action pair에 대한 Q-value를 이용하여 current Q-value와의 차이; TD error를 계산한다.
-
current state-action pair에 대한 eligibility; 방문횟수를 1 더해준다.
-
모든 에 대하여 eligibility를 고려한 만큼의 TD-error값을 더하여 Q-value를 갱신하고, 다른 실제로 방문되지 않은 state-action pair에 대해 eligibility를 감소시키는 과정을 반복한다.
(=Q-table 전체를 업데이트 한다.)
-
current state, action에 , 를 대입한다.
-

4. Off-Policy Learning
4.1 off-policy learning
-
off-policy란?
target policy 를 따랐을 때의 value를 계산하거나, policy를 개선하고 싶을 때 target과 다른 behavior policy 를 따랐을 때의 경험적 정보를 활용하는 방법
-
target policy : compute or
-
behavior policy :
→ 실제로 action을 sampling 할 때 사용하는 policy
-
- off-policy의 장점
- 사람이나 다른 agent가 수행한 결과를 보고 나의 target policy를 emprovement 할 수 있다.
- emprovement policy에 대해 다시 iterative를 수행할 때, 이미 과거에 했던 경험을 재사용할 수 있다. (=behavior policy는 update되지 않았으므로)
- behavior policy가 exploration하는 경험을 바탕으로 optimal policy를 학습할 수 있다. *trade-off에서 탈출!
- 하나의 behavior policy의 경험을 바탕으로 여러개의 policy들을 학습시킬 수 있다.
4.2 Importance Sampling for off-policy
-
Importance Sampling
-
notation
- : 확률분포 를 따라 sampling되는 확률변수
- : 와는 다른 어떤 확률분포
- : input에 대한 어떤 function
-
proof
1. 를 따라 samping된 에 대한 의 Expectation은 expectation의 definition에 의해 probability value의 합으로 표현될 수 있다.
2. 위 수식을 에 대한 probability로 나타내기 위하여 를 분자 분모에 동일하게 곱해준다.
3. 위 수식은 이제 의 형태로 해석할 수 있고, 이는 를 따라 samping된 에 대한 의 expectation으로 나타낼 수 있다!💡 두 확률분포의 비율만 곱해주면 어떤 확률 분포를 기반으로 구한 값에 대한 기댓값을 다른 확률 분포를 기반으로 구했을 때에 대한 기댓값으로 표현할 수 있다!
-
-
Importance Sampling for Off-policy MC
-
를 얻을 때까지 수행한 각각이 action이 선택될 확률의 비을 계속 곱해준다.
-
return
-
Update
-
그러나 MC는 전체 episode가 끝난 다음에 를 받아 계산하기 때문에, 끝날때까지 수행한 action의 수가 커지면 커질수록 의 앞에 곱해지는 ratio가 너무 많아지기 때문에 실제로 이 방법을 사용해서 계산할 수는 없다. (ratio들의 곱에 대한 variance가 너무 큼)
→ 그렇다면 1-step해서도 수행가능한 TD는?
-
-
Importance Sampling for Off-policy TD
TD의 경우에는 앞에 곱해지는 term이 훨씬 적기 때문에 Importance sampling을 이용하여 off-policy method로 학습할 수 있다.
4.3 Q-Learning
-
Q-Learning의 특징
-
No importance sampling required !
-
Agent가 실행할 실제 next-action은 behaviour policy를 따라 선택된다.
- 그러나 Q-function을 update할 때는 target policy를 따라 선택된 action 에 대하여 계산한다!
TD는 reward + 추측값과의 차이를 이용하여 현재값을 update하는데, 추측값에서는 behavior policy를 따르지 않아도 상관없기 때문이다.
- update (by Bellman Equation!)
-
-
off-policy control with Q-Learning
-
(both) policy improvement
아이디어 : behavior policy와 target policy 둘다 점차 emprovement가 되지만, behavior policy는 여전히 exploration을 고려할 수 있도록 policy를 설정하고 싶다.
- target policy : greedy
- behavior policy : -greedy
- target policy : greedy
-
Q-Learning target
target policy를 이용하여 선택된 action A’를 greedy policy에 대한 수식으로 바꾸어 표현할 수 있다.
-
Q-Learning Update
-
-
(Theorem) Q-learning Control의 수렴성
Q-learning control converges to the optimal action-value function,
4.4 Q-Learning Algorithm
- Q-Learning 알고리즘 설명
-
초기에는 랜덤한 값들로 Q-table을 초기화한다.
-
에 대한 -greedy방법을 이용하여 state 에서의 action 를 고른다.
-
action 를 Agent가 시행하고, 그 결과로 받게되는 reward 과 도달한 next-state 에 대한 정보를 받는다.
-
에 대한 greedy방법을 ***이용하여 state 에서의 action 를 선택한다.*
-
Q-Learning Update를 수행한다.
-
current state, action에 만 대입한다.
-

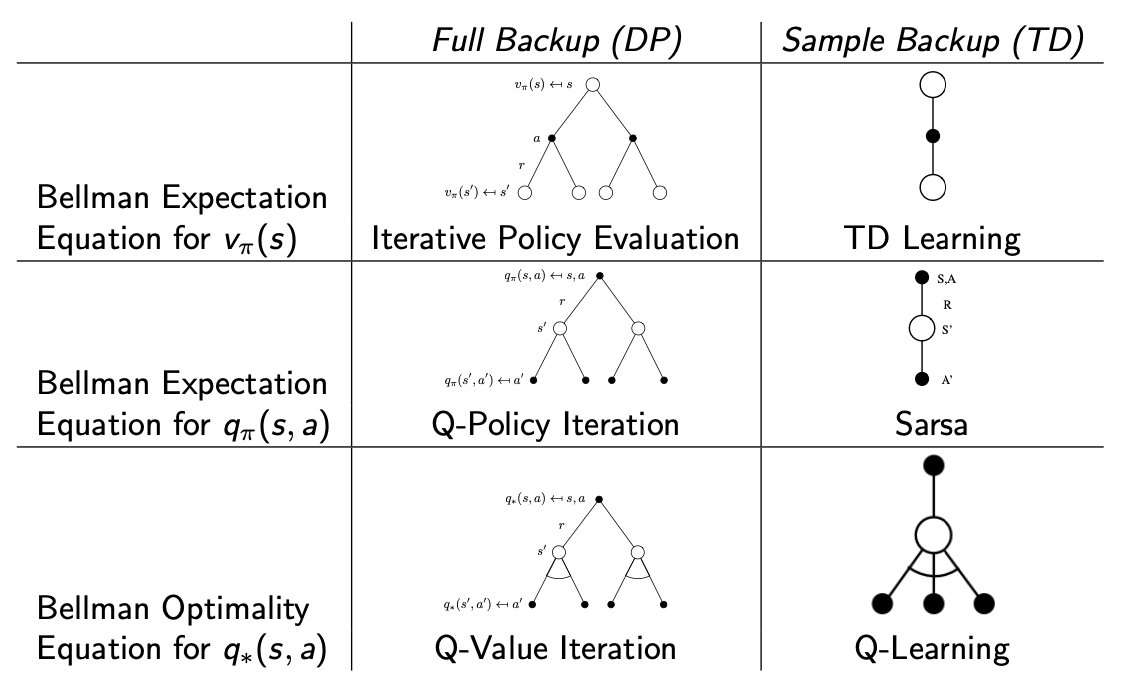
Summary
Relationship Between DP and TD
(where

Reference
