이전 수업리뷰
무결성 - 제약조건
/DB에서 가장 중요/
도메인 무결성 - 도메인 제약조건(타입 설정, 범위 고정)
참조 무결성 - 참조 제약조건(Foreign key) - 참조하는 데이터의 업데이트, 삭제시 어떻게 할 것인가?를 설정해야 한다
개체 무결성 - 키 제약조건(Primary Key) : 슈퍼키(유일성), 후보키(유일성, 최소성), 기본키Disk & File
(Quiz) x86 시스템에서 CPU 내부의 Resigter 갯수는? 16
기초지식) PC에서 CPU는 연산을, 메모리는 저장(캐시, 메모리-주기억장치)을 담당한다. DB도 다르지 않다.
사용자가 Data를 보고싶으면 보조기억장치 -> 주기억장치 -> CPU 연산처리 -> 사용자 라는 흐름을 가진다.
버퍼 관리자 - 찾은 데이터를 바탕으로 메모리에 올라온 데이터를 관리한다 (윈도우에서 가상메모리가 작동하는 방식과 유사)
파일 관리자 - DB는 하나의 파일을 여러 디스크에 저장할 수 있어야한다. 반면 PC에 운영체제는 하나의 파일을 여러개의 디스크에 저장할 수 없다
디스크 관리자 - 8TB의 디스크에서 1Byte의 파일을 찾고싶을 때, 어떻게 찾을것인가?
기억장치 계층구조 개요
DB에서 3차 저장장치(디스크, 테이프)를 어디에 쓸까? - 백업 용도로 사용한다
디스크 - HDD,SDD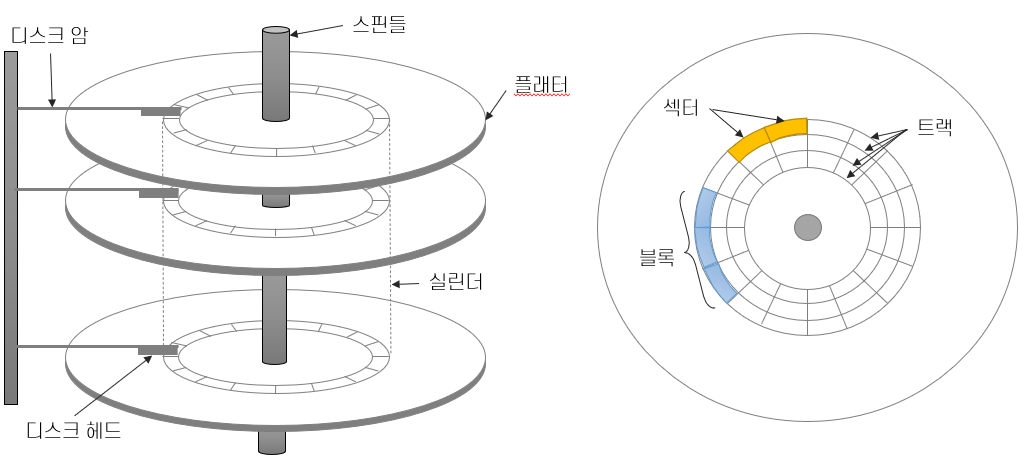
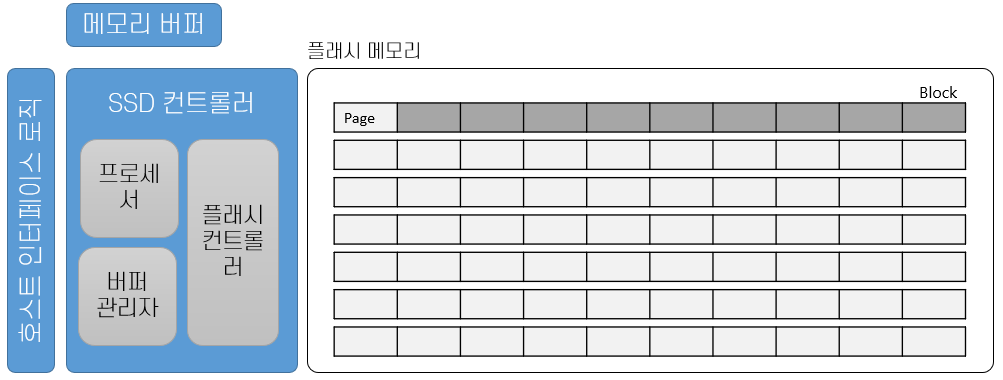
HDD - 자기장 이용, SSD - 반도체 이용(모든 구성요소가 전기장치)
디스크의 성능
HDD - DBMS가 작업을 수행하려면 데이터는 주 기억장치에 있어야 한다
- 블록단위로 전송되므로, 블록내 항목 중 하나만 필요해도 전체 블록이 올라가야 한다
SSD - 전송시간만 소요(HDD와 구분), 쓰기의 경우 빈 공간이 없으면 공간을 초기화 하고,
이 작업시간동안 해당 공간에 대한 I/O 작업이 대기 상태가 된다비어있는 블록의 추적 감시
레코드를 삽입함에 따라 DB는 확장되고 축소된다
DBMS는 사용중인디스크 블록과 페이지가 어떤 블록에 존재하는지 추적 감시함
추적감시
- 비어있는 블록들의 리스트를유지
- 디스크 블록마다 1비트씩 블록의 사용 여부를 나타내는 비트맵 유지
운영체제 파일 시스템을 이용한 디스크 관리
DBMS는 운영체제의 파일 시스템을 바탕으로 데이터베이스를 관리하기도 한다
하지만 대부분의 DBMS는 운영체제의 파일 시스템에 의존하지 않는다
운영체제 사양에 맞추면 DBMS 이식이 너무 힘들어진다
운영체제는 최대 파일 크기를 제한하는 경우가 있다
운영체제 파일은 여러 디스크로 분할되지 못한다
페이지 참조 패턴을 일반적인 운영체제보다 더 정확히 예측해야 한다
페이지를 디스크에 기록하는 시점에 대해 운영체제보다 더 많은 제어를 해주어야 한다버퍼 관리자
대부분의 DB는 주 기억장치보다 더 큰 용량을 가지는데 CPU는 주 기억장치에 적재된 데이터만 처리할 수 있다. 따라서 DBMS는 필요할 때 마다 데이터를 주 기억장치에 적재해야 하고, 언제 페이지를 교체해야 하는지 결정해야 함
버퍼 풀 - 가용한 주 기억장치 공간을 페이지라는 단위로 분할한 데이터 적재 공간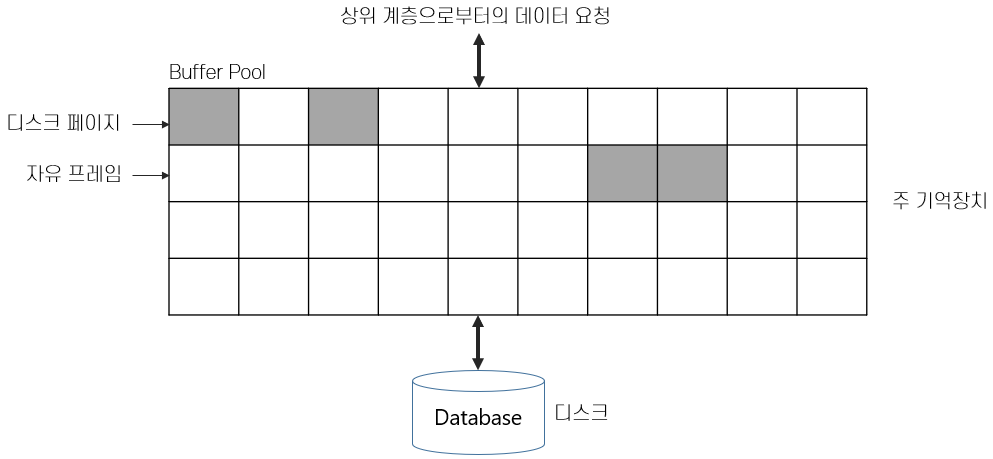
버퍼풀 내부 프레임에 들어있는 데이터 : 레코드 (프레임 0Xff01에 들어있는 레코드 : )
RID - 프레임 번호 + 레코드 번호 (SQL에서 RID LookUp으로 사용)
Pin Count를 사용해서 DB가 몇명의 Client가 해당 Page를 참조하는지 확인한다. 만약 Pin Count가 N이면 페이지 교체를 해준다(이런 작업이 없으면 페이지 교체가 되지 않아서 대기중인 사용자는 DB가 고장난것처럼 느끼게 된다)
Dirty Bit: Dirty Bit가 발생하면 즉시 디스크에 바뀐 정보를 작성한다
버퍼 교체 전략 - LRU, Clock, FIFO, MRU, Random
알고리즘의 페이지 교체 전략과 거의 유사하다
Scale-Up / Scale-Out
Scale up : 기존의 서버를 보다 높은 사양으로 업그레이드
Scale out : 장비를 추가해서 확장하는 방식 (DBMS는 Scale out이 어려움)
DB는 확장이 불가능하다. 또, 한개만 쓰는게 좋다
WAL (Write Ahead Log) 프레임에서 Pincount와 상관없이 DirtyCount가 (Ex)1이면 무조건 쓰기 과정을 수행한다
레코드 형식 - 고정길이 레코드, 가변길이 레코드
고정길이 레코드 - 각 필드의 길이가 고정적이고 필드의 수도 고정된 레코드 형식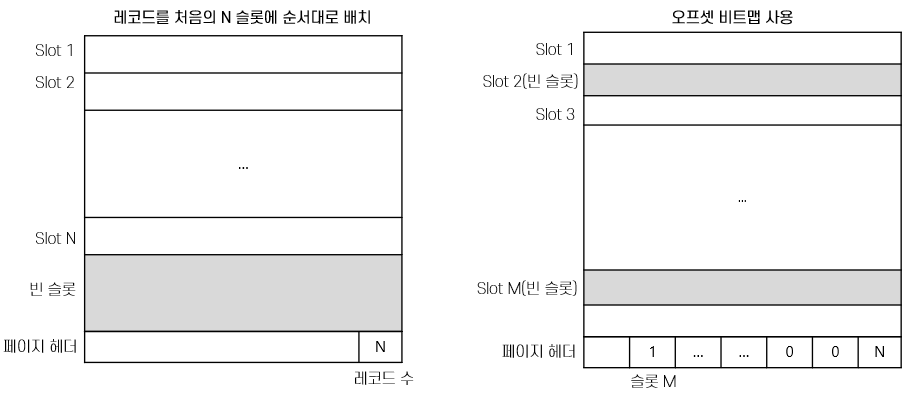 같은 타입의 데이터가 반복되서 속도가 빠르다
같은 타입의 데이터가 반복되서 속도가 빠르다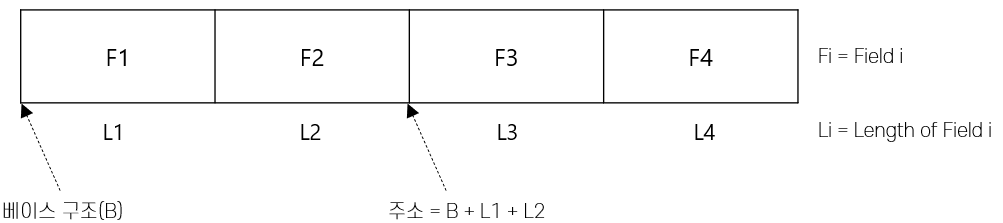
ex) 자바 - 배열, Char, Int등
가변길이 레코드 - 필드의 길이가 가변적인 경우, 해당 레코드의 길이가 가변적으로 된다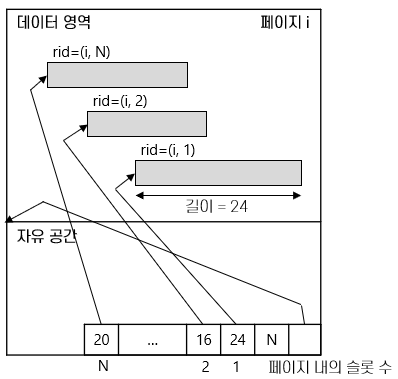 - 필드를 분리자로 구분하여 연속적으로 저장
- 필드를 분리자로 구분하여 연속적으로 저장 - 레코드의 앞부분에 정수로 된 오프셋들을 배열로 저장
- 레코드의 앞부분에 정수로 된 오프셋들을 배열로 저장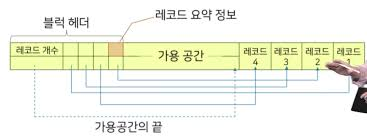
ex) nvarchar()
속도 측면에서는 고정길이 레코드가 유리하다. 하지만 모든것을 고정길이로 하면 불편하고, 저장장치의 낭비도 생긴다.
페이지 형식
페이지 - 레코드가 탑재되는 슬롯의 모임
레코드는 <페이지 번호, 슬롯번호> 의 쌍으로 식별 가능
<페이지 번호, 슬롯번호> 쌍을 RID라 하며, 레코드 포인터가 됨파일과 인덱스 - 힙, ISAM, 인덱스
Heap 파일 - 가장 간단한 파일구조로, 레코드가 파일의 빈 공간에 순서 없이 저장
파일을 그냥 더미처럼 쌓아놓는다고 생각하면 편하다
페이지 내부의 데이터가 어떤 형태로도 정렬되지 않으며 파일의 모든 레코드를 검색하면 다음 레코드를 되풀이해서 요청해야 한다
파일의 레코드는 각기 유일한 rid를 가지며, 한 파일에 속하는 페이지는 크기가 모두 같다
파일의 생성과 제거, 레코드의 삽입과 rid를 통한 레코드 (삭제, 선택), 파일 내의 모든 레코드 스캔 연산을 지원함
일반적으로 B Tree 혹은 B+Tree를 사용해서 구현한다
인덱스 개요 - 선택 조건에 맞는 RID를 구할 수 있도록 만든 보조 자료 구조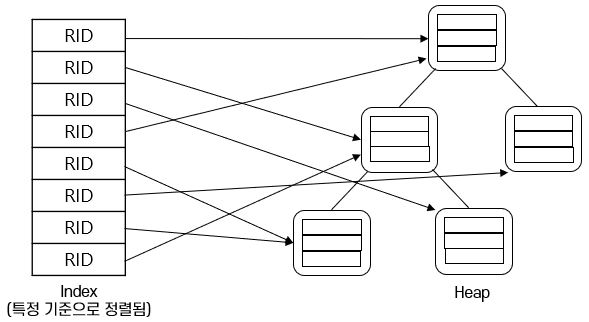
대부분의 자료 구조는 저장된 데이터의 rid를 직접 알 수 없다
정렬되지 않은 자료 구조에서 검색을 수행할 경우, 전체 자료 구조를 스캔해야 한다
정렬은 데이터 기준, 검색은 RID 기준
ISAM - 색인 순차 접근 방식 파일(MySQL에서 사용), 최근에는 잘 쓰이지 않는다
오버플로우 데이터가 없을때는 굉장히 빠르지만, 오버플로우 데이터가 있을 경우 상당한 부하가 걸린다
B+트리 - ISAM을 수정하여 오버플로우가 나지 않도록 한 동적 트리 자료구조
내부 노드들이 탐색 경로를 유도하고 단말 노드들이 데이터 엔트리를 가지는 균형 트리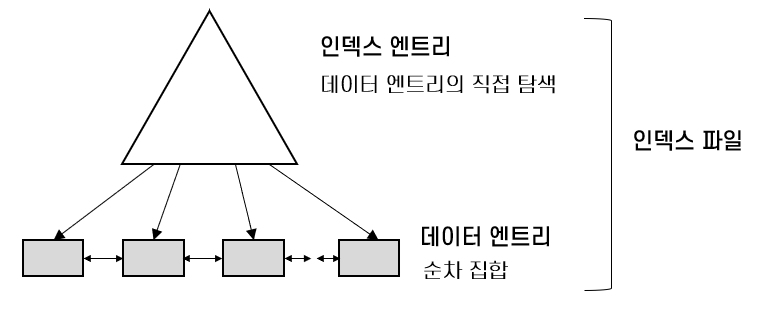
트리에서 삽입, 삭제를 수행해도 트리의 균형이 유지됨
레코드를 탐색할 때 루트로부터 알맞은 단말 까지만 가면 됨시스템 카탈로그 - 자신이 가지고 있는 모든 데이터에 대한 설명 정보 저장(DB)
(MySQL - Information Schema 같은것)
파일 조직과 인덱스
re) 인덱스란? 파일 검색 속도를 빠르게 하기 위한 보조 자료구조
DB 흐름도
사용자
Query Optimizer : 사용자가 작성한 Query를 최적화 해준다
해석기
Buffer Manager
File Manager
Data Manager
DiskQuery Optimizer : Cost 기반, Procedure 기반 두가지로 나누어진다
비용 모델 개요
페이지수 B, Page 쓰는시간 D, 레코드 수 R, 레코드 처리시간 C, 한 레코드에 해시함수 적용시간 H파일 조직법 비교 기준 연산
스캔(Scan) - 파일에 있는 모든 레코드를 가져옴. 파일에 있는 페이지들은 디스크로 부터 버퍼 풀로 반입 되어야함
동등 셀렉션(Equality Selection) - 질의에서 요구하는 검색어와 같은 문자열임을 만족하는 모든 레코드를 가져옴
범위 셀렉션(Range Selection) - 1에서 10까지, 홍길동에서 이순신까지 등 범위에 해당하는 모든 레코드를 가져옴
삽입(Insertion) - 주어진 레코드를 파일에 삽입
삭제(Deletion) - RID로 명세된 레코드 삭제.Heap File, 정렬 File, Hash File
힙 파일 - 정렬되지 않은 단순한 형태의 파일
삽입에 대해서는 효율이 좋으나 나머지는 좋지않다
스캔 B(D+RC)
동등 셀렉션 후보 키에 대한 연산일 경우 0.5B(D+RC). 후보 키가 아닌 경우 스캔과 동일
범위 셀렉션 스캔과 동일
삽입 레코드가 항상 파일의 끝에 삽입된다고 가정할 경우 2D+C
삭제 탐색 비용 + C + D정렬 파일 - 특정 필드를 기준으로 정렬된 파일
스캔 - 힙 파일과 다르지 않음. B(D+RC)
동등 셀렉션 - 정렬 기준 필드로 검색할 경우 이진 탐색으로 Dlog2B + Clog2R.
정렬 필드가 아닌 경우 스캔과 동일
범위 셀렉션 - 정렬 기준 필드로 검색할 경우 첫 레코드를 찾는데 동등 셀렉션과 동일.
이후 범위내 스캔
삽입 - 정렬 순서를 유지하기 위해 레코드가 삽입될 위치를 검색 후 레코드 추가.
후속 페이지를 모두 로드하여 다시 저장. 탐색 비용 + B(D + RC)
해시 파일 - 특정 필드를 기준으로 정렬된 파일
스캔 - 힙 파일과 다르지 않음. B(D+RC)
동등 셀렉션 - 정럴 기준 필드로 검색할 경우 이진 탐색으로 Dlog2B + Clog2R.
정렬 필드가 아닌 경우 스캔과 동일
범위 셀렉션 - 정렬 기준 필드로 검색할 경우 첫 레코드를 찾는데 동등 셀렉션과 동일. 이후 범위내 스캔
삽입 - 정렬 순서를 유지하기 위해 레코드가 삽입될 위치를 검색 후 레코드 추가.
후속 페이지를 모두 로드하여 다시 저장. 탐색 비용 + B(D + RC)
파일 조직 선택 힙 파일은 저장 성능이 우수하고 스캔, 삽입, 삭제 연산이 빠르지만 탐색은 느리다
힙 파일은 저장 성능이 우수하고 스캔, 삽입, 삭제 연산이 빠르지만 탐색은 느리다
정렬 파일은 저장 성능이 우수하고, 삽입, 삭제 연산이 느리지만 탐색이 대단히 빠르다
해시 파일은 저장 성능이 떨어지지만, 삽입과 삭제가 빠르며 동등 탐색에서 대단히 우수. 하지만 범위탐색을 지원하지 못하고 스캔 성능이 떨어짐
정렬된 데이터(PK) - Seek 수행 (빠르다)
정렬되지 않은 데이터 - Scan 수행 (느리고 효율이 떨어진다)
ex) 이름으로 검색하는 경우 (PK가 없다) -> 전체 데이터에서 이름을 찾는건 너무 오래걸리니 이름으로 구성된 보조자료 구조를 활용한다! ---> 인덱스를 활용한다
검색 뿐 아니라 join 등을 사용할 때도 성능 향상이 일어난다
인덱스 - 해당 파일의 기본적인 레코드 조직법으로는 효율적으로 지원되지 않는 연산의 속도를 높이기 위한 보조 자료구조
인덱스의 종류 - Clustered Index, Non-Clustered Index
클러스터드 인덱스 - 파일을 조직할 때 레코드의 순서를 파일에 대한 인덱스의 순서와 동일한 순서로 유지
파일의 재조직이 필요한 구조
데이터가 삽입/삭제될 때 마다 정렬 순서를 유지하기 위해서 그 주변의 데이터를 이동해야 함
파일이 동적으로 변하는 경우 유지 관리 오버헤드가 높음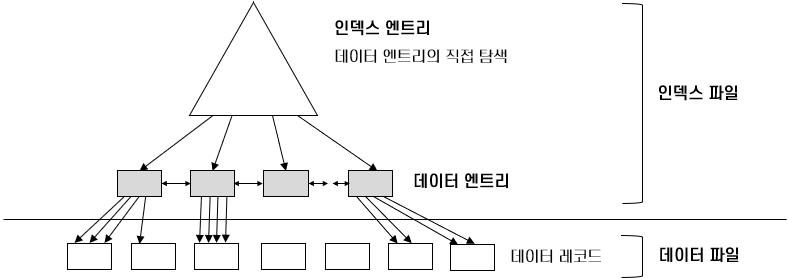
넌 클러스터드 인덱스 - 하나의 데이터 파일은 하나의 탐색키에 대해서만 클러스터링 될 수 있음
하나의 데이터 파일에 대해 하나의 클러스드 인덱스만 만들 수 있음
클러스터드 인덱스 구조 파일의 키가 아닌 필드의 빠른 검색을 위한 보조 자료구조밀집 인덱스, 희소 인덱스
밀집 인덱스 - 파일에 있는 모든 탐색 키 값에 대해 데이터 엔트리 구성
희소 인덱스 - 데이터 파일의 페이지별로 하나의 데이터 엔트리를 구성
기본 인덱스, 보조 인덱스
기본 인덱스 - 기본 키를 포함한 필드들에 대한 보조 인덱스
기본키를 희소, 클러스터드 인덱스로 지정하는 DBMS도 있다
보조 인덱스 - 기본키 이외의 인덱스
키 필드가 아닌 필드에 대한 인덱스는 중복이 있을 수 있다
복합키 인덱스
복합키 인덱스 - 인덱스가 여러 개의 필드를 포함하는 경우 (데이터 조직과 쿼리 형태에 따라 높은 성능을 보인다) - 인덱스가 컬럼 하나만 보는게 아니라 컬럼 두개를 보게 하는 경우
(인덱스는 면접에 자주 나오는 부분이니 다시 한번 보도록 하자)
Index는 QueryOptimizer에서 사용한다.
만약에 QueryOptimizer가 Index를 사용하지 않으면 "Hint" 혹은 "Index Hint"를 사용해서 강제로 Index를 사용할 수 있게 할 수 있다.
