복습
사용자 -> Query Optimizer -> 해석기 -> 버퍼 매니저 -> 파일 매니저 -> 디스크 매니저
파일의종류) Heap, 정렬파일-(ISAM, BTree, B+Tree), Hash
파일매니저 - 페이지
버퍼매니저 - 버퍼 풀(프레임(페이지(레코드)))
프레임 - 물리 메모리를 일정한 크기로 나눈 블록
페이지 - 가상 메모리를 일정한 크기로 나눈 블록
파일을 검색하는 5가지 방법에 따라 파일의 종류별로 검색의 속도가 다르다.
DBMS마다 선택한 파일의 종류가 다르다
인덱스를 사용하여 검색 속도를 증가시킴 (검색속도를 증가시키기 위한 보조자료구조)
클러스터, 논 클러스터, 기본 인덱스, 복합키 인덱스, 등
조언) 전산학 기초의 바탕이 중요하다 - 운영체제, 아키텍처, DB등
관계대수식, 페이지 falut, 등...
알고리즘도 중요한데 전산학 기초도 물어본다(더 어려워졌다)
Statement와 Expression의 차이
Statement : 문(for 문 등); 상태가 변함
Expression : 표현식(식); 상태가 변하지 않음, 연산만 일어남
(Query Optimizer - Relational Algebra, 해석기-Relational Calculus)
관계대수 - 관계 모델에 관한 두 가지 형식 질의어 중 하나. 연산자들의 모임을 이용하여 대수로 표현. 대수로 표현되는 성질로 인해 연산자들을 조합하여 복합한 질의 만들기
a = 1 / Statement
b = 2 / Statement
a + b / Expression
C = a + b / Statement (c = (expression a+b))이 과정을 관계형 DB로 옮겨보자
c = a+b (릴레이션 c = 릴레이션 a + 릴레이션 b))
DB는 집합 연산식으로 모든걸 표현할 수 있다. (교집합 차집합 멱집합 합집합, 카티션 프로덕트([1,2,3]* [4,5,6] = [(1,4), (1,5) ,..., (3,6)] 등)
관계 대수 개요 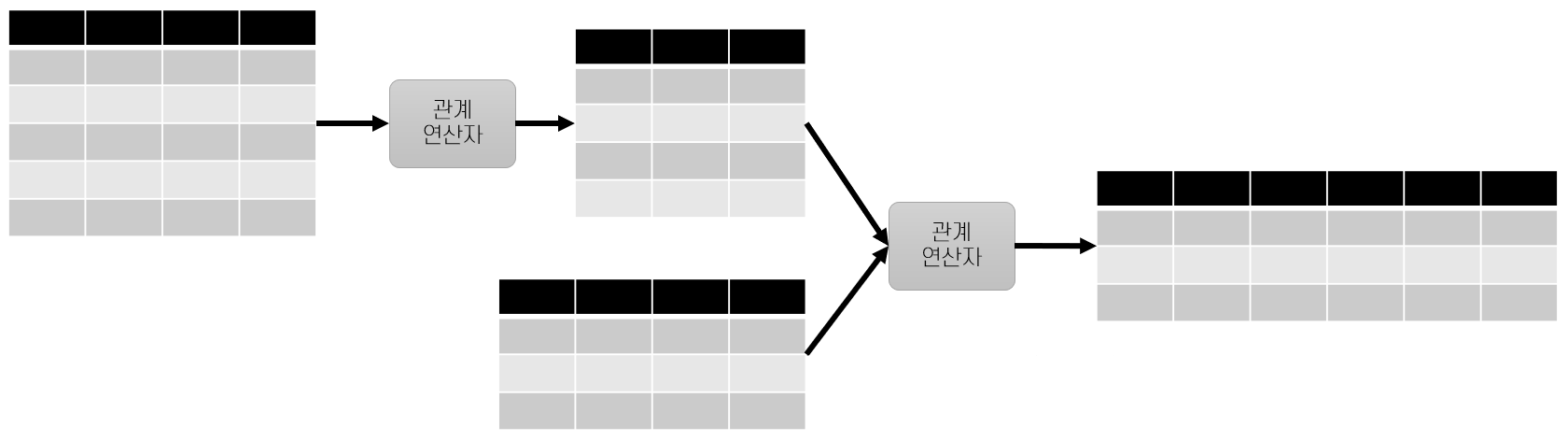
관계 대수식 - 연산자들의 모임을 사용해서 구성된 대수식
한 릴레이션, 단일 식에 적용한 단항(Unary) 대수 연산자, 또는 두 개의 식에 적용한 이항(Binary) 대수 연산자로 순환적으로 정의됨. 관계 대수의 기본 연산자인 셀렉션, 프로젝션, 합집합, 교집합, 카티션 프로덕트로와 이의 조합으로도 만들 수 있음
연산자들을 조합해서 복잡한 질의를 만들기 쉬움
릴레이션, 단항(Unary) 연산자와 이항(Binary) 연산자로 순환적으로 정의
셀렉션, 프로젝션, 합집합, 차집합, 카티션 프로덕트등의 기본 연산자의 조합으로 구성
관계 질의는 연산자의 적용 순서를 통해 원하는 답을 구하는 계산 절차를 한 단계씩 묘사한 것
-대수식은 질의 수행을 위한 계획으로 생각할 수 있음
-관계 시스템은 대수식을 질의 수행 계획으로 표현하는데 이용관계 연산자 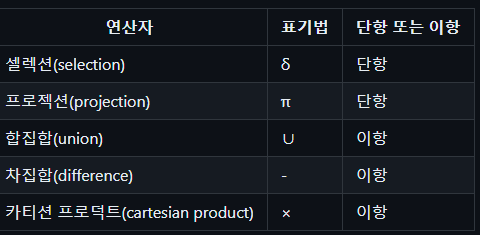
테이블 기준
δ(selection, sigma) : 가로연산(tuple 고르기) - where 절
π(pi, projection) : 세로연산(column 고르기) - select 절 /
어디서?(table) - from절)
∪(union) : 합집합
- (intersection) : 차집합
SQL : 관계대수식을 바탕으로 생성한 언어
ex)
π productName,CategoryName(δ productNo=2(Product ⋈ Category))
SELECT productName, CategoryName
FROM product NATURAL JOIN Category
WHRERE productNo = 2;더 효율적인 방법 :
π productName,CategoryName(δ productNo=2(Product) ⋈ Category)
이와같이 더 효율적인 관계 대수식을 구성하여 효율적으로 처리할 수 있어야 한다
실제로 query optimizer는 관계대수식을 다양하게 구성하고 그 중에서 가장 효율적인 식을 선택한다
DB Type : Relation(오직 하나)
Java Type(Primitive) : 8 (5(numeric)+2(realnum)+1(bool))
Join - Cartesian Product의 연산에 조건을 걸어주는것
셀렉션과 프로젝션
δ (시그마) - 릴레이션에서 투플들을 선택(Selction)할 수 있는 연산자
π (파이) - 필드들을 추출(Projection)할 수 있는 연산자
단일 릴레이션에 있는 데이터를 조작하는데 사용
셀렉션 연산자 δ는 셀렉션 조건을 통해 얻을 투플들을 명세
비교 연산자 <, ⇐, =, ≠, >= > 중의 하나를 op라고 할 때
애트리뷰트 op 상수 또는 애트리뷰트 op 애트리트뷰트 형태의 항을 불리언으로 조합프로젝션 연산자 π는 릴레이션의 필드들을 추출
집합연산
합집합, 교집합, 차집합, 카티션 프로덕트와 같은 표준 집합 연산
합집합(Union, ∪)
같은 요소를 가지는 집합만 합집합 가능
합집합이 가능하려면
두 릴레이션의 필드 수가 같고, 왼쪽부터 오른쪽으로 가면서 순서대로 대응되는 필드들의 도메인이 같아야 한다.인스턴스 R이나 인스턴스 S 모두에 속하는 투플들을 포함하는 릴레이션 인스턴스를 만듦
R과 S는 합병 가능해야 하며, 결과 스키마는 R의 스키마와 동일
교집합(Intersection, ∩)
R ∩ S는 양쪽에 함께 속하는 모든 투플로 구성된 릴레이션 인스턴스를 만듦
R과 S는 합병 가능해야 하며, 결과 스키마는 R의 스키마와 동일
차집합(Set-different, – )
R – S는 R에는 속하고 S에는 속하지 않는 투플로 구성된 릴레이션 인스턴스를 만듦
R과 S는 합병 가능해야 하며, 결과 스키마는 R의 스키마와 동일
카디션 프로덕트(Cartisian Product, X)
R X S는 R의 모든 필드와 S의 모든 필드를 순서대로 가지는 스키마의 릴레이션 인스턴스를 만듦
R X S는 r∈R, s∈S 쌍에 대하여 투플 <r, s>를 하나씩 가짐
사용자가 실제로 원하는 결과는 카티션 프로덕트 결과의 일부인 경우가 대부분이므로 카티션 프로덕트 연산 자체는 많이 쓰이지 않는다
SQL 문에서 ON과 WHERE의 차이 :
ON : Join을 하기전 필터링을 한다(=ON 조건으로 필터링이 된 레코드들 간 JOIN 수행)
WHERE : Join을 한 후 필터링을 한다(=Join 결과에 대해 WHERE 수행)
이름 바꾸기
ρ(로우) - 릴레이션에서 필드의 이름을 변경(Renaming)할 수 있는 연산자
관계 대수식 안에서 이름 충돌이 발생할 수 있음
관계 대수식 안에서 릴레이션 인스턴스의 이름을 주는 것이 편리함
긴 대수식을 작은 부분으로 나누어 결과 인스턴스에 이름을 줄 수 있도록 하는 것이 편리함
SELECT p.ProductName, c.CategoryName
FROM
(SELECT * FROM Product) as p INNER JOIN (SELECT * FROM Category) AS c;
FROM Product as p NATURAL JOIN Category as c;
// 둘 중 아무거나 가능조인
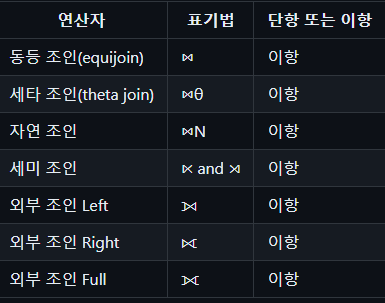
둘 이상의 릴레이션으로부터 정보를 조합하는 연산
유도된 연산으로 카티션 프로덕트와 프로젝션 연산을 함께 실행하여 얻은 결과와 같다
동등 조인 ⋈ 두 릴레이션간의 값을 가진 집합
세타 조인 ⋈θ 두 릴레이션 간의 비교 조건에 만족하는 집합
자연 조인 ⋈N 동등 조인에서 중복 속성을 제거
세미 조인 ⋉ and ⋊ 자연 조인 후 기호의 열린쪽의 속성을 제거
외부 조인 Left ⟕ 자연 조인 후 왼쪽의 모든 값을 추출, 값이 없을 경우 한쪽의 값을 NULL로 채용
외부 조인 Right ⟖ 자연 조인 후 오른쪽의 모든 값을 추출, 값이 없을 경우 한 쪽의 값을 NULL로 채용
외부 조인 Full ⟗ 자연 조인 후 양쪽의 모든 값을 추출, 값이 없을 경우 한 쪽의 값을 NULL로 채용 SQL - 가장 널리 사용되는 상용 관계 데이터베이스 언어
SQL 구성 - DML, DDL, DCL, TCL
데이터 조작어(Data Manipulation Language – DML)
데이터베이스의 데이터를 조회하거나 검색하기 위한 명령 및 데이터베이스 테이블의 데이터에 변형(삽입, 수정, 삭제)을 가하는 질의어
SELECT, INSERT, UPDATE, DELETE데이터 정의어(Data Definition Language – DDL)
테이블, 무결성 등의 데이터 구조를 정의하는데 사용되는 명령어들로 데이터 구조와 관련된 질의어
CREATE, ALTER, DROP, TRUNCATE(데이터 한번에 전부 초기화)데이터 제어어(Data Control Language – DCL)
데이터베이스에 접근하고 개체들을 사용하도록 권한을 주고 회수하는 질의어
GRANT, REVOKE, DENY트랜잭션 제어어(Transaction Control Language – TCL)
논리적인 작업의 단위를 묶어서 DML에 의해 조작된 결과를 트랜잭션별로 제어하는 질의어
COMMIT, ROLLBACK, SAVEPOINT####DDL : 데이터 정의 언어
행, 속성, 관계, 인덱스, 뷰, 저장프로시저 등 데이터베이스의 구조와 객체 정의
CREATE
릴레이션(테이블), 뷰, 인덱스, 저장 프로시저 등 데이터베이스 객체 생성CREATE TABLE {Table Name} (
[Column Name] [Data Type] {NULL | NOT NULL} {Column Option}
{Constraint List} [Constraint definition]
)
CASCADE
| SET NULL
| SET DEFAULT
| RESTRICT
| NO ACTIONDROP - 절대 무슨일이 있어도 지워진 TABLE은 다시 복구할 수 없다
존재하는 데이터베이스 객체 삭제DROP TABLE [TableName]ALTER
존재하는 데이터베이스 객체 수정ALTER TABLE [TableName]
{ALTER COLUMN} [COLUMN NAME] {Column Option}
{ADD} (Column | Constraints} {ADD Option}
{DROP} (Column | Constraints} {DROP Option}TRUNCATE
테이블 내 데이터의 완전 삭제SQL 질의 형식
SQL 표현의 기본 구조 : SELECT, FROM, WHERE
SELECT [DISTINCT] A1, A2 … An
FROM r1 A, r2 B, … rm M
WHERE PSELECT
관계 대수에서 프로젝션(Projection - π) 연산과 일치, 결과에 나타날 속성을 나열하는데 사용됨
중복된 튜플은 릴레이션에 나타날 수 없다
중복성 제거는 시간 소비성 작업이니, SQL은 프로젝션 결과와 릴레이션에서 중복을 허용한다
중복이 없어야 하는 결과 집합 쿼리의 경우 DISTINCT를 붙여 써준다
SUM, COUNT, AVG, 등...FROM
관계 대수의 카티션 프로덕트에 해당하며, 질의에서 조회할 릴레이션을 나열
기호를 사용해 모든 속성을 사용할 수 있다
리스트에 있는 릴레이션들의 카티션 프로덕트를 정의
-자연 조인은 카티션 프로덕트, 셀렉션 연산, 프로젝션 연산으로 수행됨
-FROM절에서 간단히 자연 조인을 SQL 연산으로 표현할 수 있음WHERE
관계대수에서 셀렉션(Selection - σ) 연산과 일치, FROM 절에 나타나는 릴레이션 속성들의 조건으로 구성
WHERE 절의 조건식으로 셀렉션 연산을 수행
식 op 식` 형태의 조건들을 조합한 불리언 식으로, op는 비교 연산자 {<, ⇐, =, <>, >=, >} 중의 하나
범위 연산을 위해 BETWEEN 비교 연산을 제공
null 검사하고싶으면 = null이 아니라 반드시 is null을 써야 한다
EXISTS, LIKE(정규표현식 사용 %~~%,_~~_, _~~%), in 등 사용 가능
앞뒤로 전부, 앞뒤로 한글자, 앞에 한글자 뒤로 전부
- Like로 검색 못하는 것들이 있음. Full-text Searching 등으로 DB가 아니라 외부 Framework를 써서 해결해야 한다집합연산
집합 가능 조건 : 합병 가능한 두 연산일때 집합 가능
UNION, INTERSECT(MySQL 지원 X), EXCEPT(MySQL 지원 X, MINORS_ORACLE)
UNION - Column 수만 같으면 무조건 진행
서브 쿼리 개요
단일 질의 안에 질의가 포함된 형태의 쿼리
관계 대수 질의 결과는 릴레이션을 반환함
서브 쿼리의 결과를 주 쿼리에서 받아서 처리는 형식으로, 포함된 쿼리(Nested Query) 라라고도 부름서브 쿼리 (Subquery)
가장 많이 사용되는 형태로, WHERE 절에서 셀렉션 연산의 값을 산출하기 위해 사용하는 질의인라인 뷰(Inline View)
FROM 절에서 질의의 결과를 테이블처럼 사용하는 용도의 질의스칼라 서브 쿼리(Scala Subquery)
SELECT 문에서 사용되는 서브 쿼리로, 주로 계산 결과값을 쿼리 결과에 포함시키는데 사용되는 질의연관 서브 쿼리
서브 쿼리에서 주 쿼리의 필드값과 연관되어 사용하는 질의서브쿼리의 동작은 이중 루프의 수행과 비슷하다
포함된 서브 쿼리
단일 질의 내부에 질의가 포함된 일반적 쿼리; 서브쿼리의 결과를 변수처럼 사용한다
단일행 서브 쿼리(Single Row Subquery)
쿼리의 결과가 하나의 Row만을 산출다중행 서브 쿼리(Multi Row Subquery)
쿼리 결과가 여러 Row를 산출다중 컬럼 서브 쿼리(Multi Column Subquery)
전체 테이블을 비교하는 것 보다 일부 테이블만을 불러와 그 중에서 셀렉션하는 것이 비교 횟수가 적음서브쿼리에선 IN, ANY, ALL, EXISTS를 쓸 수 있다
IN - 다수의 비교값과 비교하여 비교값 중 하나라도 같은 값이 있으면 결과를 반환
ANY - IN 연산과 동일하나, 비교 연산을 사용할 수 있음
ALL - ANY 연산과 유사하나, 모든 값을 만족해야 함
EXISTS - 값이 있으면 True, 없으면 False
Inline View - 서브쿼리가 from 절 내부에서 사용되는 경우
From절에서 사용된 서브쿼리의 결과가 하나의 테이블에 대한 뷰 처럼 사용됨
서브 쿼리와 테이블 조인이 이루어질 경우 쿼리의 가독성이 떨어짐
전체 테이블을 비교하는 것 보다 일부 테이블만을 불러와 그 중에서 셀렉션하는 것이 비교 횟수가 적음스칼라 서브쿼리 - SELECT 절에 포함된 서브 쿼리
스칼라 서브 쿼리의 반환 값은 하나의 레코드에서 단일 컬럼이어야 함
테이블의 조인이 많아 실행 계획의 제어가 어려울 경우 사용
결과 집합이 대량인 경우 효율이 저하됨
소량의 테이블에서 명칭만 가져올 경우 유리함스칼라 서브쿼리가 유리한 경우
스칼라 서브 쿼리를 수행할 결과 집합이 대량이 아닌 경우
코드 테이블의 조인이 많이 실행 계획이 복잡해지는 경우
코드 테이블에서 명칭만 가져오는 경우 (대량의 데이터 조회가 아닌 경우)상호연관 서브쿼리 - 서브 쿼리가 주 쿼리의 필드값과 연관되어 사용
가능하면 쓰지 않는것이 좋다(효율이 매우 떨어짐)
주 쿼리의 한 Row에 대해 서브 쿼리가 한번씩 실행됨
테이블에서 Row를 먼저 읽고 각 Row의 서브 쿼리에서 사용함결과 집합이 대량인 경우 효율이 떨어짐
포함된 서브 쿼리와 인라인 뷰, 포함된 서브쿼리에서 주 쿼리와 값을 비교하는 모든 경우
집단연산
집계함수 - SELECT 절에서 산출되는 Columns의 값에 대한 집계를 위해 사용
COUNT([DISTINCT] A) A 필드에 있는 [유일한] 값들의 수
SUM([DISTINCT] A) A 필드에 있는 [유일한] 값들의 합
AVG(DISTINCT] A) A 필드에 있는 [유일한] 값들의 평균
MAX (A) A 필드에 있는 최대값
MIN (A) A 필드에 있는 최소값
GROUP BY 와 HAVING 절- 릴레이션의 튜플들을 여러 그룹으로 나누어 그룹별로 연산 수행
그룹의 수는 릴레이션의 인스턴스에 따라 좌우
GROUP BY - 컬럼의 값을 기준으로 튜플을 그룹화
HAVING - 그룹에 대한 조건식을 지정
SELECT [DISTINCT] select-list
FROM from-list
WHERE conditional statement
GROUP BY grouping-list
HAVING group conditional statement정렬 - ORDER BY, INDEX
ORDER BY - DB 질의의 결과는 테이블 내의 튜플의 위치대로 산출
ORDER BY 절에 사용되는 컬럼을 기준으로 데이터 산출
오름차순(DESC)와 내림차순(ASC – 기본 값)으로 데이터를 정렬 함어찌되었든 정렬을 하면서 속도가 느려질 수 있다
인덱스를 활용한 정렬 - 인덱스가 생성되면, 해당 인덱스를 바탕으로 정렬할 수 있다
삽입 - INSERT 문 - 테이블에 튜플을 삽입하기 위해 사용
INSERT INTO <Table Name>
[(Column Name 1, Column Name2, … Column Name n)]
VALUES (Value 1, Value 2 … Value 3)갱신
UPDATE 문 - 테이블의 데이터를 갱신하기 위해 사용
튜플 전체가 아니라 데이터단위로 데이터 갱신
테이블 내에서 조건에 해당하는 모든 튜플의 데이터를 모두 갱신
따라서 DROP처럼 한번 UPDATE하면 백업하기전에는 못돌린다. 주의할 것
삭제
DELETE, TRUNCATE
DELETE
<delete statement: searched> ::=
DELETE FROM <target table>
[ WHERE <search condition> ]