연관관계 맵핑
R-DB 에서의 관계란?
DB 정규화 : 중복 데이터로 인해 발생하는 데이터 불일치 현상을 해소
정규화를 통해 각각의 DB 테이블들은 중복되지 않은 데이터를 가지게 된다.
- 필요한 데이터를 가져오기 위해서는 여러 테이블 사이의 관계를 JOIN을 통해 관계 테이블을 참조한다
연관 관계(Association)
- 데이터베이스 테이블 사이의 관계를 Entity의 속성으로 모델링한다
- 데이터베이스 테이블은 FK로 JOIN을 사용해 관계 테이블을 참조한다
- 객체는 참조를 사용해 연관된 객체를 참조한다
FK 맵핑 하는 방법 두가지
- @JoinColumn : 외래 키 맵핑(1개)
- @JoinColumns : 복합 외래 키 맵핑(N개)
*1대다 관계도 @ManyToOne을 사용해서 명시할 수 있다
@ManyToOne(fetch = FetchType.EAGER, cascade = CascadeType.ALL)
@JoinColumn(name = "team_id")
private type name; // 이거는 반드시 해주고 그 다음에 속성을 column으로 직접 달아줄 수 있다- fetch : eager / lazy
- EntityManager에서 Find method를 사용할 때, Join해서 가져올 객체를 함께 가져오고 싶으면 Eager를 사용.
- Poo poo = foo.getPoo() // 실행시 가져오고 싶으면 lazy를 사용
cascade :
- EntityManager.persist)를 수행할 때, member 하위 연관관계 객체도 한번에 저장하고 싶은 경우 persist를 사용하면 된다.
다중성 : Multiplicity
- @OneToOne
- @OneToMany
- @ManyToOne
- (@ManyToMany) 잘 안씀 -> OneToMany, ManyToOne으로 분리하면 되는데 굳이?
Fetch 전략
- JPA가 하나의 Entity를 가져올 때 연관관계에 있는 Entity들을 어떻게 가져올 것인지에 대한 설정
- FetchType.EAGER (즉시 로딩)
- FetchType.LAZY (지연 로딩)
다중성과 기본 Fetch 전략
- N-ToOne (@OneToOne, @ManyToOne) : FetchType.EAGER
- N-ToMany (@OneToMany, @ManyToMany) : FetchType.LAZY
영속성 전이 (CASCADE)
- Entity의 영속성 상태 변화를 연관된 Entity에도 함께 적용
- 연관관계의 다중성 (Multiplicity) 지정 시 cascade 속성으로 설정
@OneToOne(cascade = CascadeType.PERSIST)
@OneToMany(cascade = CascadeType.ALL)
@ManyToOne(cascade = { CascadeType.PERSIST, CascadeType.REMOVE })Cascade 종류
public enum CascadeType {
ALL, /* PERSIST, MERGE, REMOVE, REFRESH, DETACH */
PERSIST, // cf.) EntityManager.persist()
MERGE, // cf.) EntityManager.merge()
REMOVE, // cf.) EntityManager.remove()
REFRESH, // cf.) EntityManager.refresh()
DETACH // cf.) EntityManager.detach()
}연관관계는 - 단방향(Unidirectional), 양방향(Bidirectional)로 구성된다
양방향 연관관계
- 관계의 주인(Owner)
* 연관 관계의 주인은 FK가 있는곳- 연관 관계의 주인이 아닐 경우, mappedBy 속성으로 연관 관계의 주인을 지정한다
단방향 VS 양방향
단방향 Mapping 만 써도 연관관계 Mapping은 이미 완료된다.
JPA 연관관계도 내부적으로 FK 참조를 기반하여 구현한다. 따라서 본질적으로 참조는 단방향이다단방향에 비해 양방향은 복잡하고 양방향 연관관계를 맵핑하려면 객체에서 양쪽 방향을 모두 관리해야 함
물리적으로 존재하지 않는 연관관계를 처리하기 위해 mappedBy 속성을 통해 관계의 주인을 정해야 함단방향을 양방향으로 만들면 반대 방향으로의 객체 그래프 탐색 가능
우선적으로는 단방향 맵핑을 사용하고 반대 방향으로의 객체 그래프 탐색 기능이 필요할 때 양방향을 사용*주인 Entity는 CRUD가 가능하지만, 주인이 아닌 Entity는 Select만 가능하다(fk field)
- JPA에서 대상 테이블에 FK가 있는데, 주 테이블이 단방향으로 이를 참조하는것을 지원하지 않는다.(1대1에서 FK가 있는쪽을 무조건 주 방향으로 잡아라)
양방향 1대1 관계도 만들 수 있다
일대일 식별관계 (FK를 PK로 가지는 관계)
@MapsId를 써서 PK,FK임을 나타낼 수 있다
@MapsId("연결된 필드 이름")로 명시적으로 사용 가능
하위에서 mappedId로 가져온 객체와 Mapping
단방향 다대일 (N:1) 관계 <-> 일대다 관계(1:N) 관계
@ManyToOne
@OneToMany 달기 나름이다
단방향 일대다 단점 : 다른 테이블에 FK가 있으면 연관관계 처리를 위해 추가적인 UPDATE 쿼리를 실행해야 한다(Persist시 사용)
-> 해결 : 단방향 일대다 관계보다 양방향 Mapping을 사용하자!
Repository : 도메인 객체에 접근하는 컬렉션과 비슷한 인터페이스를 사용해 도메인과 데이터 맵핑 계층 사이를 중재(mediate) - 일반적 정의
- 실제 저장하는 DB와 도메인 사이에 존재해서 Collection과 비슷하게 동작해줌.
findall, find, delete 등...
DDD (Domain Driven Development) : a mechanism for encapsulating storage, retrieval, and search behavior which emulates a collection of objects
*주의사항 : Repository는 JPA의 개념이 아니라 Spring Framework가 제공하는 것임
Spring Data Repository : data access layer 구현을 위해 반복해서 작성했던, 유사한 코드를 줄일 수 있는 추상화 제공
Repository 설정
- JpaRepository를 상속받아서 쓰면 된다
public interface ItemRepository extends JpaRepository<T, ID> {
}Repository의 계층구조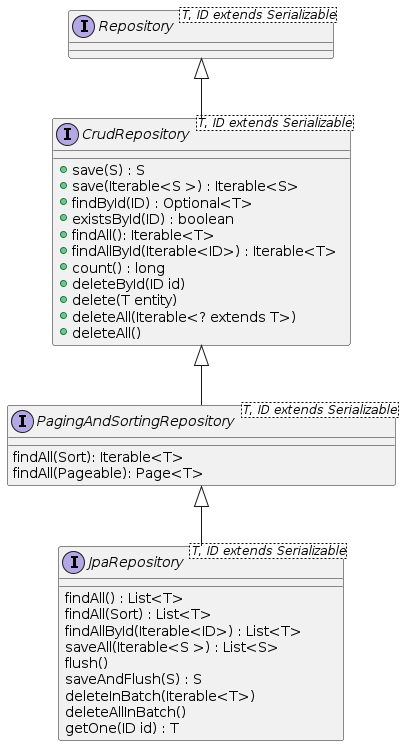
JpaRepository가 제공하는 메소드들이 실제 수행하는 쿼리
// insert / update
<S extends T> S save(S entity);
// select * from Items where item_id = {id}
Optional<T> findById(ID id);
// select count(*) from Items;
long count();
// delete from Items where item_id = {id}
void deleteById(ID id);
// ...@Repository와 @Spring Data Repository의 차이점
- @Repository
- org.springframework.stereotype.Repository
- Spring Stereotype annotation
Ex.) @Controller, @Service, @Repository, @Component
- @ComponentScan 설정에 따라 classpath scanning을 통해 빈 자동 감지 및 등록
- 다양한 데이터 액세스 기술마다 다른 예외 추상화 제공
- DataAccessException, PersistenceExceptionTranslator - Spring Data Repository
- org.springframework.data.repository
- @EnableJpaRepositories 설정에 따라 Repository interface 자동 감지 및 동적으로 구현 생성해서 Bean으로 등록
cf.) @NoRepositoryBean
- Spring Data Repository bean으로 등록하고 싶지 않은 중간 단계 interface에 적용
메서드 이름으로 쿼리 생성
- Spring Data JPA에서 제공하는 기능으로 이름 규칙에 맞춰서 interface에 선언하면 쿼리가 생성된다
public interface ItemRepository {
// select * from Items where item_name like '{itemName}'
List<Item> findByItemNameLike(String itemName);
// select item_id from Items
// where item_name = '{itemName}'
// and price = {price} limit 1
boolean existsByItemNameAndPrice(String itemName, Long price);
// select count(*) from Items where item_name like '{itemName}'
int countByItemNameLike(String itemName);
// delete from Items where price between {price1} and {price2}
void deleteByPriceBetween(long price1, long price2);
}어떤 키워드를 써야 메소드가 생성 될까? 참고)
https://docs.spring.io/spring-data/jpa/reference/repositories/query-keywords-reference.html#appendix.query.method.subject
https://docs.spring.io/spring-data/jpa/reference/jpa/query-methods.html#jpa.query-methods.query-creationpublic interface ItemRepository {
// select * from Items where item_name like '{itemName}'
List<Item> findByItemNameLike(String itemName);
// select item_id from Items
// where item_name = '{itemName}'
// and price = {price} limit 1
boolean existsByItemNameAndPrice(String itemName, Long price);
// select count(*) from Items where item_name like '{itemName}'
int countByItemNameLike(String itemName);
// delete from Items where price between {price1} and {price2}
void deleteByPriceBetween(long price1, long price2);
}SimpleJpaRepository에서 @Repository가 등록되어있어서 우리가 @Repository 없이 써도 Bean으로 등록이 된다.
**Stream API 중단연산자, 종단연산자 공부해보기
- Intermeditate Operation(Map, Filter ... )
- Terminal Operation(Foreach, toArray, collect ... )
복잡한 쿼리 작성
JPA에서 제공하는 객체지향 쿼리
JPQL : 엔티티 객체를 조회하는 객체지향 쿼리(가아아끔 씀)
Criteria API : JPQL을 생성하는 빌더 클래스(거의 안씀)
Third party library를 이용하는 방법
Querydsl(자주 씀)
jOOQ(가끔 씀)
* ...
JPQL VS Criteria API
JPQL
- SQL을 추상화해서 특정 DBMS에 의존적이지 않은 객체지향 쿼리
- 문제 : 결국은 SQL이라는 점
*문자 기반 쿼리이다보니 컴파일 타임에 오류를 발견할 수 없다
SELECT DISTINCT post
FROM Post post
JOIN post.postUsers postUser
JOIN postUser.projectMember projectMember
JOIN projectMember.member member
WHERE member.name = 'foooooo'Criteria API
- 프로그래밍 코드로 JPQL을 작성할 수 있고 동적 쿼리 작성이 쉽다
- 컴파일 타임에 오류를 발견할 수 있고 IDE의 도움을 받을 수 있다
- 문제 : 너무 복잡함
EntityManager em = ...;
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<PostEntity> cq = cb.createQuery(PostEntity.class);
Root<PostEntity> post = cq.from(Post.class);
cq.select(post);
TypedQuery<PostEntity> q = em.createQuery(cq);
List<PostEntity> posts = q.getResultList();
=SELECT post FROM PostEntity post