LLM에 대해 알아보자✨

📌 LM? LLM? 단어 정의
LLM에 대해 알아보기 전에 LLM의 기본 개념인 LM에 대해 알아보자
| 비교 항목 | LM(언어 모델) | LLM(대규모 언어 모델) |
|---|---|---|
| 학습 데이터 | 소규모 | 수십억 개의 문장 |
| 학습 방법 | 간단한 확률 모델 | 트랜스포머 기반 딥러닝 |
| 활용 예시 | 입력된 문장에서 다음 단어 예측 | ChatGPT,Bard,Claude,Llama 등) |
우선 LM(Language Model)이란 입력값(자연어)을 기반으로 통계학적으로 가장 적절한 출력값을 출력하도록 학습된 모델이다. 즉, 자연어의 패턴을 학습하고 이해하여 텍스트를 생성하거나 예측하는 AI모델로 단어나 문장을 보고 다음에 올 단어를 예측하는 모델이라 정의할 수 있다.
반면 LLM(Large Language Model, 대규모 언어 모델)은 거대한 양의 텍스트 데이터를 학습하여 인간과 비슷한 수준의 자연어 이해 및 생성이 가능한 AI 모델을 의미한다. (ex. GPT-4, Claude, Llama, Mistral, Gemini 등)
📌 LLM의 구조와 학습 방식
LLM의 구조 및 학습 방식은 다음과 같다
1. 구조: 트랜스포머 아키텍처(Transformer Architecture)
대부분의 LLM은 트랜스포머 아키텍처를 기반으로 만들어졌다
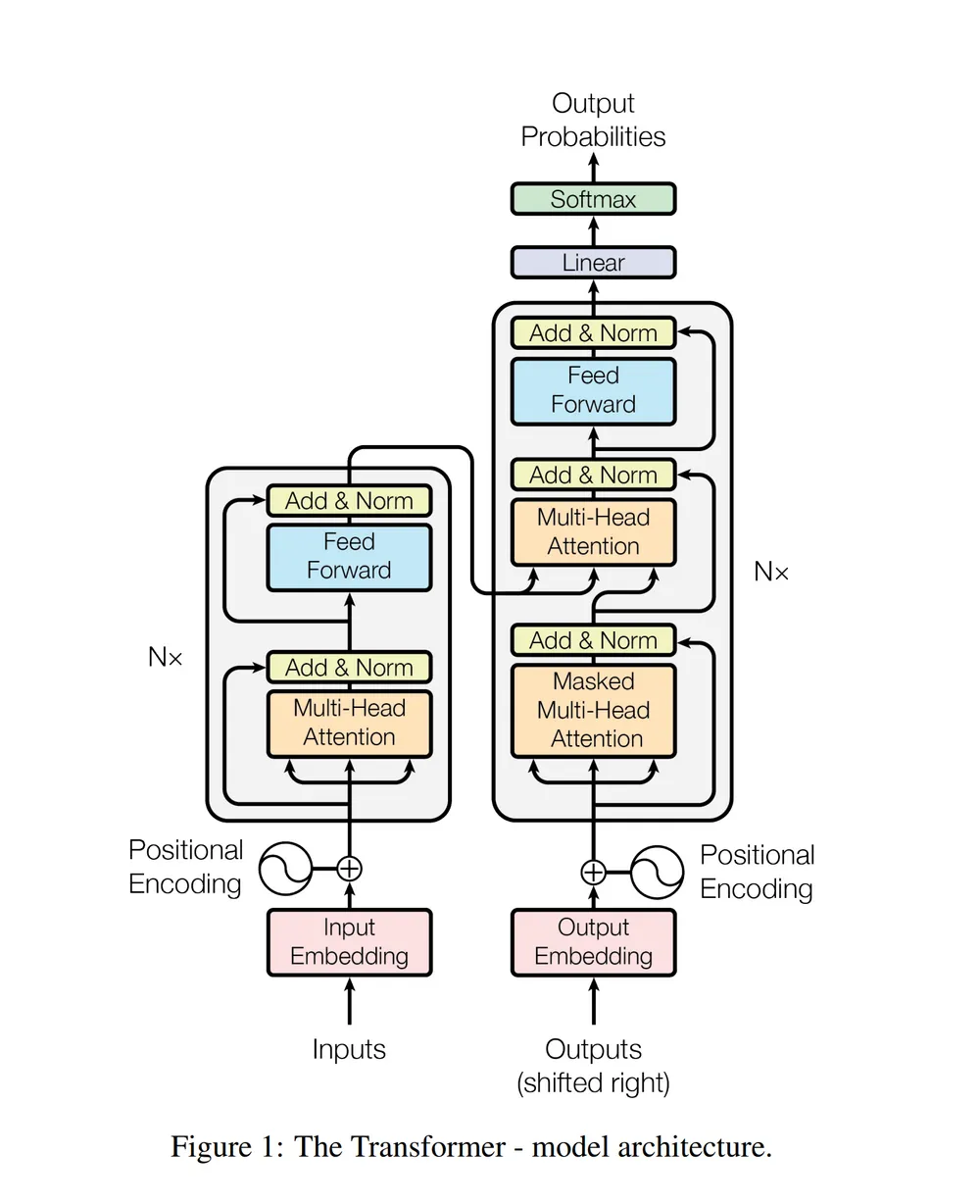
-
트랜스포머 아키텍처는 2017년 논문 "Attention Is All You Need"에서 처음 등장했고, 자연어 처리(NLP, Natural Language Processing) 개념에서 혁신적인 발전을 가져온 구조이다
*Attention Is All You Need: Google 종사자 8명이 작성한 논문으로 머신러닝 분야에서의 획기적인 논문 연구로 손꼽힌다 -
기존 RNN/LSTM(딥러닝 모델)보다 병렬처리가 가능하고, 자연어에 대한 이해와 생성 성능이 뛰어나다
병렬처리의 장점: 언어학습 과정 중 병렬처리 방식은 순차처리 방식와 달리 모든 데이터를 동시에 처리할 수 있기에 속도가 빠르다는 점에 있어 개발 효율성과 성능 향상 부분에서 효과적이라는 특징이 있다
2. 학습 방식: 사전 학습 + 미세 조정
LLM은 2단계 학습 과정을 거친다
-
1) 사전 학습(Pretraining): 인터넷의 방대한 텍스트 데이터(ex. 책, 논문, 블로그, 위키백과 등)를 학습해 언어 패턴을 익힌다
-
2) 미세 조정(Fine-tuning): 특정 케이스에 맞게 추가적인 데이터를 학습하여 모델을 최적화한다
*ex. 법률 상담, 치료 상담, 개발 보조 장치 등 다양한 필요 목적에 맞게 미세 조정 학습 과정을 거친다
📌 대표적인 LLM 모델 비교
LLM의 대표적인 모델 예시를 비교해보면 다음과 같다
| 모델 | 개발사 | 특징 |
|---|---|---|
| GPT-4 | OpenAI | ChatGPT 기반 모델 |
| Claude | Anthropic | 윤리적이고 안전한 AI 설계, GPT의 경쟁 모델 |
| Llama2 | Meta | 오픈소스 LLM, 기업용 활용 가능 |
| Mistral 7B | Mistral AI | 가벼운 모델이지만 높은 성능 |
| Gemini | Google DeepMind | 멀티모달(텍스트+이미지) AI 모델 |
📌 LLM 활용 예시
LLM이 우리 일상 속에서 어떤 식으로 활용되고 있는지 알아보자
- AI 챗봇: ChatGPT, Claude, Bimg AI 등
- 번역 & 요약: Google 번역, DeppL, AI 문서 요약기
- 코딩 지원 도구: GitHub, Copilot, Code Llama
- 의료 & 법률 AI: AI 기반 상담 시스템
- 검색 & 추천 시스탬: AI 기반 검색 엔진
📌 LLM 실습
LLM을 직접 사용해보고 싶다면 다음과 같은 방법이 있다
1. Open AI API 사용(import 방식)
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "LLM이 뭐야?"}]
)
print(response["choices"][0]["message"]["content"])2. Hugging Face 홈페이지 활용
Hugging Face(허깅 페이스)는 머신러닝, 딥러닝 등의 AI 리소스들을 사용, 공유, 배포할 수 있는 플랫폼이다 *홈페이지 주소: https://huggingface.co/
- Pre-trained 모델 사용
- 오픈소스 모델 다운
