알고리즘
1.버블 정렬
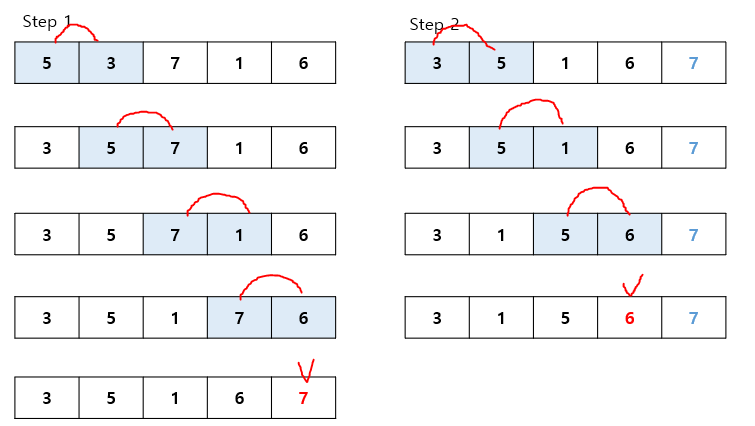
특징 인접한 데이터를 비교하며 자리를 바꾸는 방식 구현 난이도는 쉽지만 속도는 O(n^2)로 느리다 정렬 과정 Step 1)
2.삽입 정렬
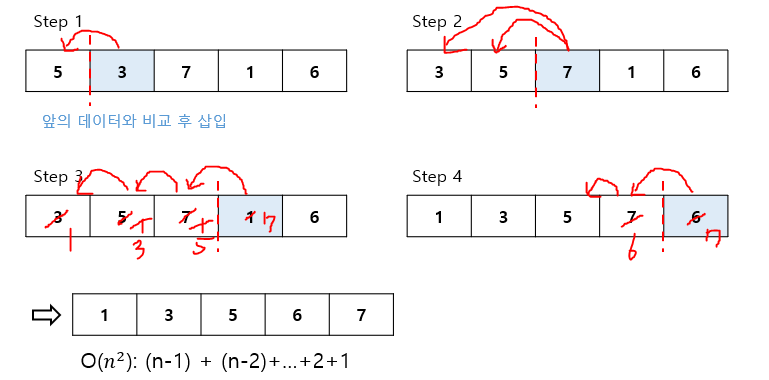
앞의 데이터를 정렬해가면서 삽입 위치를 찾아 정렬하는 방식알고리즘 복잡도: O(n^2)
3.합병 정렬 (Merge Sort)
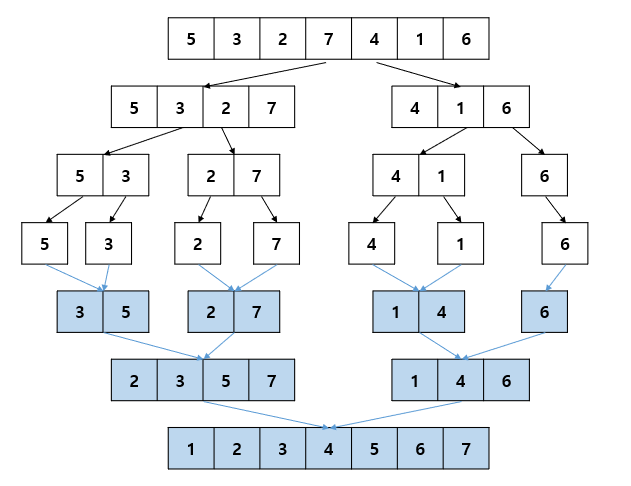
배열을 계속 분할해서 길이가 1이 되도록 만들고, 인접한 부분끼리 정렬하면서 합병하는 방식O(nlogn)합병 과정에서는 추가 저장을 위한 메모리가 필요하다쪼개고 합쳐지는 과정을 인덱스를 통해 구분하는 것으로 구현한다.인덱스를 더 짜를 수 없을 때까지 짜른 뒤, p와 q
4.힙 정렬 (Heap Sort)

힙 자료구조 형태의 정렬 방식기존 배열을 최대 힙으로 구조 변경 후 정렬 진행자바에 있는 힙을 만들어서 값을 넣은 후에 사용해도 된다O(nlogn)array를 heap으로 바꾸면서 정렬한다.
5.퀵 정렬 (Quick Sort)
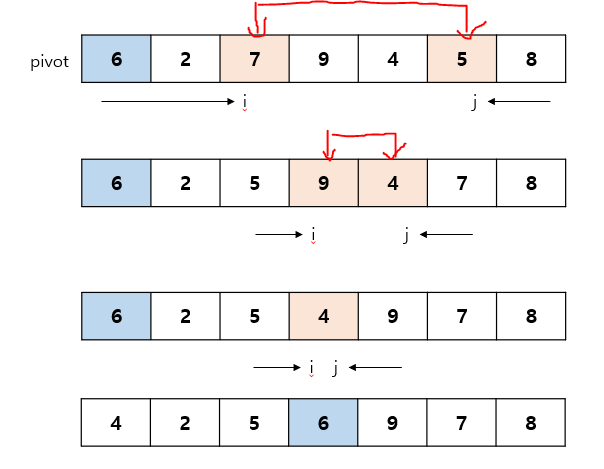
임의의 기준 값(pivot)을 정하고 그 값을 기준으로 좌우로 분할하며 정렬하는 방식O(n^2) - pivot이 최소값 또는 최대값으로 지정되는 최악의 경우pivot 정하는 방법1) 중간에 있는 값2) 왼쪽 끝에 값3) 오른쪽 끝에 값4) 위에 3개 값을 뽑은 후 크기
6.기수 정렬 (Radix Sort)
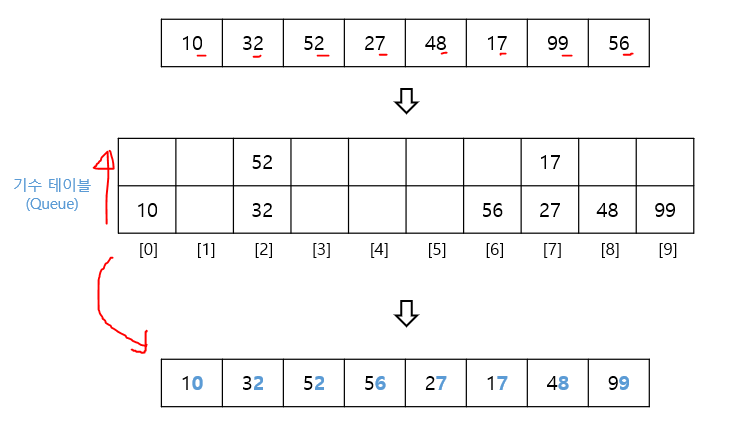
낮은 자리 수부터 정렬하는 방식 \- ex) 123이 있으면 1의 자리수 3부터 -> 2 -> 1 순으로 정렬각 원소 간의 비교 연산을 하지 않아 빠른 대신, 기수 테이블을 위한 메모리 필요O(dn) -> d는 최대 자리수 \- ex) 1, 2, 3, 4, 5, 10
7.계수 정렬 (Counting Sort)
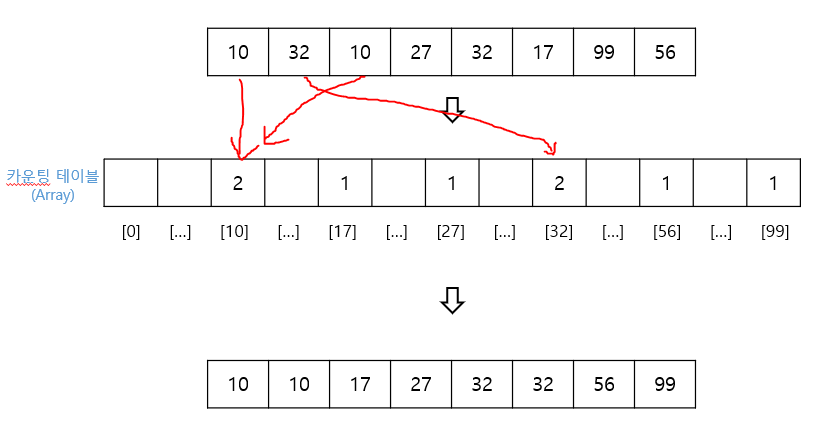
숫자끼리 비교하지 않고, 카운트를 세서 정렬하는 방식카운팅을 위한 메모리 필요O(n+k)k는 정렬 대상 데이터 중 최대값으로, k가 n보다 더 커서 worst한 케이스를 만들 수 원소 중 가장 큰 값으로 배열 사이즈를 잡아서, 카운팅 테이블을 만든다각 위치의 값을 카운
8.셸 정렬 (Shell Sort)
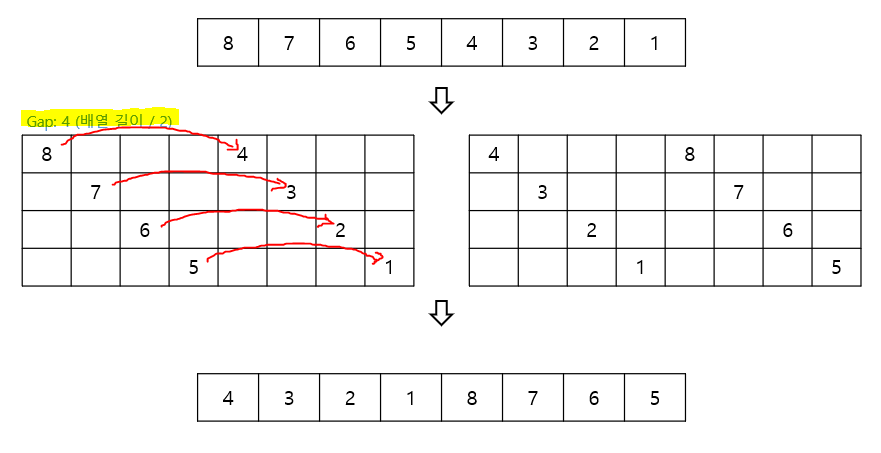
삽입 정렬의 약점을 보완한 정렬 방식 \- 삽입 정렬의 약점오름차순 정렬 기준, 내림차순으로 구성된 데이터에 대해서는 앞의 데이터와 하나씩 비교하며 모두 교환 필요이전의 모든 데이터와 비교하지 않고 일정 간격을 두어 비교O(n^2) \- 간격 설정에 따라 Wor
9.이진 탐색 (Binary Search)
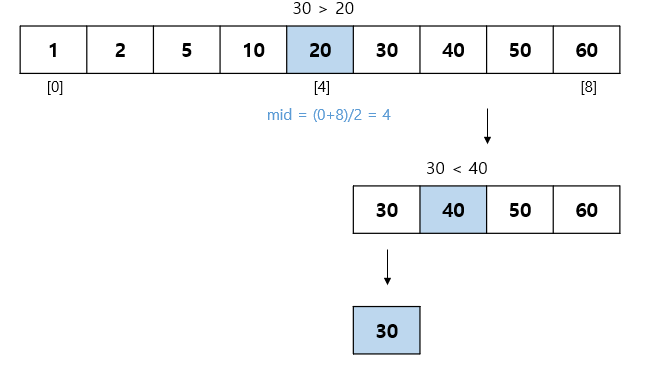
정렬된 상태의 데이터에서 특정 값을 빠르게 탐색하는 방법찾고자 하는 값과 데이터 중앙에 있는 값을 비교찾고자 하는 값이 더 작으면 데이터 왼쪽 부분에서 이진 탐색찾고자 하는 값이 더 크면 데이터 오른족 부분에서 이진 탐색O(logN)30을 찾는 과정'해당 데이터가 있을
10.투 포인터
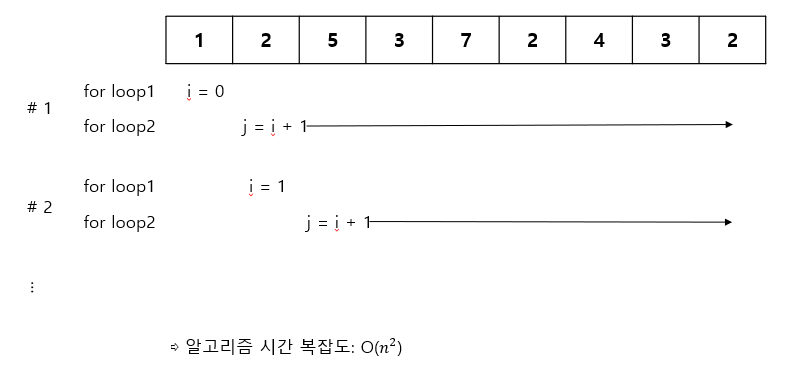
배열에서 두 개의 포인터를 사용하여 원하는 결과를 얻는 방법다중 for문의 복잡도를 좀 더 선형적으로 풀 수 있다두 개 포인터의 배치 방법1) 같은 방향에서 시작 \- 첫 번째 원소에 둘 다 배치 \- 주어지는 조건에 따라서 2개의 포인터가 서로 다르게 움직임2)
11.그리디 알고리즘 (Greedy Algorithm)
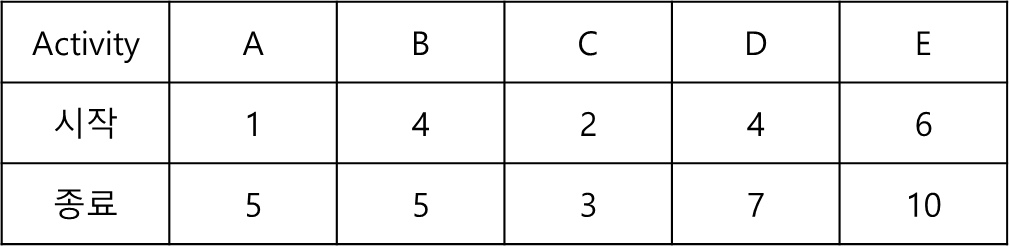
매 순간 현재 기준으로 최선의 답을 선택해 나가는 기법 \- 빠르게 근사치를 계산 \- 결과적으로는 최적해가 아닐 수 있다1) Activity Selection ProblemN 개의 활동과 각 활동의 시작/종료 시간이 주어졌을 때, 한 사람이 최대한 많이 할
12.분할 정복 (Divide and Conquer)
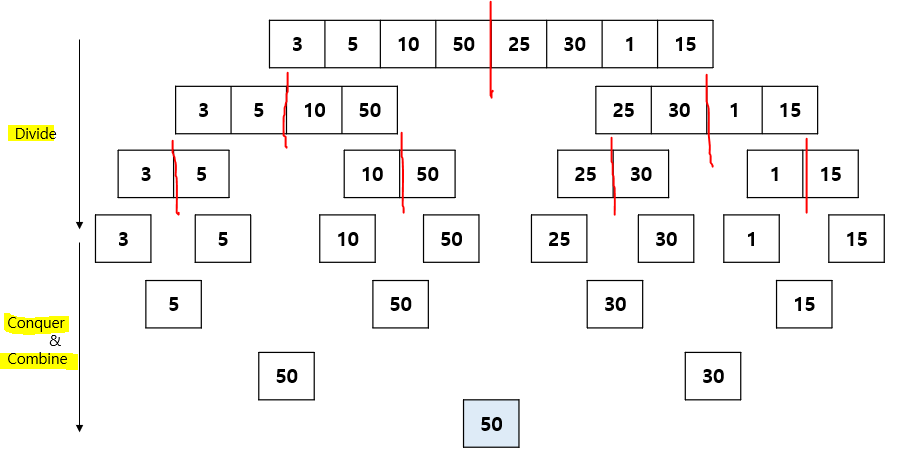
큰 문제를 작은 부분 문제로 나누어 해결하는 방법ex) 합병 정렬, 퀵 정렬, 이진 검색분할 정복 과정1) 문제를 하나 이상의 작은 부분들로 분할2) 부분들을 각각 정복3) 부분들의 해답을 통합하여 원래 문제의 답을 구함장점 문제를 나누어 처리하며 어려운 문제 해결 가